[Из песочницы] Как я парсил БД C-Tree, разработанную 34 года назад

Прилетела мне недавно задача дополнить функционал одной довольно старой програмки (исходного кода программы нет). По сути нужно было просто сканить периодически БД, анализировать информацию и на основе этого совершать рассылки. Вся сложность оказалась в том, что приложение работает с БД c-tree и написано аж в 1984 году.
Порывшись на сайте производителя данной БД нашёл некий odbc драйвер, однако у меня никак не получалось его подключить. Многочисленные гугления так же не помогли нормально сконнектиться с базой и доставать данные. Позже было решено связаться с техподдержкой и попросить помощи у разработчиков данной базы, однако ребята честно признались что уже прошло 34 года, всё поменялось 100500 раз, нормальных драйверов для подключения на такое старьё у них нет и небось уже тех программистов в живых тоже нету, которые писали сие чудо.
Порывшись в файлах БД и изучив структуру, я понял, что каждая таблица в БД сохраняется в два файла с расширением *.dat и *.idx. Файл idx хранит информацию по id, индексам и т.д. для более быстрого поиска информации в базе. Файл dat содержит саму информацию, которая хранится в табличках.
Решено было парсить эти файлики самостоятельно и как-то добывать эту информацию. В качестве языка использовался Go, т.к. весь остальной проект написан на нём.
Я опишу только самый интересные моменты, с которыми я столкнулся при обработке данных, которые в основном затрагивают не сам язык Go, а именно алгоритмы вычислений и магию математики.
С ходу понять что где в файлах нереально, так как нормальной кодировки там нет, данные записываются в какие-то определённые биты и изначально больше похоже на мусорку данных.

Вдохновляющую фразочку я получил от клиента с небольшим описанием, почему так:»**** was a MS-DOS application running on 8086 processors and memory was scarce».
Логика работы была таковой: назначаю в программе какие-то новые данные, смотрю какие файлы изменялись и затем пытаюсь выщемить биты данных, которые поменяли значения.
В процессе разработки я понял следующие важные правила, которые мне помогли разобраться быстрее:
- начало и конец файла (размер всегда разный) зарезервированы под табличные данные
- длинна строки в таблице занимает всегда одно и то же количество байт
- вычисления проводятся в 256ричной системе
Время в расписании
В приложении создаётся расписание с интервалом в 15 минут (Например 12:15 — 14:45). Потыкав в разное время, нашёл область памяти, которая отвечает за часы. Я считываю данные из файла побайтово. Для времени используется 2 байта данных.
Каждый байт может содержать значение от 0 до 255. При добавлении в расписание 15 минут в первый байт добавляется число 15. Плюсуем ещё 15 минут и в байте уже число 30 и т.д.
Например у нас следующие значения:
[0] [245]
Как только значение превышает 255, в следующий байт добавляется 1, а в текущий записывается остаток.
245 + 15 = 260
260 — 256 = 4
Итого имеем значение в файле:
[1] [4]
А теперь внимание! Очень интересная логика. Если это диапазон с 0 минут до 45 минут в часе, то в байты добавляется по 15 минут. НО! Если это последние 15 минут в часе (с 45 до 60), то в байты добавляется число 65.
Получается что 1 час всегда равен числу 100. Если у нас 15 часов 45 минут, то в файле мы увидим такие данные:
[6] [9]
А теперь включаем немного магии и переводим значения из байтов в целое число:
6×256 + 9 = 1545
Если разделить это число на 100, то целая часть будет равна часам, а дробная — минутам:
1545/100 = 15.45
Кодяра:
data, err := ioutil.ReadFile(defaultPath + scheduleFileName)
if err != nil {
log.Printf("[Error] File %s not found: %v", defaultPath+scheduleFileName, err)
}
timeOffset1 := 98
timeOffset2 := 99
timeSize := 1
//first 1613 bytes reserved for table
//one record use 1598 bytes
//last 1600 bytes reserved for end of table
for position := 1613; position < (len(data) - 1600); position += 1598 {
...
timeInBytesPart1 := data[(position + timeOffset2):(position + timeOffset2 + timeSize)]
timeInBytesPart2 := data[(position + timeOffset1):(position + timeOffset1 + timeSize)]
totalBytes := (int(timeInBytesPart1[0]) * 256) + int(timeInBytesPart2[0])
hours := totalBytes / 100
minutes := totalBytes - hours*100
...
