[Из песочницы] Multi-pattern matching на GPU миф или реальность

Немного лирики
В те давние времена, когда трава была зеленее и деревья были выше, я твёрдо верил, что такие страшные слова, как дивергенция потоков, cache missing, coalescing global memory accesses и прочие не позволяют эффективно реализовать задачу множественного поиска на GPU. Годы шли, уверенность не исчезала, но в один прекрасный момент я наткнулся на библиотеку PFAC. Если интересно, на что она способна — добро пожаловать под кат.
Зачем всё это
Зачем мы это делаем и что мы хотим получить? Самым интересным фактом является производительность библиотеки PFAC. Хочется получить высокую скорость работы, полученную за счёт использования GPU. Для сравнения будем использовать CPU и OpenMP реализации алгоритма PFAC.
Предполагаю, что читатель имеет некоторое представление об архитектуре CUDA. Если это пока еще не так, то с основными идеями можно ознакомиться в статьях, например здесь и здесь.
О библиотеке
Библиотека PFAC была разработана в 2012 году и адаптирована под архитектуры и возможности видеокарт того времени, поэтому, если у вас видеокарта с compute capability не выше 3.0, вы готовы поставить ubuntu 12.04 и cuda 4.2, то всё должно взлететь из коробки. Однако, мы не ищем лёгких путей и в данной статье мы будем работать с ubuntu 16.04 и cuda 9.0. В роли стенда для тестирования будет использоваться ноутбук с Intel Core i7–7500U, GeForce 940MX и 8 Гб RAM.
Прежде чем рваться в бой и считать гигабиты, скажу пару слов про алгоритмическую часть, чтобы понимать что нас ждёт.
В библиотеке реализован параллельный алгоритм Ахо-Корасик без сходов. PFAC, соответственно, сокращение от Parallel Failureless Aho-Corasick. Алгоритм строит префиксное дерево без сходов и упаковывает его в таблицу.
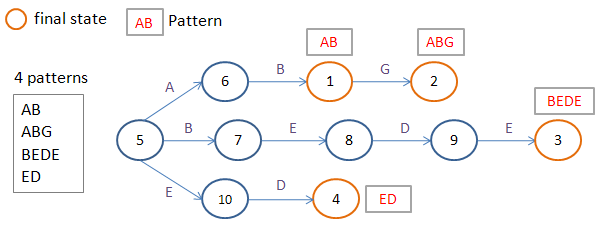
Как утверждается в документации, каждый поток обрабатывает данные, начиная со своего входного символа. 
Однако, если смотреть исходники, каждый поток обрабатывает по 4 символа, что связано с выравниванием памяти.
Все страшные слова, с которых я начал статью, имеют место быть в данном решении. Никто не гарантирует, что все нити внутри одного варпа (32 последовательно идущие нити внутри одного блока) будут обрабатывать близко расположенные данные таблицы. Также нет гарантий, что все нити внутри варпа перейдут по одной ветви ветвления или выйдут из цикла прохода по дереву в один момент времени.
Но предлагаю не думать о плохом, и с горящими глазами и оптимистичным настроем приступить к вычислительному эксперименту.
Развёртывание
Для начала попробуем развернуть PFAC. Считаю, что CUDA уже установлена, а также пути до nvcc и библиотек добавлены.
Заходим в проект, делаем make. Ожидание — всё хорошо, всё развернулось. Суровая реальность — какие-то непонятные ошибки. Оказывается, для CUDA 9.0 сборки под видеокарты с compute capability ниже 3.0 являются deprecated. С этим можно бороться. Надо только поменять src/Makefile.
