[Из песочницы] Ищем утечки памяти с помощью Eclipse MAT
Пожалуй, все java-разработчики, участвующие в коммерческих проектах рано или поздно сталкиваются с проблемой утечки памяти, влекущей за собой медленную работу приложения и почти неизбежно приводящую в итоге к известной OutOfMemoryError. В данной статье будет рассмотрен реальный пример такой ситуации и способ поиска ее причины с помощью Eclipce Memory Analizer.
Утечкой памяти принято называть ситуацию, когда количество занятой памяти в куче растет при длительной работе приложения и не уменьшается после завершения работы Garbage Collector-а. Как известно, память jvm делится на кучу и стек. В стеке кэшируются значения переменных простых типов и ссылок на объекты в разрезе потока, а в куче хранятся сами объекты. Также в куче есть пространство, именуемое Metaspace, где хранятся данные о загруженных классах и данные привязанные к самим классам, а не их экземплярам, в частности, значения статических переменных. Периодически запускаемый java-машиной Garbage Collector (далее GC) находит в куче объекты, на которые больше нет ссылок и освобождает память, занимаемую этими объектами. Алгоритмы работы GC разные и сложные, в частности, при очередном запуске GC не каждый раз «исследует» всю кучу на предмет поиска неиспользуемых объектов, поэтому рассчитывать на то, что какой-либо больше неиспользуемый объект, будет удален из памяти после одного запуска GC не стоит, но если объем памяти, используемой приложением неуклонно растет без видимых причин длительное время, то пора задуматься о том, что могло привести к такой ситуации.
В состав jvm входит многофункциональная утилита Visual VM (далее VM). VM позволяет визуально на графиках наблюдать в динамике ключевые показатели jvm, в частности, объем свободной и занятой памяти в куче, количество загруженных классов, потоков и.т.д. Кроме этого, с помощью VM можно снимать и исследовать дампы памяти. Разумеется, VM позволяет также снимать дампы потоков, и осуществлять профилирование приложения, однако обзор этих функций выходит за рамки данной статьи. Все что нам нужно от VM в данном примере, это подключиться к виртуальной машине и посмотреть для начала на общую картинку использования памяти. Хотелось бы отметить, что для подключения VM к удаленному серверу требуется, чтобы на нем были настроены параметры jmxremote, так как подключение осуществляется через jmx. За описанием данных параметров можно обратиться к официальной документации Oracle или многочисленным статьям на Хабре.
Итак, будем считать, что мы успешно подключились к серверу приложений с помощью VM и взглянем на графики.
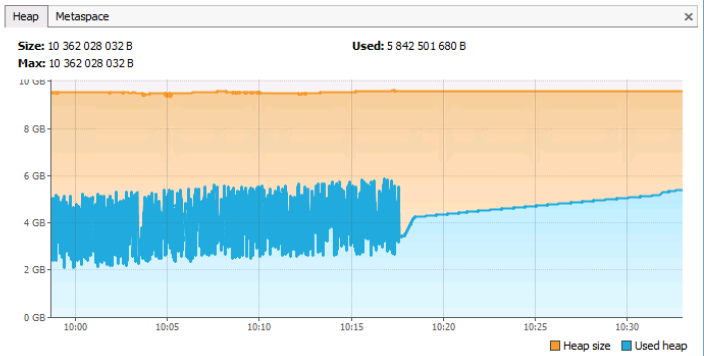
На вкладке Heap можно увидеть общий объем и объем занятой памяти jvm. Нужно отметить, что на данной вкладке учитывается и память типа Metaspace (ну, а как иначе, ведь это тоже куча). На вкладке Metaspace отображается информация только по памяти занимаемой метаданными (самими классами и объектами к ним привязанными).
Взглянув на график мы видим, что общий объем памяти heap составляет ~10Гб, текущий занятый объем ~5.8Гб. Гребни на графике соответствуют вызовам GC, почти прямая линия (без гребней), начиная примерно с 10:18 может (но не обязательно!) говорить о том, что с этого времени сервер приложений почти не работал, так как не было активного выделения и освобождения памяти. Вообще, данный график соответствует нормальной работе сервера приложений (если, конечно, судить о работе только по памяти). Проблемным графиком был бы такой, где прямая горизонтальная синяя линия без гребней, проходила бы примерно на уровне оранжевой, обозначающей максимальный объем памяти в куче.
