[Из песочницы] Балансировка двух провайдеров на основе BGP и EEM
Статья рассматривает способ управления BPG-анонсами на маршрутизаторах Cisco, c операционной системой IOS XE, с помощью Cisco Embedded Event Manager (EEM) для балансировки входящего трафика и резервирования uplink от нескольких вышестоящих провайдеров.
Введение
Часто в сети небольшого провайдера можно встретить ситуацию, когда uplink представляет собой BGP-присоединение к двум или более операторам. Причем, второй провайдер используется не в качестве резерва, а вместе и одновременно с первым. Кроме того, ситуация осложняется тем, что каналы эти могут быть не симметричны по скорости. Например, при общей потребности uplink в 2 Gbps покупается два канала у двух разных провайдеров: 1500 Mbps и 500 Mbps. Протокол BGP, в этом случае замечательно решает задачу резервирования. Конечно, полноценного резерва тут нет. Очевидно, что нельзя зарезервировать два гигабита пятьюстами мегабитами без деградации сервиса для абонентов, однако, полного отказа услуги не произойдет. А если отказ произойдет не в ЧНН (часы наибольшей нагрузки), то сервис может не пострадать вовсе.
Значительно больше проблем в такой ситуации возникает не с резервированием, а с балансировкой. Особенно из-за несимметричности каналов по скорости. Причем, балансировка исходящего трафика (который мы можем, более или менее, контролировать) не столь важна. А вот контролировать входящий трафик значительно сложнее.
Рассмотрим, в качестве примера, следующую схему:
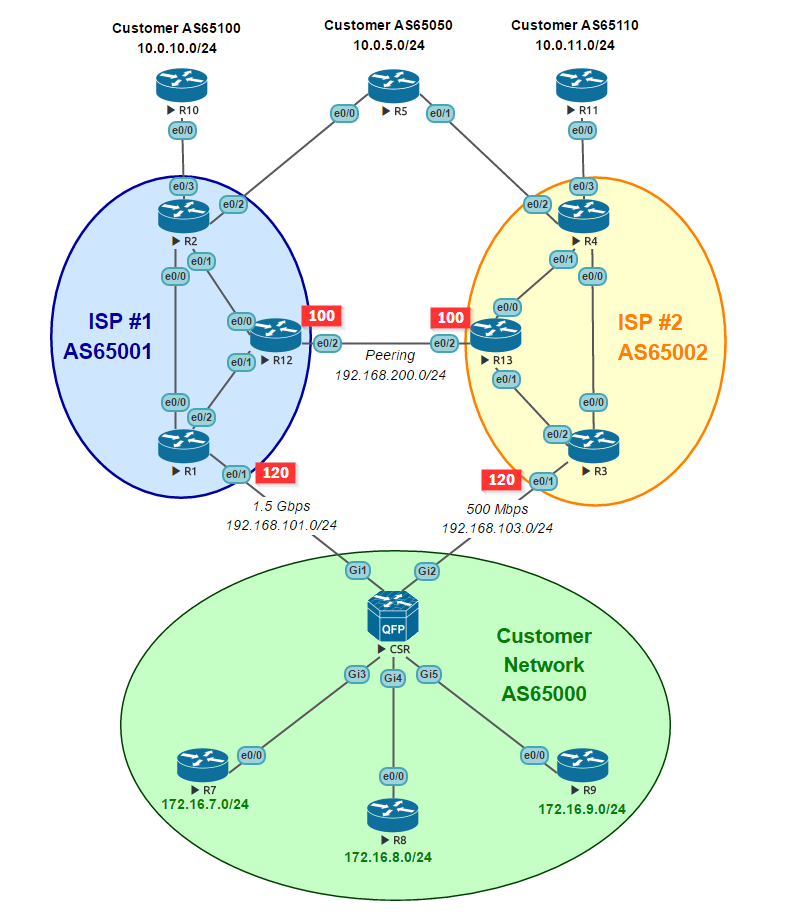
«Наша» AS65000 подключена в двум провайдерам: ISP #1 (AS65001) и ISP #2 (AS65002) по каналам шириной 1,5 Gbps и 500 Mbps, соответственно. Абоненты в нашей сети находятся за тремя локальными маршрутизаторами R7, R8 и R9 и используют, соответственно, три подсети:
- 172.16.7.0/24
- 172.16.8.0/24
- 172.16.9.0/24
В качестве «ресурсов глобальной сети Интернет» выступают три маршрутизатора:
- R5 (AS65050, 10.0.5.0/24) — имеет присоединение к обоим провайдерам;
- R10 (AS65100, 10.0.10.0/24) — присоединен только к ISP#1;
- R11 (AS65110, 10.0.11.0/24) — присоединен только к ISP#2.