#
# Makefile in directory src
#
# resource usage:
#
# To compile a dynamic module
# (1) nvcc cannot accept -fPIC, so compile .cu to .cu.cpp first
# nvcc -arch=sm_50 -cuda ../src/PFAC_kernel.cu
#
# (2) then use g++ to comple PFAC_notex_shared_reorder.cu.cpp
# g++ -fPIC -c PFAC_kernel.cu.cpp
#
# (3) finally combine two object files to a .so library
# g++ -shared -o libpfac.so $(LIBS) PFAC_kernel.cu.o ...
#
# $(LIBS) is necessary when compiling PFAC library on 32-bit machine
#
include ../common.mk
INC_DIR = ../include
LIB_DIR = ../lib
OBJ_DIR = ../obj
INCPATH += -I../include/
CU_SRC = PFAC_kernel.cu
CU_SRC += PFAC_reduce_kernel.cu
CU_SRC += PFAC_reduce_inplace_kernel.cu
CU_SRC += PFAC_kernel_spaceDriven.cu
CPP_SRC = PFAC_reorder_Table.cpp
CPP_SRC += PFAC_CPU.cpp
CPP_SRC += PFAC_CPU_OMP.cpp
CPP_SRC += PFAC.cpp
inc_files = $(INC_DIR)/PFAC_P.h $(INC_DIR)/PFAC.h
35
CU_OBJ = $(patsubst %.cu,%.o,$(CU_SRC))
CU_CPP = $(patsubst %.cu,%.cu.cpp,$(CU_SRC))
CPP_OBJ = $(patsubst %.cpp,%.o,$(CPP_SRC))
cppobj_loc = $(patsubst %.o,$(OBJ_DIR)/%.o,$(CPP_OBJ))
cppobj_fpic_loc = $(patsubst %.o,$(OBJ_DIR)/%_fpic.o,$(CPP_OBJ))
cu_cpp_sm50_loc = $(patsubst %.cpp,$(OBJ_DIR)/sm50_%.cpp,$(CU_CPP))
cu_cpp_obj_sm50_loc = $(patsubst %.cpp,$(OBJ_DIR)/sm50_%.cpp.o,$(CU_CPP))
all: mk_libso_no50 mk_lib_fpic
mk_libso_no50: $(cu_cpp_sm50_loc)
$(CXX) -shared -o $(LIB_DIR)/libpfac_sm50.so $(LIBS) $(cu_cpp_obj_sm50_loc)
mk_liba: $(cppobj_loc)
ar cru $(LIB_DIR)/libpfac.a $(cppobj_loc)
ranlib $(LIB_DIR)/libpfac.a
mk_lib_fpic: $(cppobj_fpic_loc)
$(CXX) -shared -o $(LIB_DIR)/libpfac.so $(cppobj_fpic_loc) $(LIBS)
$(OBJ_DIR)/%_fpic.o: %.cpp $(inc_files)
$(CXX) -fPIC -c $(CXXFLAGS) $(INCPATH) -o $@ $<
$(OBJ_DIR)/PFAC_CPU_OMP_reorder_fpic.o: PFAC_CPU_OMP_reorder.cpp $(inc_files)
$(CXX) -fPIC -c $(CXXFLAGS) $(INCPATH) -o $@ $<
$(OBJ_DIR)/PFAC_CPU_OMP_reorder.o: PFAC_CPU_OMP_reorder.cpp $(inc_files)
$(CXX) -c $(CXXFLAGS) $(INCPATH) -o $@ $<
$(OBJ_DIR)/%.o: %.cpp $(inc_files)
$(CXX) -c $(CXXFLAGS) $(INCPATH) -o $@ $<
$(OBJ_DIR)/sm50_%.cu.cpp: %.cu
$(NVCC) -arch=sm_50 -cuda $(INCPATH) -o $@ $<
$(CXX) -fPIC -O2 -c -o $@.o $@
#clean :
# rm -f *.linkinfo
# rm -f $(OBJ_DIR)/*
# rm -f $(EXE_DIR)/*
####### Implicit rules
.SUFFIXES: .o .c .cpp .cc .cxx .C
.cpp.o:
$(CXX) -c $(CXXFLAGS) $(INCPATH) -o "$@" "$<"
.cc.o:
$(CXX) -c $(CXXFLAGS) $(INCPATH) -o "$@" "$<"
.cxx.o:
$(CXX) -c $(CXXFLAGS) $(INCPATH) -o "$@" "$<"
.C.o:
$(CXX) -c $(CXXFLAGS) $(INCPATH) -o "$@" "$<"
.c.o:
$(CC) -c $(CFLAGS) $(INCPATH) -o "$@" "$<"
####### Build rules
Пересобираем.
