[Из песочницы] Основы Serverless приложений в среде Amazon Web Services
 День добрый, дорогие Хабра-пользователи!
День добрый, дорогие Хабра-пользователи! Сегодня хотелось бы поговорить об активно набирающей обороты технологии в мире ИТ — об одной из облачных технологий, а именно — о бессерверной архитектуре приложений (БСА — Serverless). В последнее время облачные технологии набирают все большую популярность. Это происходит по простой причине — лёгкой доступности, относительной дешевизны и отсутствию начального капитала — как знаний для поддержания и развёртывания инфраструктуры, так и денежного характера.
Технология Serverless становится все более и более популярна, но почему-то очень мало освещается в ИТ индустрии, в отличие от других облачных технологий, таких как IaaS, DBaaS, PaaS.
Для написания статьи я использовал AWS (Amazon Web Services) как, бесспорно, самый большой и продуманный сервис (исходя из анализа Gartner’s за 2015 год).

На сегодня нам понадобится:
- AWS аккаунт (для тестов и минимальной разработки хватит и Free — tier);
- Платформа для разработки (я предпочитаю Linux — Fedora, но можно использовать любую дистрибуцию, поддерживающую Node не менее 4.3 и NPM);
- Serverless Framework 1.* Beta — Об этом фреймворке я расскажу поподробнее в отдельной главе (https://github.com/serverless/serverless)
Ну, что — начнём с азов.
Serverless — в чём основа популярности
Serverless — бессерверная архитектура приложений. На самом деле, не такая уж она и бессерверная. Основу архитектуры составляют микросервисы, или функции (lambda), выполняющие определённую задачу и запускаемые на логических контейнерах, спрятанных от посторонних глаз. Т.е. конечному пользователю дан только интерфейс загрузки кода функции (сервиса) и возможность подключения к этой функции источников событий (events).
Рассматривая на примере сервиса Амазона, источником событий может быть множество тех же сервисов Амазона:
- S3 хранилище может генерировать множество событий на практически любых операциях, таких как добавление, удаление и редактирование файлов в бакетах.
- RDS и DynamoDB — более того, Dynamo позволяет генерировать события на добавлении или изменении данных в таблице.
- Cloudwatch — система на подобии cron.
- И, самое для нас интересное — API Gateways. Это программный эмулятор HTTP протокола, позволяющий абстрагировать запросы до единичного события микросервиса.
Схематично работу микросервиса можно представить таким образом:
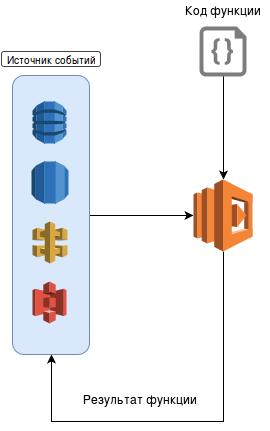 В действительности же, как только вы загружаете код функции в Амазон, он сохраняется в качестве пакета на внутреннем файловом сервере (наподобие S3). В момент получения первого события, Амазон автоматически запускает мини-контейнер с определенным интерпретатором (или виртуальной машиной, в случае JAVA) и запускает полученный код, подставляя сформированное тело события в качестве аргумента. Как понятно из принципа микросервисов, каждая такая функция не может иметь состояния (stateless), так как доступа к контейнеру нет, и время его существования ничем не определено. Благодаря этому качеству микросервисы могут беспрепятственно горизонтально расти в зависимости от количества запросов и нагрузки. На самом деле, исходя из практики, балансирование ресурсов в Амазоне выполнено довольно-таки неплохо и функция достаточно быстро «плодится» даже при скачкообразных повышениях нагрузки.
В действительности же, как только вы загружаете код функции в Амазон, он сохраняется в качестве пакета на внутреннем файловом сервере (наподобие S3). В момент получения первого события, Амазон автоматически запускает мини-контейнер с определенным интерпретатором (или виртуальной машиной, в случае JAVA) и запускает полученный код, подставляя сформированное тело события в качестве аргумента. Как понятно из принципа микросервисов, каждая такая функция не может иметь состояния (stateless), так как доступа к контейнеру нет, и время его существования ничем не определено. Благодаря этому качеству микросервисы могут беспрепятственно горизонтально расти в зависимости от количества запросов и нагрузки. На самом деле, исходя из практики, балансирование ресурсов в Амазоне выполнено довольно-таки неплохо и функция достаточно быстро «плодится» даже при скачкообразных повышениях нагрузки.
