[Из песочницы] Обработка естественного языка в задаче мониторинга предвыборной агитации
В данной статье мы рассмотрим процесс разработки методики контроля предвыборной агитации в Ростовском региональном сегменте Интернет-СМИ с использованием обработки естественного языка и машинного обучения.Также я остановлюсь на особенностях и нюансах, ведь задача стояла довольно специализированная: необходимо было выделять агитацию, и, если она может нарушать закон — оперативно уведомлять Избирком. Забегая вперед скажу, что с задачей я успешно справился.В задаче разработки методики контроля предвыборной агитации в Ростовском региональном сегменте Интернет-СМИ применяются наработки из нескольких смежных областей знаний:
автоматизированная обработка текстов (текстмайнинг), обработка естественного языка, машинное обучение. При создании электронных архивов документов агитационных публикаций Интернет-СМИ встает задача упорядочения информационного массива, когда документы, близкие по определенным содержательным критериям, объединяются в группы, называемые категориями, рубриками, тематическими подборками, кластерами, сюжетами и т.п.Интеллектуальной системой проведен мониторинг предвыборной агитации в Ростовском региональном сегменте Интернет-СМИ в период выборов депутатов законодательного собрания Ростовской области пятого созыва [1].Система автоматически находила и скачивала электронные публикации с сайтов региональных СМИ. После этого производилась интеллектуальная обработка текстовых массивов по специально разработанному алгоритму. Алгоритм, используя лингвистические атрибуты, которые идентифицируют агитационные публикации, начислял каждой публикации баллы. Публикация, содержащая агитацию за или против кандидата, имеет балл не менее 10. Публикация, содержащая агитацию за или против кандидата и потенциально нарушающая действующий закон, имеет балл не менее 20.Отчеты формировались системой ежедневно. Отчет содержался в файле xlsx и открывается в любой программе, работающей с электронными таблицами.
Основной результат работы автоматизированной системы классификации таков: система не обнаружила агитационных публикаций в Ростовском региональном сегменте Интернет-СМИ, размещенных кандидатами и избирательными объединениями, участвующими в выборах депутатов Законодательного Собрания Ростовской области от 08.09.2013. За отчетный период показатели системы мониторинга следующие:
Количество ресурсов СМИ: 60 Количество кандидатов в депутаты: 1161 Общее количество проанализированных публикаций: более 5000 Количество найденных подозрительных публикаций за все время проведения мониторинга, которые могут потенциально нарушать законодательство: 5 Количество найденных публикаций, достоверно нарушающих законодательство о выборах: 0 Для разработки методики интеллектуальной обработки данных на естественном языке для целей контроля предвыборной агитации в Ростовском региональном сегменте Интернет-СМИ ставится следующая задача классификации с применением машинного обучения дедуктивным способом:
Имеется множество категорий (классов, меток) 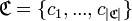 . При обработке публикаций СМИ с текстами агитационной тематики выделяется четыре класса:
. При обработке публикаций СМИ с текстами агитационной тематики выделяется четыре класса:
Агитационная публикация, нарушающая законодательство
Агитационная публикация, не нарушающая законодательство
Информационная публикация не являющаяся агитационной
Публикация, для которой не определен класс (ошибка определения)
Имеется множество документов, набор тестируемых публикаций Интернет-СМИ, для которых необходимо определить класс 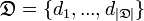 . Неизвестная целевая функция
. Неизвестная целевая функция 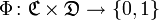 . Необходимо построить классификатор
. Необходимо построить классификатор 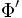 , максимально близкий к
, максимально близкий к  .Имеется некоторая начальная коллекция размеченных документов
.Имеется некоторая начальная коллекция размеченных документов 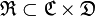 , для которых известны значения — набор достоверно агитационных публикаций. Коллекция делится на «обучающую» и «проверочную» части. Первая используется для обучения классификатора, вторая — для независимой проверки качества его работы.Классификатор может выдавать точный ответ
, для которых известны значения — набор достоверно агитационных публикаций. Коллекция делится на «обучающую» и «проверочную» части. Первая используется для обучения классификатора, вторая — для независимой проверки качества его работы.Классификатор может выдавать точный ответ 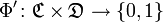 или степень подобия . Степенью подобия является процент верно классифицированных документов.Для обработки «обучающей» выборки был выбран так называемый «наивный» (упрощенный) алгоритм Байеса. С точки зрения быстроты обучения, стабильности на различных данных и простоты реализации, «наивный» алгоритм Байеса превосходит практически все известные эффективные алгоритмы классификации [3].
