[Из песочницы] Как я восстанавливал данные в неизвестном формате с магнитной ленты
Предыстория
Будучи любителем ретро железа, приобрёл я как-то у продавца из Великобритании ZX Spectrum+. В комплекте с самим компьютером мне достались несколько аудиокассет с играми (в оригинальной упаковке с инструкциями), а также программами, записанными на кассеты без особых обозначений. На удивление данные с кассет 40-летней давности хорошо читались и мне удалось загрузить почти все игры и программы с них.

Однако, на некоторых кассетах я обнаружил записи, сделанные явно не компьютером ZX Spectrum. Звучали они совершенно по-другому и, в отличие от записей с упомянутого компьютера, не начинались с короткого BASIC загрузчика, который обычно присутствует в записях всех программ и игр.
Какое-то время мне не давало это покоя — очень хотелось узнать, что скрыто в них. Если бы получилось прочитать аудио сигнал как последовательность байтов, можно было бы поискать в них символы или что-то, что указывает на происхождение сигнала. Своего рода ретро-археология.
Сейчас, когда я прошёл весь путь и смотрю на этикетки самих кассет, я улыбаюсь, потому что
На этикетке левой кассеты — название компьютера TRS-80, и чуть ниже название производителя: «Manufactured by Radio Shack in USA»
(Если хотите сохранить интригу до конца, не заходите под спойлер)
Сравнение аудио сигналов
Первым делом оцифруем аудиозаписи. Можно послушать как это звучит:
И как обычно звучит запись с компьютера ZX Spectrum:
В обоих случаях в начале записи присутствует так называемый пилотный тон — звук одной частоты (на первой записи он очень короткий
Надо сказать о самой форме сигнала. Например, на ZX Spectrum его форма прямоугольная:
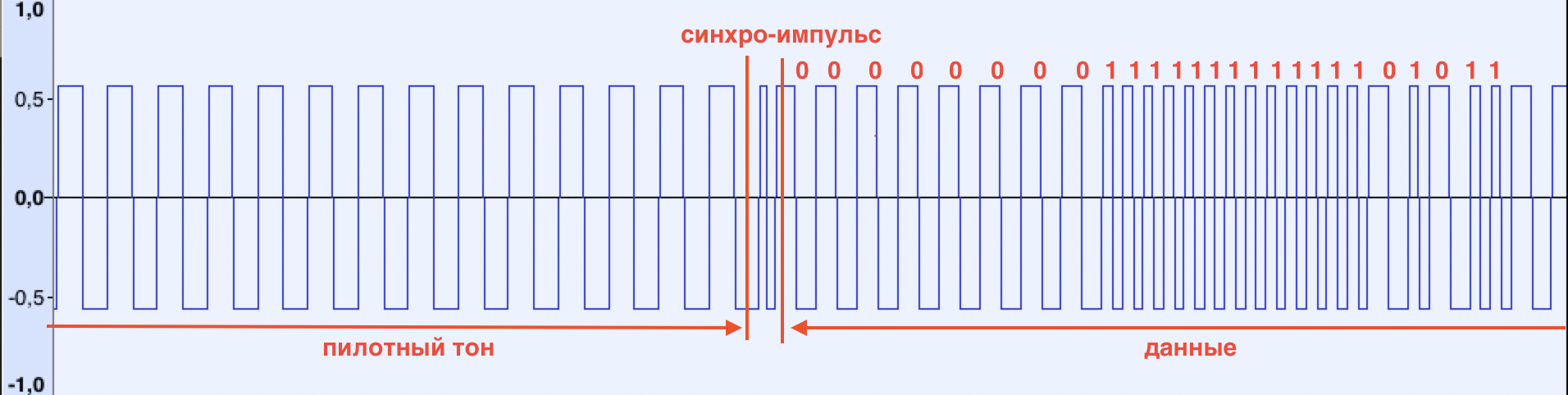
При обнаружении пилотного тона ZX Spectrum отображает чередующиеся красно-голубые полоски на бордюрной части экрана, показывая, что сигнал распознан. Пилотный тон заканчивается синхро-импульсом, который сигнализирует компьютеру о том, что следует начинать принимать данные. Он характеризуется меньшей (по сравнению с пилотным тоном и последующими данными) длительностью (см. рисунок)
