[Из песочницы] Оптимизация веб-сервиса подсказок для почтовых адресов и ФИО
Разработка, о которой идет речь в данной статье была выполнена в 2015 году, однако предпосылки к ней появились значительно раньше. Все началось с того, что в 2008-ом году у нас возникла идея разработать веб-сервис по стандартизации и исправлению пользовательских контактных данных, таких как почтовые адреса и номера телефонов. Веб-сервис должен был получать посредством REST API контактные данные, которые указал некий пользователь в произвольном текстовом виде, и приводить эти данные в порядок. По сути, сервис должен был решать задачу распознавания пользовательских контактных данных в произвольной текстовой строке. Дополнительно в ходе такой обработки сервис должен был исправлять опечатки в адресах, восстанавливать пропущенные компоненты адреса, а также приводить обработанные данные к структурированному виду. Сервис разрабатывался для нужд бизнес-пользователей, для которых корректность клиентских контактных данных является критичным фактором. В первую очередь это интернет-магазины, службы доставки, а также CRM и MDM системы больших организаций.
В вычислительном плане поставленная задача оказалась достаточно тяжелой, поскольку обработке подлежат неструктурированные текстовые данные. Поэтому вся обработка была реализована на C++, тогда как прикладная бизнес-логика была написана на Perl и оформлена в виде FastCGI-сервера.
Шесть лет данный сервис успешно работал, пока мы не столкнулись с новой задачей, заставившей нас пересмотреть архитектуру решения. Новая задача заключалась в формировании подсказок в режиме реального времени для вводимых пользователями почтовых адресов, фамилий, имен и отчеств.
Обработка в реальном времениФормирование подсказок в режиме реального времени подразумевает, что сервис получает от пользователя новый HTTP-запрос всякий раз, когда тот вводит очередной символ почтового адреса или ФИО в процессе заполнения некоторой формы с контактными данными. В рамках запроса сервис получает текстовую строку, введенную пользователем к настоящему моменту, анализирует ее и формирует несколько наиболее вероятных вариантов ее автодополнения. Пользователь видит полученные от сервиса подсказки и либо выбирает подходящий вариант, либо продолжает ввод. В реальности это должно выглядеть примерно следующим образом.

Данная задача отличается от стандартизации уже введенных контактных данных, на которую изначально был рассчитан сервис, тем, что один и тот же пользователь в ходе заполнения формы порождает на порядок большее число запросов. При этом скорость обработки этих запросов должна превышать скорость, с которой пользователь набирает вводимые данные на клавиатуре. В противном случае пользователь успеет ввести все данные вручную и никакие подсказки ему будут не нужны.
Для оценки приемлемого времени отклика мы провели ряд экспериментов с регулируемой задержкой. В результате чего пришли к выводу, что подсказки перестают быть полезными, когда время отклика начинает превышать 150 мс. Наша исходная архитектура сервиса позволяла оставаться в этих рамках при одновременной работе 40 пользователей (эти показатели получены для сервера с двумя ядрами и 8Гб ОЗУ). Для увеличения этого числа необходимо наращивать количество процессоров у серверного железа. А поскольку функции подсказок для почтовых адресов и ФИО разрабатывались для их свободного использования всеми желающими, мы понимали, что процессоров и серверов может потребоваться значительно больше. Поэтому возник вопрос о том, нельзя ли оптимизировать обработку запросов за счет изменения архитектуры сервиса.
Исходная архитектураАрхитектура сервиса, которую нужно было улучшить, имела следующий вид.
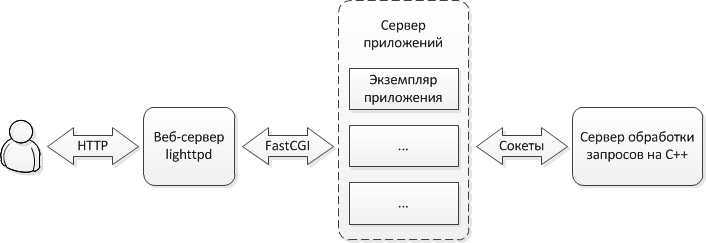
Согласно данной схеме, пользовательское приложение (например, веб-браузер), генерирует HTTP-запросы, которые получает веб-сервер (в нашем случае используется легковесный веб-сервер lighttpd). Если в запросах имеем дело не со статикой, то они транслируются серверу приложений, который соединен с веб-сервером посредством FastCGI интерфейса (в нашем случае сервер приложений написан на Perl). Если запросы касаются обработки контактных данных, то они передаются дальше серверу обработки. Для взаимодействия с сервером обработки используются сокеты.
