[Из песочницы] MongoDB и исследование рынка ИТ-вакансий
Вы когда-нибудь анализировали вакансии?
Задавались вопросом, в каких технологиях наиболее сильна потребность рынка труда на текущий момент? Месяц назад? Год назад?
Как часто открываются новые вакансии Java-разработчиков в определенном районе Вашего города и как активно они закрываются?
В этой статье я расскажу Вам, как можно достичь желаемого результата и построить отчетную систему по интересующей нас теме. Поехали!
Источник
Выбор пал на Headhunter.ru
Вероятно, многие из вас знакомы и даже пользовались таким ресурсом как Headhunter.ru. На этом сайте ежедневно размещаются тысячи новых вакансий в различных областях. Так же у HeadHunter существует API, позволяющий разработчику взаимодействовать с данными этого ресурса.
Инструментарий
На несложном примере рассмотрим построение процесса получения данных для отчетной системы, который базируется на работе с API сайта Headhunter.ru. В качестве промежуточного хранения информации будем использовать встраиваемую СУБД SQLite, обработанные данные будем хранить в NoSQL базе MongoDB, в качестве основного языка — Python версии 3.4.
Каждая вакансия висит на сайте в течение 30 дней, после чего, если она не продлевается, то попадает в архив. Если вакансия попала в архив до истечения 30-ти дней, значит, она была закрыта работодателем.
HeadHunter API (далее — HH API) позволяет получать массив опубликованных вакансий за любую дату за последние 30 дней, чем и воспользуемся — будем на ежедневной основе собирать опубликованные вакансии за каждый день.
Реализация
- Подключение БД SQLite
import sqlite3 conn_db = sqlite3.connect('hr.db', timeout=10) c = conn_db.cursor() - Таблица для хранения изменения статуса вакансии
Для удобства, будем сохранять историю изменения статуса вакансии (доступность на дату) в специальной таблице БД SQLite. Благодаря таблице vacancy_history нам будет известна на любую дату выгрузки доступность вакансии на сайте, т.е. в какие даты она была активна.c.execute(''' create table if not exists vacancy_history ( id_vacancy integer, date_load text, date_from text, date_to text )''') - Фильтрация выборки вакансий
Существует ограничение на то, что один запрос не может вернуть более 2000 коллекций, а так как в течение одного дня на сайте может быть опубликовано гораздо больше вакансий, поставим фильтр в теле запроса, например: вакансии только по Санкт-Петербургу (area = 2), по специализации IT (specialization = 1)path = ("/vacancies?area=2&specialization=1&page={}&per_page={}&date_from={}&date_to={}".format(page, per_page, date_from, date_to)) - Дополнительные условия отбора
Рынок труда активно растет и даже с учетом фильтра количество вакансий может превысить 2000, поэтому установим дополнительное ограничение в виде раздельного запуска за каждый день: вакансии за первую половину дня и вакансии за вторую половину дняdef get_vacancy_history(): ... count_days = 30 hours = 0 while count_days >= 0: while hours < 24: date_from = (cur_date.replace(hour=hours, minute=0, second=0) - td(days=count_days)).strftime('%Y-%m-%dT%H:%M:%S') date_to = (cur_date.replace(hour=hours + 11, minute=59, second=59) - td(days=count_days)).strftime('%Y-%m-%dT%H:%M:%S') while count == per_page: path = ("/vacancies?area=2&specialization=1&page={} &per_page={}&date_from={}&date_to={}" .format(page, per_page, date_from, date_to)) conn.request("GET", path, headers=headers) response = conn.getresponse() vacancies = response.read() conn.close() count = len(json.loads(vacancies)['items']) ... # Вставка значений в БД try: c.executemany('INSERT INTO vacancy_history VALUES (?,?,?,?)', collection_for_ins) except sqlite3.DatabaseError as err: print("Error: ", err) else: conn_db.commit() if collection_for_ins: page = page + 1 total = total + count # обнуление массива del(collection_for_ins[:]) hours = hours + 12 count_days = count_days - 1 hours = 0
