[Из песочницы] ELK+R как хранилище логов
В компании заказчика появилась необходимость в неком хранилище логов с возможностью горизонтального масштабирования. Исходя из начала задачи первая мысль — Splunk. К сожалению, стоимость данного решения уходила далеко за пределы бюджета заказчика.
В итоге выбор пал на связку Logstash + Elasticsearch + Kibana.
Вдохновившись статьей на Хабре «Собираем и анализируем логи с помощью Lumberjack+Logstash+Elasticsearch+RabbitMQ» и вооружившись небольшим «облаком» на DevStack, начались эксперименты.
Первое, что понравилось — RabbitMQ как промежуточное звено, дабы не растерять логи. Но, к сожалению, logstash-forwarder оказался не очень удобным в сборе логов из Windows, а так как большинство клиентов будет как раз на WinServer, то это оказалось критичным. Поиски привели к nxlog community edition. Связку с logstash оказалось найти не трудно (использовался банально tcp + json).
И начались тесты. Все эксперименты проводились на конфигурации:
Name/Cores/RAM/HDD
HAProxy: 1Core/512MB/4Gb
LIstener: 2Core/512MB/4G
RABBIT: 2Core/2Gb/10G
Filter:2Core/2G/4G
ES_MASTER: 2Core/2G/4G
ES_DATA: 2Core/2G/40G
ES_BALANSER: 2Core/2G/4G
KIBANA: 2Core/2G/4G
Система: Ubuntu Server 14.04 LTS (образ здесь).
Первый подход
Связка: nxlog => haproxy => logstash (listener) => rabbimq => logstash (filter) => elasticsearch
listener`ов и filter`ов по 2 инстанса
elasticsearch — кластер из 2 «равноправных» инстанса
Преимущества:
- Прост в установке на стороне заказчика.
Недостатки:
- Узкое место — rabbitmq. После перезагрузки rabbitmq приходилось перезапускать listener`ы, т. к. они по неведомой мне причине не хотели переподключаться самостоятельно. Да и падение «кролика» никто не отменял;
- Elasticsearch с очень большой потугой переваривал запросы, после наполнения индекса > 100mb;
- Неудобно добавлять новые инстансы в ES кластер: приходилось руками дописывать в filter список доступных серверов.
Ошибки были учтены + появилось новое требование: система должна быть на CentOS.
Второй подход
Связка: nxlog => haproxy => logstash (listener) => haproxy (2) => rabbimq => haproxy (3) => logstash (filter) => elasticsearch-http => elasticsearch-data+master
haproxy (2) и haproxy (3) — это одна и та же машина.
Под ES 5 машин — ES-http, 2xES-data и 2xES-master.
Преимущества:
- Горизонтальный рост до бесконечности;
- Отказоустойчивость;
- Можно реализовать обмен между listener и filter на rabbitmq ram нодах (+10 к производительности).
