[Из песочницы] Julia. Работа с таблицами
Julia — один из самых молодых математических языков программирования, претендующий на роль основного языка программирования в этой сфере. К сожалению, на данный момент достаточно мало литературы на русском языке, а материалы, доступные на английском языке, содержат сведения, которые, в силу динамичности развития Julia, не всегда соответствуют текущей версии, но это не очевидно для начинающих Julia-программистов. Постараемся восполнить пробелы и донести идеи Julia до читателей в виде простых примеров.
Целью этой статьи является дать представление читателям об основных способах работы c таблицами в языке программирования Julia с тем, чтобы побудить начать использовать этот язык программирования для обработки реальных данных. Предполагаем, что читатель уже знаком с другими языками программирования, поэтому будем давать лишь минимальные сведения о том, как это делается, но не будем вдаваться в детали методов обработки данных.
Безусловно, одним из важнейших этапов работы программы, выполняющей анализ данных, является их импорт и экспорт. Причем, наиболее распространенный формат представления данных — это таблица. Существуют библиотеки для Julia, которые предоставляют доступ к реляционным СУБД, используют обменные форматы типа HDF5, MATLAB, JLD. Но в данном случае нас будет интересовать только текстовый формат представления таблиц, типа CSV.
Прежде чем рассматривать таблицы, необходимо сделать небольшое введение в особенности представления этой структуры данных. Для Julia таблица может быть представлена как двумерный массив или как DataFrame.
Массивы
Начнём с массивов в Julia. Нумерация элементов начинается с единицы. Это вполне естественно для математиков, а, кроме того, такая же схема используется в Fortran, Pascal, Matlab. Для программистов, никогда не использовавших эти языки, такая нумерация может показаться неудобной и стать причиной ошибок при написании граничных условий, но, в действительности, это лишь вопрос привычки. После пары недель использования Julia вопрос переключения между моделями языков уже не возникает.
Второй существенный момент этого языка — внутреннее представление массивов. Для Julia линейный массив — это столбец. В то же время для языков типа C, Java, одномерный массив — это строка.
Проиллюстрируем это массивом, созданном в командной строке (REPL)
julia> a = [1, 2, 3]
3-element Array{Int64,1}:
1
2
3
Обратите внимание на тип массива — Array{Int64,1}. Массив одномерный, типа Int64. При этом, если мы хотим объединить этот массив с другим массивом, то, поскольку имеем дело со столбцом, мы должны использовать функцию vcat (то есть vertical concatenate). Итогом получаем новый столбец.
julia> b = vcat(a, [5, 6, 7])
7-element Array{Int64,1}:
1
2
3
5
6
7
Если же мы создаём массив как строку, то при записи литерала используем пробелы вместо запятых и получаем двумерный массив с типом Array{Int64,2}. Второй аргумент в декларации типа означает количество координат многомерного массива.
julia> c = [1 2 3]
1×3 Array{Int64,2}:
1 2 3
То есть мы получили матрицу с одной строкой и тремя столбцами.
Эта схема представления строк и столбцов также характерна для Fortran и Matlab, но, следует лишь напомнить, что Julia — это язык, который именно на их область применения и ориентирован.
Матрица для Julia — это двумерный массив, где все ячейки имеют один тип. Обратим внимание на то, что тип может быть абстрактный Any или вполне конкретный, такой как Int64, Float64 или, даже, String.
Создать матрицу мы можем в форме литерала:
julia> a = [1 2; 3 4]
2×2 Array{Int64,2}:
1 2
3 4
Создать при помощи конструктора и выделить память без инициализации (undef):
julia> a = Array{Int64,2}(undef, 2, 3)
2×3 Array{Int64,2}:
4783881648 4783881712 4782818640
4783881680 4783881744 4782818576
Или с инициализацией, если вместо undef будет указано любое конкретное значение.
Склеить из отдельных колонок:
julia> a = [1, 2, 3]
3-element Array{Int64,1}:
1
2
3
julia> b = hcat(a, a, a, a)
3×4 Array{Int64,2}:
1 1 1 1
2 2 2 2
3 3 3 3
Инициализировать случайным образом:
julia> x = rand(1:10, 2, 3)
2×3 Array{Int64,2}:
1 10 2
9 7 7
Аргументы rand — диапазон от 1 до 10 и размерность 2×3.