или степень подобия . Степенью подобия является процент верно классифицированных документов.Для обработки «обучающей» выборки был выбран так называемый «наивный» (упрощенный) алгоритм Байеса. С точки зрения быстроты обучения, стабильности на различных данных и простоты реализации, «наивный» алгоритм Байеса превосходит практически все известные эффективные алгоритмы классификации [3].
Обучение алгоритма производится путем определения относительных частот значений всех атрибутов входных данных при фиксированных значениях атрибутов класса. Классификация осуществляется путем применения правила Байеса для вычисления условной вероятности каждого класса для вектора входных атрибутов. Входной вектор приписывается классу, условная вероятность которого при данном значении входных атрибутов максимальна. «Наивность» алгоритма заключается в предположении, что входные атрибуты условно (для каждого значения класса) независимы друг от друга. Это предположение является очень сильным, и, во многих случаях неправомерным, что делает факт эффективности классификации при помощи «наивного» алгоритма Байеса довольно неожиданным.
Достоинством наивного байесовского классификатора является малое количество данных для обучения, необходимых для оценки параметров, требуемых для классификации.В основе NBC (Naïve Bayes Classifier) лежит теорема Байеса.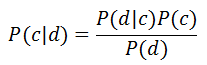 где,
где,
P (c|d) — вероятность, что документ d принадлежит классу c, именно её нам надо рассчитать;
P (d|c) — вероятность встретить документ d среди всех документов класса c;
P (c) — безусловная вероятность встретить документ класса c в корпусе документов;
P (d) — безусловная вероятность документа d в корпусе документов.
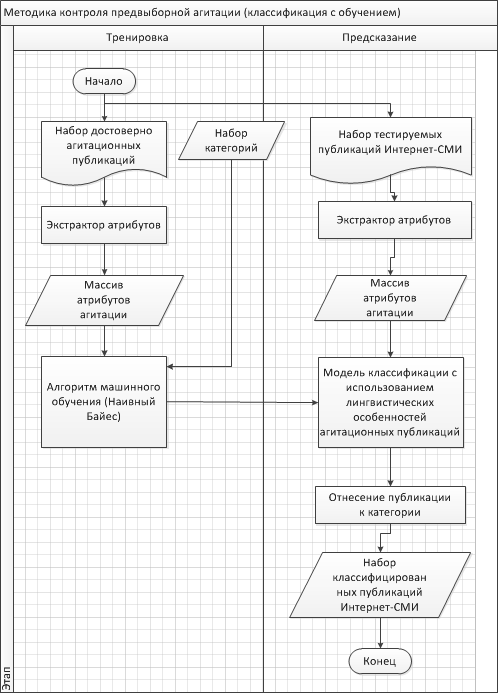 Рисунок 1. Модель методики контроля агитацииРисунок 1 иллюстрирует алгоритм и модель методики контроля предвыборной агитации, реализующей машинное обучение Наивным Байесовским классификатором и специально разработанную лингвистическую модель агитационной публикации, дополняющую и уточняющую результат, выдаваемый им.
Рисунок 1. Модель методики контроля агитацииРисунок 1 иллюстрирует алгоритм и модель методики контроля предвыборной агитации, реализующей машинное обучение Наивным Байесовским классификатором и специально разработанную лингвистическую модель агитационной публикации, дополняющую и уточняющую результат, выдаваемый им.
Рассмотрим этапы работы модели.
1. Индексация документов. На первом этапе производится автоматизированный сбор публикаций Интернет-СМИ и накопление их в СУБД для последующей обработки.2. Построение и обучение классификатора.
2.1 Тренировка. Из массива достоверно агитационных публикаций выделяется массив атрибутов агитации. Наивный Байесовский классификатор позволяет выявить наиболее информативные атрибуты и модифицировать их для учета контекста.
2.2 Предсказание. В процессе «предсказания» набору тестируемых публикаций Интернет-СМИ ставится в соответствие массив атрибутов. В процессе решения научно-исследовательской задачи создания методики контроля предвыборной агитации в Ростовском региональном сегменте Интернет-СМИ разработана лингвистическая модель агитационных публикаций. Модель дополняет результаты работы модуля машинного обучения на тренировочном наборе агитационных публикаций, добавляя к оценке специальные лингвистические атрибуты предвыборной агитации и правила, описанные ниже [5].
3. Оценка качества классификации. В результате методика обеспечивает получение на выходе качественно размеченного массива публикаций Интернет-СМИ.