Можно заметить, что если в данной схеме заменить сервер обработки на сервер БД, то получится достаточно распространенная схема, применяемая в традиционных веб-приложениях, разрабатываемых с использованием популярных фреймворков для Python или Ruby, а также для PHP под управлением php_fpm.
Данная архитектура казалась весьма удачной, поскольку позволяет легко масштабировать сервис при увеличении нагрузки, для этого просто добавляются новые сервера обработки. Но поскольку производительность оставляла желать лучшего, было принято решение измерить время, которое тратит сервис на разных этапах обработки запроса. В результате получилась следующая диаграмма.
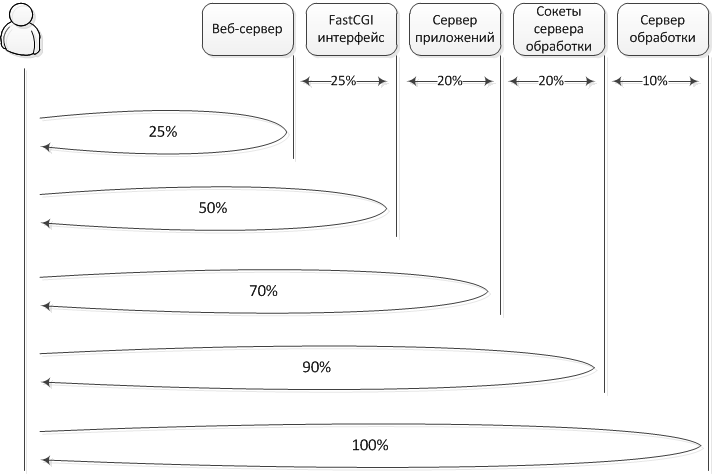
Данная иллюстрация показывает, сколько времени в процентном соотношении уходит от момента отправки запроса и до момента получения ответа веб-клиентом, в случае прохождения запроса через всю цепочку обработки или только какого-то ее фрагмента. При проведении данного эксперимента клиент и сервер размещались в одной локальной сети.
Например, первое число на диаграмме указывает на то, что 25% времени уходит на передачу запроса от веб-клиента, его прохождение через тракт веб-сервера и возврат веб-клиенту ответа. Аналогично все остальные стадии учитывают как прохождение запроса в прямом направлении, так и возврат ответа по той же цепочке в обратном направлении. А именно, при дальнейшем продвижении запроса, он поступает через FastCGI интерфейс на сервер приложений. На прохождение через этот интерфейс уходит еще 25% времени.
Далее запрос проходит через сервер приложений. На это тратится дополнительные 20% времени. В нашем случае никакой обработки запроса сервером приложений не выполняется. Приложение лишь выполняет парсинг HTTP-запроса, передает его дальше серверу обработки, получает от него ответ и передает его обратно FastCGI интерфейсу. Фактически 20% времени уходит на парсинг запроса и на издержки интерпретатора, поскольку приложение реализовано на скриптовом языке.
Еще 20% времени уходит на прохождение данных через сокетный интерфейс, который используется для связи приложения с сервером обработки. Этот интерфейс работает чуть быстрее, в сравнении с FastCGI (20% против 25%), поскольку соответствующий протокол и его реализация значительно проще. Обработка самого запроса, заключающаяся в формировании подсказок для введенных пользователем данных, отнимает лишь 10% от всего времени (в тестах использовался один из самых тяжелых, с точки зрения обработки, запросов).