Провайдеры имеют между собой пиринговый стык (между R12 и R13).
В отличии от клиентского присоединения, загрузка которого прямо связано с выручкой провайдера, пиринговый стык может не приносить провайдеру непосредственный доход, а то и вовсе, быть расходным. Поэтому нормальной практикой является увеличение BPG Local Preference для клиентских присоединений, и его уменьшение для пиров. На нашей схеме значения local preference обозначены красными маркерами: на пиринге у обоих провайдеров стоит значение 100 (по умолчанию), а на соединениях с нами, как с клиентом, увеличенное 120. Такой вариант позволяет провайдеру, при получении одинакового BPG-маршрута от клиента и другого провайдера, явным образом отдавать предпочтение клиентскому присоединению. Одновременно, именно это и является одной из причин трудностей с балансировкой uplink стандартными средствами BGP.
Метод балансировки
Как я уже писал, балансировка исходящего трафика, для большинства провайдеров, не столь критична, поэтому темой статьи является управление именно входящим трафиком. Нам нужно разложить наш трафик по двум не симметричным каналам:
- 1500 Mbps через ISP#1;
- 500 Mbps через ISP#2.
Эмпирическим путем устанавливаем два диапазона IP-адресов, которые «потребляют» трафик в требуемой нам пропорции. Для простоты ситуации (принцип метода от этого не меняется) допустим, что абоненты за маршрутизаторами R7 и R8 потребляют примерно три четверти общего входящего трафика, а оставшаяся четверть приходится на абонентов маршрутизатора R9. В таком случае, использую BGP анонсы, мы должны добиться что бы трафик для сетей 172.16.7.0/24 и 172.16.8.0/24 шел через ISP#1, а для сети 172.16.9.0/24 — через ISP#2.
Сформируем два префикс-листа и рассмотрим методы, которыми мы можем разделить трафик для них по каналам:
ip prefix-list isp-1-out seq 5 permit 172.16.7.0/24
ip prefix-list isp-1-out seq 10 permit 172.16.8.0/24
ip prefix-list isp-2-out seq 5 permit 172.16.9.0/24AS-PATH Prepend
В качестве стандартного решения такой задачи протокол BGP предлагает механизм AS-PATH Prepend. Суть его в том, что при выборе лучшего маршрута из нескольких возможных, протокол BGP использует значение атрибута AS-PATH, где последовательно перечислены номера всех автономных систем, через которые прошел BGP-анонс. Маршрут с кратчайшим AS-PATH является предпочтительным. Метод AS-PATH prepend позволяет искусственно удлинить значение атрибута для некоторых маршрутов.
Попробуем применить этот метод в нашей сети. Для этого создадим на CRS два route-map и используем их:
route-map isp-1-out permit 10
match ip address prefix-list isp-1-out
route-map isp-1-out permit 20
match ip address prefix-list isp-2-out
set as-path prepend 65000 65000 65000
route-map isp-2-out permit 10
match ip address prefix-list isp-1-out
set as-path prepend 65000 65000 65000
route-map isp-2-out permit 20
match ip address prefix-list isp-2-out
router bgp 65000
address-family ipv4
neighbor 192.168.101.1 route-map isp-1-out out
neighbor 192.168.103.3 route-map isp-2-out outТеперь в сторону ISP#1 префикс 172.16.9.0/24 будет анонсироваться с AS-PATH, удлиненным на три номера AS65000, а в сторону ISP#2 тоже самое будет делаться для префиксов 172.16.7.0/24 и 172.16.8.0/24.
Теперь, в идеале, трафик для каждой группы префиксов должен поступать через своего провайдера, а в случае падения одного из uplink, начнет работать анонс с prepend. Например, при падении ISP#2 трафик для
172.16.9.0/24 не прервется, так как весь мир все равно «видит» этот префикс через ISP#1, хоть с удлиненным AS-PATH.
