[Из песочницы] Как просто написать распределенный веб-сервис на Python + AMQP
Привет, Хабр. Я уже довольно давно пишу на Python. Недавно пришлось разбираться с RabbitMQ. Мне понравилось. Потому что он без всяких проблем (понятно, что с некоторыми тонкостями) собирается в кластер. Тут я подумал:, а неплохо бы его использовать в качестве очереди сообщений в кусочке API проекта, над которым я работаю. Сам API написан на tornado, основная мысль была в исключении блокирующего кода из API. Все синхронные операции выполнялись в пуле тредов.Первое, что я решил, это сделать отдельный процесс (ы) «worker», который бы брал на себя всю синхронную работу. Задумал, чтобы «worker» был максимально прост, и делал задачи из очереди одну за другой. Скажем, выбрал из базы что-нибудь, ответил, взял на себя следующую задачу и так далее. Самих «worker«ов можно запустить много и тогда AMQP выступает уже в роли некоего подобия IPC.
Спустя некоторое время из этого вырос модуль, который берет на себя всю рутину связанную с AMQP и передачей сообщений туда и назад, а также сжимает их gzipом, если данных слишком много. Так родился crew. Собственно, используя его, мы с вами напишем простой API, который будет состоять из сервера на tornado и простых и незамысловатых «worker» процессов. Забегая вперед скажу, что весь код доступен на github, а то, о чем я буду рассказывать дальше, собрано в папке example.
ПодготовкаИтак, давайте разберемся по порядку. Первое, что нам нужно будет сделать — это установить RabbitMQ. Как это делать я описывать не буду. Скажу лишь то, что на той-же убунте он ставится и работает из коробки. У меня на маке единственное, что пришлось сделать, это поставить LaunchRocket, который собрал все сервисы, что были установлены через homebrew и вывел в GUI: 
Дальше создадим наш проект virtualenv и установим сам модуль через pip:
mkdir -p api cd api virtualenv env source env/bin/activate pip install crew tornado В зависимостях модуля умышленно не указан tornado, так как на хосте с workerом его может и не быть. А на веб-части обычно создают requirements.txt, где указаны все остальные зависимости.
Код я буду писать частями, чтобы не нарушать порядок повествования. То, что у нас получится в итоге, можно посмотреть тут.
Пишем код Сам tornado сервер состоит из двух частей. В первой части мы определяем обработчики запросов handlers, а во второй запускается event-loop. Давайте напишем сервер и создадим наш первый метод api.Файл master.py:
# encoding: utf-8
import tornado.ioloop import tornado.gen import tornado.web import tornado.options
class MainHandler (tornado.web.RequestHandler): @tornado.gen.coroutine def get (self): # Вызываем задачу test c приоритетом 100 resp = yield self.application.crew.call ('test', priority=100) self.write (»{0}: {1}».format (type (resp).__name__, str (resp)))
application = tornado.web.Application ( [ ('/', MainHandler), ], autoreload=True, debug=True, )
if __name__ == »__main__»: tornado.options.parse_command_line () application.listen (8888) tornado.ioloop.IOLoop.instance ().start () Благодаря coroutine в торнадо, код выглядит просто. Можно написать тоже самое без coroutine.
Файл master.py:
class MainHandler (tornado.web.RequestHandler): def get (self): # Вызываем задачу test c приоритетом 100 self.application.crew.call ('test', priority=100, callback=self._on_response)
def _on_response (resp, headers): self.write (»{0}: {1}».format (type (resp).__name__, str (resp))) Наш сервер готов. Но если мы его запустим, и сходим на /, то не дождемся ответа, его некому обрабатывать.