Фух! Вроде бы всё хорошо. Добавляем в LD_LIBRARY_PATH путь до папки lib.
Пробуем запустить тестовый пример simple_example — вылетает ошибка:
simple_example.cpp:64: int main(int, char**): Assertion `PFAC_STATUS_SUCCESS == PFAC_status' failed.
Если добавить вывод PFAC_status — получаем статус 10008, что соответствует PFAC_STATUS_ARCH_MISMATCH. По непонятным причинам архитектура не поддерживается.
Погружаемся в код глубже. В файле src/PFAC.cpp находим следующий код, генерирующий данный статус.
int device_no = 10*deviceProp.major + deviceProp.minor ;
if ( 30 == device_no ){
strcpy (modulepath, "libpfac_sm30.so");
}else if ( 21 == device_no ){
strcpy (modulepath, "libpfac_sm21.so");
}else if ( 20 == device_no ){
strcpy (modulepath, "libpfac_sm20.so");
}else if ( 13 == device_no ){
strcpy (modulepath, "libpfac_sm13.so");
}else if ( 12 == device_no ){
strcpy (modulepath, "libpfac_sm12.so");
}else if ( 11 == device_no ){
strcpy (modulepath, "libpfac_sm11.so");
}else{
return PFAC_STATUS_ARCH_MISMATCH ;
}
Из расположенных рядом комментариев становится ясно, что код не работает только с compute capability 1.0. Заменим данный фрагмент на
int device_no = 10*deviceProp.major + deviceProp.minor ;
if ( 11 > device_no )
return PFAC_STATUS_ARCH_MISMATCH ;
sprintf(modulepath, "libpfac_sm%d.so", device_no);
Вроде теперь всё нормально. Больше явных зависимостей от версии вычислительных возможностей видеокарты не наблюдается.
Снова пробуем запустить тестовый вариант. Наблюдаем странную ошибку:
Error: fails to PFAC_matchFromHost, PFAC_STATUS_CUDA_ALLOC_FAILED: allocation fails on device memory.
К нашему счастью, в библиотеке существует способ включения отладочной информации.
В файле include/PFAC_P.h необходимо раскомментировать строчку
#define PFAC_PRINTF( ... ) printf( __VA_ARGS__ )
И, соответственно, закомментировать
//#define PFAC_PRINTF(...)
Теперь, после запуска simple_example, можно наблюдать более внятное сообщение об ошибке:
Error: cannot bind texture, 11264 bytes invalid texture reference
Error: fails to PFAC_matchFromHost, PFAC_STATUS_CUDA_ALLOC_FAILED: allocation fails on device memory
Ага, значит проблема не в выделении памяти, а в использовании текстурной памяти. PFAC позволяет отключать текстурную память. Попробуем этим воспользоваться. В файле test/simple_example.cpp после создания хендла добавим строчку:
PFAC_setTextureMode(handle, PFAC_TEXTURE_OFF ) ;
Свершилось чудо, консоль выдала нам долгожданные строчки.
At position 0, match pattern 1
At position 1, match pattern 3
At position 2, match pattern 4
At position 4, match pattern 4
At position 6, match pattern 2
Однако, древние манускрипты говорят о том, что текстурная память повышает производительность за счёт использования текстурного кеша. Ну что ж, попробуем запустить PFAC с текстурной памятью.
PFAC поддерживает 2 режима работы PFAC_TIME_DRIVEN и PFAC_SPACE_DRIVEN. Нам интересен первый. Реализация располагается в файле src/PFAC_kernel.cu.
