[Из песочницы] Откуда растут ноги у Java Memory Model
Современное железо и компиляторы готовы перевернуть с ног на голову наш код, лишь бы он работал быстрее. А их производители тщательно скрывают свою внутреннюю кухню. И все прекрасно, пока код выполняется в одном потоке.
В многопоточной среде можно волей-неволей наблюдать интересные вещи. Например выполнение инструкций программы не в том порядке, как написано в исходном коде. Согласитесь, неприятно осознавать, что выполнение исходного кода строчка за строчкой это всего лишь наша фантазия.
Но все уже осознали, ведь жить с этим как-то надо. А Java программисты даже неплохо живут. Потому что в Java есть модель памяти — Java Memory Model (JMM), которая предоставляет достаточно простые правила для написания корректного многопоточного кода.
И правил этих достаточно для большинства программ. Если вы их не знаете, но пишите или хотите писать многопоточные программы на Java, то лучше как можно скорее ознакомиться с ними. А если знаете, но вам не хватает контекста или интересно узнать откуда растут ноги у JMM, тогда статья может вам помочь.
И абстракцией погоняет
В моем представлении существует пирог, или, что более подходящее — айсберг. JMM это верхушка айсберга. Под водой сам айсберг — теория многопоточного программирования. Под айсбергом — Ад.

Айсберг — это абстракция, если она протечет, то Ад мы конечно же увидим. Хоть там и происходит масса всего интересного, в обзорной статье до этого мы не доберемся.
В статье меня больше интересуют следующие темы:
- Теория и терминология
- Как теория многопоточного программирования отражается на JMM
- Модели конкурентного программирования
Теория многопоточного программирования позволяет уйти от сложности современных процессоров и компиляторов, она позволяет моделировать выполнение многопоточных программ и изучать их свойства. Роман Елизаров сделал отличный доклад, цель которого дать теоретическую базу для понимания JMM. Рекомендую доклад всем, кто интересуется данной темой.
Почему так важно знать теорию? На мой взгляд, надеюсь только на мой, у некоторых программистов бытует мнение, что JMM это усложнение языка и латание каких-то проблем платформы с многопоточностью. Теория показывает, что в Java не усложнили, а упростили и сделали более предсказуемым очень сложное многопоточное программирование.
Конкуренция и параллелизм
Для начала давайте рассмотрим терминологию. К сожалению, в терминологии нет консенсуса — изучая разные материалы, вы можете встретить различные определения конкуренции и параллелизма.
Проблема в том, что даже если мы докопаемся до истины и найдем точные определения этим понятиям, то все равно вряд ли стоит рассчитывать, что все будут подразумевать то же самое под этими понятиями. Концов тут не найдешь.
Роман Елизаров, в докладе теория параллельного программирования для практиков говорит о том что, иногда эти понятия смешивают. Иногда выделяют параллельное программирование как общее понятие, которое разделяется на конкурентное и распределенное.
Мне кажется, что в контексте JMM нужно все таки разделять конкуренцию и параллелизм или скорее даже понимать, что есть две разные парадигмы, как бы они не назывались.
Часто цитируют Роба Пайка, который различает понятия следующим образом:
- Конкуренция — это способ одновременного решения множества задач
- Параллелизм — это способ выполнения разных частей одной задачи
Мнение Роба Пайка не является эталоном, но на мой взгляд, от него удобно отталкиваться для дальнейшего изучения вопроса. Подробнее про различия можно почитать тут.
Скорее всего больше понимания в вопросе появится, если мы выделим основные признаки конкурентной и параллельной программы. Признаков достаточно много, рассмотрим самые значимые.
Признаки конкуренции.
- Наличие нескольких потоков управления (например Thread в Java, корутина в Kotlin), если поток управления один, то конкурентного выполнения быть не может
- Недетерминированный результат выполнения. Результат зависит от случайных событий, реализации и того как была проведена синхронизация. Даже если каждый поток полностью детерминированный, итоговый результат будет недетерминированным
Параллельная программа будет обладать другим набором признаков.
- Необязательно имеет несколько потоков управления
- Может приводить к детерминированному результату, так например, результат умножения каждого элемента массива на число, не изменится, если умножать его по частям параллельно
Как ни странно, параллельное выполнение возможно на одном потоке управления, и даже на одноядерной архитектуре. Дело в том, что параллелизм на уровне задач (или потоков управления) к которому мы привыкли, это не единственный способ выполнять вычисления параллельно.