С другой стороны, еще одно преимущество такого stateless запуска заключается в том, что оплату за использование сервиса, как правило, можно производить, основываясь на времени выполнения конкретной функции. Столь удобный способ оплаты — в англоязычной литературе Pay-as-you-go — даёт возможность запускать стартапы или иные проекты без начального капитала. Ведь необходимости выкупать хостинг для размещения кода — нет. Оплату можно производить пропорционально использованию сервиса (что так же гибко позволяет рассчитать необходимую монетизацию вашего сервиса).
Таким образом, плюсы подобной архитектуры — это:
- Отсутствие аппаратной части — серверов;
- Отсутствие прямого контактирования и администрирования серверной части;
- Практически безграничный горизонтальный рост вашего проекта;
- Оплата за использованное время ЦПУ.
К минусам же можно отнести:
- Отсутствие чёткого контроля контейнера (вы никогда не знаете, где и как они запускаются, кто имеет доступ) — что нередко может вызывать паранойю.
- Отсутствие «целостности» приложения: каждая функция — это независимый объект, что часто приводит к некой разбросанности приложения и затруднениям сложить все воедино.
- Холодный старт контейнера оставляет желать лучшего (как минимум, в Амазоне). Первый запуск контейнера с лямбда функцией частенько может притормозить на 2–3 секунды, что не всегда хорошо воспринимается пользователями.
В общем и целом у технологии есть свой сегмент спроса и свой рынок потребителей. Я же нахожу технологию весьма подходящей для начального этапа стартапов, начиная от простейших блогов, заканчивая онлайн играми и не только. Особый упор в данном случае ставится на независимость от серверной инфраструктуры и безграничный прирост производительности в автоматическом режиме.
Serverless Framework
Как было упомянуто выше, одним из минусов БСА является разрозненность приложения и весьма тяжёлый контроль всех необходимых компонентов — таких, как события, код, роли и политики безопасности. Должен сказать, что в проектах чуть сложнее, чем Hello World, регламентирование всех перечисленных компонентов — огромная головная боль. И не редко приводит к отказу сервисов при очередном обновлении.
Чтобы избежать этой проблемы, хорошие люди написали очень полезную утилиту с одноимённым названием — Serverless. Данный фреймворк заточен сугубо для использования в AWS инфраструктуре (и, хотя 0.5 ветка версий была полностью заточена под NodeJS, большим плюсом стало перенаправление ветки 1.* в сторону всех поддерживаемых AWS языков). В дальнейшем речь пойдёт о ветке 1.*, так как, на мой взгляд, её структура более логична и гибка в использовании. Более того, в версии 1 было вычищено большинство мусора и добавлена поддержка Java и Python.
В чем же полезность данного решения? Ответ очень прост — Serverless Framework концентрирует в себе всю необходимую инфраструктуру проекта, а именно: контроль кода, тестирование, создание и контролирование ресурсов, ролей и политик безопасности. И так все это в одном месте, и может быть запросто добавлено в git для контроля версий.
Прочитав базовые инструкции по установке фреймворка и его настройке, вам, наверняка, уже удалось его установить, но дабы сохранить полезность статьи для начинающих, позвольте мне перечислить необходимые этапы. Дочитав до этого местя я надеюсь у вас под рукой уже консоль с Centos, так что начнём наше знакомство с установки NPM/Node (т.к. пакет serverless, все же, написан на NodeJS).
Этап первый
Я предпочитаю NVM для контроля версий ноды:
curl https://raw.githubusercontent.com/creationix/nvm/v0.31.6/install.sh | bash
Этап второй
Перегружаем профиль, как указано в конце инсталяции:
. ~/.bashrc
Этап третий
Теперь устанавливаем сборку Node/NPM — (в примере я использую 4.4.5, так как попросту она была под рукой)
nvm install v4.4.5
Этап четвёртый
После успешной установки пришло время настроить доступ к AWS — в рамках этой статьи я пропущу этап настройки конкретного AWS аккаунта для разработки и его роли — детальную инструкцию можно найти в мануалах фреймворка.