Хотелось бы подчеркнуть, что вся специфика нашей задачи в проведенных экспериментах проявляется лишь на последней стадии и именно эта стадия, с точки зрения производительности, вызывает меньше всего вопросов. Остальные этапы весьма стандартны. Так, мы используем событийный веб-сервер, который просто извлекает полученный запрос из одного сокета, ассоциированного с прослушиваемым HTTP-портом, и кладет эти данные в FastCGI-сокет. Аналогично сервер приложений — извлекает данные из FastCGI-сокета и передает их сокету сервера обработки. В самом приложении оптимизировать по большому счету нечего.
Удручающая картина, при которой лишь 10% от времени отклика приходится на полезные действия, заставила нас задуматься о смене архитектуры.
Новая архитектура сервисаДля устранения издержек в исходной архитектуре необходимо в идеале избавиться от приложения на интерпретируемом языке, а также устранить сокетные интерфейсы. При этом необходимо сохранить возможность масштабирования сервиса. Мы рассматривали следующие варианты.
Событийный сервер приложений
В рамках данного варианта была рассмотрена возможность реализовать событийный сервер приложений, например, на Node.js или Twisted. В такой реализации количество сокетных интерфейсов, через которые проходят запросы, остается прежним, поскольку каждый запрос поступает на балансирующий веб-сервер, тот передает его одному из экземпляров сервера приложений, который в свою очередь транслирует запрос серверу обработки. Суммарное время обработки запроса остается прежним. Однако число одновременно обрабатываемых запросов увеличивается за счет асинхронного использования сокетов. Грубо говоря, пока один запрос находится в процессе перехода через сокетный интерфейс, другой запрос может проходить через бизнес-логику приложения в рамках того же экземпляра.
От данного варианта реализации пришлось отказаться, поскольку мы посчитали неоправданным реализацию полностью асинхронного приложения лишь ради устранения одного узкого места в старой архитектуре — сокетного интерфейса между приложением и сервером обработки. Остальные операции ввода-вывода, такие как журналирование, фиксация пользовательской статистики, рассылка почты и взаимодействие с другими сервисами в старом приложении выполнялись отложенно в отдельных потоках, поэтому асинхронности не требовали. Кроме того, данная архитектура не позволяет сократить время обработки единичного запроса, так что пользовательские приложения, работающие с сервисом через API, прироста в производительности не получат.
Интеграция приложения и веб-сервера
Здесь была рассмотрена реализация приложения в виде Java-сервлета или .Net приложения, который напрямую вызывается веб-сервером. В этом случае удается избавиться от FastCGI интерфейса, а заодно от интерпретируемого языка. Сокетный интерфейс с сервером обработки сохраняется.
На принятии решения не в пользу данного подхода сказалась привязка всего решения к конкретному веб-серверу, который должен поддерживать выбранную технологию. Например, Tomcat для Java-сервлетов или Microsoft IIS в случае использования .Net. Нам хотелось сохранить совместимость приложения с легковесными серверами lighttpd и nginx.
Интеграция приложения с сервером обработки
В данном случае привязки к конкретному веб-серверу нет, поскольку интерфейс FastCGI сохраняется. Приложение реализуется на C++ и объединяется с сервером обработки. Таким образом, мы уходим от использования интерпретируемого языка, а также устраняем сокетный интерфейс между приложением и сервером обработки.
К недостатку данного подхода можно отнести отсутствие достаточно популярного и обкатанного на больших проектах фреймворка. Из кандидатов мы рассматривали CppCMS, TreeFrog и Wt. По части первого у нас возникли опасения на счет будущей поддержки проекта ее разработчиками, поскольку свежих обновлений на сайте проекта давно не было. TreeFrog базируется на Qt. Эту библиотеку мы активно используем в офлайновых проектах, однако посчитали ее избыточной и недостаточно надежной для поставленной задачи. По части Wt — фреймворк имеет большой акцент на GUI, тогда как в нашем случае GUI — вещь второстепенная. Дополнительным фактором при отказе от использования этих фреймворков было желание минимизировать риски, связанные с использованием сторонних библиотек, без которых в принципе можно обойтись, поскольку в данном случае имела место переработка существующего работающего сервиса, который не хотелось сломать из-за недостаточно отлаженной сторонней библиотеки.