Теперь взглянем на другой график.
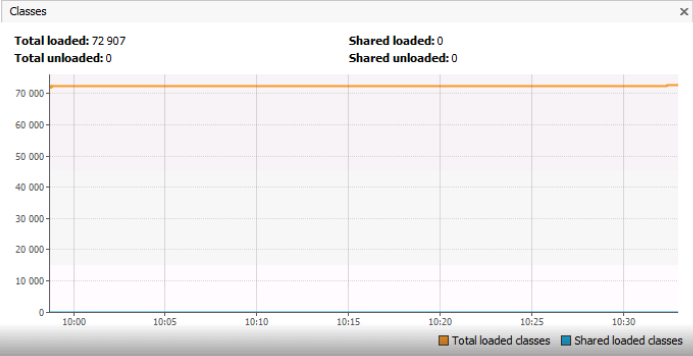
Вот тут мы подходим непосредственно к разбору примера, являющегося основной темой настоящей статьи. На графике Classes отображается количество загруженных в Metaspace классов, и оно составляет ~ 73 тысячи объектов. Хотелось бы обратить внимание, что речь не об экземплярах классов, а о самих классах, то есть объектах типа Class. Из графика не видно, по сколько же экземпляров каждого отдельного типа ClassА или ClassB загружено в память. Возможно, количество одинаковых классов типа ClassA по какой-то причине кратно увеличивается? Должен сказать, что в примере о котором будет рассказано ниже 73000 уникальных классов являлось абсолютно нормальной ситуацией.
Дело в том, что в одном из проектов, в которых принимал участие автор данной статьи, был разработан механизм универсального описания сущностей предметной области (как например в 1С) названный словарной системой, и аналитики, настраивающие систему под конкретного заказчика или под конкретную бизнес область, имели возможность через специальный редактор моделировать бизнес модель создавая новые и изменяя существующие сущности, оперируя не на уровне таблиц, а такими понятиями как «Документ», «Счет», «Сотрудник» и.т.д. Ядро системы создавало для данных сущностей таблицы в реляционной СУБД, причем для каждой сущности могло создаваться несколько таблиц, так как универсальная система позволяла исторично хранить значения атрибутов и еще много чего требующего создания дополнительных служебных таблиц в БД.
Полагаю, что те, кому приходилось работать с ORM-фреймворками уже догадались к чему автор, отвлекся от основной темы статьи на разговор о таблицах. В проекте использовался Hibernate и для каждой таблицы должен был существовать класс Entity-бина. При этом, поскольку, новые таблицы создавалась динамически в процессе работы системы аналитиками, то классы бинов Hibernate генерировались, а не писались вручную разработчиками. И при каждой очередной генерации создавалось около 50–60 тысяч новых классов. Таблиц в системе было значительно меньше (примерно 5–6 тыс), но для каждой таблицы генерировался не только класс Entity-бина, а еще много вспомогательных классов, что в итоге приводило к общей цифре.
Механизм работы был следующий. При старте системы на основании метаданных в БД генерировались классы Entity-бинов и вспомогательные классы (далее просто классы бинов). При работе системы фабрика сессий Hibernate создавала сессии, сессии создавали экземпляры объектов классов бинов. При изменении структуры (добавлении, изменении таблиц) происходила перегенерация классов бинов и создание новой фабрики сессий. После перегенерации новая фабрика создавала новые сессии, которые использовали уже новые классы бинов, старая фабрика и сессии закрывались, а старые классы бинов выгружались GC, так как на них больше не было ссылок из объектов инфраструктуры Hibernate.