Находим строчки, где происходит монтирование текстурной памяти на глобальную:
cuda_status = cudaBindTexture( &offset, (const struct textureReference*) texRefTable,
(const void*) handle->d_PFAC_table,
(const struct cudaChannelFormatDesc*) &channelDesc,
handle->sizeOfTableInBytes ) ;
Для видеокарт с compute capability 5.0 и далее несколько изменена реализация работы текстурной памяти и установленный режим доступа некорректен, поэтому заменим данную строчку на
cuda_status = cudaBindTexture( &offset, tex_PFAC_table,
(const void*) handle->d_PFAC_table, handle->sizeOfTableInBytes ) ;
После чего, в файле test/simple_example.cpp снова включаем текстурную память:
PFAC_setTextureMode(handle, PFAC_TEXTURE_ON ) ;
Проверяем работу — всё работает.
Тестирование и сравнение
Теперь посмотрим на производительность библиотеки.
Для тестирования будем использовать сигнатуры предоставляемые clamAV
Скачиваем файл main.cvd. Далее распаковываем
dd if=main.cvd of=main.tar.gz bs=512 skip=1
tar xzvf main.tar.gz
Тестировать будем на сигнатурах файла main.mdb.
Делаем много рутинных действий: отрезаем n строк и считаем их паттернами, шафлим входные данные и т.д. Думаю, здесь в подробности ударяться уже не стоит.
Для того, чтобы поиграться с производительностью, я несколько модернизировал файл test/simple_example.cpp
#include
#include
#include
#include
#include
#include
#include
int main(int argc, char **argv)
{
if(argc < 2){
printf("args input file, input pattern\n" );
return 0;
}
char dumpTableFile[] = "table.txt" ;
char *inputFile = argv[1]; //"../test/data/example_input" ;
char *patternFile = argv[2];//"../test/pattern/example_pattern" ;
PFAC_handle_t handle ;
PFAC_status_t PFAC_status ;
int input_size ;
char *h_inputString = NULL ;
int *h_matched_result = NULL ;
// step 1: create PFAC handle
PFAC_status = PFAC_create( &handle ) ;
PFAC_status = PFAC_setTextureMode(handle, PFAC_TEXTURE_OFF);
printf("%d\n", PFAC_status);
assert( PFAC_STATUS_SUCCESS == PFAC_status );
// step 2: read patterns and dump transition table
PFAC_status = PFAC_readPatternFromFile( handle, patternFile) ;
if ( PFAC_STATUS_SUCCESS != PFAC_status ){
printf("Error: fails to read pattern from file, %s\n", PFAC_getErrorString(PFAC_status) );
exit(1) ;
}
// dump transition table
FILE *table_fp = fopen( dumpTableFile, "w") ;
assert( NULL != table_fp ) ;
PFAC_status = PFAC_dumpTransitionTable( handle, table_fp );
fclose( table_fp ) ;
if ( PFAC_STATUS_SUCCESS != PFAC_status ){
printf("Error: fails to dump transition table, %s\n", PFAC_getErrorString(PFAC_status) );
exit(1) ;
}
//step 3: prepare input stream
FILE* fpin = fopen( inputFile, "rb");
assert ( NULL != fpin ) ;
// obtain file size
fseek (fpin , 0 , SEEK_END);
input_size = ftell (fpin);
rewind (fpin);
// allocate memory to contain the whole file
h_inputString = (char *) malloc (sizeof(char)*input_size);
assert( NULL != h_inputString );
h_matched_result = (int *) malloc (sizeof(int)*input_size);
assert( NULL != h_matched_result );
memset( h_matched_result, 0, sizeof(int)*input_size ) ;
// copy the file into the buffer
input_size = fread (h_inputString, 1, input_size, fpin);
fclose(fpin);
auto started = std::chrono::high_resolution_clock::now();
