[Из песочницы] Moneyball и Формула-1: модель прогнозирования результатов квалификаций

Сразу скажу: я не IT-специалист, а энтузиаст в сфере статистики. Помимо этого, я на протяжении многих лет участвовал в различных конкурсах прогнозов по Формуле-1. Отсюда вытекают и задачи, стоявшие перед моей моделью: выдавать прогнозы, которые были бы не хуже тех, которые создаются «на глаз». А в идеале модель, конечно, должна обыгрывать человеческих оппонентов.
Эта модель посвящена прогнозированию исключительно результатов квалификаций, поскольку квалификации более предсказуемы, чем гонки, и их проще моделировать. Однако, конечно, в будущем я планирую создать модель, позволяющую с достаточно хорошей точностью предсказывать и результаты гонок.
Для создания модели я свел в одну таблицу все результаты практик и квалификаций за сезоны 2018 и 2019. 2018-й год служил в качестве обучающей выборки, а 2019-й — в качестве тестовой. По этим данным мы построили линейную регрессию. Если максимально просто объяснять регрессию, то наши данные — это совокупность точек на координатной плоскости. Мы провели прямую, которая меньше всего отклоняется от совокупности этих точек. И функция, графиком которой является эта прямая — это и есть наша линейная регрессия.
От известной из школьной программы формулы $inline$y = kx + b $inline$ нашу функцию отличает только то, что переменных у нас две. Первая переменная (X1) — это отставание в третьей практике, а вторая переменная (X2) — среднее отставание по предыдущим квалификациям. Эти переменные не равнозначны, и одна из наших целей — определить вес каждой переменной в диапазоне от 0 до 1. Чем дальше переменная от нуля, тем большее значение она имеет при объяснении зависимой переменной. В нашем случае в качестве зависимой переменной выступает время на круге, выраженное в отставании от лидера (или точнее, от некоего «идеального круга», поскольку у всех пилотов эта величина была положительной).
Поклонники книги Moneyball (в фильме этот момент не объясняется) могут вспомнить, что там с помощью линейной регрессии определили, что процент занятия базы, aka OBP (on-base percentage), более тесно связан с заработанными ранами, чем другие статистические показатели. Мы преследуем примерно такую же цель: понять, какие именно факторы наиболее тесно связаны с результатами квалификаций. Один из больших плюсов регрессии в том, что она не требует продвинутого знания математики: мы просто задаем данные, а потом Excel или другой табличный редактор выдает нам готовые коэффициенты.
По сути, с помощью линейной регрессии мы хотим узнать две вещи. Во-первых, насколько выбранные нами независимые переменные объясняют изменение функции. И во-вторых, насколько велика значимость каждой из этих независимых переменных. Иначе говоря, что лучше объясняет результаты квалификации: результаты заездов на предыдущих трассах или итоги тренировок на этой же трассе.
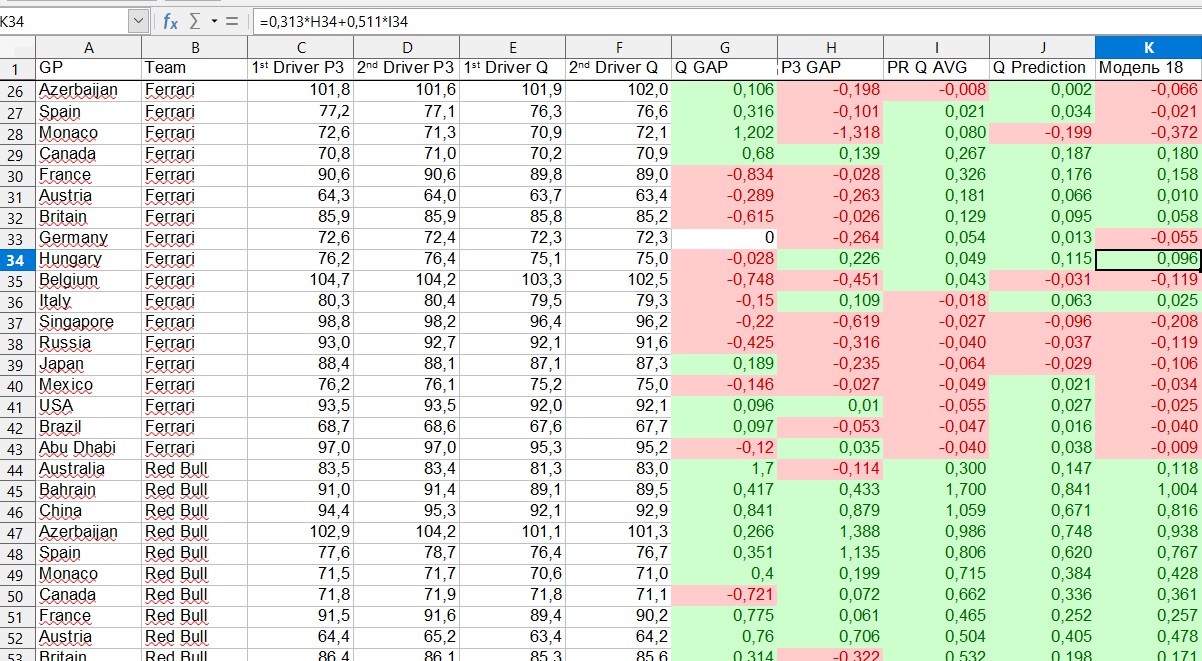
Тут надо отметить важный момент. Конечный результат складывался из двух независимых параметров, каждый из которых вытекал из двух независимых регрессий. Первый параметр — сила команды на этом этапе, точнее, отставание лучшего пилота команды от лидера. Второй параметр — распределение сил внутри команды.