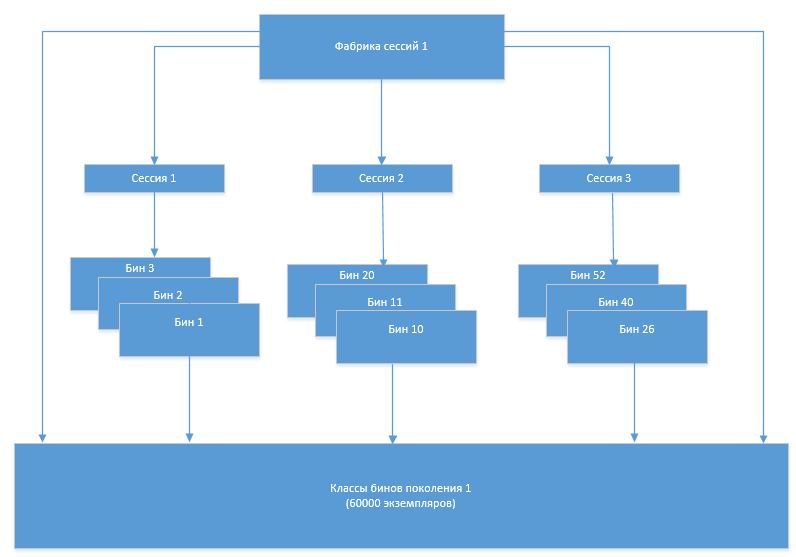
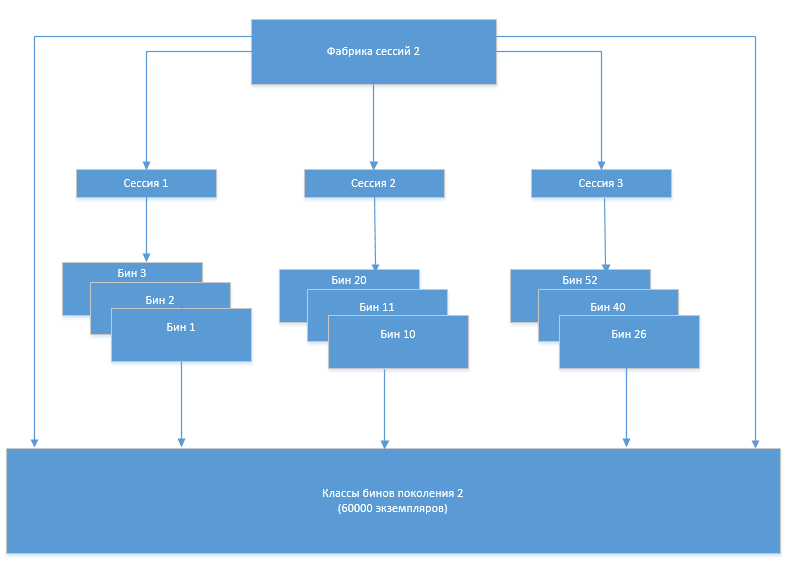
В какой-то момент появилась проблема, что количество классов бинов стало увеличиваться после каждой очередной перегенерации. Очевидно, что это происходило из-за того, что старый набор классов, который уже не должен был использоваться, по какой-то причине не выгружался из памяти. Для того чтобы разобраться в причинах такого поведения системы нам пришел на помощь Eclipse Memory Analizer (MAT).
MAT умеет работать с дампами памяти находя в них потенциальные проблемы, но для начала этот дамп памяти нужно получить, а в реальных средах с получением дампа есть определенные нюансы.
Снятие дампа памяти
Как говорилось выше, дамп памяти можно снять непосредственно из VM, нажав кнопку
Но, из-за большого размера дампа VM может просто не справиться с этой задачей, зависнув через некоторое время после нажатия кнопки Heap Dump. Кроме того, совсем не факт, что будет возможно подключение по jmx к продуктовому серверу приложений, необходимое для VM. В этом случае на помощь нам приходит другая утилита из состава jvm, которая называется jMap. Она запускается в командной строке, непосредственно на сервере где работает jvm, и позволяет задать дополнительные параметры снятия дампа:
jmap -dump: live, format=b, file=/tmp/heapdump.bin 14616
Параметр –dump: live крайне важен, так как позволяет существенно сократить его размер, не включая объекты, на которых больше нет ссылок.
Другая распространенная ситуация, это когда снятие дампа вручную не представляется возможным из-за того, что падает сама jvm с OutOfMemoryError. В этой ситуации на помощь приходит опция -XX:+HeapDumpOnOutOfMemoryError и в дополнение к ней -XX: HeapDumpPath, позволяющая указать путь к снятому дампу.