Параллелизм возможен на уровне:
- битов (например в 32-разрядных машинах сложение происходит в одно действие, параллельно обрабатывая все 4 байта 32-разрядного числа)
- инструкций (на одном ядре, в одном потоке процессор может выполнять инструкции параллельно, несмотря на то что код последовательный)
- данных (существуют архитектуры с параллельной обработкой данных (Single Instruction Multiple Data), способные выполнять одну инструкцию на большом наборе данных)
- задач (подразумевается наличие нескольких процессоров или ядер)
Параллелизм на уровне инструкции это один из примеров оптимизаций, которые происходят с выполнением кода, и которые скрываются от программиста.
Гарантируется, что оптимизированный код будет эквивалентен исходному в рамках одного потока, потому что невозможно писать адекватный и предсказуемый код, если он будет делать не то, что подразумевал программист.
Не все то, что исполняется параллельно имеет значение для JMM. Параллельное выполнение на уровне инструкций в рамках одного потока не рассматривается в JMM.
Терминология очень шаткая, у Романа Елизарова доклад называется «Теория параллельного программирования для практиков», хотя там больше именно про конкурентное программирование, если придерживаться вышесказанного.
В контексте JMM в статье я буду придерживаться термина конкуренция, так как конкуренция часто про общее состояние. Но тут надо быть аккуратным, не цепляться за термины, но понимать, что существуют разные парадигмы.
Модели с общим состоянием: «чередование операций» и «произошло до»
В своей статье Морис Херлихи (автор книги The Art Of Multiprocessor programming) пишет, что конкурентная система содержит коллекцию последовательных процессов (в теоретических трудах означает то же самое, что и поток), которые коммуницируют через общую память.
Модель с общим состоянием включает в себя вычисления с передачей сообщений, где разделяемое состояние это очередь сообщений и вычисления с разделяемой памятью, где общим состоянием являются структуры в памяти.
Каждое из вычислений можно моделировать.
В основе модели лежит конечный автомат. Модель фокусируется исключительно на разделяемом состоянии и полностью игнорируется локальные данные каждого из потоков. Каждое действие потоков над разделяемом состоянием является функцией перехода в новое состояние.
Так например, если 4 потока записывают данные в разделяемую переменную, то будет 4 функции перехода в новое состояние. Какая из этих функций будет применена, зависит от хронологии событий в системе.
Вычисления с передачей сообщений моделируются похожим образом, только состояние и функции перехода зависят от посылки или приема сообщений.
Если модель показалась вам сложной, то в примере мы исправим это. Она действительно очень проста и интуитивно понятна. Настолько, что не зная про существование этой модели, большинство людей все равно будут анализировать программу как предполагает модель.
Такую модель называют — модель исполнения через чередование операций (название услышал в докладе Романа Елизарова).
В плюсы модели можно смело записывать интуитивность и естественность. В дебри можно уходить по ключевым словам Sequential consistency и работе Лесли Лэмпорта.
Однако есть важное уточнение насчет данной модели. Модель имеет ограничение, что все действия над разделяемым состоянием должны быть моментальными и при этом действия не могут происходить одновременно. Говорят, что такая система имеет линейный порядок — все действия в системе упорядочены.
На практике такого не происходит. Операция не происходит моментально, а выполняется в интервале, на многоядерных системах эти интервалы могут пересекаться. Конечно это не означает, что модель бесполезна на практике, просто нужно создать определенные условия для ее использования.
А пока рассмотрим другую модель — «произошло до», которая фокусируется не на состоянии, а на множестве операций чтения и записи ячеек памяти во время исполнения (истории) и их отношениях.
Модель говорит, что события в разных потоках проходят не мгновенно и атомарно, а параллельно, и не возможно выстроить порядок между ними. События (запись и чтение разделяемых данных) в потоках на многопроцессорной или многоядерной архитектуре происходят действительно параллельно. В системе отсутствует понятие глобального времени, мы не можем понять когда закончилась одна операция и началась другая.
На практике это означает, что мы можем в одном потоке записать в переменную значение и сделать это, скажем утром, и прочитать из этой переменной значение в другом потоке вечером, и мы не можем сказать, что мы точно прочитаем значение записанное утром. В теории эти операции проходят параллельно и не ясно когда закончится одна и начнется другая операция.
Это трудно вообразить, как так получается, что простые операции чтения и записи сделанные в разное время суток проходят одновременно. Но если задуматься, то нам действительно не важно время когда происходят события записи и чтения, если мы не можем гарантировать, что мы увидим результат записи.
А мы действительно можем не увидеть результат записи, т.е. в переменную значение которой является 0 в потоке P мы записываем 1, а в потоке Q читаем эту переменную. Неважно сколько пройдет физического времени после записи, мы все равно можем прочитать 0.