После того, как синхро-импульс получен, компьютер фиксирует каждый подъём/спуск сигнала, измеряя его длительность. Если длительность меньше опредёленной границы, в память записывается бит 1, иначе 0. Биты собираются в байты и процесс повторяется до тех пор пока не будет получено N байт. Число N, как правило, берётся из заголовка загружаемого файла. Последовательность загрузки следующая:
- пилотный тон
- заголовок (фиксированной длины), содержит размер загружаемых данных (N), имя и тип файла
- пилотный тон
- сами данные
Чтобы удостовериться, что данные загружены верно, ZX Spectrum последним байтом читает так называемый байт чётности (parity byte), который вычисляется при сохранении файла операцией XOR над всеми байтами записанных данных. При чтении файла компьютер вычисляет байт чётности из полученных данных и, если результат отличается от сохранённого, выводит сообщение об ошибке «R Tape loading error». Строго говоря, компьютер может выдать это сообщение и раньше, если при чтении не может распознать импульс (пропущен или его длительность не соответствует определённым границам)
Итак, посмотрим теперь, как выглядит неизвестный сигнал:
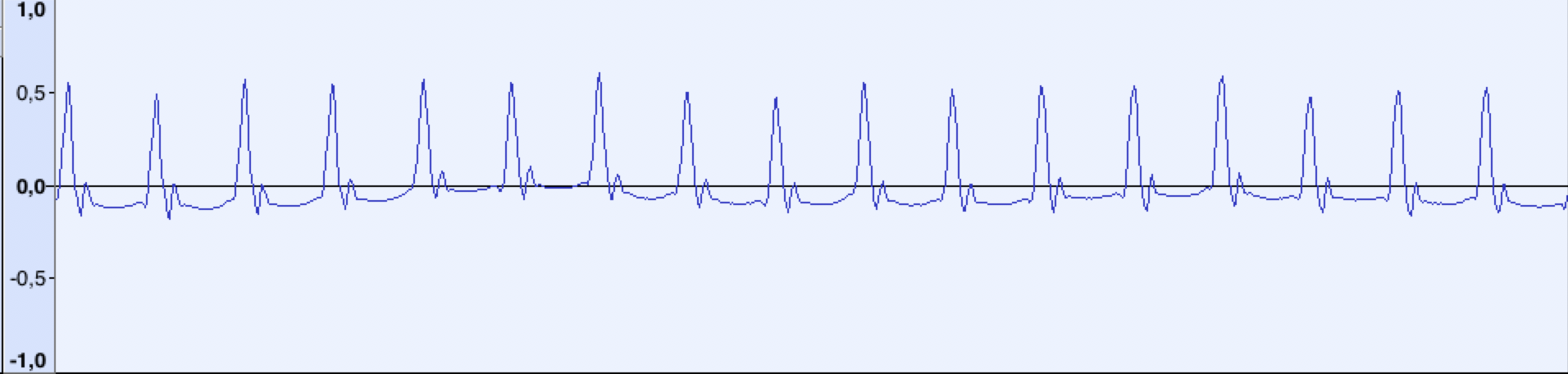
Это пилотный тон. Форма сигнала значительно отличается, но видно что сигнал состоит из повторяющихся коротких импульсов определённой частоты. При частоте дискретизации 44100 Гц, расстояние между «пиками» примерно равно 48 сэмплов (что соответствует частоте ~918 Гц) Запомним эту цифру.
Посмотрим теперь на фрагмент с данными:
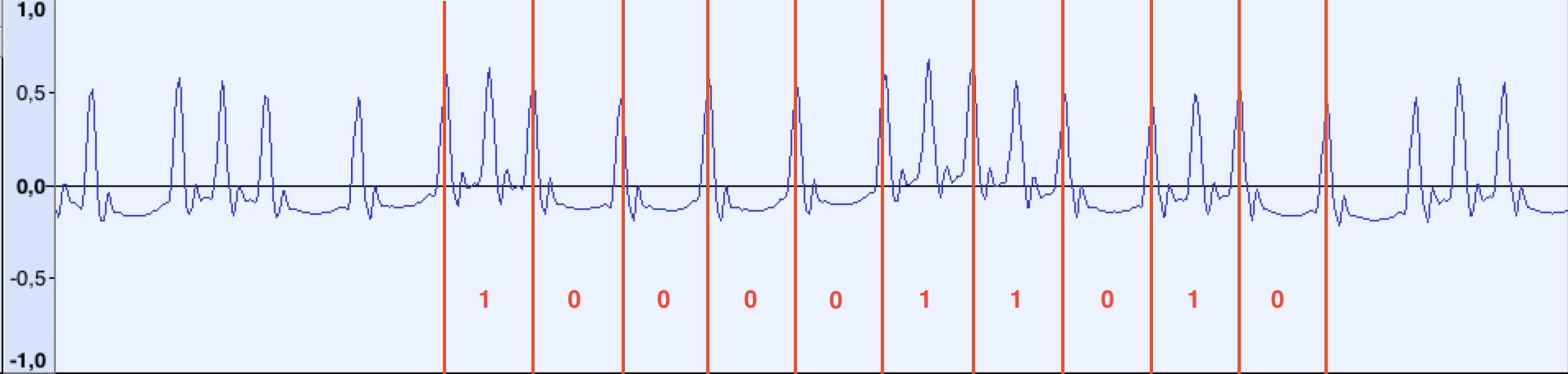
Если измерить расстояние между отдельными импульсами, окажется, что между «длинными» импульсами расстояние по-прежнему в ~48 сэмплов, а между короткими — ~24. Немного забегая вперёд, скажу, что в итоге выяснилось, «опорные» импульсы с частотой 918 Гц следуют непрерывно, от начала и до конца файла. Можно предположить, что при передаче данных, если между опорными импульсами встречается дополнительный импульс, считаем его за бит 1, иначе 0.
