[Из песочницы] Entity Framework: повышаем производительность при сохранении данных в БД
При добавлении/изменении большого количества записей (10³ и выше), производительность Entity Framework оставляет желать лучшего. Причиной этому являются как архитектурные особенности самого фреймворка, так и неоптимальный генерируемый SQL. Забегая вперед — сохранение данных в обход контекста сокращает время выполнения на порядки.Содержание статьи:1. Insert/Update стандартными средствами Entity Framework2. Поиск решения проблемы3. Интеграция Entity Framework и SqlBulkCopy4. Продвинутая вставка с использованием MERGE5. Сравнение производительности6. Выводы
Insert/Update стандартными средствами Entity FrameworkНачнем с Insert. Стандартным способом добавления новых записей в БД является добавление в контекст с последующим сохранением: context.Orders.Add (order); context.SaveChanges (); Каждый вызов метода Add приводит к дорогостоящему в плане выполнения вызову внутреннего алгоритма DetectChanges. Данный алгоритм сканирует все сущности в контексте и сравнивает текущее значение каждого свойства с исходным значением, хранимым в контексте, обновляет связи между сущностями и т.п. Известным способом поднятия производительности, актуальным до выхода EF 6, является отключение DetectChanges на время добавления сущностей в контекст: context.Configuration.AutoDetectChangesEnabled = false; orders.ForEach (order => context.Orders.Add (order)); context.Configuration.AutoDetectChangesEnabled = true; context.SaveChanges (); Также рекомендуется не держать в контексте десятки тысяч объектов и сохранять данные блоками, сохраняя контекст и создавая новый каждые N объектов, например, как тут. Наконец, в EF 6 появился оптимизированный метод AddRange, поднимающий производительность до уровня связки Add+AutoDetectChangesEnabled: context.Orders.AddRange (orders); context.SaveChanges (); К сожалению, перечисленные подходы не решают основной проблемы, а именно: при сохранении данных в БД, на каждую новую запись генерируется отдельный INSERT запрос! SQL INSERT [dbo].[Order]([Date], [Number], [Text]) VALUES (@0, @1, NULL) С Update ситуация аналогичная. Следующий код: var orders = context.Orders.ToList (); //… записали новые данные context.SaveChanges (); приведет к выполнению отдельного SQL-запроса на каждый измененный объект: SQL UPDATE [dbo].[Order] SET [Text] = @0 WHERE ([Id] = @1) В простейших случаях, может помочь EntityFramework.Extended: //update all tasks with status of 1 to status of 2 context.Tasks.Update ( t => t.StatusId == 1, t2 => new Task { StatusId = 2 }); Данный код выполнится в обход контекста и сгенерирует 1 SQL-запрос. Более подробно о скорости EF и работе с этой библиотекой в статье за авторством tp7. Очевидно, что решение не универсальное и годится только для записи во все целевые строки одного и того же значения.2. Поиск решения проблемы Испытывая стойкое отвращение к написанию «велосипедов», я в первую очередь поискал best-practices для множественной вставки с помощью EF. Казалось бы, типовая задача —, но подходящего решения «из коробки» найти не удалось. В то же время, SQL Server предлагает ряд техник быстрой вставки данных, таких как утилита bcp и класс SqlBulkCopy. О последнем и пойдет речь ниже.System.Data.SqlClient.SqlBulkCopy — класс из состава ADO.NET, предназначенный для записи большого объема данных в таблицы SQL Server. В качестве источника данных может принимать DataRow[], DataTable, либо реализацию IDataReader.Что умеет:
Отправлять данные на сервер поблочно с поддержкой транзакций; Выполнять маппинг колонок из DataTable на таблицу БД; Игнорировать constraints, foreign keys при вставке (опционально). Минусы: Атомарность вставки (опционально); Невозможность продолжения работы после возникновения исключения; Слабые возможности по обработке ошибок. Подробнее о классе можно прочитать в статье JeanLouis, а здесь мы рассмотрим нашу насущную проблему —, а именно отсутствие интеграции SqlBulkCopy и EF. Устоявшегося подхода к решению такой задачи нет, но есть несколько проектов различной степени пригодности, таких как: EntityFramework.BulkInsertНа поверку оказавшийся нерабочим. При изучении Issues я наткнулся на дискуссию с участием… небезызвестной Julie Lerman, описывающую проблему, аналогичную моей и оставшуюся без ответа авторов проекта.
EntityFramework.UtilitiesЖивой проект, активное сообщество. Нет поддержки Database First, но обещают добавить.
Entity Framework Extensions$300.