Так работают компьютеры и модель это отражает.
Модель совсем абстрактная и для удобной работы нуждается в визуализации. Для визуализации и только для нее используется модель с глобальным временем, с оговорками, что при доказательстве свойств программ глобальное время не используется. В визуализации каждое событие представляется в виде интервала с началом и окончанием.
События проходят параллельно, как мы выяснили. Но все таки система имеет частичный порядок, так как есть особые пары событий, которые имеют порядок, в таком случае говорят, что эти события имеют отношение «произошло до». Если вы впервые слышите про отношение «произошло до», то наверное знание факта, что это отношение как бы упорядочивает события вам мало поможет.
Пробуем анализировать Java программу
Какой-то теоретический минимум мы рассмотрели, давайте попробуем двинуться дальше и рассмотрим многопоточную программу на конкретном языке — Java, из двух потоков с общим изменяемым состоянием.
Классический пример.
private static int x = 0, y = 0;
private static int a = 0, b = 0;
synchronized (this) {
a = 0;
b = 0;
x = 0;
y = 0;
}
Thread p = new Thread(() -> {
a = 1;
x = b;
});
Thread q = new Thread(() -> {
b = 1;
y = a;
});
p.start();
q.start();
p.join();
q.join();
System.out.println("x=" + x + ", y=" + y);
Нам нужно смоделировать исполнения этой программы и получить все возможные результаты — значения переменных x и y. Результатов будет несколько, как мы помним из теории, такая программа является недетерминированной.
Как будем моделировать? Сразу хочется воспользоваться моделью чередования операций. Но модель «произошло до» говорит нам, что события в одном потоке параллельны событиям из другого потока. Поэтому модель чередования операций тут не уместна, если между операциями нет отношения «произошло до».
Результат выполнения каждого потока всегда детерминирован, так как события в одном потоке всегда упорядочены, считайте, что они получают отношение «произошло до» даром. Но как события в разных потоках могут получить отношение «произошло до» не совсем очевидно. Конечно же, это отношение формализовано в модели, вся модель написана математическим языком. Но что с этим делать на практике, в конкретном языке, сразу не разобрать.
Какие есть варианты?
Проигнорировать ограничения и моделировать чередованием. Попробовать то можно, возможно ничего страшного не случится.
Чтобы понять какие результаты можно получить просто сделаем перебор всех возможных вариантов исполнения.
Все возможные исполнения программы можно представить в виде конечного автомата.
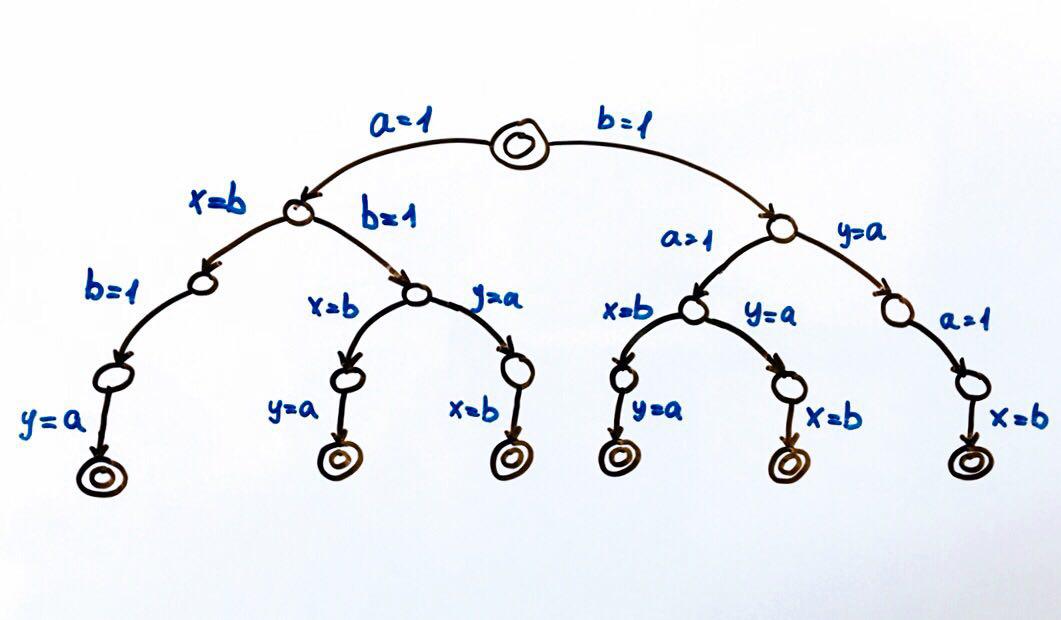
Каждый круг это состояние системы, в нашем случае переменные a, b, x, y. Функция перехода это действие над состоянием, которое переводит систему в новое состояние. Так как над общим состоянием могут совершать действия два потока, то и перехода из каждого состояния будет два. Двойные круги это конечные и начальное состояния системы.