Или использовать включение (Comprehensions)
julia> x = [min(i, j) for i = 0:2, j = 0:2 ]
3×3 Array{Int64,2}:
0 0 0
0 1 1
0 1 2
Отметим, что тот факт, что для Julia столбцы представляют собой линейный блок памяти, приводит к тому, что перебор элементов именно по столбцу будет существенно быстрее, чем перебор по строкам. В частности, в следующем примере используется матрица 1_000_000 строк и 100 столбцов.
#!/usr/bin/env julia
using BenchmarkTools
x = rand(1:1000, 1_000_000, 100)
#x = rand(1_000_000, 100)
function sumbycolumns(x)
sum = 0
rows, cols = size(x)
for j = 1:cols,
i = 1:rows
sum += x[i, j]
end
return sum
end
@show @btime sumbycolumns(x)
function sumbyrows(x)
sum = 0
rows, cols = size(x)
for i = 1:rows,
j = 1:cols
sum += x[i, j]
end
return sum
end
@show @btime sumbyrows(x)
Результаты:
74.378 ms (1 allocation: 16 bytes)
=# @btime(sumbycolumns(x)) = 50053093495
206.346 ms (1 allocation: 16 bytes)
=# @btime(sumbyrows(x)) = 50053093495
@btime в примере — многократный запуск функции для расчёта среднего времени её выполнения. Этот макрос предоставляется библиотекой BenchmarkTools.jl. В базовом комплекте Julia имеется макрос time, но он измеряет однократный интервал, что, в данном случае, будет неточно. Макрос show просто выводит в консоль выражение и его вычисленное значение.
Оптимизация хранения по столбцу удобна именно для выполнения статистических операций с таблицей. Поскольку традиционно, таблица ограничена по количеству столбцов, а количество строк может быть любым, то большинство операций, таких как подсчёт среднего, минимального, максимального значений, выполняется именно для столбцов матриц, а не для их строк.
Синонимом для двумерного массива является тип Matrix. Впрочем, это, скорее, является стилевым удобством, а не необходимостью.
Обращение к элементам матрицы выполняется по индексу. Например для ранее созданной матрицы
julia> x = rand(1:10, 2, 3)
2×3 Array{Int64,2}:
1 10 2
9 7 7
Мы можем получить конкретный элемент как x[1, 2] => 10. Так и получить целиком столбец, например второй столбец:
julia> x[:, 2]
2-element Array{Int64,1}:
10
7
Или вторую строку:
julia> x[2, :]
3-element Array{Int64,1}:
9
7
7
Также имеется полезная функция selectdim, где можно задать порядковый номер размерности, для которой следует сделать выборку, а также индексы элементов этой размерности. Например сделать выборку по 2-й размерности (столбцы), выбрав 1 и 3-й индексы. Этот подход удобен тогда, когда в зависимости от условий, надо переключаться между строками и столбцами. Впрочем, это верно и для многомерного случая, когда количество размерностей больше 2-х.
julia> selectdim(x, 2, [1, 3])
2×2 view(::Array{Int64,2}, :, [1, 3]) with eltype Int64:
1 2
9 7
Функции для статистической обработки массивов
Подробнее об одномерных массивах
Многомерные массивы
Функции линейной алгебры и матрицы специального вида
Чтение таблицы из файла можно выполнить при помощи функции readdlm, реализованной в библиотеке DelimitedFiles. Запись — при помощи writedlm. Эти функции обеспечивают работу с файлами с разделителями, частным случаем которых является формат CSV.
Проиллюстрируем примером из документации:
julia> using DelimitedFiles
julia> x = [1; 2; 3; 4];
julia> y = ["a"; "b"; "c"; "d"];
julia> open("delim_file.txt", "w") do io
writedlm(io, [x y]) # записываем таблицу с двумя столбцами
end;
julia> readdlm("delim_file.txt") # Читаем таблицу
4×2 Array{Any,2}:
1 "a"
2 "b"
3 "c"
4 "d"
В данном случае, следует обратить внимание на то, что таблица содержит данные разных типов. Поэтому при чтении файла создаётся матрица с типом Array{Any,2}.
Другой пример — чтение таблиц, содержащих однородные данные
julia> using DelimitedFiles
julia> x = [1; 2; 3; 4];
julia> y = [5; 6; 7; 8];
julia> open("delim_file.txt", "w") do io
writedlm(io, [x y]) # пишем таблицу
end;
julia> readdlm("delim_file.txt", Int64) # читаем ячейки как Int64
4×2 Array{Int64,2}:
1 5
2 6
3 7
4 8
julia> readdlm("delim_file.txt", Float64) # читаем ячейки как Float64
4×2 Array{Float64,2}:
1.0 5.0
2.0 6.0
3.0 7.0
4.0 8.0
С точки зрения эффективности обработки, такой вариант предпочтительнее, поскольку данные будут представлены компактно. В то же время, явное ограничение таблиц, представляемых матрицей — требование однородности данных.