Рассмотрим программную составляющую комплекса средств контроля предвыборной агитации в Ростовском региональном сегменте Интернет-СМИ. Он использует набор следующих библиотек:
библиотека обработки естественного языка Natural Language Toolkit (NLTK) [2] библиотека для обработки регулярных выражений (re) корпус достоверно агитационных материалов (materials) библиотека случайных величин (random) Регулярные выражения (РВ) это, по существу, крошечный язык программирования, встроенный в язык Python и доступный при помощи модуля re. Используя его, указываются правила для множества возможных строк, которые необходимо проверить; это множество может содержать слова, фразы, цифры, или адреса электронной почты. Также используется возможность с помощью регулярных выражений изменять строку или разбивать ее на части для автоматической обработки длинных списков кандидатов и партий. В результате работы автоматического классификатора Байеса был получен набор специальных языковых конструкций (паттернов) в виде биграм (двоек слов).
Программный комплекс средств контроля предвыборной агитации в Ростовском региональном сегменте Интернет-СМИ также включает в себя функцию просмотра наиболее информативных атрибутов. На листинге 1 показано 5 таких атрибутов (здесь и далее представлены фрагменты программного кода). По каждому атрибуту доступна частотная характеристика, показывающая, насколько тот или иной атрибут «успешен» в определении агитационного текста. Например, если в тексте найдена комбинация фамилии кандидата и любая форма слова «голосуйте», классификатор приходит к выводу, что данный текст имеет вероятность почти 26 шансов к одному оказаться агитационным (в процентом выражении 96,1%).
classifier.show_most_informative_features (5)
Most Informative Features suffix (4) = ('Бессонов', 'голосуйте') agitacia: ne_agitacia = 25.9: 1.0 suffix (4) = ('Стенякина', 'призываю') agitacia: ne_agitacia = 17.0: 1.0 suffix (2) = ('смейте', 'фальсифицировать') agitacia: ne_agitacia= 11.5: 1.0 suffix (1) = ('голосовать', 'против') ne_agitacia: agitacia = 6.3: 1.0 suffix (2) = ('коррупция', 'бичом') ne_agitacia: agitacia = 4.4: 1.0 Листинг 1. Результат работы классификатора Байеса: найдены двойки слов и соответствующая им вероятность агитации.
Стоит подробнее рассмотреть результаты автоматического классификатора, чтобы понять, способен ли он комплексно решить задачу выявления четырех перечисленных ранее в постановке задачи классов: агитация без нарушений, агитация с нарушением закона, информационная публикация. После анализа результаты работы классификатора, было выявлено, что он неплохо справляется с задачей отделения агитационных публикаций от информационных, то есть тех, в которых описывается работа тех или иных должностных лиц, события или выступления на докладах и конференциях. При этом основная задача мониторинга состоит в том, чтобы выявлять публикации с агитацией, потенциально нарушающие законодательство, и эта задача более сложная. С этой задачей автоматика классификатора Байеса справляется недостаточно хорошо: основная причина заключается в сложности конструкций русского языка, а также в наличии эмоционально окрашенных фраз, метафор, аллегорий, намеков, которые часто используются в агитационных текстах. Таким образом, точность определения того, присутствует ли нарушение закона необходимо повысить с помощью дополнительных атрибутов.
В результате научного исследования была разработана лингвистическая модель предвыборной агитации, осуществляемой в период избирательной кампании. Каждый из лингвистических атрибутов модели входит в нее с весовым коэффициентом, отражающим важность того или иного лингвистического конструкта. Таким образом, модель представляет собой сумму произведений, многочлен n-ой степени, по числу атрибутов:
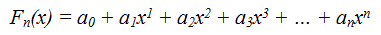
или в сокращенном виде:
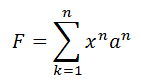
где an — фиксированные коэффициенты (баллы) важности атрибута, x — переменная, сколько раз в тексте встречается комбинация агитационных лингвистических атрибутов.