Что это значит на примере? Допустим, мы берем Гран-при Венгрии сезона-2019. Модель показывает, что отставание «Феррари» от лидера составит 0,218 секунды. Но это отставание первого пилота, а кто им будет — Феттель или Леклер — и какой разрыв между ними будет, определяется другим параметром. В этом примере модель показала, что впереди будет Феттель, а Леклер проиграет ему 0,096 секунды.
К чему такие сложности? Не проще ли рассматривать каждого пилота по отдельности вместо этой разбивки на отставание команды и отставание первого пилота от второго внутри команды? Возможно, это так, но мои личные наблюдения показывают, что смотреть на результаты команды гораздо надежнее, чем на результаты каждого пилота. Один пилот может допустить ошибку, или вылететь с трассы, или у него будут технические проблемы — все это будет вносить хаос в работу модели, если только не отслеживать вручную каждую форс-мажорную ситуацию, что требует слишком много времени. Влияние форс-мажоров на результаты команды гораздо меньше.
Но вернемся к моменту, где мы хотели оценить, насколько хорошо выбранные нами независимые переменные объясняют изменения функции. Это можно сделать с помощью коэффициента детерминации. Он продемонстрирует, в какой степени результаты квалификации объясняются результатами практик и предыдущих квалификаций.
Поскольку мы строили две регрессии, то и коэффициента детерминации у нас тоже два. Первая регрессия отвечает за уровень команды на этапе, вторая — за противостояние между пилотами одной команды. В первом случае коэффициент детерминации равен 0,82, то есть 82% результатов квалификаций объясняются выбранными нами факторами, а еще 18% — какими-то другими факторами, которые мы не учли. Это достаточно неплохой результат. Во втором случае коэффициент детерминации составил 0,13.
Эти показатели, по сути, означают, что модель достаточно хорошо предсказывает уровень команды, но испытывает проблемы с определением разрыва между партнерами по команде. Однако для итоговой цели нам не нужно знать разрыв, нам достаточно знать, кто из двух пилотов будет выше, и с этим модель в основном справляется. В 62% случаев модель ставила выше того пилота, который действительно был выше по итогам квалификации.
При этом при оценке силы команды результаты последней тренировки были в полтора раза важнее, чем результаты предыдущих квалификаций, а вот во внутрикомандных дуэлях все было наоборот. Тенденция проявилась как на данных 2018, так и 2019 года.
Итоговая формула выглядит так:
Первый пилот:
$$display$$Y1 = (0,618 * X1 + 0,445 * X2)$$display$$
Второй пилот:
$$display$$Y2 = Y1 + (0,313 * X1 + 0,511 * X2)$$display$$
Напоминаю, что X1 — это отставание в третьей практике, а X2 — среднее отставание по предыдущим квалификациям.
Что означают эти цифры. Они означают, что уровень команды в квалификации на 60% определяется результатами третьей практики и на 40% — результатами квалификаций на предыдущих этапах. Соответственно, результаты третьей практики — в полтора раза более значимый фактор, чем результаты предыдущих квалификаций.