c.execute("""
select
a.id_vacancy,
date(a.date_load) as date_last_load,
date(a.date_from) as date_publish,
ifnull(a.date_next, date(a.date_load, '+1 day')) as date_close
from (
select
vh1.id_vacancy,
vh1.date_load,
vh1.date_from,
min(vh2.date_load) as date_next
from vacancy_history vh1
left join vacancy_history vh2
on vh1.id_vacancy = vh2.id_vacancy
and vh1.date_load < vh2.date_load
where date(vh1.date_load) between :date_in and :date_out
group by
vh1.id_vacancy,
vh1.date_load,
vh1.date_from
) as a
where a.date_next is null
""",
{"date_in" : date_in, "date_out" : date_out})
date_in = dt.datetime(2018, 7, 1)
date_out = dt.datetime(2018, 7, 31)
closed_vacancies = get_closed_by_period(date_in, date_out)
df = pd.DataFrame(closed_vacancies,
columns = ['id_vacancy', 'date_last_load', 'date_publish', 'date_close'])
df.head()
Получаем результат такого вида:
| id_vacancy | date_last_load | date_publish | date_close | |
|---|---|---|---|---|
| 0 | 18126697 | 2018–07–09 | 2018–07–09 | 2018–07–10 |
| 1 | 18155121 | 2018–07–09 | 2018–06–19 | 2018–07–10 |
| 2 | 18881605 | 2018–07–09 | 2018–07–02 | 2018–07–10 |
| 3 | 19620783 | 2018–07–09 | 2018–06–27 | 2018–07–10 |
| 4 | 19696188 | 2018–07–09 | 2018–06–15 | 2018–07–10 |
# Экспорт полной таблицы из БД в CSV
data = c.execute('select * from vacancy_history')
with open('vacancy_history.csv','w', newline='') as out_csv_file:
csv_out = csv.writer(out_csv_file)
csv_out.writerow(d[0] for d in data.description)
csv_out.writerows(data.fetchall())
conn_db.close()
Тяжелая артиллерия
А что, если нам нужно провести более сложный анализ данных? Здесь на помощь приходит документоориентированная NoSQL база данных MongoDB, которая позволяет хранить данные в JSON-формате.
- Демонстрационный экземпляр моей базы MongoDB развернут в облачном сервисе mLab, который позволяет бесплатно создавать базу данных до 500MB, чего вполне достаточно для разбора текущей задачи. В базе данных hr_db имеется коллекция Vacancy, к которой установим соединение:
# Подключаем облачную базу Mongo from pymongo import MongoClient from pymongo import ASCENDING from pymongo import errors client = MongoClient('mongodb://: @ds115219.mlab.com:15219/hr_db') db = client.hr_db VacancyMongo = db.Vacancy - Стоит отметить, что не всегда уровень заработной платы указывается в рублях, поэтому для анализа необходимо привести все значения к рублевому эквиваленту. Для этого выкачиваем с помощью HH API коллекцию словарей, где содержится информация о курсе валют на текущую дату:
# Получение справочника def get_dictionaries(): conn = http.client.HTTPSConnection("api.hh.ru") conn.request("GET", "https://api.hh.ru/dictionaries", headers=headers) response = conn.getresponse() if response.status != 200: conn.close() conn = http.client.HTTPSConnection("api.hh.ru") conn.request("GET", "https://api.hh.ru/dictionaries", headers=headers) response = conn.getresponse() dictionaries = response.read() dictionaries_json = json.loads(dictionaries) return dictionaries_json - Заполнение словаря с валютами текущими курсами валют:
hh_dictionary = get_dictionaries() currencies = hh_dictionary['currency'] currency_rates = {} for currency in currencies: currency_rates[currency['code']] = currency['rate']
Вышеописанные действия по сбору вакансий запускаются на ежедневной основе, поэтому нет необходимости каждый раз просматривать все вакансии и получать по каждой из них детальную информацию. Будем брать только те, что были получены за последние пять дней.
