[Из песочницы] Как мы восстанавливали поврежденный .wav файл
Был интересный опыт, когда с другом восстанавливали .wav файл. Я решил описать наш мучительный процесс, вдруг кому-то пригодится.
Предыстория
Бывают грустные истории, когда диктофон зависает/или выдает ошибку при сохранении файла. Следовательно, при попытке открыть поврежденный файл мы получаем ошибки, типа: не удалось декодировать формат, неверный формат или программа не распознала формат файла.
Пытаемся разобраться
Так как открыть файл у нас не получилось, решили по гуглить. Мы хотели понять, как скормить .wav файл проигрывателю. Нашли кучу советов: загрузить его в Raw (сыром формате), поиграться с настройками и т.д. Все эти попытки потерпели фиаско.
Решили изучить, что такое вообще wav, нашли инфу про заголовки и их описание:

Устанавливаем хекс редактор (wxHexEditor), открываем и пытаемся хоть что-то найти похожее на заголовок.
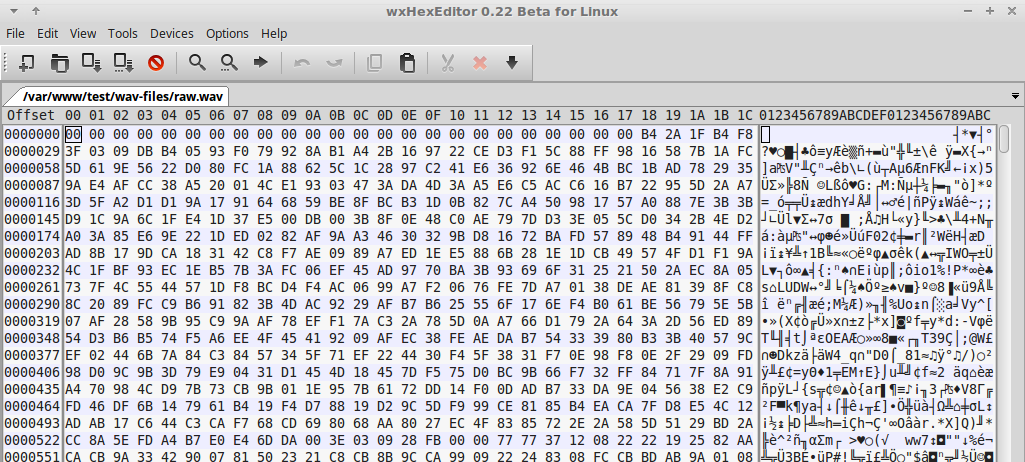
Провал… их не было.
Решили записать новую запись с удачным сохранением. Открыли его в редакторе и смотрим заголовки.
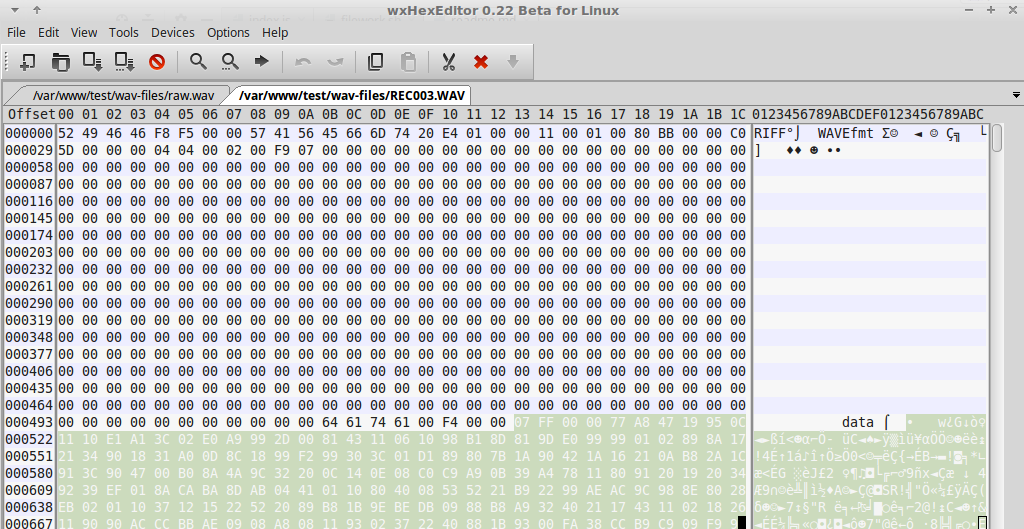
Копируем заголовки и вставляем в наш битый файл (далее БФ)! Судорожно сохраняем и запускаем файл в проигрывателе, и ничего не работает! (Я, как настоящий мужик, начал рыдать в углу комнаты)
Перед тем как что-то построить, нужно что-то сломать.
Мы решили разобраться, как можно сломать нормальный файл и получить такую уродскую картину, как поврежденный файл.
Рисунок: сверху склеенный БФ, внизу нормальная запись.