Всего возможно 6 различных исполнений, которые в результате дают пары значений x, y: (1, 1), (1, 0), (0, 1)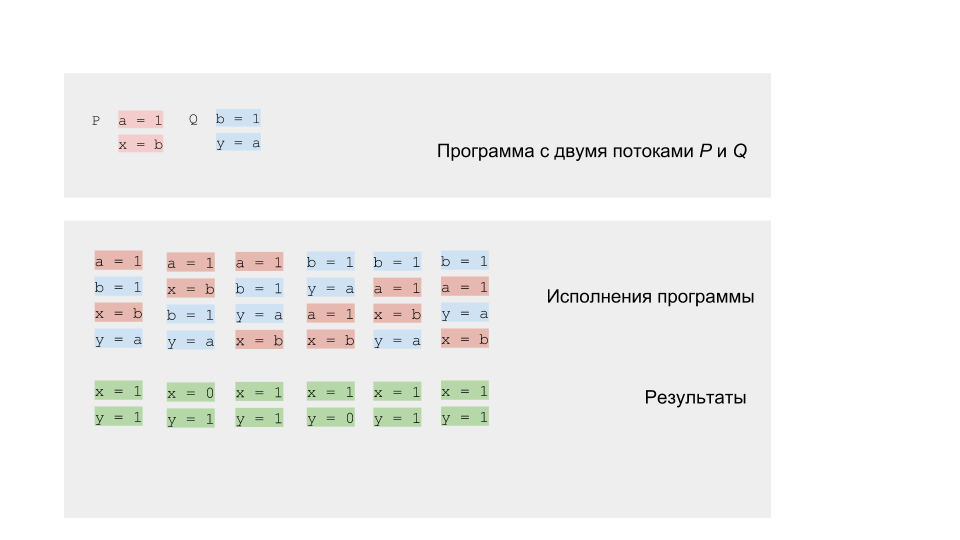
Можем запустить программу и проверить результаты. Как и полагается конкурентной программе, она будет иметь недетерминированный результат.
Для тестирования конкурентных программ лучше использовать специальные инструменты (инструмент, доклад).
Но можно попробовать запускать программу несколько миллионов раз, а еще лучше написать цикл, который это сделает за нас.
Если мы запустим код на одноядерной или однопроцессорной архитектуре, то мы должны получить результат из набора, который ожидаем. Модель чередования будет прекрасно работать. На многоядерной архитектуре, например x86, нас может ждать сюрприз — мы можем получить результат (0,0), которого не может быть согласно нашему моделированию.
Объяснение этому можно поискать в интернете по ключевому слову — reordering. Сейчас важно понять, что моделирование чередованием действительно не подходит в ситуации, когда мы не можем определить порядок доступа к разделяемому состоянию.
Теория конкурентного программирования и JMM
Пришло время рассмотреть подробнее отношение «произошло до» и как это дружит с JMM. Оригинальное определение отношения «произошло до» можно найти в документе Time, Clocks, and the Ordering of Events in a Distributed System.
Модель памяти языка помогает в написании конкурентного кода, так как определяет какие операции имеют отношение «произошло до». Список таких операций представлен в спецификации в разделе Happens-before Order. Фактически этот раздел отвечает на вопрос — при каких условиях мы увидим результат записи в другом потоке.
В JMM есть различные порядки. Очень бодро про порядки рассказывает Алексей Шипилёв в одном из своих докладов.
В модели с глобальным временем все операции в одном потоке имеют порядок. Например, события записи и чтения переменной, можно представить как два интервала, тогда модель нам гарантирует, что в рамках одного потока эти интервалы никогда не пересекутся. В JMM такой порядок называется — Program Order (PO).
PO связывает действия в одном потоке и ничего не говорит о порядке исполнения, говорит только о порядке в исходном коде. Этого вполне достаточно, чтобы гарантировать детерминизм для каждого потока в отдельности. PO можно рассматривать как исходные данные. PO всегда просто расставить в программе — все операции (линейный порядок) в исходном коде в рамках одного потока будут иметь PO.
В нашем примере получится примерно следующее:
P: a = 1 PO x = b — запись в a и чтение b имеет PO порядокQ: b = 1 PO y = a — запись в b и чтение a имеет PO порядок
Подсмотрел такую форму записи w (a, 1) PO r (b): 0. Очень надеюсь, что ее никто не запатентовал для докладов. Впрочем в спецификации есть похожая форма.