Полные возможности функции readdlm рекомендуем посмотреть в документации. Среди дополнительных опций есть возможность указать режим обработки заголовков, пропуск строк, функцию обработки ячеек и пр.
Альтернативным способом чтения таблиц является библиотека CSV.jl По сравнению с readdlm и writedlm эта библиотека предоставляет существенно большие возможности в управлении опциями записи и чтения, а также проверки данных в файлах с разделителями. Однако принципиальное отличие заключается в том, что результат выполнения функции CSV.File может быть материализован в тип DataFrame.
DataFrames
Библиотека DataFrames обеспечивает поддержку структуры данных DataFrame, которая и ориентирована на представление таблиц. Принципиальным отличием от матрицы здесь является то, что каждый столбец хранится индивидуально, причём каждый столбец имеет своё имя. Вспоминаем, что для Julia по-колоночный режим хранения, вообще, является естественным. И, хотя здесь имеем частный случай одномерных массивов, получается оптимальное решение как с точки зрения скорости, так и гибкости представления данных, поскольку тип каждого столбца может быть индивидуальным.
Посмотрим как создать DataFrame.
Любая матрица может быть конвертирована в DataFrame.
julia> using DataFrames
julia> a = [1 2; 3 4; 5 6]
3×2 Array{Int64,2}:
1 2
3 4
5 6
julia> b = convert(DataFrame, a)
3×2 DataFrame
│ Row │ x1 │ x2 │
│ │ Int64 │ Int64 │
├─────┼───────┼───────┤
│ 1 │ 1 │ 2 │
│ 2 │ 3 │ 4 │
│ 3 │ 5 │ 6 │
Функция convert обеспечивает преобразование данных в указанный тип. Соответственно, для типа DataFrame методы функции convert определены в библиотеке DataFrames (по терминологии Julia, существуют функции, а многообразие их реализаций с разными аргументами называется методами). Следует обратить внимание на то, что столбцам матрицы автоматически присвоены имена x1, x2. То есть, если теперь мы запросим имена столбцов, то получим их в виде массива:
julia> names(b)
2-element Array{Symbol,1}:
:x1
:x2
Причём имена представлены в формате типа Symbol (хорошо знакомом в мире Ruby).
DataFrame может быть создан непосредственно — пустым или содержащим какие-то данные в момент конструирования. Например:
julia> df = DataFrame([collect(1:3), collect(4:6)], [:A, :B])
3×2 DataFrame
│ Row │ A │ B │
│ │ Int64 │ Int64 │
├─────┼───────┼───────┤
│ 1 │ 1 │ 4 │
│ 2 │ 2 │ 5 │
│ 3 │ 3 │ 6 │
Здесь мы указываем массив со значениями столбцов и массив с именами этих столбцов. Конструкции вида collect (1:3) — это преобразование итератора-диапазона от 1 до 3 в массив значений.
Доступ к столбцам возможен как по их имени, так и по индексу.
Очень легко добавить новый столбец, прописав какое-то значение во всех существующих строках. Например, df выше, хотим добавить столбец Score. Для этого нам надо написать:
julia> df[:Score] = 0.0
0.0
julia> df
3×3 DataFrame
│ Row │ A │ B │ Score │
│ │ Int64 │ Int64 │ Float64 │
├─────┼───────┼───────┼─────────┤
│ 1 │ 1 │ 4 │ 0.0 │
│ 2 │ 2 │ 5 │ 0.0 │
│ 3 │ 3 │ 6 │ 0.0 │
Также как и в случае простых матриц, мы можем склеивать экземпляры DataFrame при помощи функций vcat, hcat. Однако vcat возможно использовать только при одинаковых колонках в обеих таблицах. Выровнять DataFrame можно, например, при помощи следующей функции:
function merge_df(first::DataFrame, second::DataFrame)::DataFrame
if (first == nothing)
return second
else
names_first = names(first)
names_second = names(second)
sub_names = setdiff(names_first, names_second)
second[sub_names] = 0
sub_names = setdiff(names_second, names_first)
first[sub_names] = 0
vcat(second, first)
end
end
Функция names здесь получает массив имён столбцов. Функция setdiff (s1, s2) в примере выявляет все элементы s1, которые не входят в s2. Далее, расширяем DataFrame до этих элементов. vcat склеивает два DataFrame и возвращает результат. Использование return в данном случае не нужно, поскольку результат последней операции очевиден.