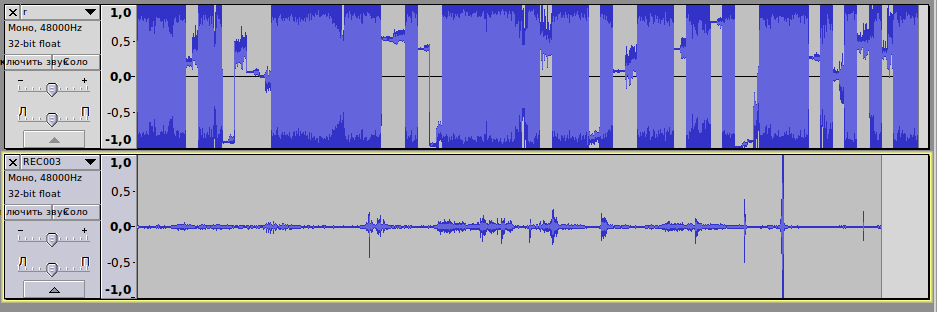
Оказалось что, если удалить в хексРедаторе 1 байт в нормальном файле и сохранить, картина становится похожей. А если вернуть байт, даже пустой забитый нулями, то все становится нормально.
Написание баш скрипта
Решили побайтово удалять и сохранять файл, чтобы получить нормальную картину, как на рисунке выше. Создали 2 файла, один только заголовки, а другой поврежденный файл (предварительно его обрезав чуть меньше мегабайта).
Написали небольшой скрипт, который удаляет один байт из файла и склеивает с заголовком, после чего сохраняет с порядковым номером.
#!/bin/bash
for i in {1..1000}
do
cat header.wav > "./wav/$i.wav"
tail -c +$i raw.wav >> "./wav/$i.wav"
done
Запускаем скрипт и с трепетом, на краешке стульчика, ждем результат. К сожалению, нам пришлось просматривать эти файлы вручную, но как лучше сделать по другому мы не знали. Закидывали по 250 файлов в audacity и просматривали дорожки:
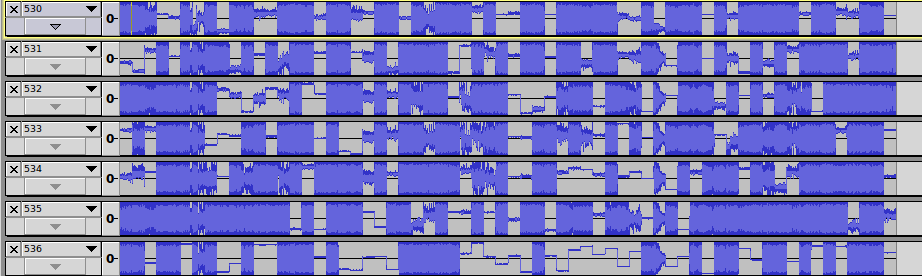
Скроллить пришлось недолго, потому что на 537 файле мы нашли, то что искали:
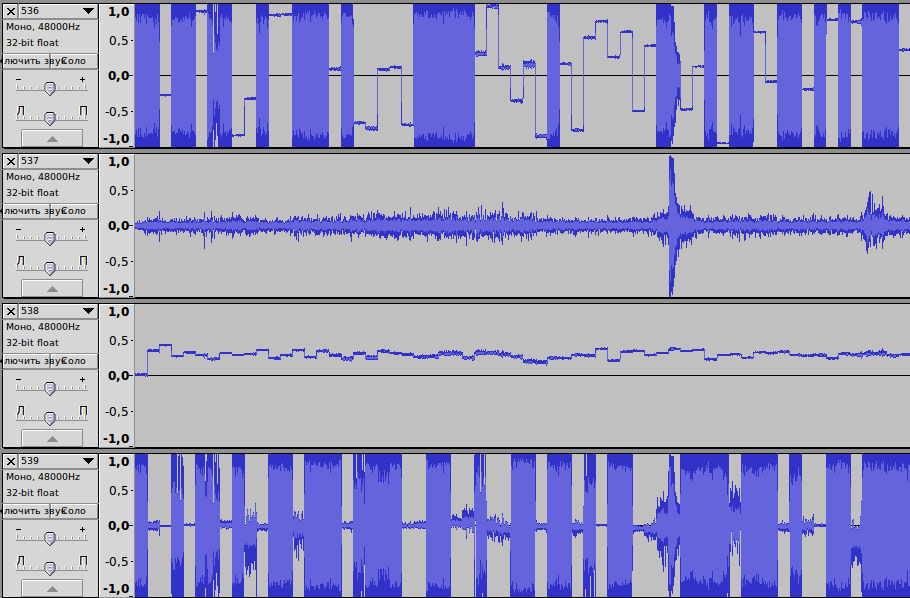
Осталось дело за малым. Смотрим этот файл в хеш редаторе, где он остановился. Открываем БФ в редакторе и удаляем после заголовка нужную нам длину байтов. Вот и все, двухчасовой файл нормально воспроизводится.
P.S.
Скорее всего, это можно было сделать проще. Кто знает, как облегчить работу или как-то ее оптимизировать, пишите, добавлю в этот «гайд».
Всем спасибо за внимание.