Поклонники Формулы-1 наверняка знают ответ на этот вопрос, но для остальных следует прокомментировать, почему я брал результаты именно третьей практики. В Формуле-1 проводится три практики. Однако именно в последней из них команды традиционно тренируют квалификацию. Однако же в тех случаях, когда третья практика срывается из-за дождя или других форс-мажоров, я брал результаты второй практики. Насколько я помню, в 2019 году был только один такой случай — на Гран-при Японии, когда из-за тайфуна этап прошел в укороченном формате.
Также кто-то наверняка заметил, что модель использует среднее отставание в предыдущих квалификациях. Но как быть на первом этапе сезона? Я использовал отставания с предыдущего года, но не оставлял их как есть, а вручную их корректировал, основываясь на здравом смысле. Например, в 2019 году «Феррари» в среднем была быстрее, чем «Ред Булл» на 0,3 секунды. Однако похоже, что у итальянской команды не будет такого преимущества в этом году, а может, они и вовсе будут позади. Поэтому для первого этапа сезона 2020, Гран-при Австрии, я вручную приблизил «Ред Булл» к «Феррари».
Таким образом я получал отставание каждого пилота, ранжировал пилотов по отставанию и получил итоговый прогноз на квалификацию. При этом важно понимать, что первый и второй пилот — это чистые условности. Возвращаясь к примеру с Феттелем и Леклером, на Гран-при Венгрии модель посчитала первым пилотом Себастьяна, но на многих других этапах она отдавала предпочтение Леклеру.
Результаты
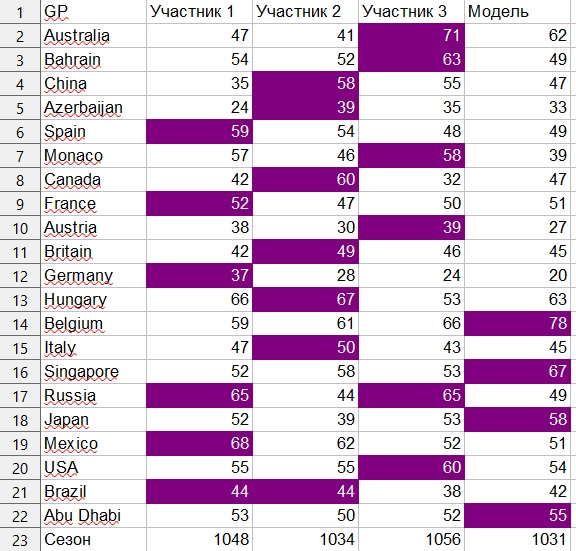
Как я говорил, задачей было создать такую модель, которая позволит прогнозировать не хуже людей. За основу я брал свои прогнозы и прогнозы своих партнеров по команде, которые создавались «на глаз», но при внимательном изучении результатов практик и совместном обсуждении.
Система оценки была следующая. Учитывалась только первая десятка пилотов. За точное попадание прогноз получал 9 баллов, за промах в 1 позицию 6 баллов, за промах в 2 позиции 4 балла, за промах в 3 позиции 2 балла и за промах в 4 позиции — 1 балл. То есть если в прогнозе пилот стоит на 3-м месте, а в результате он взял поул-позишн, то прогноз получал 4 балла.
При такой системе максимальное количество баллов за 21 Гран-при — 1890.
Человеческие участники набрали 1056, 1048 и 1034 балла соответственно.
Модель набрала 1031 балл, хотя при легкой манипуляции с коэффициентами я также получал 1045 и 1053 балла.
Лично я доволен итогами, поскольку это мой первый опыт в построении регрессий, и он привел к достаточно приемлемым результатам. Безусловно, хотелось бы их улучшить, поскольку я уверен, что с помощью построения моделей, даже таких простых, как эта, можно добиваться лучшего результата, чем просто оценивая данные «на глаз». В рамках этой модели можно было бы, например, учесть тот фактор, что некоторые команды слабы в практиках, но «выстреливают» в квалификациях. Например, есть наблюдение, что «Мерседес» часто не был лучшей командой в ходе тренировок, но гораздо лучше выступал в квалификациях. Однако эти человеческие наблюдения не нашли отражения в модели. Поэтому в сезоне 2020, который начнется в июле (если не произойдет ничего непредвиденного), я хочу проверить эту модель в соревновании против живых прогнозистов, а также найти, как ее можно сделать лучше.
Помимо этого, я надеюсь вызвать отклик в комьюнити любителей Формулы-1 и верю, что с помощью обмена идеями мы сможем лучше понимать, из чего складываются результаты квалификаций и гонок, а это в конечном счете цель любого человека, который делает прогнозы.