Далее, снятый дамп открываем с помощью Eclipse Memory Analizer. Файл может быть большим по объему (несколько гигабайтов), поэтому надо предусмотреть достаточное количество памяти в файле MemoryAnalyzer.ini:
-Xmx4096m
Локализация проблемы с использованием MAT
Итак, рассмотрим ситуацию, когда количество загруженных классов кратно увеличивается по сравнению с начальным уровнем и не уменьшается даже после принудительного вызова сборки мусора (это можно сделать нажатием соответствующей кнопки в VM).
Выше был концептуально описан процесс перегенерации классов бинов и их использования. На более техническом уровне это выглядело следующим образом:
- Закрываются все Hibernate-сессии (класс SessionImpl)
- Закрывается старая фабрика сессий (SessionFactoryImpl) и обнуляется ссылка на нее из LocalSessionFactoryBean
- Пересоздается ClassLoader
- Обнуляются ссылки на старые классы бинов в классе-генераторе
- Происходит перегенерация классов бинов
При отсутствии ссылок на старые классы бинов, количество классов не должно увеличиться после сборки мусора.
Запускаем MAT и открываем полученный ранее файл дампа памяти. После открытия дампа MAT показывает самые большие по объему цепочки объектов в памяти.
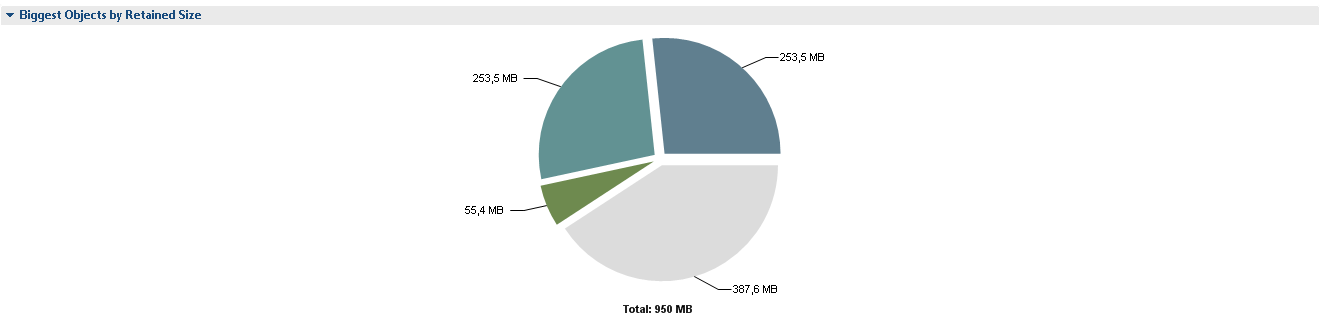
После нажатия Leak Suspects видим подробности:
2 сегмента круга по 265 M это 2 экземпляра SessionFactoryImpl. Непонятно почему их 2 экземпляра и, скорее всего, каждый из экземпляров держит ссылки на полный набор классов Entity-бинов. О потенциальных проблемах MAT сообщает нам следующим образом.

Сразу отмечу, что Problem Suspect 3 на самом деле проблемой не является. В проекте был реализован парсер собственного языка, являющегося мультиплатформенной надстройкой над SQL и позволяющего оперировать не таблицами, а сущностями системы, а 121M занимает кэш его запросов.
Вернемся к двум экземплярам SessionFactoryImpl. Нажимаем Duplicate Classes и видим, что действительно каждого класса Entity-бина по 2 экземпляра. То есть ссылки на старые классы Entity-бинов остались и, скорее всего, это ссылки из SesssionFactoryImpl. Судя по исходному коду этого класса ссылки на классы бинов должны храниться в поле classMetaData.
Щелкаем на Problem Suspect 1, далее на класс SessionFactoryImpl и по контекстному меню выбираем List Objects→ With outgouing references. Таким образом мы можем увидеть все объекты на которые ссылается SessionFactoryImpl.