Теперь напишем простой worker:
Файл worker.py:
# encoding: utf-8
from crew.worker import run, context, Task
@Task ('test') def long_task (req): context.settings.counter += 1 return 'Wake up Neo.\n'
run ( counter=0, # This is a part of this worker context ) Итак, как видно в коде, есть простая функция, обернутая декоратором Task («test»), где test — это уникальный идентификатор задачи. В вашем worker не может быть двух задач с одинаковыми идентификаторами. Конечно, правильно было бы назвать задачу «crew.example.test» (так обычно и называю в продакшн среде), но для нашего примера достаточно просто «test».
Сразу бросается в глаза context.settings.counter. Это некий контекст, который инициализируется в worker процессе при вызове функции run. Также в контексте уже есть context.headers — это заголовки ответа для отделения метаданных от ответа. В примере с callback-функцией именно этот словарь передается в _on_response.
Заголовки сбрасываются после каждого ответа, а вот context.settings — нет. Я использую context.settings для передачи в функции worker (ы) соединения с базой данных и вообще любого другого объекта.
Также worker обрабатывает ключи запуска, их не много:
$ python worker.py --help Usage: worker.py [options]
Options: -h, --help show this help message and exit -v, --verbose make lots of noise --logging=LOGGING Logging level -H HOST, --host=HOST RabbitMQ host -P PORT, --port=PORT RabbitMQ port URL подключения к базе и прочие переменные можно брать из переменный окружения. Поэтому worker в параметрах ждет только как ему соединиться c AMQP (хост и порт) и уровень логирования.
Итак, запускаем все и проверяем:
$ python master.py & python worker.py
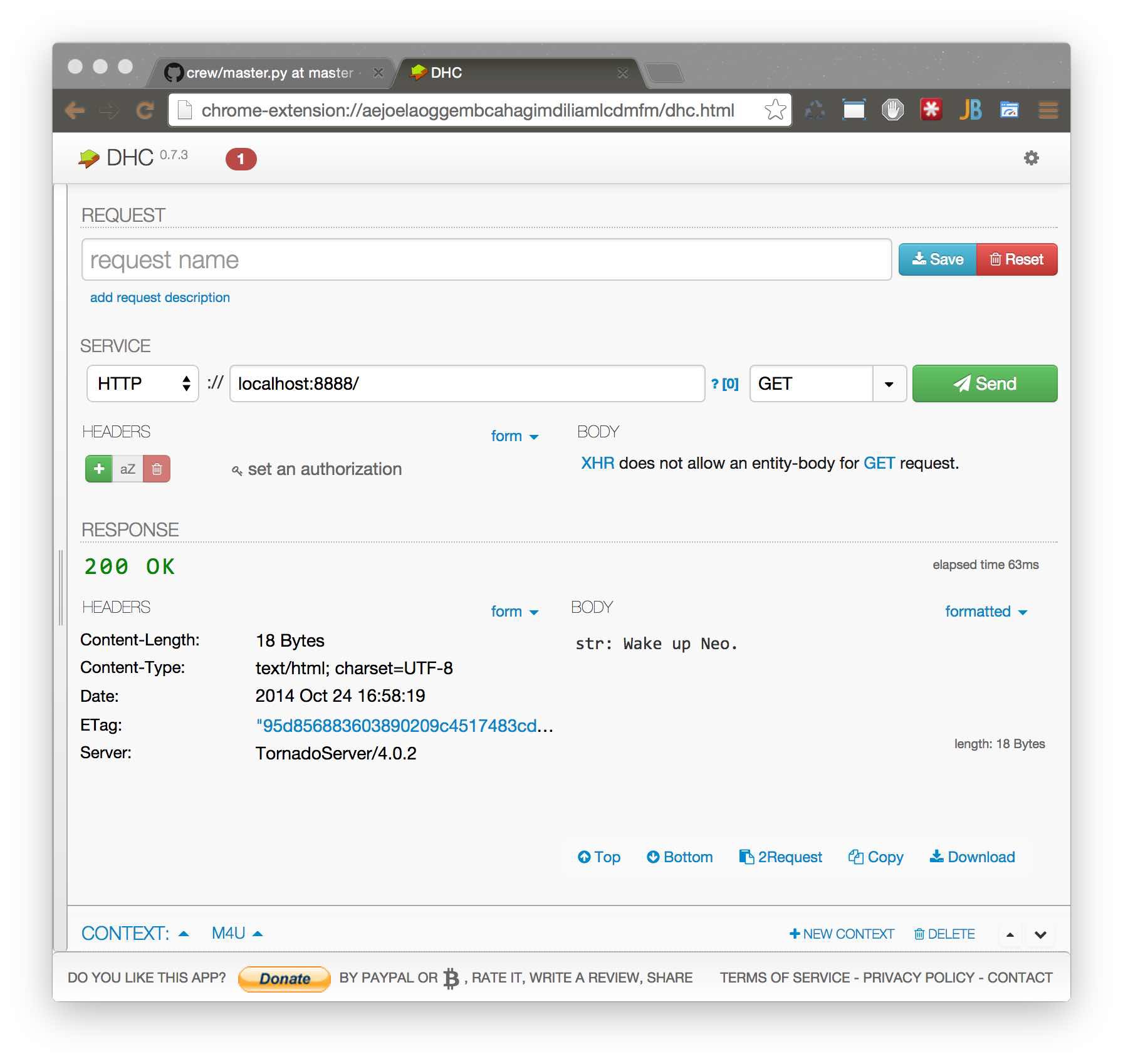