}
Дата в расписании
Логика работы вычисления значения из байт для дат такая же как и во времени. Байт заполняется до 255, затем обнуляется, а в следующий байт добавляется 1 и т.д. Только для даты уже было выделено не два, а четыре байта памяти. Видимо разработчики решили, что их приложение может прожить ещё несколько миллионов лет. Получается, что максимальное число, которое мы можем получить равно:
[255] [255] [255] [256]
256×256 * 256×256 + 256×256 * 256 + 256×256 + 256 = 4311810304
Эталонная стартовая дата в приложении равна 31 декабря 1849. Конкретную дату считаю путём добавления дней. Я изначально знаю, что AddDate из пакета time имеет ограничение и не сможет скушать 4311810304 дней, однако на ближайшие лет 200 хватит)
Кодяра:
func getDate(data []uint8) time.Time {
startDate := time.Date(1849, 12, 31, 0, 00, 00, 0, time.UTC)
var result int
for i := 0; i < len(data)-1; i++ {
var sqr = 1
for j := 0; j < i; j++ {
sqr = sqr * 256
}
result = result + (int(data[i]) * sqr)
}
return startDate.AddDate(0, 0, result)
}
Расписание доступности
У сотрудников есть расписание доступности. В день можно назначить до трёх интервалов времени. Например:
8:00 — 13:00
14:00 — 16:30
17:00 — 19:00
Расписание может быть назначено на любой день недели. Мне необходимо было сгенерировать расписание на ближайшие 3 месяца.
Вот примерная схема хранения данных в файле:
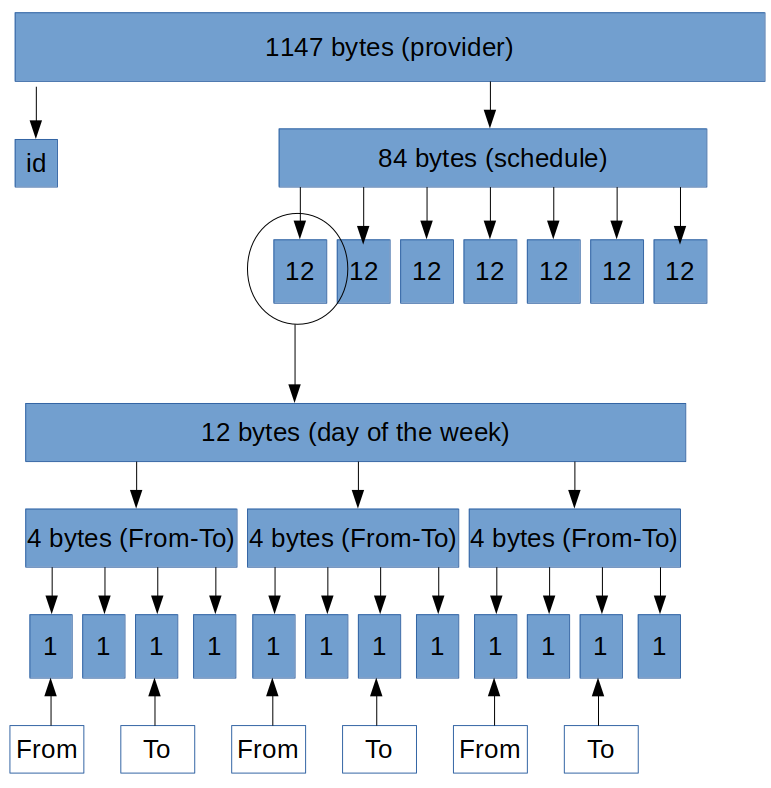
Я вырезаю из файла каждую запись по отдельности, затем смещаюсь на определённое количество байт в зависимости от дня недели и там уже обрабатываю время.