- Получение массива вакансий за последние 5 дней из БД SQLite:
def get_list_of_vacancies_sql(): conn_db = sqlite3.connect('hr.db', timeout=10) conn_db.row_factory = lambda cursor, row: row[0] c = conn_db.cursor() items = c.execute(""" select distinct id_vacancy from vacancy_history where date(date_load) >= date('now', '-5 day') """).fetchall() conn_db.close() return items - Получение массива вакансий за последние пять дней из MongoDB:
def get_list_of_vacancies_nosql(): date_load = (dt.datetime.now() - td(days=5)).strftime('%Y-%m-%d') vacancies_from_mongo = [] for item in VacancyMongo.find({"date_load" : {"$gte" : date_load}}, {"id" : 1, "_id" : 0}): vacancies_from_mongo.append(int(item['id'])) return vacancies_from_mongo - Остается найти разницу между двумя массивами, по тем вакансиям, которых нет в MongoDB, получить детальную информацию и записать ее в базу данных:
sql_list = get_list_of_vacancies_sql() mongo_list = get_list_of_vacancies_nosql() vac_for_proс = [] s = set(mongo_list) vac_for_proс = [x for x in sql_list if x not in s] vac_id_chunks = [vac_for_proс[x: x + 500] for x in range(0, len(vac_for_proс), 500)] - Итак, у нас готов массив с новыми вакансиями, которых еще нет в MongoDB, по каждой из них мы получим детальную информацию с помощью запроса в HH API, перед непосредственной записью в MongoDB обработаем каждый документ:
- Приведем величину заработной платы к рублевому эквиваленту;
- Добавим к каждой вакансии градацию уровня специалиста (Junior/Middle/Senior etc)
Все это реализуем в функции vacancies_processing:from nltk.stem.snowball import SnowballStemmer stemmer = SnowballStemmer("russian") def vacancies_processing(vacancies_list): cur_date = dt.datetime.now().strftime('%Y-%m-%d') for vacancy_id in vacancies_list: conn = http.client.HTTPSConnection("api.hh.ru") conn.request("GET", "/vacancies/{}".format(vacancy_id), headers=headers) response = conn.getresponse() if response.status != 404: vacancy_txt = response.read() conn.close() vacancy = json.loads(vacancy_txt) # salary salary = None if 'salary' in vacancy: if vacancy['salary'] != None: ... max_salary = 500000 if salary is not None: salary = int(salary) if salary >= max_salary: salary = max_salary # grade grade = None if 'name' in vacancy: p_grade = '' title = re.sub(u'[^a-zа-я]+', ' ', vacancy['name'].lower(), re.UNICODE) words = re.split(r'\s{1,}', title.strip()) for title_word in words: title_word = stemmer.stem(title_word) if len(title_word.strip()) > 1: p_grade = p_grade + " " + title_word.strip() if re.search('(главн)|(princip)', p_grade): grade = 'principal' elif re.search('(ведущ)|(senior)|([f|F]ull)', p_grade): grade = 'senior' ... else: grade = 'not specify' vacancy['salary_processed'] = salary vacancy['date_load'] = cur_date vacancy['grade'] = grade vacancy.pop('branded_description', None) try: post_id = VacancyMongo.insert_one(vacancy) except errors.DuplicateKeyError: print ('Cant insert the duplicate vacancy_id:', vacancy['id']) - Получение детальной информации путем обращения к HH API, предобработку полученных