Вместе с тем, сам факт существования таких проектов натолкнул на мысль о том, что разработка веб-приложений на C++ дело не такое уж безнадежное. Поэтому было решено провести исследование имеющихся библиотек, которые можно было бы использовать при разработке веб-приложения на C++.
Имеющиеся библиотекиДля взаимодействия с веб-сервером приложение должно реализовывать один из поддерживаемых веб-сервером протоколов HTTP, FastCGI или SCGI. Мы остановились на FastCGI и его реализации в виде libfcgi.
Для парсинга HTTP-запросов и формирования HTTP-ответов нам подошла библиотека cgicc. Данная библиотека берет на себя все заботы по разбору HTTP-заголовков, извлечению параметров запроса, декодированию тела полученного сообщения, а также по формированию HTTP-ответа.
Для парсинга XML-запросов, которые могут приходить от пользователей сервиса в рамках REST API, был выбран Xerces.
В C++ нет поддержки юникода «из коробки», поэтому для работы с текстом было принято решение использовать стандартные STL-строки при условии обязательного соблюдения внутреннего соглашения, что все строковые данные всегда должны быть представлены в UTF-8.
Для взаимодействия с внешними сервисами и почтовыми серверами было решено использовать libcurl, а для генерации хешей — openssl.
Самописные компонентыДля генерации html-представлений нам нужен был несложный шаблонизатор. В старой реализации сервиса для этих целей использовался HTML: Template, поэтому при переходе на C++ нужен был шаблонизатор с похожим синтаксисом и похожими возможностями. Мы попробовали поработать с CTPP, Clearsilver и Google-ctemplate.
CTPP оказался неудобным в использовании, поскольку перед использованием шаблона его необходимо перегонять в бинарный код, а затем создавать виртуальную машину, которая его выполнит. Все эти сложности делают код неоправданно громоздким.
У Clearsilver весь интерфейс реализован на чистом C и для его использования потребовалось писать внушительную объектную обертку. Ну, а Google-ctemplate не покрывал все возможности HTML: Template, которые использовались в старой версии сервиса. Для его полноценного использования потребовалось бы менять логику, отвечающую за формирование представлений. Поэтому в случае с шаблонизатором пришлось разработать собственный велосипед, что и было сделано.
Разработка собственного C++ шаблонизатора отняла около трех дней, тогда как на поиск и изучение готовых решений, указанных выше, мы потратили вдвое больше времени. Кроме того, свой шаблонизатор позволил расширить синтаксис HTML: Template, добавив в него конструкцию «else if», а также операторы сравнения переменных с предопределенными в шаблоне значениями.
Управление сессиями пришлось также реализовать самостоятельно. Здесь сказалась специфика разрабатываемого сервиса, поскольку сессия в нашем случае хранит довольно много информации, отражающей поведение пользователя в реальном времени. Дело в том, что кроме обработки данных через REST API, простые пользователи часто обращаются к сервису как к справочной службе, например, когда требуется узнать почтовый индекс для заданного адреса. Время от времени среди пользователей появляются такие, которые решают автоматизировать стандартизацию имеющихся у них контактных данных путем разработки веб-бота, имитирующего работу человека в браузере, вместо того, чтобы использовать предназначенный для этого REST API. Такие боты создают бесполезную нагрузку на сервис, что сказывается на работе других пользователей. Для борьбы с ботами сервис в рамках сессий накапливает сведения, отражающие поведение пользователей. Эти сведения впоследствии используются отдельным модулем сервиса, отвечающим за распознавание ботов и их блокировку.
Пожалуй, ключевым стандартом, который нам пришлось реализовать самостоятельно, является JSON. На C++ есть довольно много его открытых реализаций, которые мы анализировали, прежде чем создавать еще одну. Основной причиной создания собственной реализации является использование JSON в связке с нестандартным аллокатором памяти, который использовался на сервере обработки для ускорения операций динамического выделения и высвобождения памяти. Данный аллокатор работает в 2–3 раза быстрее стандартного на массовых операциях выделения/высвобождения блоков небольшого размера. Поскольку работа с JSON укладывается в данный паттерн, мы хотели получить бесплатный прирост производительности на всех операциях, связанных с парсингом и построением JSON-объектов.
