[Из песочницы] Как написать быструю систему скриптования и развертывания базы данных
Сейчас историки пытаются преподнести, что в тысяча пятьсот каком-то годучто-то там было.Да не было ничего! В.С. Черномырдин
Итак, все началось в далеком 2006 году, когда я попал в it-компанию, которая занималась разработкой решений в области телекоммуникаций. Наша команда разрабатывала приложение на C#, которое получало некоторые данные из базы данных MS Sql Server, обрабатывало их и складывало обратно. Сначала в нашей базе было около 10 таблиц и пара хранимых процедур. Со временем число таблиц и других объектов стало расти. Мы начали задумываться, как управлять этими объектами. Скрипты мы хранили в системе контроля версий.Изначально мы использовали DB Project из Visual Studio, но со временем стало очевидно, что данная среда очень долго производит разворачивание, т.к. производит сравнение целевой базы данных и исходных скриптов. К тому же нам в базе данных нужна была часть объектов от большой подсистемы, с которой мы интегрировались и которые мы не хотели хранить в своем репозитарии. В итоге мы написали простенькое приложение, которое принимало xml файл со списком объектов, которые мы хотим развернуть. Данный файл редактировался вручную каждым разработчиков, а его «текстовость» позволяла устранять конфликты при комитах. В дальнейшем мы отказались от xml файла в пользу строгого порядка хранения скриптов и порядка их наката. (таблицы накатывались перед представлениями и т.д.)
Все было хорошо, пока не появилась новая проблема. Наша техподдержка могла править код в ветке релиза, а так же иногда вносить изменения прямо на клиенте, что приводило к проблемам при установке очередного релиза. Мы решили реализовать подсистему, которая обнаруживала бы «нелегальные» изменения на клиенте. Наше приложение скриптовало базу данных, присылало скрипты на наш сервер, разворачивало их в правильную структуру и тут подключалась наша система развертывания, которая на выходе получала две базы данных — из репозитария и с клиента. Далее запускалась все та же Visual Studio, которая сравнивала базы данных.
Скриптование происходило за счет использования библиотеки SMO (Server Management Objects).
С ней было легко работать, но была одна большая проблема — скорость. Она могла скриптовать около 6 объектов в секунду. База данных на клиенте насчитывала около 10000 объектов и процесс скриптования занимал пол часа.
Несколько месяцев назад мы с моим коллегой решили реализовать самую быструю систему скриптования и развертывания баз данных, учтя все достоинства и недостатки того, что мы уже сделали. Вот что у нас получилось.
Современная техника настолькооблегчила труд женщин, что у мужчин появиласьуйма свободного времени.Владислав Гжещик
Скриптование
Для системы скриптования мы определили следующие требования: • Поддержка всех версий Ms Sql Server, начиная с 2008; • Скрипты нужно формировать параллельно (скриптование любой базы данных должно длиться секунды, а не минуты); • Структуру хранения скриптов необходимо определять в настройках; • Возможность выбора типов объектов, которые нужно заскриптовать (например, получить скрипты только хранимых процедур); • Хранение скриптов в файловой системе, архиве, облачном сервисе.
Первым делом мы попытались запустить скриптование через SMO параллельно, но получили около 60 объектов в секунду, что никуда не годилось. Было решено использовать мета информацию из системных объектов Ms Sql Server, из которой можно было сформировать скрипт. Начали думать, а как по каким-то абстрактным данным сформировать скрипт. И тут на помощь нам пришли El-expressions из Java. После недолгого кодирования получили свой движок шаблонов.Пример шаблона для генерации скрипта primary key:
${templ: if_cont_coll (${PKFields},${ALTER TABLE [${Schema}].[${TableName}] ADD ${templ: if_cont_field_val (${PKName},${ CONSTRAINT [${PKName}] },${})}${ConstraintType} ${PKType} ( ${templ: for (${PKFields}, ${[${FieldName}] ${Order}},${, })} )WITH (${PKProperties})${templ: if_cont_field_val (${PKFileGroup},${ ON [${PKFileGroup}]},${})}${templ: if_cont_coll (${PartitionPKFields},${(${templ: for (${PartitionPKFields},${[${PartitionFieldName}]},${,})})})}})} Данный шаблон по своей логической структуре напоминает описание из MSDN.При загрузке мета информации об объекте базы данных мы формируем набор полей и коллекций. Для конкретного primary key мы получаем такие поля, как Schema, TableName и т.д. Поля, по которым строится ключ, мы загружаем в коллекцию PKFields.