данных и вставку их в MongoDB будет проводить в несколько потоков, по 500 вакансий в каждом:t_num = 1 threads = [] for vac_id_chunk in vac_id_chunks: print('starting', t_num) t_num = t_num + 1 t = threading.Thread(target=vacancies_processing, kwargs={'vacancies_list': vac_id_chunk}) threads.append(t) t.start() for t in threads: t.join()
Заполненная коллекция в MongoDB выглядит примерно следуюшим образом:
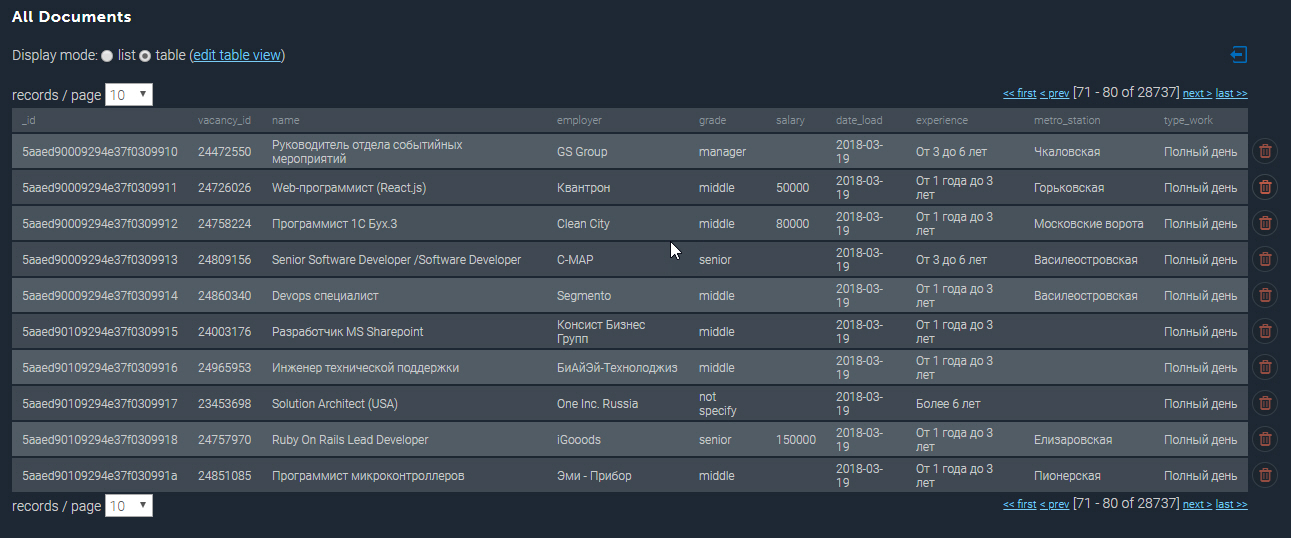
Еще немного примеров
Имея в распоряжении собранную базу данных, можем выполнять различные аналитические выборки. Итак, выведу Топ-10 самых высокооплачиваемых вакансий Python-разработчиков в Санкт-Петербурге:
cursor_mongo = VacancyMongo.find({"name" : {"$regex" : ".*[pP]ython*"}})
df_mongo = pd.DataFrame(list(cursor_mongo))
del df_mongo['_id']
pd.concat([df_mongo.drop(['employer'], axis=1),
df_mongo['employer'].apply(pd.Series)['name']], axis=1)[['grade',
'name',
'salary_processed'
]].sort_values('salary_processed',
ascending=False)[:10]
| grade | name | name | salary_processed |
|---|---|---|---|
| senior | Web Team Lead / Архитектор (Python/Django/React) | Investex Ltd | 293901.0 |
| senior | Senior Python разработчик в Черногорию | Betmaster | 277141.0 |
| senior | Senior Python разработчик в Черногорию | Betmaster | 275289.0 |
| middle | Back-End Web Developer (Python) | Soshace | 250000.0 |
| middle | Back-End Web Developer (Python) | Soshace | 250000.0 |
| senior | Lead Python Engineer for a Swiss Startup | Assaia International AG | 250000.0 |
| middle | Back-End Web Developer (Python) | Soshace | 250000.0 |
| middle | Back-End Web Developer (Python) | Soshace | 250000.0 |
| senior | Python teamlead | DigitalHR | 230000.0 |
| senior | Ведущий разработчик (Python, PHP, Javascript) | IK GROUP | 220231.0 |
А теперь выведем, возле какой станции метро наивысшая концентрация вакантных должностей для Java-разработчиков. С помощью регулярного выражения фильтрую по названиям вакансии «Java», а так же отбираю только те вакансии, где указан адрес:
cursor_mongo = VacancyMongo.find({"name" : {"$regex" : ".*[jJ]ava[^sS]"}, "address" : {"$ne" : None}})
df_mongo = pd.DataFrame(list(cursor_mongo))
df_mongo['metro'] = df_mongo.apply(lambda x: x['address']['metro']['station_name']
if x['address']['metro'] is not None
else None, axis = 1)
df_mongo.groupby('metro')['_id'] \
.count() \
.reset_index(name='count') \
.sort_values(['count'], ascending=False) \
[:10]
| metro | count |
|---|---|
| Василеостровская | 87 |
| Петроградская | 68 |
| Выборгская | 46 |
| Площадь Ленина | 45 |
| Горьковская | 45 |
| Чкаловская | 43 |
| Нарвская | 32 |
| Площадь Восстания | 29 |
| Старая Деревня | 29 |
| Елизаровская | 27 |
Итоги
Итак, аналитические возможности разработанной системы поистине широкие и могут использоваться для планирования стартапа или открытия нового направления деятельности.
Замечу, что представлен пока лишь базовый функционал системы, в дальнейшем планируется развитие в сторону анализа по географическим координатам и предсказания появления вакансий в том или ином районе города.
Полный исходный код к этой статье Вы можете найти по ссылке на мой GitHub.
P.S. Комментарии к статье приветствуются, буду рад ответить на все Ваши вопросы и узнать Ваше мнение. Спасибо!