Кодяра:
type Schedule struct {
ProviderID string `json:"provider_id"`
Date time.Time `json:"date"`
DayStart string `json:"day_start"`
DayEnd string `json:"day_end"`
Breaks *ScheduleBreaks `json:"breaks"`
}
type SheduleBreaks []*cheduleBreak
type ScheduleBreak struct {
Start time.Time `json:"start"`
End time.Time `json:"end"`
}
func ScanSchedule(config Config) (schedules []Schedule, err error) {
dataFromFile, err := ioutil.ReadFile(config.DBPath + providersFileName)
if err != nil {
return schedules, err
}
scheduleOffset := 774
weeklyDayOffset := map[string]int{
"Sunday": 0,
"Monday": 12,
"Tuesday": 24,
"Wednesday": 36,
"Thursday": 48,
"Friday": 60,
"Saturday": 72,
}
//first 1158 bytes reserved for table
//one record with contact information use 1147 bytes
//last 4494 bytes reserved for end of table
for position := 1158; position < (len(dataFromFile) - 4494); position += 1147 {
id := getIDFromSliceByte(dataFromFile[position:(position + idSize)])
//if table border (id equal "255|255"), then finish parse file
if id == "255|255" {
break
}
position := position + scheduleOffset
date := time.Now()
//create schedule on 3 future month (90 days)
for dayNumber := 1; dayNumber < 90; dayNumber++ {
schedule := Schedule{}
offset := weeklyDayOffset[date.Weekday().String()]
from1, to1 := getScheduleTimeFromBytes((dataFromFile[(position + offset):(position + offset + 4)]), date)
from2, to2 := getScheduleTimeFromBytes((dataFromFile[(position + offset + 1):(position + offset + 4 + 1)]), date)
from3, to3 := getScheduleTimeFromBytes((dataFromFile[(position + offset + 2):(position + offset + 4 + 2)]), date)
//no schedule on this day
if from1.IsZero() {
continue
}
schedule.Date = time.Date(date.Year(), date.Month(), date.Day(), 0, 0, 0, 0, time.UTC)
schedule.DayStart = from1.Format(time.RFC3339)
switch {
case to3.IsZero() == false:
schedule.DayEnd = to3.Format(time.RFC3339)
case to2.IsZero() == false:
schedule.DayEnd = to2.Format(time.RFC3339)
case to1.IsZero() == false:
schedule.DayEnd = to1.Format(time.RFC3339)
}
if from2.IsZero() == false {
scheduleBreaks := ScheduleBreaks{}
scheduleBreak := ScheduleBreak{}
scheduleBreak.Start = to1
scheduleBreak.End = from2
scheduleBreaks = append(scheduleBreaks, &scheduleBreak)
if from3.IsZero() == false {
scheduleBreak.Start = to2
scheduleBreak.End = from3
scheduleBreaks = append(scheduleBreaks, &scheduleBreak)
}
schedule.Breaks = &scheduleBreaks
}
date = date.AddDate(0, 0, 1)
schedules = append(schedules, &schedule)
}
}
return schedules, err
}
//getScheduleTimeFromBytes calculate bytes in time range
func getScheduleTimeFromBytes(data []uint8, date time.Time) (from, to time.Time) {
totalTimeFrom := int(data[0])
totalTimeTo := int(data[3])
//no schedule
if totalTimeFrom == 0 && totalTimeTo == 0 {
return from, to
}
hoursFrom := totalTimeFrom / 4
hoursTo := totalTimeTo / 4
minutesFrom := (totalTimeFrom*25 - hoursFrom*100) * 6 / 10
minutesTo := (totalTimeTo*25 - hoursTo*100) * 6 / 10
from = time.Date(date.Year(), date.Month(), date.Day(), hoursFrom, minutesFrom, 0, 0, time.UTC)
to = time.Date(date.Year(), date.Month(), date.Day(), hoursTo, minutesTo, 0, 0, time.UTC)
return from, to
}
В целом хотелось просто поделиться знаниями о том, какими алгоритмами вычислений пользовались раньше.
