[Из песочницы] Хранение иерархических структур. Симбиоз «Closure Table» и «Adjacency List»
Когда перед нами встаёт задача хранения и управления иерархическими структурами данных всегда приходится выбирать из довольно ограниченного набора паттернов. Для того чтобы найти наиболее подходящий шаблон необходимо проанализировать особенности каждого способа хранения и обработки данных и оценить их с учётом задачи и специфики используемой СУБД.
Предположим, существует задача, предоставить возможность пользователям сайта оставлять комментарии к публикациям. Комментарии должны иметь древовидную структуру, пользователи должны иметь возможность оставить один или более комментариев к посту, а также отвечать на любые комментарии других пользователей. То есть, нужна система комментариев аналогичная той, что мы можем видеть на Habrahabr. По каким-то причинам, нам не подходят готовые решения, допустим из-за того, что предполагается дополнительная очень сложная бизнес-логика, которая должна быть интегрирована в систему комментариев.
Наша цель — разработать свою реализацию, учитывающую требования нашего приложения.
Что для нас важно?
- Минимизировать количество запросов к базе данных. В частности, для извлечения ветки комментариев должно быть достаточно одного запроса.
- Получить высокую производительность, поэтому запросы к базе данных, особенно на чтение, должны быть простыми и выполняться быстро даже при большом объёме данных.
- Хранить текст комментариев и иерархическую структуру дерева в разных таблицах.
- Иметь возможность отсортировать извлечённые из базы данных комментарии, чтобы в результате отобразить их в естественном виде, как древовидную иерархическую структуру или, что ещё лучше, сразу извлечь из базы данных отсортированное дерево.
- Контролировать глубину вложенности комментариев.
- Гарантировать целостность данных.
- Учесть специфику MySQL. Как известно, эта СУБД не поддерживает рекурсивные запросы. Рекурсия в этой СУБД возможна только в хранимых процедурах с ограничением вложенности — не более 255 уровней.
- Требования вполне обоснованные и актуальные для многих проектов.
Итак, рассмотрим известные способы хранения и работы с деревьями. Их не так уж и много:
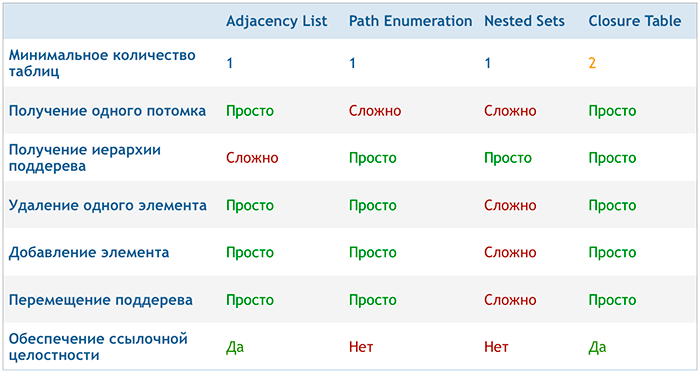
Детали реализации этих паттернов отлично рассмотрены в презентации Билла Карвина (Bill Karwin).
Особенность метода «Adjacency List», заключается в том, что без поддержки рекурсивных запросов СУБД, извлечь одним простым запросом произвольную часть иерархии невозможно. Поэтому, в контексте использования MySQL этот вариант нас совершенно не устраивает.
Метод «Path Enumeration» (или как его ещё называют «Materialized Path»), очевидно, нам тоже не подходит, ввиду низкой производительности SQL-запросов SELECT, так как предполагается использование оператора LIKE и поиск по шаблонам вида:»½/¾%». Хранение некого множества в виде строки с разделителями, едва ли уместно в мире реляционных баз данных.
Пожалуй, самый интересный паттерн для работы с древовидными структурами — Nested Sets. Он вполне может быть использован для нашей задачи, но его реализация довольно сложная и он не обеспечивает целостность данных. Ошибка при вставке нового элемента в иерархию или при переносе поддерева из одного места в другое может создать большие проблемы. Необходимость пересчёта и изменения значений части левых и правых индексов элементов поддерева при добавлении нового элемента, вне всяких сомнений, является существенным недостатком Nested Sets.
Последний метод «Closure Table», исходя из наших требований, мог бы стать лучшим выбором, если бы не одно «но» — отсутствие простого способа построить отсортированное дерево из получаемого запросом плоского списка связей.
Давайте рассмотрим этот шаблон работы с древовидными структурами данных подробнее.
Схема связей элементов дерева «Closure Table» выглядит следующим образом:

Предположим, у нас есть иерархия комментариев, которая соответствует приведённой выше схеме связей:
Таблица comments:

Таблица commentsTree:

Получить список всех элементов нужной нам части дерева можно следующим запросом (извлечём дерево начиная от `commentsTree`.`idAncestor` = 1):
SELECT
`tableData`.`idEntry`,
`tableData`.`content`,
`tableTree`.`idAncestor`,
`tableTree`.`idDescendant`,
`tableTree`.`level`,
`tableTree`.`idSubject`
FROM `comments` AS `tableData`
JOIN `commentsTree` AS `tableTree`
ON `tableData`.`idEntry` = `tableTree`.`idDescendant`
WHERE `tableTree`.`idAncestor` = 1
В результате получим:

Всё просто! Но извлечённые строки нужно преобразовать в отсортированную древовидную иерархию. Именно она нам нужна. Увы, данных для преобразования этого множества в нужную нам форму недостаточно.
Как же нам решить эту проблему?
Вариант 1. Заставим СУБД сортировать дерево
Существует довольно оригинальный способ, при помощи которого можно получить из базы данных сразу отсортированную древовидную иерархию, причём всего одним запросом. Известный разработчик Билл Карвин (Bill Karwin) предложил весьма изящный вариант решения задачи извлечения отсортированного дерева:
SELECT
`tableData`.`idEntry`,
`tableData`.`content`,
`tableTree`.`level`,
`tableTree`.`idAncestor`,
`tableTree`.`idDescendant`,
GROUP_CONCAT(`tableStructure`.`idAncestor`) AS `structure`
FROM
`comments` AS `tableData`
JOIN `commentsTree` AS `tableTree`
ON `tableData`.`idEntry` = `tableTree`.`idDescendant`
JOIN `commentsTree` AS `tableStructure`
ON `tableStructure`.`idDescendant` = `tableTree`.`idDescendant`
WHERE `tableTree`.`idAncestor` = 1
GROUP BY `tableData`.`idEntry`
ORDER BY `structure`
В результате мы получим, то что нам нужно:

Но, как не сложно заметить, такой способ будет корректно работать только в случае, когда длина идентификаторов idAncestor у всех строк, отвечающих условию запроса, одинаковая. Обратите внимание на следующий фрагмент SQL-запроса: «GROUP_CONCAT (tableStructure.idAncestor ORDER BY tableStructure.level DESC) AS structure». Сортировка строк содержащих множества »12,14,28» и »13,119,12» будет некорректной с точки зрения нашей задачи. То есть, если все идентификаторы в запрашиваемой части дерева одинаковой длинны, то сортировка верная, а в случае если это не так, то структура дерева будет нарушена. Уменьшить количество неправильных сортировок можно, задав начало отсчёта идентификаторов с большого целого числа, например 1000000, указав в SQL запросе при создании таблицы AUTO_INCREMENT=1000000.
Для того чтобы полностью избавится от этой проблемы, можно указать для столбца идентификатора idAncestor параметр ZEROFILL, в этом случае СУБД будет автоматически добавлять атрибут UNSIGNED и идентификаторы буду выглядеть примерно так: 0000000004, 0000000005, 0000000194.
Для некоторых задач, без сомнений, можно использовать этот способ. Но давайте всё-таки постараемся избежать использования двух JOIN«ов при работе с двумя таблицами, функции GROUP_CONCAT (), да ещё и параметра ZEROFILL.
Вариант 2. Симбиоз двух методов «Closure Table» и «Adjacency List»
Давайте ещё раз посмотрим на метод «Closure Table». В плоском списке связей иерархической структуры, который мы получаем всего одним запросом, нам, очевидно, не хватает информации о связи каждого элемента со своим родителем, для того, чтобы мы смогли построить отсортированное дерево. Поэтому, давайте добавим поле idNearestAncestor в таблицу commentsTree и будем сохранять там ссылку на элемент, который является ближайший предком.

Таким образом, мы получили симбиоз двух методов «Closure Table» и «Adjacency List». Теперь формирование правильно отсортированной иерархической структуры — тривиальная задача. И самое главное, мы нашли решение, которое полностью отвечает требованиям.
Следующим запросом мы получим необходимые для построения дерева данные:
SELECT
`tableData`.`idEntry`,
`tableData`.`content`,
`tableTree`.`idAncestor`,
`tableTree`.`idDescendant`,
`tableTree`.`idNearestAncestor`,
`tableTree`.`level`,
`tableTree`.`idSubject`
FROM `comments` AS `tableData`
JOIN `commentsTree` AS `tableTree`
ON `tableData`.`idEntry` = `tableTree`.`idDescendant`
WHERE `tableTree`.`idAncestor` = 1
Критика «Closure Table»
Шаблон «Closure Table» часто критикуют за то, что необходимо хранить в базе данных связи каждого элемента дерева со всеми его предками, а так же ссылку каждого элемента на самого себя. Чем глубже в иерархии располагается элемент, тем больше записей в таблице необходимо сделать. Очевидно, что добавление новых элементов в конец глубокой древовидной иерархии будет менее эффективным, чем вставка элементов вблизи корня дерева. Кроме этого, стоит отметить, что для хранения деревьев метод Closure Table требует больше места в базе данных, чем любой другой метод.
Для того чтобы объективно оценить значимость этих замечаний, их следует рассматривать в контексте специфики реального проекта. Например, снижение производительности при добавлении нового элемента на двухвостый или тысячный уровень может быть незначительным или некритичным для работы приложения, или же, что ещё более вероятно, такая ситуация вовсе никогда не произойдёт. Как правило, в реальной жизни нет необходимости в иерархических структурах большой вложенности. Кроме этого, в большинстве случаев, принципиальным параметром является скорость извлечения данных, а не записи. Объём дискового пространства, который может потребовать структура дерева едва ли стоит учитывать, так как другие потребители этого ресурса намного более значимые, например логирование посетителей сайта.
Пример моей реализации системы древовидных комментариев основанной на методах «Closure Table» и «Adjacency List» на github.
Используемые материалы
- Презентация Билла Карвина (Bill Karwin). http://www.slideshare.net/billkarwin/models-for-hierarchical-data
- Обсуждение вопросов сортировки деревьев на stackoverflow. http://stackoverflow.com/questions/8252323/mysql-closure-table-hierarchical-database-how-to-pull-information-out-in-the-c, http://stackoverflow.com/questions/192220/what-is-the-most-efficient-elegant-way-to-parse-a-flat-table-into-a-tree
- Документация MySQL