Движок шаблонов позволяет реализовывать любые функции. Например, можно организовать условный оператор IF… ELSE, оператор цикла FOR и т.д. (в примере все функции начинаются с ключевого слова templ::).
Теперь у нас есть шаблоны для каждого типа объекта, настало время решить проблему медленного скриптования.Мы создали специальный файл TypeMapper, который содержит информацию о конкретном типе скриптования. Выдержка из этого файла:
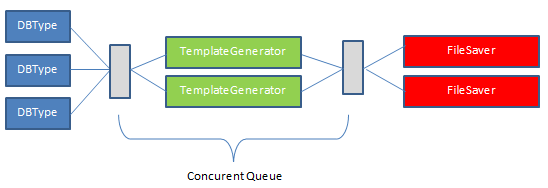
В итоге мы создаем N запросов в Ms Sql Server и по ним формируем объекты-описатели, которые описывают конкретный объект и передаем его в TemplateGenerator через конкурентную очередь. Генератор шаблонов работает параллельно по числу логических ядер и передает готовый скрипт с его именем в FileSaver через еще одну конкурентную очередь. FileSaver сохраняет файлы так же параллельно, в зависимости от пропускной способности дисковой подсистемы.
В итоге база данных, в которой находится 15000 объектов скриптуется за 50 секунд на обычном десктопном компьютере с локальным инстансом Ms Sql Server, тогда как SMO сможет это сделать за 50 минут!
Так же во время скриптования мы формируем специальный граф зависимости, подробнее о котором речь пойдет в следующей части.
Развертывание
В первой части статьи я рассказывал, что вначале мы развертывали скрипты из плоского списка, который формировался разработчиками. Мы решили, что это неудобно и попытались решить эту проблему. При скриптовании мы формируем специальный граф зависимости, в котором находится информация о том, каким по порядку должен быть развернут конкретный скрипт. Таким образом, мы можем выполнять скрипты, находящиеся на одном уровне, параллельно.Вы можете спросить, а что делать, если есть граф зависимости, а в каталог скриптов были добавлены новые скрипты? В таком случае, если скрипт не найден в графе зависимостей, он считается независимым и выполняется в первой партии. Если он «упал», то такой скрипт помещается в очередь «второго шанса». После развертывания всех скриптов происходит повторное развертывание из очереди «второго шанса». Так повторяется, пока новая очередь «второго шанса» не опустеет.
Теоретически может произойти всё, что угодно. Но на практикенередко случается всё, что неугодно.Юрий Татаркин
Итак, что нам удалось получить. Мы научились быстро получать скрипты любых объектов базы данных. Выполнять скрипты, учитывая их зависимости. Что мы сделали из этих возможностей.
Spindle Scripting Tool — десктопное приложение, которое позволяет в несколько кликов получить скрипты базы данных, выбрав типы объектов для скриптования. Можно изменить шаблоны формирования имен файов скриптов. Скрипты могут быть сохранены на диске, в архиве, в облачном сервисе. Вместе с этим формируется граф зависимости и файл проекта, который позволяет выполнить развертывание, просто выбрав нужный файл проекта.
Spindle SSMS Addin — дополнение для Sql Server Management Studio. Данное дополнение позволяет сформировать скрипты базы данных, выбрав базу в окне Object Explorer. А так же уникальная функциональность — прямо в окне редактора скриптов, выделив объект базы данных, нажать правую кнопку мыши и в контекстном меню выбрать команду получения скрипта. Скрипт сформируется в несколько миллисекунд и откроется в новом окошке редактора. Данная функция, в отличие от встроенной возможности, отлично работает с удаленными серверами.
Ну и на сладкое — мы поняли, что мы можем сравнить 2 базы данных между собой за считанные секунды.
Spindle Comparer — сверхбыстрый компаратор баз данных. Достаточно выбрать любые 2 базы данных и нажать кнопку Compare.