Можем проверить результат:
julia> df1 = DataFrame(:A => collect(1:2))
2×1 DataFrame
│ Row │ A │
│ │ Int64 │
├─────┼───────┤
│ 1 │ 1 │
│ 2 │ 2 │
julia> df2 = DataFrame(:B => collect(3:4))
2×1 DataFrame
│ Row │ B │
│ │ Int64 │
├─────┼───────┤
│ 1 │ 3 │
│ 2 │ 4 │
julia> df3 = merge_df(df1, df2)
4×2 DataFrame
│ Row │ B │ A │
│ │ Int64 │ Int64 │
├─────┼───────┼───────┤
│ 1 │ 3 │ 0 │
│ 2 │ 4 │ 0 │
│ 3 │ 0 │ 1 │
│ 4 │ 0 │ 2 │
Отметим, что с точки зрения соглашения об именовании в Julia не принято использовать подчёркивания, но тогда страдает читаемость. Также не вполне хорошо в этой реализации то, что модифицируются исходные DataFrame. Но, тем не менее, этот пример хорош именно для иллюстрации процесса выравнивания множества столбцов.
Склейка нескольких DataFrame по общим значениям в столбцах возможна при помощи функции join (например склеить две таблицы с разными столбцами по идентификаторам общих пользователей).
DataFrame удобен для просмотра в консоли. Любой способ вывода: при помощи макроса show, при помощи функции println и пр. приведёт к тому, что в консоль будет напечатана таблица в удобной для восприятия форме. Если DataFrame слишком большой, то будут выведены начальные и конечные строки. Впрочем, можно и явно запросить голову и хвост функциями head и tail, соответственно.
Для DataFrame доступны функции группировки данных и агрегации по указанной функции. Имеются различия в том, что они возвращают. Это может быть коллекция с DataFrame, соответствующих критерию группировки, либо один единственный DataFrame, где имена колонок будут образованы от исходного имени и имени функции агрегации. В сущности, реализуется схема разбить-вычислить-объединить (split-apply-combine). См. Подробнее
Воспользуемся примером из документации с таблицей примеров, доступной в составе пакета DataFrames.
julia> using DataFrames, CSV, Statistics
julia> iris = CSV.read(joinpath(dirname(pathof(DataFrames)), "../test/data/iris.csv"));
Выполним группировку при помощи функции groupby. Указываем имя столбца группировки и получаем результат типа GroupedDataFrame, который содержит коллекцию отдельных DataFrame, собранных по значениям столбца группировки.
julia> species = groupby(iris, :Species)
GroupedDataFrame with 3 groups based on key: :Species
First Group: 50 rows
│ Row │ SepalLength │ SepalWidth │ PetalLength │ PetalWidth │ Species │
│ │ Float64 │ Float64 │ Float64 │ Float64 │ String │
├─────┼─────────────┼────────────┼─────────────┼────────────┼─────────┤
│ 1 │ 5.1 │ 3.5 │ 1.4 │ 0.2 │ setosa │
│ 2 │ 4.9 │ 3.0 │ 1.4 │ 0.2 │ setosa │
│ 3 │ 4.7 │ 3.2 │ 1.3 │ 0.2 │ setosa │
Полученный результат может быть преобразован в массив при помощи ранее упомянутой функции collect:
julia> collect(species)
3-element Array{Any,1}:
50×5 SubDataFrame{Array{Int64,1}}
│ Row │ SepalLength │ SepalWidth │ PetalLength │ PetalWidth │ Species │
│ │ Float64 │ Float64 │ Float64 │ Float64 │ String │
├─────┼─────────────┼────────────┼─────────────┼────────────┼─────────┤
│ 1 │ 5.1 │ 3.5 │ 1.4 │ 0.2 │ setosa │
│ 2 │ 4.9 │ 3.0 │ 1.4 │ 0.2 │ setosa │
│ 3 │ 4.7 │ 3.2 │ 1.3 │ 0.2 │ setosa │
…
Выполним группировку при помощи функции by. Укажем имя столбца и функцию обработки полученных DataFrame. Первый этап работы by аналогичен функции groupby — получим коллекцию DataFrame. Для каждого такого DataFrame подсчитаем количество строк и поместим их в столбец N. Результат будет склеен в единственный DataFrame и возвращён как результат функции by.