Но каждый поток в отдельности нам не особо интересен, так как у потоков есть общее состояние, нас больше интересует взаимодействие потоков. Все чего мы хотим — это быть уверенными в том, что мы увидим запись переменных в других потоках.
Напомню, у нас это не получалось, потому что операции записи и чтения переменных в разных потоках не мгновенные (это отрезки, которые пересекаются), соответственно разобрать где начало и конец операций невозможно.
Идея простая — в момент, когда мы читаем переменную a в потоке Q, запись этой самой переменной в потоке P могла еще не закончиться. И не важно сколько физического времени разделяют эти события — наносекунда или несколько часов.
Чтобы упорядочить события нам нужно отношение «произошло до». JMM определяет такое отношение. В спецификации закреплен порядок в одном потоке:
Если операция x и y проходят в одном потоке и в PO сначала происходит x, а потом y, тогда x произошло до y.
Забегая вперед, можно сказать, что мы можем заменить все PO на Happens-before (HB):
P: w(a, 1) HB r(b)
Q: w(b, 1) HB r(a)
Но снова мы вертимся в рамках одного потока. HB возможно между операциями, происходящими в разных потоках, чтобы разобраться с этими случаями познакомимся с другими порядками.
Synchronization Order (SO) — связывает Synchronization Actions (SA), полный список SA приведен в спецификации, в разделе 17.4.2. Actions. Вот некоторые из них:
- Чтение volatile переменной
- Запись volatile переменной
- Lock монитора
- Unlock монитора
SO нам интересен, так как обладает свойством, что все чтения в SO порядке видят последние записи в SO. А я напомню, мы только этого и добиваемся.
На этом месте я еще раз повторю чего мы добиваемся. У нас есть многопоточная программа, мы хотим смоделировать все возможные исполнения и получить все результаты, которые она может дать. Есть модели, которые позволяют это сделать достаточно просто. Но они требуют, чтобы все действия над разделяемым состоянием были упорядочены.
Согласно свойству SO — если все действия в программе будут SA тогда мы добьемся своего. Т.е. мы можем расставить для всех переменных модификатор volatile и можем использовать модель чередований. Если интуиция подсказывает вам, что так делать не стоит, то вы абсолютно правы. Этими действиями мы просто запретим оптимизации над кодом, конечно иногда это хороший вариант, но это точно не общий случай.
Рассмотрим еще один порядок Synchronizes-With Order (SW) — SO для конкретных пар unlock/lock, запись/чтение volatile. Не важно в каких потоках будут эти действия, главное чтобы они были над одним монитором, volatile переменной. SW дает «мостик» между потоками.
И вот теперь мы подошли к самому интересному порядку — Happens-before (HB).
HB является транзитивным замыканием объединений SW и PO. PO дает линейный порядок внутри потока, а SW «мостик» между потоками. HB транзитивно, т.е. если
x HB y и y HB z, тогда x HB y
В спецификации есть список HB отношений, с ним можно подробнее ознакомиться, вот некоторые из списка:
В рамках одного поток любая операция happens-before любой операцией следующей за ней в исходном коде.
Выход из synchronized блока/метода happens-before вход в synchronized блок/метод на том же мониторе.
Запись volatile поля happens-before чтение того же самого volatile поля.
Вернемся к нашему примеру:
P: a = 1 PO x = b
Q: b = 1 PO y = a
Вернемся к нашему примеру и попробуем проанализировать программу, с учетом порядков.
Анализ программы с помощью JMM основывается на выдвижении каких-либо гипотез и их подтверждения или опровержения.