В модель входит набор специальных атрибутов, являющихся лингвистическими конструкциями, которые автоматически находятся разработанным программно-аппаратным комплексом [1]:
призывы голосовать за кандидата, кандидатов, список, списки кандидатов либо против него (них); выражение предпочтения какому-либо кандидату, избирательному объединению, в частности указание на то, за какого кандидата, за какой список кандидатов, за какое избирательное объединение будет голосовать избиратель (за исключением случая опубликования (обнародования) результатов опроса общественного мнения); описание возможных последствий в случае, если тот или иной кандидат будет избран или не будет избран, тот или иной список кандидатов будет допущен или не будет допущен к распределению депутатских мандатов; распространение информации, в которой явно преобладают сведения о каком-либо кандидате (каких-либо кандидатах), избирательном объединении в сочетании с позитивными либо негативными комментариями; распространение информации о деятельности кандидата, не связанной с его профессиональной деятельностью или исполнением им своих служебных (должностных) обязанностей; деятельность, способствующая созданию положительного или отрицательного отношения избирателей к кандидату, избирательному объединению, выдвинувшему кандидата, список кандидатов. пометка об оплате материала в Интернет-СМИ. Основой модели является полный набор потенциальных кандидатов, фамилии которых будут встречаться в агитационном тексте в именительном или ином падеже. Здесь и далее, для краткого описания встречающейся фамилии будет применяться обозначение, для партии .В программной реализации базовое упоминание кандидатов и партий реализовано следующим образом:
if re.search (re.compile ('\b (?:%s)\b' + '|'.join (map (re.escape, kandidats_all))), corpus.raw (fileid)): dict_features[fileid]['Упоминание кандидата'] = 10 else: dict_features[fileid]['Упоминание кандидата'] = 0
if re.search (re.compile ('\b (?:%s)\b' + '|'.join (map (re.escape, partii_all))), corpus.raw (fileid)): dict_features[fileid]['Упоминание партии'] = 1 else: dict_features[fileid]['Упоминание партии'] = 0 Листинг 2. Фрагмент программной функции: поиск упоминания кандидатов и партий.Особенностью модели является балльная система: каждой публикации за каждый специальный атрибут, найденный в тексте назначается определенное количество баллов an. Например, если в тексте встречается упоминание кандидата, публикация сразу получает 10 баллов в качестве порогового значения. Если же в публикации находится и упоминание Законодательного собрания, общее количество баллов составляет 12. Таким образом, по количеству баллов легко судить о потенциальной вероятности найти нарушение законодательства в публикации: если публикация набрала менее 10 баллов, это с высокой долей вероятности свидетельствует о том, что она информационная, в ней присутствуют атрибуты политических текстов, но вклад каждого атрибута не велик: 1 или 2 балла. В случае, если публикация набирает более 12 баллов, следует более внимательно проанализировать ее содержание, так как помимо фамилии кандидата в ней также содержатся атрибуты агитации. Практически гарантированно агитационными признавались публикации, имевшие 17 и более баллов, однако в каждой из них система обнаруживала ссылки и указание на соблюдение законодательства о выборах в Законодательное собрание Ростовской области.
Опишем продуктивные модели тактик, применяемых в агитационных текстах, а также перечислим наиболее частые специальные лингвистические конструкты, реализующие данные тактики, которые были реализованы в программном коде классификатора [4]: Лингвистический конструкт «самопрезентация». Употребление фольклорных элементов языка — поговорок «трудом праведным не наживешь палат каменных», «подарки любят отдарки», «дар дара ждет» — демонстрируют общность кандидата с аудиторией (простым народом), умение мыслить так же, как она, говорить одним языком.Лингвистический конструкт «мотивация». Популярен ход: меня (как и избирателей) не устраивает status quo. Я намерен это изменить следующим образом: 1) В Думу иду, потому что она должна измениться. 2) Потому что там должны появиться люди, которые поднимут трудные вопросы, заставят думу работать на общество…«Лингвистический конструкт «обещание». Данный лингвистический конструкт позволяет автоматически находить «обещания» в текстах. В комбинации с набором фамилий потенциальных кандидатов использование конструкта выглядит так: < обещаю, возьмусь, намерен(а), буду, гарантирую, клянусь > + <фамилия>Лингвистический конструкт «привлечение авторитета». «Авторитетное мнение» — мощный инструмент воздействия на аудиторию. В роли авторитета (влиятельного, уважаемого лица — [6, с. 15]) выступают личности, ко мнению которых «объект воздействия» прислушивается. Данный лингвистический конструкт позволяет автоматически находить конструкции поддержки и лоббирования в текстах.Лингвистический конструкт «оскорбление». Стратегия дискредитации — это так называемые «стратегии «на понижение». Она направлена на политических конкурентов и используется для разрушения положительного образа или акцентирования имеющегося отрицательного образа «оппонента».Лингвистический конструкт «законность агитации». Специальные атрибуты используются, чтобы проверять автоматически факт оплаты публикации в СМИ. Основными маркерами являются упоминания Законодательного собрания в различных фондах и указание на то, из каких источников производилась оплата за публикацию, листинг 4.