// step 4: run PFAC on GPU
PFAC_status = PFAC_matchFromHost( handle, h_inputString, input_size, h_matched_result ) ;
if ( PFAC_STATUS_SUCCESS != PFAC_status ){
printf("Error: fails to PFAC_matchFromHost, %s\n", PFAC_getErrorString(PFAC_status) );
exit(1) ;
}
auto done = std::chrono::high_resolution_clock::now();
std::cout << "gpu_time: " << std::chrono::duration_cast(done-started).count()<< std::endl;
memset( h_matched_result, 0, sizeof(int)*input_size ) ;
PFAC_setPlatform(handle, PFAC_PLATFORM_CPU);
started = std::chrono::high_resolution_clock::now();
// step 4: run PFAC on GPU
PFAC_status = PFAC_matchFromHost( handle, h_inputString, input_size, h_matched_result ) ;
if ( PFAC_STATUS_SUCCESS != PFAC_status ){
printf("Error: fails to PFAC_matchFromHost, %s\n", PFAC_getErrorString(PFAC_status) );
exit(1) ;
}
done = std::chrono::high_resolution_clock::now();
std::cout << "cpu_time: " << std::chrono::duration_cast(done-started).count()<< std::endl;
memset( h_matched_result, 0, sizeof(int)*input_size ) ;
PFAC_setPlatform(handle, PFAC_PLATFORM_CPU_OMP);
started = std::chrono::high_resolution_clock::now();
// step 4: run PFAC on GPU
PFAC_status = PFAC_matchFromHost( handle, h_inputString, input_size, h_matched_result ) ;
if ( PFAC_STATUS_SUCCESS != PFAC_status ){
printf("Error: fails to PFAC_matchFromHost, %s\n", PFAC_getErrorString(PFAC_status) );
exit(1) ;
}
done = std::chrono::high_resolution_clock::now();
std::cout << "omp_time: " << std::chrono::duration_cast(done-started).count() << std::endl;
PFAC_status = PFAC_destroy( handle ) ;
assert( PFAC_STATUS_SUCCESS == PFAC_status );
free(h_inputString);
free(h_matched_result);
return 0;
}
Т.к для замеров времени использую std: chrono, в файле test/Makefile необходимо добавить флаг -std=c++0x. И не забыть установить количество потоков для OpenMP (у себя я использовал 4):
export OMP_NUM_THREADS=4
Теперь можно приступить к замерам производительности. Посмотрим, что сможет показать GPU. Длина каждого паттерна — 32, длина входных данных — 128 МБ.
Получаем следующий график:

С ростом числа паттернов производительность деградирует. Это не удивительно, ведь алгоритм Ахо-Корасика без сходов зависит не только от входных данных, но и от паттернов, т.к. для каждой позиции в тексте необходимо пройти в глубь дерева на длину совпавшей подстроки текста с префиксом какого-либо признака, а при росте количества паттернов вероятность найти подстроку, совпадающую с неким префиксом увеличивается.
А теперь более интересный график — ускорение, при помощи GPU.
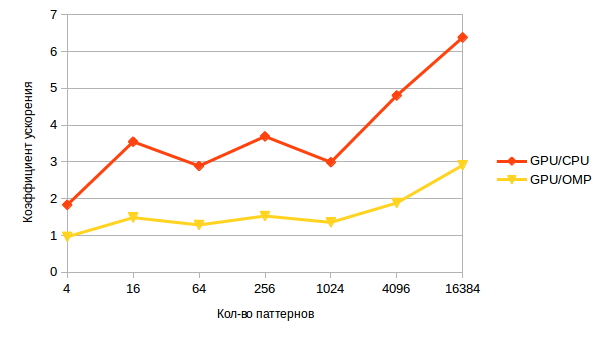
На малом кличестве паттернов оно практически незаметно, его съедает пересылка данных. Однако с ростом количества — возрастает и ускорение, что говорит о потенциальных возможностях GPU в несвойственной ей задаче.
Вместо вывода
Когда брался за эту задачу, я был скептически настроен, ведь не может же быть такого. Однако, результат даёт надежды на возможности применения CUDA в несвойственной ей отрасли.
Путь исследователя на этом не заканчивается, потребуется провести еще много работы, много исследований производительности и сравнений с конкурентами.
Первый шаг сделан, не теряем надежды!