Этот способ сработал бы, но тут в игру вмешиваются различные local preferences, которые провайдеры используют для клиентов и пиринга. Так как, при выборе маршрута атрибут LOCAL PREFERENCE имеет больший приоритет, чем AS-PATH, внутри каждого провайдера наш prepend не будет играть роли и трафик всегда будет направляться через клиентский канал. В нашей сети этот метод сработает только для AS65050, так как она присоединена в обоим провайдерам.
Посмотрим подробней.
Действительно, на R5 все хорошо:
R5#sh ip bgp
...
* 172.16.7.0/24 192.168.45.4 0 65002 65000 65000 65000 65000 ?
*> 192.168.25.2 0 65001 65000 ?
* 172.16.8.0/24 192.168.45.4 0 65002 65000 65000 65000 65000 ?
*> 192.168.25.2 0 65001 65000 ?
*> 172.16.9.0/24 192.168.45.4 0 65002 65000 ?
* 192.168.25.2 0 65001 65000 65000 65000 65000 ?
R5#sh ip route
...
172.16.0.0/24 is subnetted, 3 subnets
B 172.16.7.0 [20/0] via 192.168.25.2, 1d00h
B 172.16.8.0 [20/0] via 192.168.25.2, 1d00h
B 172.16.9.0 [20/0] via 192.168.45.4, 1d00h
R5#traceroute 172.16.7.1 source 10.0.5.1
...
1 192.168.25.2 0 msec 0 msec 1 msec
2 192.168.12.1 0 msec 1 msec 0 msec
3 192.168.101.100 3 msec 3 msec 3 msec
4 192.168.107.7 2 msec * 2 msec
R5#traceroute 172.16.9.1 source 10.0.5.1
...
1 192.168.45.4 1 msec 0 msec 1 msec
2 192.168.34.3 0 msec 1 msec 0 msec
3 192.168.103.100 3 msec 3 msec 3 msec
4 192.168.109.9 2 msec * 3 msecНа основе атрибута AS-PATH для каждой группы префиксов выбран оптимальный маршрут через своего провайдера, что подтверждает трассировка.
Но вот на R11 (AS65110) все не так радужно.
R11#traceroute 172.16.7.1 source 10.0.11.1
...
1 192.168.114.4 0 msec 1 msec 4 msec
2 192.168.34.3 1 msec 0 msec 0 msec
3 192.168.103.100 3 msec 3 msec 3 msec
4 192.168.107.7 2 msec * 2 msec
R11#traceroute 172.16.9.1 source 10.0.11.1
...
1 192.168.114.4 0 msec 1 msec 0 msec
2 192.168.34.3 0 msec 0 msec 0 msec
3 192.168.103.100 3 msec 2 msec 3 msec
4 192.168.109.9 2 msec * 2 msecТрафик до обоих хостов идет к нам через один и тот же пятисотмегабитный стык.
Причина как раз в local preference. Смотрим на R13 провайдера ISP#2:
R13>sh ip bgp
...
* 172.16.7.0/24 192.168.200.12 0 65001 65000 ?
*>i 192.168.103.100 0 120 0 65000 65000 65000 65000 ?
* 172.16.8.0/24 192.168.200.12 0 65001 65000 ?
*>i 192.168.103.100 0 120 0 65000 65000 65000 65000 ?
* 172.16.9.0/24 192.168.200.12 0 65001 65000 65000 65000 65000 ?
*>i 192.168.103.100 0 120 0 65000 ?
R13#sh ip route
...
172.16.0.0/24 is subnetted, 3 subnets
B 172.16.7.0 [200/0] via 192.168.103.100, 1d00h
B 172.16.8.0 [200/0] via 192.168.103.100, 1d00h
B 172.16.9.0 [200/0] via 192.168.103.100, 1d00hНа маршрутизаторе все BGP-анонсы наших сетей в двух экземплярах:
- полученные через клиентское присоединение (next-hop 192.168.103.100);
- полученные через пиринг (next-hop 192.168.200.12).
Но, несмотря на длинный AS-PATH, для префиксов 172.16.7.0/24 и 172.16.8.0/24 best-маршрут — маршрут с local preference 120 через клиента, т.е. через нас, а не через пиринг. Получается, что ISP#2 направит весь трафик наших абонентов через канал 500Mbps. И, если за этим провайдером окажется дата-центр какого-нибудь крупного контент-провайдера (например VK.com), то это приведет к перегрузке на канале и проблемам с сервисом.