Работает, но что случилось за ширмой? При запуске tornado-сервера tornado подключился к RabbitMQ, создал Exchange DLX и начал слушать очередь DLX. Это Dead-Letter-Exchange — специальная очередь, в которую попадают задачи, которые не взял ни один worker за определенный timeout. Также он создал очередь с уникальным идентификатором, куда будут поступать ответы от workerов.После запуска worker создал по очереди на каждую обернутую декоратором Task очередь и подписался на них. При поступлении задачи воркер main-loop создает один поток, контролируя в главном потоке время исполнения задачи и выполняет обернутую функцию. После return из обернутой функции сериализует его и ставит в очередь ответов сервера.
После поступления запроса tornado-сервер cтавит задачу в соответствующую очередь, указывая при этом идентификатор своей уникальной очереди, в которую должен поступить ответ. Если ни один воркер не взял задачу, тогда RabbitMQ перенаправляет задачу в exchange DLX и tornado-сервер получает сообщение о том, что истек таймаут пребывания очереди, генерируя исключение.
Зависшая задача Чтобы продемонстрировать, как работает механизм завершения задач, которые повисли в процессе выполнения, напишем еще один веб-метод и задачу в worker.В файл master.py добавим:
class FastHandler (tornado.web.RequestHandler): @tornado.gen.coroutine def get (self): try: resp = yield self.application.crew.call ( 'dead', persistent=False, priority=255, expiration=3, ) self.write (»{0}: {1}».format (type (resp).__name__, str (resp))) except TimeoutError: self.write ('Timeout') except ExpirationError: self.write ('All workers are gone') И добавим его в список хендлеров:
application = tornado.web.Application ( [ (r»/», MainHandler), (r»/stat», StatHandler), ], autoreload=True, debug=True, ) А в worker.py:
@Task ('dead') def infinite_loop_task (req): while True: pass Как видно из приведенного выше примера, задача уйдет в бесконечный цикл. Однако, если задача не выполнится за 3 секунды (считая время получения из очереди), main-loop в воркере пошлет потоку исключение SystemExit. И да, вам придется обработать его.
Контекст Как уже упоминалось выше, контекст — это такой специальный объект, который импортируется и имеет несколько встроенных переменных.Давайте сделаем простую статистику по ответам нашего worker.