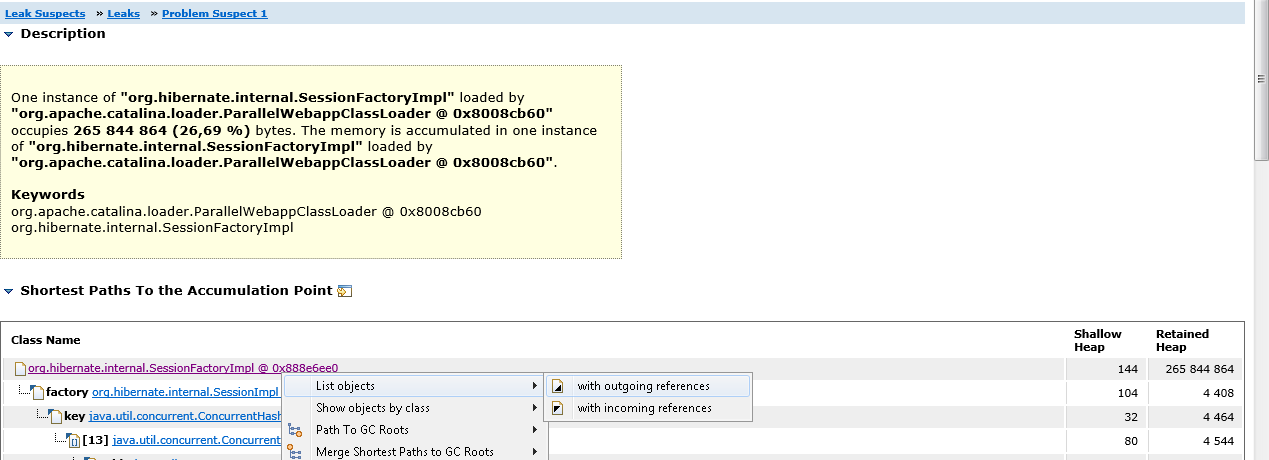
Раскрываем объект classMetaData и убеждаемся, что действительно в нем хранится массив классов Entity-бинов.
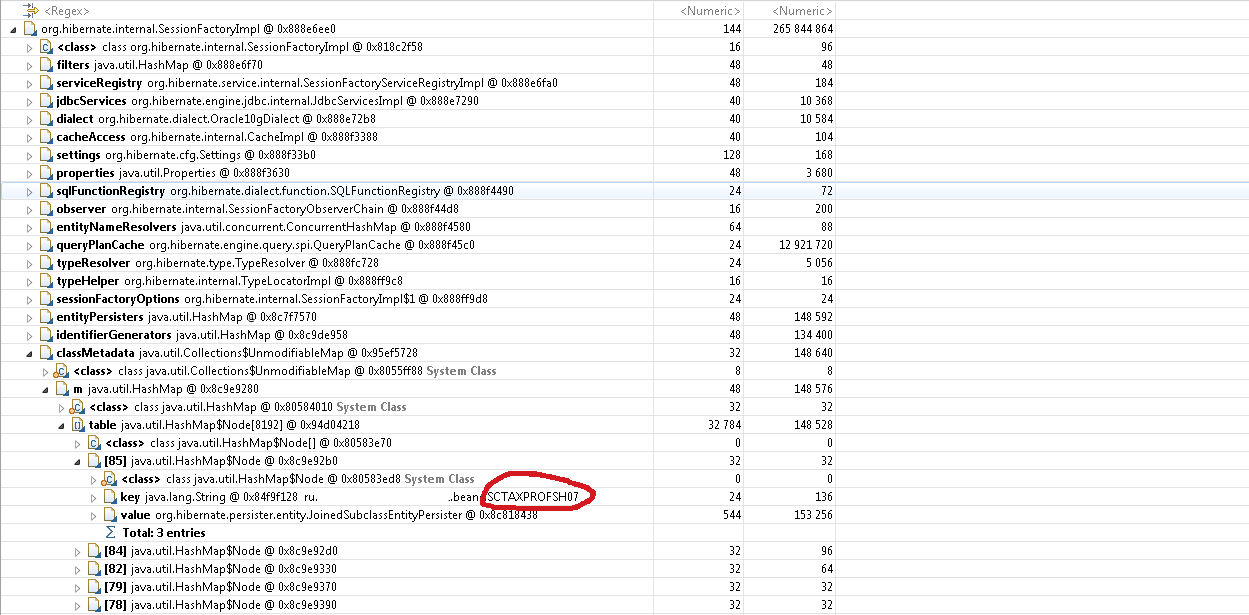
Теперь нам нужно понять, что не позволяет сборщику мусора удалить один экземпляр SessionFactoryImpl. Если вернуться к пункту Leak Suspects→ Leaks→ Problem Suspect 1, то мы увидим стек ссылок, который приводит к ссылке на SessionFactoryImpl.