if re.search (r'(Оплачено из средств избирательного фонда)|(зарегистрированн[а-яА-Я][а-яА-Я][а-яА-Я] кандидат[а-яА-Я] в депутат[а-яА-Я])', corpus.raw (fileid), re.IGNORECASE): dict_features[fileid]['Источник оплаты'] = 2 else: dict_features[fileid]['Источник оплаты'] = 0
if re.search (r'(Законодательн[а-яА-Я][а-яА-Я][а-яА-Я] Собран[а-яА-Я][а-яА-Я])', corpus.raw (fileid), re.IGNORECASE): dict_features[fileid]['Упоминание Заксобрания'] = 2 else: dict_features[fileid]['Упоминание Заксобрания'] = 0 Листинг 4. Фрагмент программной функции: поиск упоминания факта оплаты.Лингвистический конструкт «метафорический образ». Как и в художественной речи, метафоризация в политическом дискурсе основана на аналогиях, здесь особенно характерны аналогии специфической тематики, связанные: с войной и борьбой (нанести удар, выиграть сражение), игрой (сделать ход, выиграть партию, поставить на карту, блефовать, приберегать козыри), спортом (перетягивать канат, получить нокаут, положить на обе лопатки), охотой (загонять в западню, наводить на ложный след), механизмом (рычаги власти), организмом (болезнь роста, ростки демократии, внутреннее оздоровление города), театром (играть главную роль, быть марионеткой, статистом, суфлером, выйти на авансцену) и др.
В агитматериалах можно увидеть «стандартный набор» метафор: «пошел по стопам того-то», «прошел всю карьерную лестницу», «необходимо поставить заслон…», «судьба города (страны…) в ваших руках». Данный лингвистический конструкт позволяет автоматически находить метафорические образы в текстах. В комбинации с набором фамилий потенциальных кандидатов использование конструкта выглядит так: < метафорический образ> + <фамилия>Лингвистический конструкт «ролевой миф». Универсальная основа политических текстов. Популярны роли: «борец», «покровитель», «слуга народа», «хозяин», «хозяйственник» и пр. Успешность хода во многом зависит от того, насколько удачно роль будет соответствовать ожиданиям аудитории. Пример: Алексей Хрусталев о борьбе с коррупцией знает не понаслышке. Он воюет с ней как редактор «Ростовской недели», как депутат городской Думы. Угрозы в его адрес звучали неоднократно. А недавно ему взорвали машину — для острастки. Но Алексей Хрусталев дезертиром не стал, он продолжает войну с коррупцией и ведет борьбу за победу на выборах в депутаты Законодательно собрания. Данный лингвистический конструкт позволяет автоматически находить «роли» кандидатов в агитационных текстах.
Основным выводом проводившегося мониторинга является констатация факта: в основном публикации содержали тексты выборной (или околовыборной) тематики, но не имели достаточного количества специальных лингвистических атрибутов. Публикации, набравшие максимальное количество баллов, как правило, являлись информационными. Они освещали работу того или иного кандидата на своем посту или содержали общую сводную информацию о выборах, статистике по выборам, партиям.
Программный комплекс контроля агитации работал в рекомендательном порядке, то есть оперативно уведомлял компетентные структуры о ситуации в Ростовском региональном сегменте Интернет-СМИ, обеспечивая соблюдение законности и порядка в сети в период проведения выборов депутатов Законодательного Собрания Ростовской области от 08.09.2013.
Вскоре мы запускаем стартап Графовый Грааль с кодовым слоганом «Большие данные» в интеллектуальном анализе социальных сетей». Если тема обработки естественного языка, графов и Больших данных вам интересна — добро пожаловать!
Литература
Федеральный закон от 12.06.2002 N 67-ФЗ (ред. от 07.05.2013) «Об основных гарантиях избирательных прав и права на участие в референдуме граждан Российской Федерации». Bird Steven. Natural Language Processing with Python. [Текст] — O’Reilly Media Inc, 2009. — ISBN 0–596–51649–5 Christopher D. Manning, Prabhakar Raghavan, Hinrich Schütze An Introduction to Information Retrieval Draft. [Текст] Cambridge University Press. — 2009. Коммуникативные стратегии и тактики агитационного текста и их стилистическая репрезентация, [Электронный ресурс] Автореферат, www.userdocs.ru/informatika/8383/index.html? page=5 Режим доступа: свободный. — Загл. с экрана. — Яз. рус. «Система автоматизированного построения графа социальной сети» Инженерный вестник Дона, 2012. №4. [Электронный ресурс] ivdon.ru/magazine/archive/n4p2y2012/1428 Режим доступа: свободный. — Загл. с экрана. — Яз. рус. Толковый словарь русского языка в 4-х тт. // под ред. Д.Н. Ушакова. — М., 2000.