Этап пятый
Обычно для использования ключа AWS достаточно добавить 2 переменные окружения:
export AWS_ACCESS_KEY_ID=
export AWS_SECRET_ACCESS_KEY=
Этап шестой
Предположим, что аккаунт установлен и настроен (Прошу обратить внимание, что для SLS фреймворка необходим уровень доступа администратора к AWS ресурсам — в противном случае, можно часами пытаться разобраться, почему все работает не так, как хотелось).
Этап седьмой
Устанавливаем Serverless в глобальном режиме:
npm install -g serverless@beta
Прошу обратить внимание, что без указания beta версии, вы наверняка установили бы 0.5 ветку. На сегодняшний день 0.5 и 1.0 различны, как небо и земля, поэтому инструкции для 1.0 на версии 0.5 работать попросту не будут.
Этап восьмой
Создаём директорию проекта. И, на данном этапе — небольшое отступление об архитектуре проекта.
Архитектура Serverless проекта
Давайте перейдём теперь к тому, каким образом лямбда функцию можно загрузить в Амазон. А именно, способов этих два:
- Через веб консоль — простым копи-пастом. Способ весьма прост и удобен для односложной функции с простейшим кодом. К сожалению, таким способом в функции нельзя включить сторонних библиотек (о списке библиотек, поддерживаемых лямбда функциями, можно прочитать в документации Амазона, но, как правило, это языковой пакет из коробки и AWS SKD — не более, не менее).
- Через AWS SKD можно залить пакет функции. Это обычный zip архив, имеющий в себе все необходимые файлы и библиотеки (в данном случае, существует ограничение на максимальный размер архива в 50Мб). Не стоит забывать, что лямбда — это Микросервис, и заливать весь программный пакет в одну функцию не имеет никакого смысла. Так как оплата за функцию идёт по времени выполнения кода — так что, не забывайте оптимизировать.
В нашем случае, Serverless использует второй способ — т.е он подготавливает существующий проект и создаёт из него необходимый zip пакет. Ниже я приведу пример проекта для NodeJS, в остальном эту же логику не трудно будет применить и для остальных языков.
Функция
|__ lib // Внутренние библиотеки
|__ handler.js // Точка входа в функцию
|__ serverless.env.yaml // Переменные окружения
|__ serverless.yml // Центральная конфигурация проекта
|__ node_modules // Сторонние модули
|__ package.json
Очень не хотелось бы перегружать статью, но, к сожалению, документация по конфигурации фреймворка весьма неполна и разрознена, поэтому я бы хотел привести пример из своей практики по настройке. Вся конфигурация сервиса находится в serverless.yml файле с такой структурой:
service: Название сервисаprovider:
name: aws
runtime: nodejs4.3
iamRoleStatement:
$ref: ../custom_iam_role.json #JSON файл, описывающий IAM роль для наших функций. http://docs.aws.amazon.com/IAM/latest/UserGuide/id_roles_create_policy-examples.html. В данном JSON файле нужно оставить только массив Statements
vpc: #Дефолтные настройки VPC (на случай, если вам необходимо организовать доступ лямбда функции в вашу VPC сеть)
securityGroupIds:
- securityGroupId1
subnetIds:
- subnetId1
stage: dev #Название этапа (по сути, произвольная строка, имеющая для вас какое-то значение)
region: us-west-2 # Регион Амазона
package: #Описание пакета
includee: #Важный момент – фреймворк, по умолчанию, включает в пакет только один файл, а именно – центральную точку доступа (handler). В случае, если вы хотите включить дополнительные каталоги, их необходимо указать ниже.
- lib
- node_module # И да, как я писал ранее, Амазон не предоставляет никаких возможностей подгрузить сторонние модули автоматически – так что их необходимо включать в пакет.
exclude: # В случае, если указаны только исключения, фреймворк включит все, кроме этого списка.