Что с синхро-импульсом? Посмотрим на начало данных:
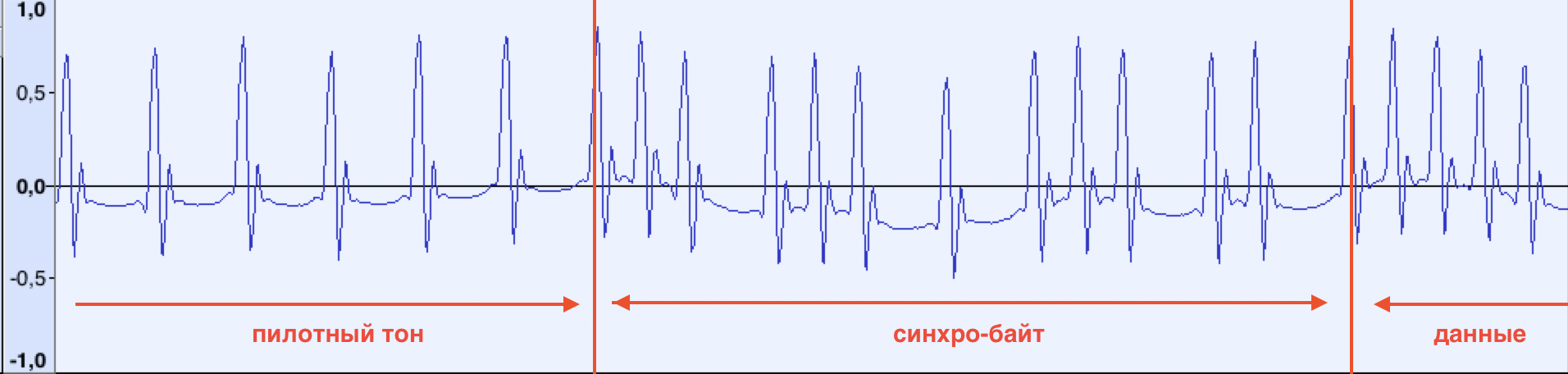
Пилотный тон заканчивается и сразу начинаются данные. Чуть позже, проанализировав несколько разных аудио записей, удалось обнаружить, что первый байт данных всегда один и тот же (10100101b, A5h). Возможно, компьютер начинает считывать данные, после того как получит его.
Можно также обратить внимание на сдвиг первого опорного импульса сразу после последней 1-цы в синхробайте. Его удалось обнаружить значительно позже в процессе разработки программы для распознавания данных, когда данные в начале файла не могли стабильно считаться.
Теперь попробуем описать алгоритм, который обработает аудио файл и загрузит данные.