julia> by(iris, :Species, df -> DataFrame(N = size(df, 1)))
3×2 DataFrame
│ Row │ Species │ N │
│ │ String⍰ │ Int64 │
├─────┼────────────┼───────┤
│ 1 │ setosa │ 50 │
│ 2 │ versicolor │ 50 │
│ 3 │ virginica │ 50 │
Ну и последний вариант — функция aggregate. Указываем столбец для группировки и функцию агрегации для остальных столбцов. Результат — DataFrame, где имена столбцов будут образованы от имени исходных столбцов и имени функции агрегации.
julia> aggregate(iris, :Species, sum)
3×5 DataFrame
│Row│Species │SepalLength_sum│SepalWidth_sum│PetalLength_sum│PetalWidth_sum│
│ │ String │ Float64 │ Float64 │ Float64 │ Float64 │
├───┼──────────┼───────────────┼──────────────┼───────────────┼──────────────┤
│ 1 │setosa │250.3 │ 171.4 │ 73.1 │ 12.3 │
│ 2 │versicolor│296.8 │ 138.5 │ 213.0 │ 66.3 │
│ 3 │virginica │329.4 │ 148.7 │ 277.6 │ 101.3 │
Функция colwise применяет указанную функцию ко всем или только к указанным столбцам DataFrame.
julia> colwise(mean, iris[1:4])
4-element Array{Float64,1}:
5.843333333333335
3.057333333333334
3.7580000000000027
1.199333333333334
Весьма удобной функцией для получения сводки по таблице, является describe. Пример использования:
julia> describe(iris)
5×8 DataFrame
│Row│ variable │mean │min │median│ max │nunique│nmissing│ eltype │
│ │ Symbol │Union… │Any │Union…│ Any │Union… │Int64 │DataType│
├───┼───────────┼───────┼──────┼──────┼─────────┼───────┼────────┼────────┤
│ 1 │SepalLength│5.84333│ 4.3 │ 5.8 │ 7.9 │ │ 0 │ Float64│
│ 2 │SepalWidth │3.05733│ 2.0 │ 3.0 │ 4.4 │ │ 0 │ Float64│
│ 3 │PetalLength│3.758 │ 1.0 │ 4.35 │ 6.9 │ │ 0 │ Float64│
│ 4 │PetalWidth │1.19933│ 0.1 │ 1.3 │ 2.5 │ │ 0 │ Float64│
│ 5 │Species │ │setosa│ │virginica│ 3 │ 0 │ String │
Полный список функций пакета DataFrames.
Также, как и для случая Matrix, в DataFrame можно применять все статистические функции, доступные в модуле Statistics. См. https://docs.julialang.org/en/v1/stdlib/Statistics/index.html
Для графического отображения DataFrame используется библиотека StatPlots.jl. См. Подробнее https://github.com/JuliaPlots/StatPlots.jl
Эта библиотека реализует набор макросов, упрощающих визуализацию.
julia> df = DataFrame(a = 1:10, b = 10 .* rand(10), c = 10 .* rand(10))
10×3 DataFrame
│ Row │ a │ b │ c │
│ │ Int64 │ Float64 │ Float64 │
├─────┼───────┼─────────┼─────────┤
│ 1 │ 1 │ 0.73614 │ 7.11238 │
│ 2 │ 2 │ 5.5223 │ 1.42414 │
│ 3 │ 3 │ 3.5004 │ 2.11633 │
│ 4 │ 4 │ 1.34176 │ 7.54208 │
│ 5 │ 5 │ 8.52392 │ 2.98558 │
│ 6 │ 6 │ 4.47477 │ 6.36836 │
│ 7 │ 7 │ 8.48093 │ 6.59236 │
│ 8 │ 8 │ 5.3761 │ 2.5127 │
│ 9 │ 9 │ 3.55393 │ 9.2782 │
│ 10 │ 10 │ 3.50925 │ 7.07576 │
julia> @df df plot(:a, [:b :c], colour = [:red :blue])
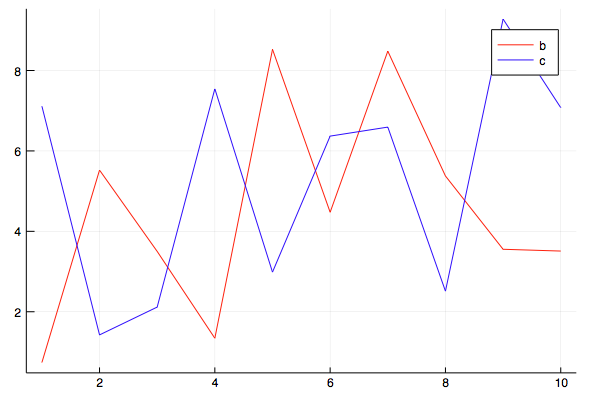
В последней строке @df — макрос, df — имя переменной с DataFrame.