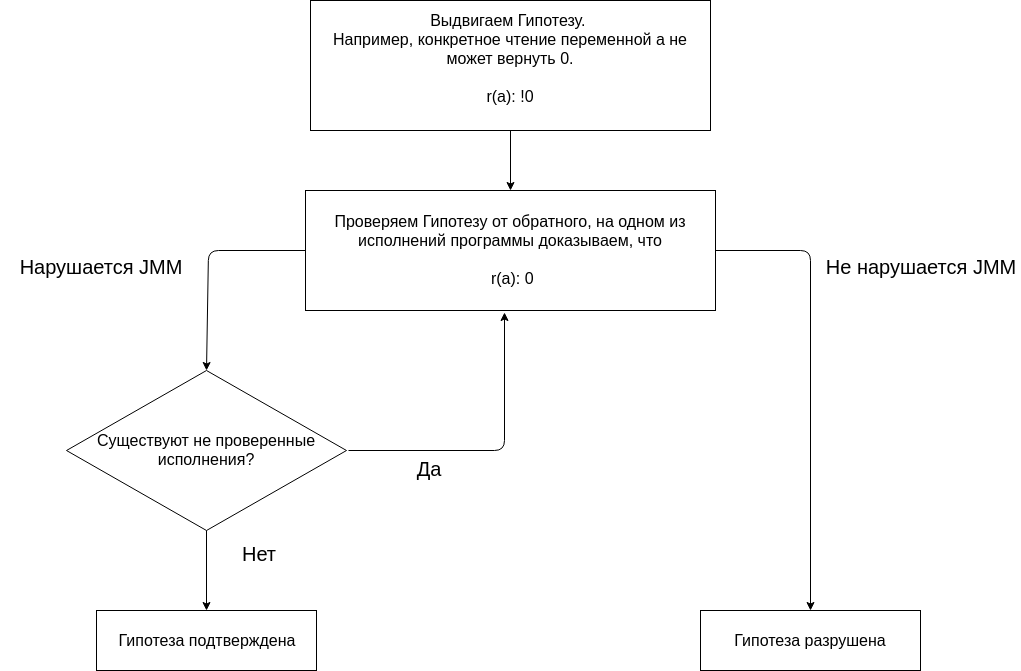
Анализ начнем с выдвижения гипотезы, что ни одно исполнение программы не дает результат (0, 0). Отсутствие результата (0, 0) на всех исполнения это предполагаемое свойство программы.
Проверяем гипотезу, строя разные исполнения.
Номенклатуру подсмотрел здесь (иногда встречается вместо … слово race со стрелочкой, сам Алексей использует в докладах стрелочку и слово race, но предупреждает, что такого порядка нет в JMM и использует такое обозначение для ясности).
Сделаем небольшую оговорку.
Так как нам важны все действия над общими переменными, а в примере общие переменные — a, b, x, y. Тогда, например, операцию x = b нужно рассматривать, как r (b) и w (x, b), причем r(b) HB w(x,b) (исходя из PO). Но так как переменная x в потоках нигде не читается (чтение в print в конце кода не интересно, так как после операции join на потоке мы увидим значение x), то можно не рассматривать действие w (x, b).
Проверяем первое исполнение.
w(a, 1) HB r(b): 0 … w(b, 1) HB r(a): 0
В потоке Q читаем переменную a, записываем в эту переменную в потоке P. Между записью и чтением нет никакого порядка (PO, SW, HB).
Если запись переменной происходит в одном потоке, а чтение в другом потоке и при этом между операциями нет отношения HB, то говорят, что чтение переменной происходит под гонкой. А под гонкой согласно JMM мы можем прочитать либо последнее записанное значение в HB, либо любое другое значение.
Такое исполнение возможно. Исполнение не нарушает JMM. При чтении переменной a, можно увидеть любое значение, так как чтение происходит под гонкой и нет гарантии, что увидим действие w (a, 1). Это не означает, что программа работает корректно, просто означает, что такой результат ожидаем.
Рассматривать остальные исполнения смысла нет, так как гипотеза уже разрушена.
JMM говорит, что если программа не имеет гонок данных, тогда все выполнения можно рассматривать как последовательные. Давайте избавимся от гонки, для этого нам нужно упорядочить операциями чтения и записи в разных потоках. Тут важно понимать, что многопоточная программа, в отличие от последовательной, имеет несколько исполнений. И чтобы говорить, что программа имеет какое-либо свойство, то требуется доказать, что это свойство программа имеет не на одном из исполнений, а на всех исполнениях.
Чтобы доказать, что программа без гонок, нужно это сделать для всех исполнений. Давайте попробуем сделать SA и отметим переменную a модификатором volatile. Volatile переменные будем помечать префиксом v.
Выдвигаем новую гипотезу. Если переменную a сделать volatile, то ни одно исполнение программы не даст результат (0, 0).
w(va, 1) HB r(b): 0 … w(b, 1) HB r(va): 0
Исполнение не нарушает JMM. Чтение va происходит под гонкой. Любая гонка разрушает транзитивность HB.
Выдвигаем еще гипотезу. Если переменную b сделать volatile, то ни одно исполнение программы не даст результат (0, 0).
w(a, 1) HB r(vb): 0 … w(vb, 1) HB r(a): 0
Исполнение не нарушает JMM. Чтение a происходит под гонкой.
Давайте проверим гипотезу, что если переменные a и b volatile, то ни одно исполнение программы не даст результат (0, 0).