Загрузка данных
Сперва рассмотрим несколько допущений, чтобы не усложнять алгоритм:
- Будем рассматривать файлы только в формате WAV;
- Аудиофайл должен начинаться с пилотного тона и не должен содержать тишину в начале
- Исходный файл должен иметь частоту дискретизации 44100 Гц. В таком случае расстояние между опорными импульсами в 48 сэмплов уже определено и нам не нужно программно его рассчитывать;
- Формат сэмплов может быть любой (8/16 бит/с плавающей точкой) — так как при чтении мы можем сконвертировать его в нужный;
- Предполагаем, что исходный файл нормализован по амплитуде, что должно стабилизировать результат;
Алгоритм чтения будет следующий:
- Читаем файл в память, одновременно конвертируем формат сэмплов в 8 бит;
- Определяем позицию первого импульса в аудиоданных. Для этого нужно узнать вычислить номер сэмпла с максимальной амплитудой. Для простоты посчитаем его один раз вручную. Сохраним в переменную prev_pos;
- Прибавляем к позиции последнего импульса 48 (pos:= prev_pos + 48)
- Так как увеличение позиции на 48 не гарантирует, что мы попадём в позицию следующего опорного импульса (дефекты ленты, нестабильная работа лентопротяжного механизма и прочее), нужно откорректировать позицию импульса pos. Для этого возьмем небольшой отрезок данных (pos-8; pos+8) и найдем на нём максимум значения амплитуды. Позицию, соответствующую максимуму, сохраним в pos. Здесь 8 = 48/6 — экспериментально полученная константа, которая гарантирует что мы определим верный максимум и не затронем другие импульсы, которые могут идти рядом. В очень плохих случаях, когда расстояние между импульсами сильно меньше или больше 48, можно реализовать принудительный поиск импульса, но в рамках статьи я не буду описывать это в алгоритме;
- На предыдущем шаге также необходимо бы проверить, что опорный импульс вообще найден. То есть, если просто искать максимум, это не гарантирует что импульс в данном отрезке присутствует. В своей последней реализации программы чтения я проверяю разницу между максимальным и минимальным значением амплитуды на отрезке, и если она превышает некоторую границу, засчитываю наличие импульса. Вопрос также, что делать если опорный импульс не найден. Тут 2 варианта: либо данные закончились и далее следует тишина, либо это следует рассматривать как ошибку чтения. Однако опустим это для упрощения алгоритма;
- На следующем шаге нужно определить наличие импульса данных (бит 0 или 1), для этого возьмем середину отрезка (prev_pos; pos) middle_pos равную middle_pos:= (prev_pos+pos)/2 и в некоторой окрестности middle_pos на отрезке (middle_pos-8; middle_pos+8) посчитаем максимум и минимум амплитуды. Если разница между ними больше 10, записываем в результат бит 1 иначе 0. 10 — константа полученная опытным путём;
- Сохраняем текущую позицию в prev_pos (prev_pos:= pos)
- Повторяем начиная с шага 3, пока не прочитаем весь файл;
- Полученный битовый массив необходимо сохранить как набор байт. Поскольку мы не учли синхро-байт при чтении, количество битов может оказаться не кратно 8, а также неизвестно необходимое смещение в битах. В первой реализации алгоритма я не знал о существовании синхро-байта и потому просто сохранял 8 файлов с разным количеством бит смещения. Один из них содержал корректные данные. В финальном алгоритме я просто удаляю все биты до A5h, что позволяет сразу получать корректный файл на выходе
# Используем gem 'wavefile'
require 'wavefile'
reader = WaveFile::Reader.new('input.wav')
samples = []
format = WaveFile::Format.new(:mono, :pcm_8, 44100)
# Читаем WAV файл, конвертируем в формат Mono, 8 bit
# Массив samples будет состоять из байт со значениями 0-255
reader.each_buffer(10000) do |buffer|
samples += buffer.convert(format).samples
end
# Позиция первого импульса (вместо 0)
prev_pos = 0
# Расстояние между импульсами
distance = 48
# Значение расстояния для окрестности поиска локального максимума
delta = (distance / 6).floor
# Биты будем сохранять в виде строки из "0" и "1"
bits = ""
loop do
# Рассчитываем позицию следующего импульса
pos = prev_pos + distance
# Выходим из цикла если данные закончились
break if pos + delta >= samples.size
# Корректируем позицию pos обнаружением максимума на отрезке [pos - delta;pos + delta]
(pos - delta..pos + delta).each { |p| pos = p if samples[p] > samples[pos] }
# Находим середину отрезка [prev_pos;pos]
middle_pos = ((prev_pos + pos) / 2).floor
# Берем окрестность в середине
sample = samples[middle_pos - delta..middle_pos + delta]
# Определяем бит как "1" если разница между максимальным и минимальным значением на отрезке превышает 10
bit = sample.max - sample.min > 10
bits += bit ? "1" : "0"
end
# Определяем синхро-байт и заменяем все предшествующие биты на 256 бит нулей (согласно спецификации формата)
bits.gsub! /^[01]*?10100101/, ("0" * 256) + "10100101"
# Сохраняем выходной файл, упаковывая биты в байты
File.write "output.cas", [bits].pack("B*")
Результат
Перепробовав несколько вариантов алгоритма и констант, мне повезло получить что-то в крайней степени интересное:
Итак, судя по символьным строкам, мы имеем программу для построения графиков. Однако в тексте программы отсутствуют ключевые слова. Все ключевые слова закодированы в виде байтов (значение каждого > 80h). Теперь нужно выяснить, какой компьютер из 80-х мог сохранять программы в таком формате.