3. Интеграция Entity Framework и SqlBulkCopy Попробуем сделать всё сами. В простейшем случае, вставка данных из коллекции объектов с помощью SqlBulkCopy выглядит следующим образом: //entities — коллекция сущностей EntityFramework using (IDataReader reader = entities.GetDataReader ()) using (SqlConnection connection = new SqlConnection (connectionString)) using (SqlBulkCopy bcp = new SqlBulkCopy (connection)) { connection.Open ();
bcp.DestinationTableName = »[Order]»;
bcp.ColumnMappings.Add («Date», «Date»); bcp.ColumnMappings.Add («Number», «Number»); bcp.ColumnMappings.Add («Text», «Text»);
bcp.WriteToServer (reader); } Сама по себе задача реализовать IDataReader на основе коллекции объектов тривиальна, поэтому я ограничусь ссылкой и перейду к описанию способов обработки ошибок при вставке с использованием SqlBulkCopy. По умолчанию, вставка данных производится в своей собственной транзакции. При возникновении исключения выбрасывается SqlException и происходит rollback, т.е. данные в БД не будут записаны вообще. А «родные» сообщения об ошибках данного класса иначе как неинформативными не назовешь. Например, что может содержать SqlException.AdditionalInformation: The given value of type String from the data source cannot be converted to type nvarchar of the specified target column.
или: SqlDateTime overflow. Must be between 1/1/1753 12:00:00 AM and 12/31/9999 11:59:59 PM.
К сожалению, SqlBulkCopy зачастую не предоставляет информацию, позволяющую однозначно определить строку/сущность, вызвавшие ошибку. Еще одна неприятная особенность — при попытке вставить дубликат записи по первичному ключу, SqlBulkCopy выбросит исключение и завершит работу, не предоставляя возможности обработать ситуацию и продолжить выполнение.
МаппингВ случае корректно сгенерированных сущностей и БД становятся неактуальными проверки на соответствие типов, или длину поля в таблице, как тут. Полезней разобраться с маппингом колонок, выполняемым через свойство SqlBulkCopy.ColumnMappings:
Если источник данных и таблица назначения имеют одинаковое количество столбцов и исходная позиция каждого исходного столбца в источнике данных соответствует исходной позиции соответствующего столбца назначения, коллекция ColumnMappings не требуется. Однако если количество столбцов или их порядок различны, необходимо использовать ColumnMappings для обеспечения правильного копирования данных между столбцами.
Для EF В 99% случаев потребуется задать ColumnMappings явно (из-за navigation properties и любых дополнительных свойств). Navigation properties можно отсеять при помощи Reflection: Получаем имена свойств для маппинга
var columns = typeof (Order).GetProperties ()
.Where (property =>
property.PropertyType.IsValueType
|| property.PropertyType.Name.ToLower () == «string»)
.Select (property => property.Name)
.ToList ();
Такой код сгодится для POCO класса без дополнительных свойств, в противном случае придется переходить на «ручное управление». Получить схему таблицы тоже достаточно просто: Читаем схему таблицы
private static List
var columns = connection.GetSchema («Columns», restrictions)
.AsEnumerable ()
.Select (s => s.Field
return columns; } Что дает возможность вручную провести маппинг между классом-источником и целевой таблицей.Использование свойства SqlBulkCopy.BatchSize и класса SqlBulkCopyOptions
SqlBulkCopy.BatchSize:
BatchSize Количество строк в каждом пакете. В конце каждого пакета серверу отправляется количество содержащихся в нем строк. SqlBulkCopyOptions — перечисление: Имя члена Описание CheckConstraints Проверять ограничения при вставке данных. По умолчанию ограничения не проверяются. Default Использовать значения по умолчанию для всех параметров. FireTriggers Когда задана эта установка, сервер вызывает триггеры вставки для строк, вставляемых в базу данных. KeepIdentity Сохранять идентификационные значения источника. Когда эта установка не задана, идентификационные значения присваиваются таблицей назначения. KeepNulls Сохранять значения NULL в таблице назначения независимо от параметров значений по умолчанию. Когда эта установка не задана, значения null, где возможно, заменяются значениями по умолчанию. TableLock Получать блокировку массового обновления на все время выполнения операции массового копирования данных. Когда эта установка не задана, используется блокировка строк. UseInternalTransaction Когда эта установка задана, каждая операция массового копирования данных выполняется в транзакции. Если задать эту установку и предоставить конструктору объект SqlTransaction, будет выброшено исключение ArgumentException. Мы можем опционально включить проверку триггеров и ограничений на стороне БД (по умолчанию выключена). При указании BatchSize и UseInternalTransaction, данные будут отправляться на сервер блоками в отдельных транзакциях. Таким образом, все успешные блоки до первого ошибочного, будут сохранены в БД.4. Продвинутая вставка с использованием MERGE SqlBulkCopy умеет только добавлять записи в таблицу, и никакого функционала для изменения уже существующих записей не предоставляет. И тем не менее, мы можем ускорить выполнение Update операций! Как? Вставляем данные во временную пустую таблицу, а затем синхронизируем таблицы с помощью инструкции MERGE, дебютировавшей в SQL Server 2008: MERGE (Transact-SQL)Выполняет операции вставки, обновления или удаления для целевой таблицы на основе результатов соединения с исходной таблицей. Например, можно синхронизировать две таблицы путем вставки, обновления или удаления строк в одной таблице на основании отличий, найденных в другой таблице.