- tmp
- .git
functions: #В этой части идет перечисление функций. Пусть вас не смущает двойственность понятий – в данном случае функция подразумевает лямбда функцию в Амазоне. В то время, как весь проект называется Сервисом. Любопытно то, что каждая новая функция, по сути, будет создавать свой отдельный пакет и совершенно отдельную lambda функцию в Амазоне.
hello:
name: hello #Название лямбда функции
handler: handler.hello # Путь до точки входа
MemorySize: 512 # Объем памяти
timeout: 10 # Таймаут
events: # Ниже перечислены события, на которые функция будет реагировать
- s3: bucketName
- schedule: rate(10 minutes)
- http:
path: users/create
method: get
cors: true
- sns: topic-name
vpc: # Кастомная настройка VPC для конкретной функции
securityGroupIds:
- securityGroupId1
- securityGroupId2
subnetIds:
- subnetId1
- subnetId2
resources:
Resources:
$ref: ../custom_resources.json # JSON файл, перечисляющий ресурсы.
По большей части, данный файл конфигурации очень сильно напоминает конфигурацию CloudFormation Сервиса Амазона — об этом я напишу, возможно, в следующей статье. Но вкратце — это сервис контроля всех ресурсов в вашем аккаунте Амазона. Serverless полностью полагается на этот сервис, и, обычно, если во время установки функции возникает непонятная ошибка, то можно найти детальную информацию об ошибке на странице консоли CloudFormation.
Я хотел бы заметить одну немаловажную деталь по поводу проекта Serverless — вы не можете включить директории и файлы, находящиеся выше по дереву каталогов, нежели директория проекта. А точнее — …/lib сделать не получится.
Теперь у нас есть конфигурация, перейдём к самой функции.
Этап девятый
Cоздаём проект с дефолтной конфигурацией
sls create —template aws-nodejs
После этой команды вы увидите структуру проекта — похожую на выше описанную.
Этап десятый
Сама функция находится в файле handler.js. Принципы написания функции можно почитать в документации Амазона. Но в общих чертах, точка доступа — это функция с тремя аргументами:
- event — объект события. Этот объект содержит все данные о событии, вызвавшем функцию. В случае с AWS API Gateway этот объект будет содержать HTTP запрос (на самом деле, Serverless устанавливает дефолтный маппер HTTP запроса в API Gateway, поэтому пользователю нет необходимости, как бы то ни было, настраивать его самому, что очень удобно для большинства проектов).
- Context — объект, содержащий текущее состояние окружения — такую информацию, как АРН текущей функции и, иногда, информацию об авторизации. Хочу напомнить, что для новой версии NodeJS 4.3 Amazon Lambda результат функции должен быть возвращен через callBack, нежели context (e.g. {done, succeed, fail})
- Callback — функция формата callback (Error, Data), возвращающая результат событию.
Для примера попробуем создать простейшую Hello World функцию:
exports.hello = function(event, context, callback) {
callback({'Hello':'World', 'event': event});
}
Этап одиннадцатый
Загрузка!
sls deploy
Обычно, эта команда займёт время на запаковку проекта, подготовку функций и окружения в самом AWS. Но, по окончанию, Serverless вернёт ARN и Endpoint, по которым можно будет увидеть результат.
В качестве заключения
Несмотря на то, что в статье были освещены всего лишь азы использования Serverless технологии, на практике же спектр применения этой технологии практически безграничен. От простых порталов (выполненных, как статичная страница при помощи React или Angular) c бэкендом и логикой на лямбда функциях — до процессинга архивов или файлов через S3 хранилище и достаточно сложных математических операций с распределением нагрузки. На мой взгляд, технология ещё в самом начале ее зарождения, и наверняка будет развиваться и далее. Так что, берём клавиатуру в руки и идём пробовать и тестировать (благо Amazon Free Tier позволяет это сделать совершенно бесплатно на первых порах).
Благодарю всех за внимание — прошу поделиться своими впечатлениями и замечаниями в комментариях! И, надеюсь, статья вам понравится — в таком случае, продолжу цикл углубления в технологию.
Комментарии (2)
 el777
el777
6 сентября 2016 в 21:26
0↑
↓
А за пределами AWS это может работать?6 сентября 2016 в 21:35
0↑
↓
Если говорить о самом фреймворке — то нет, он заточен конкретно под AWS. Если же рассматривать сам принцип — то это от части aPaaS платформа с гораздо более расширенным функционалом — и да у нее есть аналоги такие как Google App Engine, Azure WebJobs или OpenSource hook.io.
Технически многие крупные Enterprise уровня компании иметь собственные аналоги для внутреннего использования.