В файл master.py добавим следующий handler:
class StatHandler (tornado.web.RequestHandler):
@tornado.gen.coroutine def get (self): resp = yield self.application.crew.call ('stat', persistent=False, priority=0) self.write (»{0}: {1}».format (type (resp).__name__, str (resp))) Также зарегистрируем в списке обработчиков запросов:
application = tornado.web.Application ( [ (r»/», MainHandler), (r»/fast», FastHandler), (r»/stat», StatHandler), ], autoreload=True, debug=True, ) Этот handler не очень отличается от предыдущих, просто возвращает значение, которое ему передал worker.
Теперь сама задача.
В файл worker.py добавим:
@Task ('stat') def get_counter (req): context.settings.counter += 1 return 'I\'m worker »%s». And I serve %s tasks' % (context.settings.uuid, context.settings.counter) Функция возвращает строку, с информацией о количестве задач, обработанных workerом.
PubSub и Long polling Теперь реализуем пару обработчиков. Один при запросе будет просто висеть и ждать, а второй будет принимать POST данные. После передачи последних первый будет их отдавать.master.py:
class LongPoolingHandler (tornado.web.RequestHandler): LISTENERS = []
@tornado.web.asynchronous def get (self): self.LISTENERS.append (self.response)
def response (self, data): self.finish (str (data))
@classmethod def responder (cls, data): for cb in cls.LISTENERS: cb (data)
cls.LISTENERS = []
class PublishHandler (tornado.web.RequestHandler):
@tornado.gen.coroutine def post (self, *args, **kwargs): resp = yield self.application.crew.call ('publish', self.request.body) self.finish (str (resp))
…
application = tornado.web.Application ( [ (r»/», MainHandler), (r»/stat», StatHandler), (r»/fast», FastHandler), (r'/subscribe', LongPoolingHandler), (r'/publish', PublishHandler), ], autoreload=True, debug=True, )
application.crew = Client () application.crew.subscribe ('test', LongPoolingHandler.responder)
if __name__ == »__main__»: application.crew.connect () tornado.options.parse_command_line () application.listen (8888) tornado.ioloop.IOLoop.instance ().start () Напишем задачу publish.
worker.py:
@Task ('publish') def publish (req): context.pubsub.publish ('test', req) Если же вам не нужно передавать управление в worker, можно просто публиковать прямо из tornado-сервера
class PublishHandler2(tornado.web.RequestHandler):
def post (self, *args, **kwargs): self.application.crew.publish ('test', self.request.body) Параллельное выполнение заданий Часто бывает ситуация, когда мы можем выполнить несколько заданий параллельно. В crew есть для этого небольшой синтаксический сахар: class Multitaskhandler (tornado.web.RequestHandler):
@tornado.gen.coroutine def get (self, *args, **kwargs): with self.application.crew.parallel () as mc: # mc — multiple calls mc.call ('test') mc.call ('stat') test_result, stat_result = yield mc.result () self.set_header ('Content-Type', 'text/plain') self.write («Test result: {0}\nStat result: {1}».format (test_result, stat_result)) В этом случае, задаче будут поставлены две задачи параллельно и выход из with будет произведен по окончании последней.
Но нужно быть осторожным, так как какая-то задача может вызвать исключение. Оно будет приравнено непосредственно переменной. Таким образом, вам нужно проверить, не является ли test_result и stat_result экземплярами класса Exception.
Планы на будущее Когда eigrad предложил написать прослойку, которой можно запустить любое wsgi приложение с помощью crew, мне эта идея сразу понравилась. Только представьте, запросы хлынут не на ваше wsgi приложение, а будут равномерно поступать через очередь на wsgi-worker.Я никогда не писал wsgi сервер и даже не знаю, с чего начать. Но вы можете мне помочь, pull-requestы я принимаю.
Также думаю дописать client для еще одного популярного асинхронного фреймворка, для twisted. Но пока разбираюсь с ним, да и свободного времени не хватает.
Благодарности Спасибо разработчикам RabbitMQ и AMQP. Замечательные идеи.Также спасибо вам, читатели. Надеюсь, что вы не зря потратили время.