Проверяем первое исполнение.
w(va, 1) SO r(vb): 0 SO w(vb, 1) SO r(va): 0
Так как все действия в программе SA (конкретно чтение или запись volatile переменной), то мы получаем полный SO порядок между всеми действиями. Это означает, что r (va) должно увидеть w (va, 1). Данное исполнение нарушает JMM.
Нужно переходить к следующему исполнению, чтобы подтвердить гипотезу. Но так как при любом исполнении будет SO, можно отступиться от формализма — очевидно, что результат (0, 0) при любом исполнении нарушает JMM.
Чтобы использовать модель чередования нужно добавить volatile для переменных a и b. Такая программа даст результаты (1,1), (1,0) или (0,1).
В итоге можно сказать, что очень простые программы достаточно просто анализировать.
Но сложные программы с большим количеством исполнений и разделяемых данных, анализировать достаточно сложно, так как нужно проверять все исполнения.
Другие модели конкурентного выполнения
Зачем рассматривать другие модели конкурентного программирования?
С помощью потоков и примитивов синхронизации можно решить все проблемы. Это все действительно так, но проблема в том, что мы рассмотрели пример из десятка строк кода, где полезную работу делают 4 строчки кода.
И столкнулись там с кучей вопросов, вплоть до того, что мы без спецификации даже все возможные результаты правильно посчитать не смогли. Потоки и примитивы синхронизации это очень непростая вещь, использование которой безусловно оправдана в некоторых случаях. В основном эти случаи связаны с производительностью.
Извините, что много ссылаюсь на Елизарова, но что поделать, если человек действительно имеет опыт в этой области. Так вот, у него есть еще один замечательный доклад «Миллионы котировок в секунду на чистой Java», в котором он говорит, что неизменяемое состояние это хорошо, но свои миллионы котировок копировать в каждый поток, извините, не буду. Но не у всех миллионы котировок, у многих конечно же задачи скромнее. Есть ли модели конкурентного программирования, которые позволяют забыть про JMM и все равно писать безопасный конкурентный код?
Если вам действительно очень интересен этот вопрос, очень рекомендую книгу Пола Батчера «Семь моделей конкуренции за семь недель. Раскрываем тайны потоков». К сожалению про автора найти достаточно информации не удалось, но книга должна открыть вам глаза на новые парадигмы. У меня, к сожалению, нет опыта работы с многими другими моделями конкуренции, так что обзор я получил именно из этой книги.
Отвечая на вопрос выше. Насколько я понимаю, существуют модели конкурентного программирования, которые позволяют как минимум сильно уменьшить необходимость знания нюансов JMM. Однако, если есть изменяемое состояние и потоки, то какие абстракции над ними не наворачивай, все равно останется место, где эти потоки должны синхронизировать доступ к состоянию. Другой вопрос, что самому синхронизировать доступ возможно не придется, за это может отвечать фреймворк, например. Но как мы уже говорили, рано или поздно абстракция может протечь.
Можно исключить изменяемое состояние совсем. В мире функционального программирования это нормальная практика. Если нет мутабельных структур, то вероятно, проблем с разделяемой памятью тоже не будет по определению. На JVM есть представители функциональных языков, например Clojure. Clojure является гибридным функциональным языком, так как все таки позволяет менять структуры данных, но предоставляет для этого более эффективные и безопасные инструменты.
Функциональные языки отличный инструмент для работы с конкурентным кодом. Лично я не использую его, потому что моя сфера деятельности это мобильная разработка, а там это просто не является мейнстримом. Хотя определенные подходы можно перенять.
Другой способ работать с изменяемыми данными — это исключить совместное использование данных. Такой моделью программирования являются акторы. Акторы упрощают программирование, за счет того что не допускают одновременный доступ к данным. Это достигается путем того, что функция, которая выполняет работу в один момент времени может работать только в одном потоке.
Однако, актор может изменить внутреннее состояние. Учитывая, что в следующий момент времени, этот же актор может выполняться на другом потоке, то это может быть проблемой. Проблему можно решать по разному, в таких языках программирования, как Erlang или Elixir, где модель акторов является неотъемлемой частью языка, можно использовать рекурсию для вызова актора с новым состоянием.
В Java рекурсии могут обойтись слишком дорого. Впрочем в Java существуют фреймворки для удобной работы с этой моделью, самый популярный наверное Akka. Разработчики Akka обо всем позаботились, можно перейти в раздел документации Akka and the Java Memory Model и прочитать про два случая, когда может возникнуть доступ из разных потоков к разделяемому состоянию. Но что более важно, в документации написано какие события имеют отношение «произошло до». Т.е. это означает, что мы можем изменять состояние актора сколько угодно, но когда мы примем следующее сообщение и возможно обработаем его в другом потоке, то мы гарантированно увидим все изменения, сделанные в другом потоке.