Получается, что стандартный AS-PATH prepend нам не поможет.
Исключение анонсов
Другой способ разделить трафик — просто исключить из BGP-анонсов в сторону оператора те префиксы, трафик на которые мы не хотим получать через этого провайдера.
Попробуем.
Вместо route-map настроим для каждого соседа фильтрующий prefix-list.
router bgp 65000
address-family ipv4
neighbor 192.168.101.1 prefix-list isp-1-out out
neighbor 192.168.103.3 prefix-list isp-2-out outТеперь в сторону каждого провайдера анонсируются только те маршруты, которые должны получать трафик через этот стык:
CSR#sh ip bgp neighbors 192.168.101.1 advertised-routes
...
Network Next Hop Metric LocPrf Weight Path
*> 172.16.7.0/24 192.168.107.7 0 32768 ?
*> 172.16.8.0/24 192.168.108.8 0 32768 ?
Total number of prefixes 2
CSR#sh ip bgp neighbors 192.168.103.3 advertised-routes
...
Network Next Hop Metric LocPrf Weight Path
*> 172.16.9.0/24 192.168.109.9 0 32768 ?
Total number of prefixes 1При таком подходе оператор выстраивает свою таблицу маршрутизации именно так, как нам надо:
R13>sh ip route
...
172.16.0.0/24 is subnetted, 3 subnets
B 172.16.7.0 [20/0] via 192.168.200.12, 00:04:53
B 172.16.8.0 [20/0] via 192.168.200.12, 00:04:53
B 172.16.9.0 [200/0] via 192.168.103.100, 00:05:13Теперь трассировки с R11 идут через разных провайдеров:
R11#traceroute 172.16.7.1 source 10.0.11.1
...
1 192.168.114.4 4 msec 4 msec 4 msec
2 192.168.134.13 1 msec 0 msec 1 msec
3 192.168.200.12 0 msec 1 msec 0 msec
4 192.168.121.1 0 msec 1 msec 1 msec
5 192.168.101.100 2 msec 4 msec 3 msec
6 192.168.107.7 2 msec * 2 msec
R11#traceroute 172.16.9.1 source 10.0.11.1
...
1 192.168.114.4 0 msec 4 msec 0 msec
2 192.168.34.3 0 msec 1 msec 0 msec
3 192.168.103.100 3 msec 3 msec 3 msec
4 192.168.109.9 2 msec * 2 msecОднако, тут возникает проблема с резервированием. Действительно, при падении ISP#2 абоненты из сети 172.16.9.0/24 лишаются сервиса, так как весь мир больше «не видит» маршрута к ним. Обычно, это можно решить анонсированием агрегирования префикса для резерва. Например, если бы мы располагали диапазоном адресов от 172.16.6.0 до 172.16.9.255, то мы могли бы дополнительно анонсировать обоим провайдерам укрупненные подсети 172.16.6.0/23 и 172.16.8.0/23, которые включают в себя наши префиксы. Тогда, при падении одного из провайдеров и исчезновении в Интернете «специфик» маршрутов /24, все равно оставались бы /23, и сервис работал бы у всех абонентов даже на одном uplink. Но в нашем примере такое невозможно. Наши клиентские сети нельзя агрегировать в один или два префикса. Конечно, сети в примере подобраны специально, но, именно, столкновение с такой ситуацией на практике подтолкнуло меня к написанию заметки.
Embedded Event Manager
Мы решили проблему балансировки входящего трафика. Осталось добиться резервирования. Общий путь решения понятен: в случае падения одного из пиров менять фильтр исходящих анонсов на том, пире, что еще «жив». Это можно было бы реализовать «снаружи», меняя настройки нашего пограниченого маршрутизатора скриптом по SSH или SNMP. Однако, цель заметки — сделать все встроенными средствами Cisco.
Тут нам пригодиться механизм Cisco Embedded Event Manager (EEM). Это очень гибкий механизм управления маршрутизатором и траблшутинга проблем на сети, возможности которого выходят далеко за пределы описываемой задачи. Нам от него требуется его умение отловить возникновение определённого события (падение или восстановление BGP-соседства) и выполнить заданный набор команд.