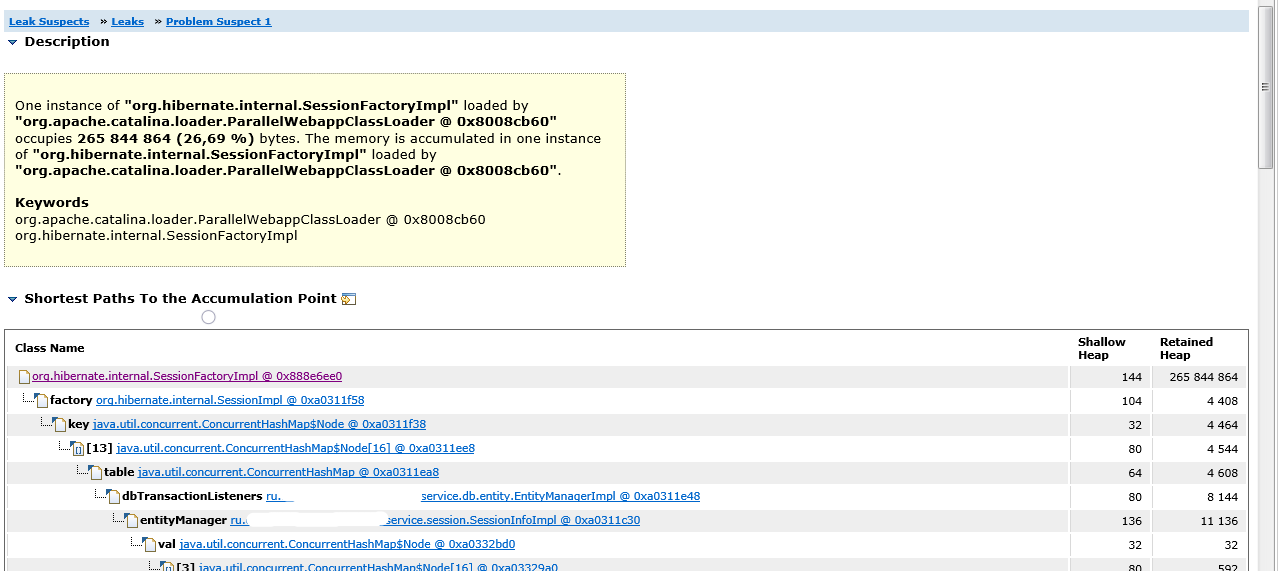
Видим, что в классе EntityManager есть массив dbTransactionListeners, который использует объекты сессий SessionImpl в качестве ключей, а сессии ссылаются на SessionFactoryImpl.
Дело в том, что объекты сессий для определенных целей кэшировались в dbTransactionListeners и перед перегенерацией классов бинов в этом массиве могли оставаться ссылки на них. Сессии, в свою очередь, ссылались на фабрику сессий, а та хранила массив ссылок на все классы бинов. Кроме этого, сессии держали ссылки на экземпляры классов сущностей, а те ссылались на сами классы бинов.
Таким образом, точка входа в проблему была найдена. Ей оказались ссылки на старые сессии из dbTransactionListeners.После того, как ошибка была исправлена и массив dbTransactionListeners стал очищаться проблема была устранена.
Итак, Eclipse Memory Analiser позволяет:
- Узнать о том какие цепочки объектов занимают максимальный объем памяти и определить точки входа в эти цепочки (Leak Suspects)
- Посмотреть дерево всех входящих ссылок на объект (Shortest Paths To the accumulation point)
- Посмотреть дерево всех исходящих ссылок объекта (Объект→ List Objects→With outgouing references)
- Увидеть дубликаты классов, загруженные разными ClassLoader-ами (Duplicate Classes)