Итоговый результатАрхитектура итогового решения, которое у нас получилось, отображена на следующей схеме.
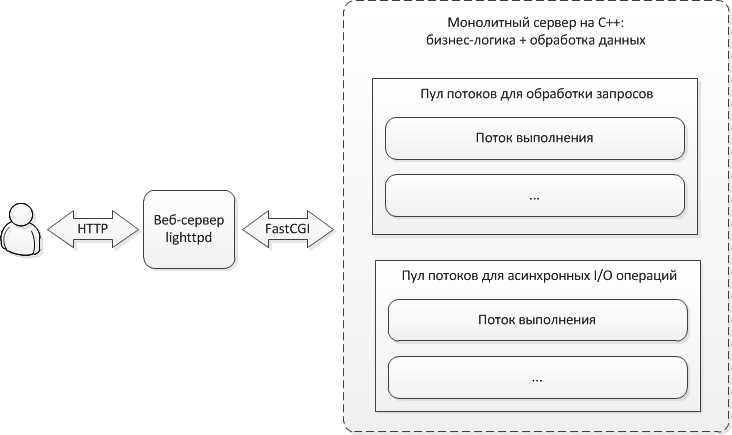
В рамках монолитного сервера объединена как логика приложения, так и сама обработка контактных данных. Для обработки входящих запросов на сервере предусмотрен пул потоков выполнения. Все операции ввода-вывода, которые требуется выполнить в ходе обработки API-запросов, делаются отложенно. Для этих целей на сервере создается отдельный пул потоков, отвечающих за выполнение асинхронного ввода-вывода. К таким операциям относится, например, обновление статистики пользователя, а также списание денег, в случае использования платных функций API. В обоих случаях нужно делать запись в БД, выполнение которой в основном потоке привело бы к его блокированию.
Данная архитектура позволяет масштабировать сервис за счет запуска дополнительных экземпляров монолитного сервера, в этом случае веб-сервер наделяется дополнительной ролью балансировщика.
Согласно диаграмме, приведенной ранее, при переходе на новую архитектуру время отклика сервиса при обработке одиночного запроса должно было сократиться примерно на 40%. Реальные эксперименты показали, что сокращение произошло на 43%. Это можно объяснить тем, что монолитное решение стало более эффективно использовать оперативную память.
Мы также провели нагрузочное тестирование для определения числа пользователей, которых новый сервис может обслуживать при одновременном использовании подсказок, обеспечивая при этом время отклика не выше 150 мс. В таком режиме сервис смог обеспечивать одновременную работу 120 пользователей. Напомню, что для старой реализации это значение составляло 40. В данном случае трехкратный прирост производительности объясняется сокращением общего числа процессов, принимающих участие в обслуживании потока запросов. Раньше запросы обрабатывались несколькими экземплярами приложения (в экспериментах число экземпляров варьировалось от 5 до 20), тогда как в новой версии сервиса все запросы обрабатываются в рамках одного многопоточного процесса. В то время как каждый экземпляр работает с собственной обособленной памятью, все вместе они конкурируют за один процессорный кэш, использование которого становится менее эффективным. В случае одного монолитного процесса такой конкуренции нет.
ЗаключениеВ данной статье был рассмотрен нестандартный подход к разработке веб-сервисов, когда требуется обеспечить обработку запросов в режиме реального времени. На примере задачи по формированию подсказок продемонстрирована необычная для веб-сервисов ситуация, когда увеличение времени отклика делает функционал сервиса фактически бесполезным для пользователя. Пример показывает, что появление такого рода требований может привести к существенным изменениям в архитектуре.
Для улучшения производительности нам пришлось объединить сервер приложений и сервер обработки данных в единый монолитный сервер, реализованный на C++. Такое решение уменьшило вдвое время отклика при обработке одиночных запросов, а также увеличило производительность сервиса в три раза при массовом использовании.