Весьма полезной библиотекой может быть Query.jl. Используя механизмы макросов и канала обработки, Query.jl предоставляет специализированный язык запросов. Пример — получить список лиц старше 50 лет и количество детей у них:
julia> using Query, DataFrames
julia> df = DataFrame(name=["John", "Sally", "Kirk"], age=[23., 42., 59.], children=[3,5,2])
3×3 DataFrame
│ Row │ name │ age │ children │
│ │ String │ Float64 │ Int64 │
├─────┼────────┼─────────┼──────────┤
│ 1 │ John │ 23.0 │ 3 │
│ 2 │ Sally │ 42.0 │ 5 │
│ 3 │ Kirk │ 59.0 │ 2 │
julia> x = @from i in df begin
@where i.age>50
@select {i.name, i.children}
@collect DataFrame
end
1×2 DataFrame
│ Row │ name │ children │
│ │ String │ Int64 │
├─────┼────────┼──────────┤
│ 1 │ Kirk │ 2 │
Или форма с каналом:
julia> using Query, DataFrames
julia> df = DataFrame(name=["John", "Sally", "Kirk"], age=[23., 42., 59.], children=[3,5,2]);
julia> x = df |> @query(i, begin
@where i.age>50
@select {i.name, i.children}
end) |> DataFrame
1×2 DataFrame
│ Row │ name │ children │
│ │ String │ Int64 │
├─────┼────────┼──────────┤
│ 1 │ Kirk │ 2 │
См. подробнее
Оба примера выше, демонстрируют использование языков запросов, функционально подобных dplyr или LINQ. Причём эти языки не ограничиваются Query.jl. Подробнее об использовании этих языков совместно с DataFrames здесь.
В последнем примере используется оператор »|>». См. Подробнее.
Этот оператор подставляет аргумент в функцию, которая указывается справа от него. Иными словами:
julia> [1:5;] |> x->x.^2 |> sum |> inv
0.01818181818181818
Эквивалентно:
julia> inv(sum( [1:5;] .^ 2 ))
0.01818181818181818
И последнее, что хотелось бы отметить, это возможность записать DataFrame в выходной формат с разделителем при помощи ранее упомянутой библиотеки CSV.jl
julia> df = DataFrame(name=["John", "Sally", "Kirk"], age=[23., 42., 59.], children=[3,5,2])
3×3 DataFrame
│ Row │ name │ age │ children │
│ │ String │ Float64 │ Int64 │
├─────┼────────┼─────────┼──────────┤
│ 1 │ John │ 23.0 │ 3 │
│ 2 │ Sally │ 42.0 │ 5 │
│ 3 │ Kirk │ 59.0 │ 2 │
julia> CSV.write("out.csv", df)
"out.csv"
Можем проверить записанный результат:
> cat out.csv
name,age,children
John,23.0,3
Sally,42.0,5
Kirk,59.0,2
Заключение
Сложно прогнозировать, станет ли Julia таким же распространенным языком программирования как R, например, но в этом году она уже стала самым быстро растущим языком программирования. Если в прошлом году о ней знали лишь единицы, в этом году, после выхода версии 1.0 и стабилизации библиотечных функций, о ней начали писать, почти наверное, в следующем году она станет языком, не знать который будет просто неприлично в области Data Science. А компании, которые, не начали использовать Julia для анализа данных, будут являться откровенными динозаврами, подлежащими замещению более проворными потомками.
Язык Julia является молодым языком программирования. Собственно, после появления пилотных проектов, будет понятно, на сколько готова инфраструктура Julia к реальному промышленному использованию. Разработчики Julia весьма амбициозны и заявляют о готовности уже сейчас. В любом случае, простой, но строгий синтаксис Julia, делает её весьма привлекательным языком программирования для обучения уже сейчас. Высокая производительность позволяет реализовывать алгоритмы, которые пригодны не только для учебных целей, но и для реального использования при анализе данных. Мы же, начнём последовательно пробовать Julia в различных проектах уже сейчас.