Почему так популярна модель с потоками?
Мы рассмотрели две модели конкурентного программирования, на самом деле их еще больше, которые делают конкурентное программирование более простым и безопасным.
Но почему тогда все еще так популярны потоки и блокировки?
Мне кажется причина в простоте подхода, конечно с одной стороны с потоками легко допустить много неочевидных ошибок, прострелить себе ногу и т.д. Но с другой стороны в потоках сложного ничего нет, особенно если не думать о последствиях.
В один момент времени ядро может выполнять одну инструкцию (на самом деле нет, параллелизм существует на уровне инструкций, но сейчас это не важно), но благодаря многозадачности даже на одноядерных машинах одновременно (конечно псевдо одновременно) может выполняться сразу нескольких программ.
Для того чтобы многозадачность работала нужна конкуренция. Как мы уже разобрались конкуренция невозможно без нескольких потоков управления.
Как вы думаете сколько потоков нужно программе, которая работает на четырехъядерном процессоре мобильного телефона, чтобы быть максимально быстрой и отзывчивой?
Их может быть несколько десятков. Теперь вопрос, зачем нужно столько потоков программе, которая работает на железе позволяющем выполнять всего 2–4 потока одновременно?
Чтобы попытаться ответить на этот вопрос, предположим, что на устройстве выполняется только наша программа и больше ничего. Как бы мы распорядились предоставленными нам ресурсами?
Можно одно ядро отдать для пользовательского интерфейса, остальные ядра для любых других задач. Если один из потоков заблокируется, например, поток может обратиться к контроллеру памяти и ждать ответа, то мы получим заблокированное ядро.
Какие технологии есть для решения проблемы?
В Java есть потоки, мы можем создать множество потоков, и тогда другие потоки смогут выполнять операции пока какой-то поток заблокирован. Имея такой инструмент, как потоки, мы можем упростить себе жизнь.
Подход с потоками не бесплатный, создание потоков обычно занимает время (решается пулами потоков), под них выделяется память, переключение между потоками — дорогая операция. Но с ними относительно легко программировать, поэтому это массовая технология, которая так широко используется в языках общего назначения, например Java.
В Java вообще любят потоки, не обязательно создавать на каждое действие по потоку, там есть более высокоуровневые вещи, такие как Executors, которые позволяют работать с пулами и писать более масштабируемый и гибкий код. Потоки это действительно удобно, можно сделать блокирующий запрос в сеть и следующей строкой написать обработку результата. Даже если мы будем ждать результат несколько секунд, то все равно сможем выполнять другие задачи, так как операционная система позаботится о распределении процессорного времени между потоками.
Потоки популярны не только в бэкенд разработке, в мобильной разработке считается вполне нормально создавать десятками потоки, чтобы можно было заблокировать поток на пару секунд, дожидаясь загрузки данных по сети или данных от сокета.
Языки вроде Erlang или Clojure пока ещё остаются нишевыми, и соответственно модели конкурентного программирования, которые они используют не так популярны. Однако, прогнозы для них самые оптимистичные.
Выводы
Если вы разрабатывает на платформе JVM, то вам нужно принять правила игры, обозначенные платформой. Только так можно писать нормальный многопоточный код. Очень желательно понимать контекст всего происходящего, так будет проще принять правила игры. Еще лучше осмотреться по сторонам и ознакомиться с другими парадигмами, хоть с подводной лодки никуда не деться, но открыть для себя новые подходы и инструменты можно.
Дополнительные материалы
Я старался размещать в тексте статьи ссылки на источники из которых черпал информацию.
В целом материал по JMM легко найти в интернете. Здесь я размещу ссылки на некоторый дополнительный материал, который связан с JMM и возможно не сразу попадается на глаза.
Чтение
- Блог Алексея Шипилёва — знаю, что очевидно, но просто грех не упомянуть
- Блог Черемина Руслана — последнее время не пишет активно, нужно искать в блоге его старые записи, поверьте это стоит того — там кладезь
- Хабр Глеба Смирнова — есть отличные статьи про многопоточность и модель памяти
- Блог Романа Елизарова — заброшен, но археологические раскопки провести нужно. В целом Роман очень много сделал для просветления народа в области теории многопоточного программирования, ищите его в медиа.
Подкасты
Выпуски, которые мне показались особенно интересными. Они не про JMM, они про Ад, которые творится в железе. Но после их прослушивания, хочется целовать руки создателям JMM, которые оградили нас от этого всего.
Видео
Кроме выступлений вышеупомянутых людей обратите внимание на академическое видео.