Кроме решения основной задачи приятными бонусами к проделанной работе стало упрощение рефакторинга, поскольку строгая типизация позволяет не напрягаться по поводу переименований в коде, т.к. проект просто не соберется в случае ошибок. Также получившийся проект стало легче сопровождать в целом, поскольку мы имеем единственный сервер, у которого бизнес-логика и логика обработки данных написана на одном языке.
Комментарии (4)
 ufadiz
ufadiz
1 июля 2016 в 23:49
0↑
↓
Глупый вопрос может быть, а почему не использовали кэширование запросов? или просто всю бд не засунули в тот же тарантул, где на lua написали бы скрипты для запросов2 июля 2016 в 11:19
0↑
↓
В старой архитектуре кэш был реализован на стороне сервера обработки. Там сконцентрированы все вычисления и работа с данными, поэтому там можно было кэшировать не просто ответы, но также результаты промежуточных вычислений. Но описанную в статье проблему этот кэш не решал, т.к. задержки возникали не доходя до него. Нужно было организовывать еще один кэш на стороне приложения или веб-сервера, но этого мы делать не стали, т.к. посчитали, что кэшировать в двух местах фактически одни и те же данные — достаточно дорого по ресурсам.
По поводу перехода на lua, если бы мы разрабатывали с нуля новый сервис, то у нас было бы больше вариантов для выбора архитектуры. Здесь же имел место рефакторинг унаследованного сервиса, у которого именно алгоритмическая часть, отвечающая за обработку данных, уже была оптимизирована (для этого в старой архитектуре вся эта обработка была оформлена в виде сервера на С++). Всю эту реализацию хотелось не переписывать заново, а аккуратно перенести в новую архитектуру.
2 июля 2016 в 07:28
+4↑
↓
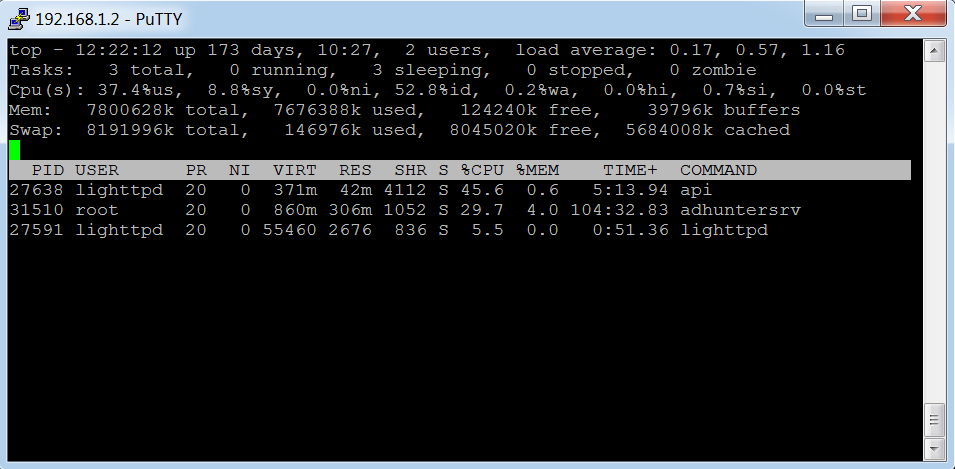
С++ имеет смысл использовать только если доказано, что приложение значительное время проводит вычисляя что-то процессором. Если команда top не показывает, что ваш процесс сервера приложений забирает хотя бы 10–20% процессорного времени, то значит ваш процесс большей частью что-то ждет, и смысла в С++ нет. Скорее всего минимизация количества компонентов (и TCP-коммуникаций между ними) и дала весь прирост скорости.2 июля 2016 в 11:57
0↑
↓
На скриншоте вывел загрузку процессора для приложения, сервера обработки и вебсервера при потоке запросов от одного пользователя.
Процесс «api» — это приложение, «lighttpd» — это вер-сервер.
Сервер обработки запущен от root, просьба не пинать за это, т.к. он запущен по-быстрому чисто для теста.
На картинке видно, что приложение отъедает 45,6% CPU.