На самом деле это очень похоже на программу на языке BASIC. Примерно в таком же формате компьютер ZX Spectrum хранит в памяти и сохраняет программы на ленту. На всякий случай я проверил ключевые слова на соответствие с таблицей. Однако результат, очевидно, оказался отрицательным.
Также я проверил ключевые слова BASIC популярных в то время компьютеров Atari, Commodore 64 и нескольких других, на которые удалось найти документацию, однако безуспешно — мои познания в разновидностях ретро-компьютеров оказались не столь широки.
Тогда я решил пойти по списку, и тут мой взгляд упал на название производителя Radio Shack и компьютера TRS-80. Именно эти названия были написаны на этикетках кассет, которые лежали у меня на столе! Я ведь не знал ранее эти названия и не был знаком с компьютером TRS-80, поэтому мне казалось, что Radio Shack это производитель аудиокассет, такой кaк BASF, Sony или TDK, a TRS-80 — длительность воспроизведения. Почему нет?
Компьютер Tandy/Radio Shack TRS-80
Очень вероятно, что рассматриваемая аудиозапись, которую я привёл в качестве примера в начале статьи, сделана на таком компьютере:

Оказалось, что данный компьютер и его разновидности (Model I/Model III/Model IV и т.д.) были очень популярны в свое время (конечно, не в России). Примечательно, что процессор, которых в них использовался — тоже Z80. По данному компьютеру в Интернете можно найти много информации. В 80-х годах информация о компьютере распространялась в журналах. На данный момент существует несколько эмуляторов компьютера под разные платформы.
Я загрузил эмулятор trs80gp и мне впервые удалось посмотреть как работал этот компьютер. Конечно, компьютер не поддерживал вывод цвета, разрешение экрана всего 128×48 точек, но существовало множество расширений и модификаций которые могли увеличивать разрешение экрана. Также существовало множество вариантов операционных систем для данного компьютера и вариантов реализации языка BASIC (который, в отличие от ZX Spectrum, в некоторых моделях даже не был «прошит» в ПЗУ и любой вариант мог загружаться с дискеты, также как и сама ОС)
Также я нашёл утилиту для конвертирования аудиозаписей в формат CAS, которых поддерживается эмуляторами, однако прочитать с их помощью записи с моих кассет по каким-то причинам не удалось.
Разобравшись с форматом файла CAS (который оказался просто побитовой копией данных с ленты, которая у меня уже имелась на руках, за исключением заголовка с наличием синхро-байта), я внес несколько изменений в свою программу и смог получить на выходе рабочий CAS файл, который заработал в эмуляторе (TRS-80 Model III):
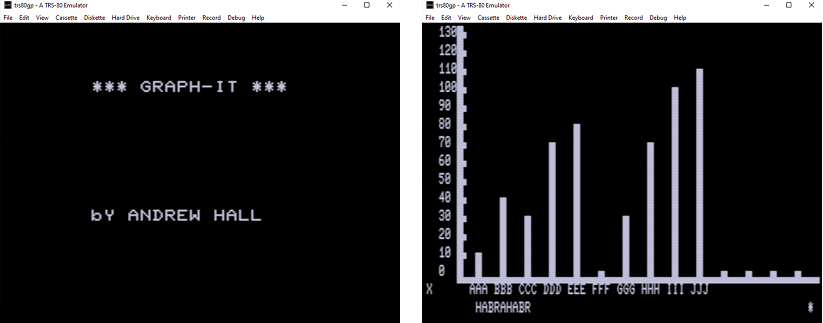
Последний вариант утилиты для конвертации с автоматическим определением первого импульса и расстоянием между опорными импульсами я оформил в виде GEM пакета, исходный код доступен на Github.
Заключение
Пройденный путь оказался увлекательным путешествием в прошлое, и я рад что в итоге нашёл разгадку. Помимо прочего я:
- Разобрался с форматом сохранения данных в ZX Spectrum и изучил встроенные в ПЗУ подпрограммы сохранения/чтения данных с аудиокассет
- Познакомился с компьютером TRS-80 и его разновидностями, изучил операционную систему, посмотрел примеры программ и даже имел возможность заняться отладкой в машинных кодах (всё-таки все мнемоники Z80 мне хорошо знакомы)
- Написал полноценную утилиту для конвертирования аудио записей в CAS формат, которая может считывать данные, нераспознаваемые «официальной» утилитой