Недостатки:
- Массивность решения;
- Трудности в установке у клиента;
В итоге получили примерно такую систему:
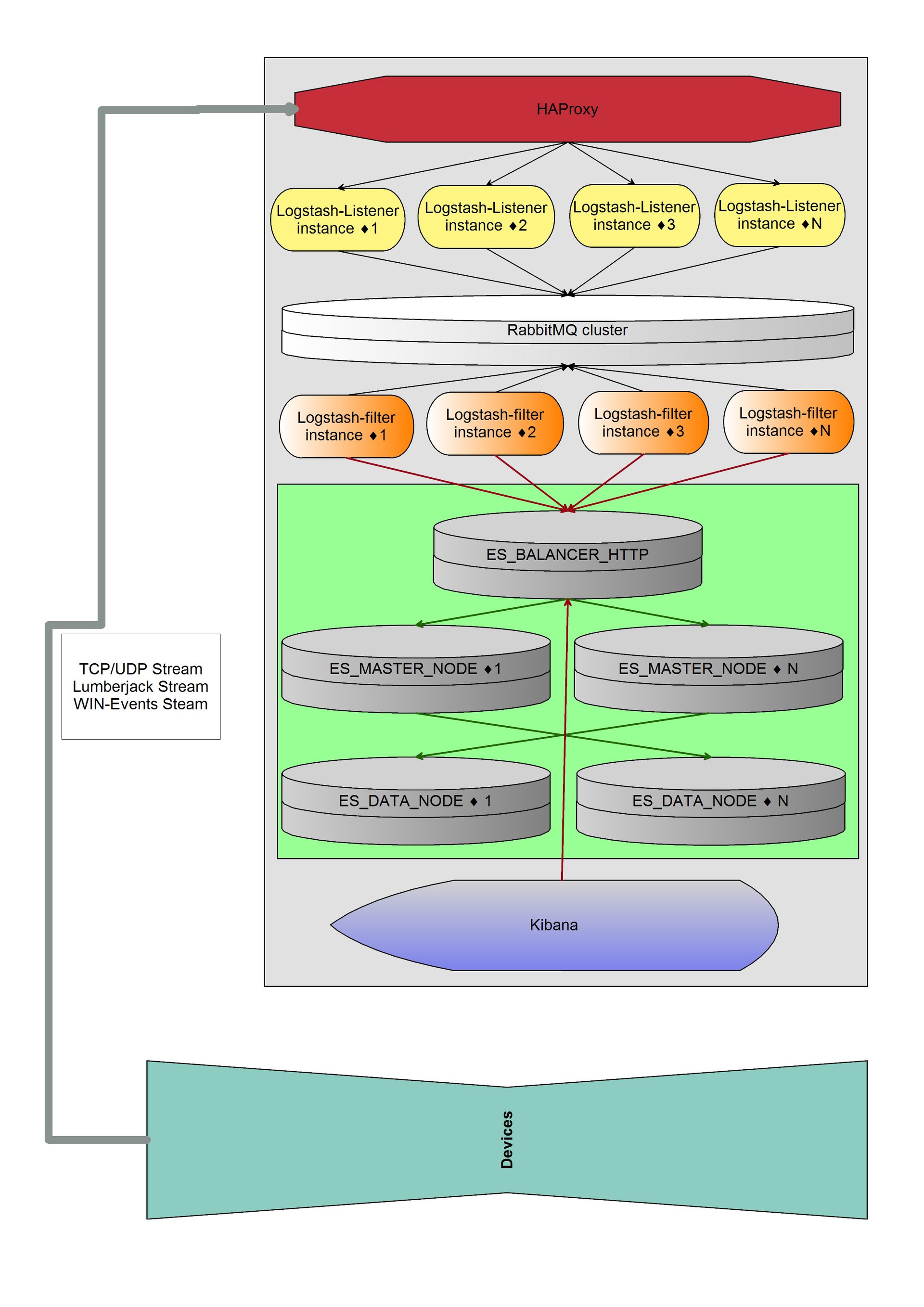
Система спокойно «переваривает» 17 488 154 сообщений логов в день. Размер сообщений — до 2 кб.
Одним из преимуществ ES является тот факт, что размер базы сообщений очень сильно сокращается при однотипности полей: при потоке в 17 млн сообщений и среднем размере сообщения 1 кб, размер базы был чуть больше 2Гб. Почти в 10 раз меньше, чем должен быть.
При такой конфигурации оборудования свободно проходит до 800 сообщений/сек без задержек. При большем количестве сообщений растёт очередь, но для пиковых нагрузок не так критично.
TODO:
- После перезапуска по очереди всех инстансов RabbitMQ, logstash-listener начинал истерически и неуспешно пытаться переподключиться к Rabbit`у. Необходим перезапуск listener`ов. Поиск причин продолжается;
- «Выжать» из Elasticsearch больше производительности.
Проблема с установкой решена средствами Chef-server.
Всё уместилось (и ещё место осталось) на тестовом стенде i5–4570 4×3.2GHz + 24Gb RAM + 2×500Gb HDD.
Если интересно и актуально, то могу написать подробный мануал, что и как устанавливать.