Используя MERGE, легко и просто реализовать различную логику по обработке дубликатов: обновлять данные в целевой таблице, либо игнорировать или даже удалять совпадающие записи. Таким образом, мы можем сохранить данные из коллекции объектов EF в БД по следующему алгоритму: cоздать/очистить временную таблицу, полностью идентичную целевой таблице; вставить данные с помощью SqlBulkCopy во временную таблицу; используя MERGE, добавить записи из временной таблицы в целевую. Шаги 1 и 3 мы рассмотрим подробнее.Временная таблицаНеобходимо создать таблицу в БД, полностью повторяющую схему таблицы для вставки данных. Создавать копии вручную — худший вариант из возможных, так как вся дальнейшая работа по сравнению и синхронизации схем таблиц также ляжет на ваши плечи. Надежнее копировать схему программно и непосредственно перед вставкой. Например, с использованием SQL Server Management Objects (SMO):
Server server = new Server (); //SQL auth server.ConnectionContext.LoginSecure = false; server.ConnectionContext.Login = «login»; server.ConnectionContext.Password = «password»; server.ConnectionContext.ServerInstance = «server»;
Database database = server.Databases[«database name»];
Table table = database.Tables[«Order»];
ScriptingOptions options = new ScriptingOptions (); options.Default = true; options.DriAll = true;
StringCollection script = table.Script (options); Стоит обратить внимание на класс ScriptingOptions, содержащий несколько десятков параметров для тонкой настройки генерируемого SQL. Полученный StringCollection развернем в String. К сожалению, лучшего решения, чем заменить в скрипте имя исходной таблицы на имя временной а-ля String.Replace («Order», «Order_TEMP»), я не нашел. Буду благодарен за подсказку красивого решения по созданию копии таблицы в пределах одной БД. Выполним готовый скрипт любым удобным способом. Копия таблицы создана!
Нюансы использования SMO в .NET 4+ Необходимо отметить, что вызов Database.ExecuteNonQuery в .NET 4+, выбрасывает исключение вида: Mixed mode assembly is built against version 'v2.0.50727' of the runtime and cannot be loaded in the 4.0 runtime without additional configuration information.
cвязанное с тем, что замечательная библиотека SMO есть только под .NET 2 Runtime. К счастью, есть workaround:
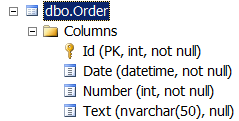
MERGE INTO [Order] AS [Target] USING [Order_TEMP] AS [Source] ON Target.Id = Source.Id WHEN MATCHED THEN UPDATE SET Target.Date = Source.Date, Target.Number = Source.Number, Target.Text = Source.Text WHEN NOT MATCHED THEN INSERT (Date, Number, Text) VALUES (Source.Date, Source.Number, Source.Text); Данный SQL-запрос сравнивает записи из временной таблицы [Order_TEMP] с записями из целевой таблицы [Order], и выполняет Update, если найдена запись с аналогичным значением в поле Id, либо Insert, если такой записи не найдено. Выполним код любым удобным способом, и готово! Не забываем очистить/удалить временную таблицу по вкусу.5. Сравнение производительности Среда выполнения: Visual Studio 2013, Entity Framework 6.1.1 (Database First), SQL Server 2012. Для тестирования использовалась таблица [Order] (схема таблицы приведена выше). Были проведены измерения времени выполнения для рассматриваемых в статье подходов к сохранению данных в БД, результаты представлены в ниже (время указано в секундах): Insert Способ фиксации изменений в базе данных Количество записей 1000 10000 100000 Add + SaveChanges 7,3 101 6344 Add + (AutoDetectChangesEnabled=false) + SaveChanges 6,5 64 801 Add + отдельный контекст + SaveChanges 8,4 77 953 AddRange + SaveChanges 7,2 64 711 SqlBulkCopy 0,01 0,07 0,42 Ого! Если использовать метод Add для добавления в контекст и SaveChanges для сохранения, сохранение 100000 записей в БД займет почти 2 часа! В то время, как SqlBulkCopy на эту же задачу тратит менее секунды! Update Способ фиксации изменений в базе данных Количество записей 1000 10000 100000 SaveChanges 6,2 60 590 SqlBulkCopy + MERGE 0,04 0,2 1,5 Вновь SqlBulkCopy вне конкуренции. Исходный код тестового приложения доступен на GitHub.Выводы В случае работы с контекстом, содержащим большое количество объектов (10³ и выше), отказ от инфраструктуры Entity Framework (добавление в контекст + сохранение контекста) и переход на SqlBulkCopy для записи в БД может обеспечить прирост производительности в десятки, а то и сотни раз. Однако, по моему мнению, использовать связку EF+SqlBulkCopy повсеместно — явный признак того, что с архитектурой вашего приложения что-то не так. Рассмотренный в статье подход следует рассматривать как простое средство для ускорения производительности в узких местах уже написанной системы, если менять архитектуру/технологию по каким-либо причинам затруднительно. Любой разработчик, использующий Entity Framework, должен знать сильные и слабые стороны этого инструмента. Успехов! Дополнительные ссылки