Для начала создадим префикс-лист, который включает в себя все наши префиксы.
ip prefix-list full-out seq 5 permit 172.16.7.0/24
ip prefix-list full-out seq 10 permit 172.16.8.0/24
ip prefix-list full-out seq 15 permit 172.16.9.0/24Теперь сконфигурируем EEM-аплет, который будет запускаться при возникновении в логе записи об изменении статуса BGP-соседства (определяем регулярным выражением). Аплет:
- парсит сообщение в логе и определяет:
- router-id BGP-соседа, который спровоцировал сообщение,
- его статус;
- в зависимости от IP-адреса и статуса применяет для другого BGP-соседу тот или иной префикс-лист;
- «мягко» сбрасывает анонсы в сторону второго соседа, что бы ускорить распространение маршрутной информации и применение сделанных изменений.
Конфигурация аплета:
event manager applet isp
event syslog pattern "neighbor 192.168.10[13].[13] (Up|Down|reset)"
action 01.0 regexp "(192.168.10[13].[13])" "$_syslog_msg" _match _ip
action 02.0 if $_ip eq "192.168.101.1"
action 03.0 set _name "ISP #1"
action 04.0 set _target_ip "192.168.103.3"
action 05.0 set _list "isp-2-out"
action 06.0 elseif $_ip eq "192.168.103.3"
action 07.0 set _name "ISP #2"
action 08.0 set _target_ip "192.168.101.1"
action 09.0 set _list "isp-1-out"
action 10.0 else
action 11.0 exit
action 12.0 end
action 13.0 regexp "(Up|Down|reset)" "$_syslog_msg" _match _state
action 14.0 if $_state eq "Up"
action 15.0 set _status "UP"
action 16.0 else
action 17.0 set _status "DOWN"
action 18.0 set _list "full-list"
action 19.0 end
action 20.0 syslog priority warnings msg "$_name now is $_status !"
action 21.0 syslog priority warnings msg "Applying prefix list '$_list' to the neighbor $_target_ip"
action 22.0 cli command "enable"
action 23.0 cli command "configure terminal"
action 24.0 cli command "router bgp 65000"
action 25.0 cli command "address-family ipv4"
action 26.0 cli command "neighbor $_target_ip prefix-list $_list out"
action 27.0 cli command "end"
action 28.0 syslog priority warnings msg "Soft clear BGP session $_target_ip"
action 29.0 cli command "clear ip bgp $_target_ip soft out"Изначально обе BGP-сессии у нас активны и анонсы выглядят следующим образом:
CSR#show ip bgp summary
...
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
192.168.101.1 4 65001 8 5 7 0 0 00:00:19 3
192.168.103.3 4 65002 8 5 7 0 0 00:00:24 3
CSR#show ip bgp neighbors 192.168.101.1 advertised-routes
...
Network Next Hop Metric LocPrf Weight Path
*> 172.16.7.0/24 192.168.107.7 0 32768 ?
*> 172.16.8.0/24 192.168.108.8 0 32768 ?
Total number of prefixes 2
CSR#show ip bgp neighbors 192.168.103.3 advertised-routes
...
Network Next Hop Metric LocPrf Weight Path
*> 172.16.9.0/24 192.168.109.9 0 32768 ?
Total number of prefixes 1На сети ISP#2 наши анонсы выглядят следующим образом:
R13>show ip bgp
...
Network Next Hop Metric LocPrf Weight Path
*> 172.16.7.0/24 192.168.200.12 0 65001 65000 ?
*> 172.16.8.0/24 192.168.200.12 0 65001 65000 ?
*>i 172.16.9.0/24 192.168.103.100 0 120 0 65000 ?Трассировки с R11 идут в нашу сеть так, как нам нужно:
R11#traceroute 172.16.7.1 source 10.0.11.1
Type escape sequence to abort.
Tracing the route to 172.16.7.1
VRF info: (vrf in name/id, vrf out name/id)
1 192.168.114.4 0 msec 1 msec 0 msec
2 192.168.134.13 0 msec 0 msec 1 msec
3 192.168.200.12 0 msec 0 msec 1 msec
4 192.168.121.1 1 msec 1 msec 1 msec
5 192.168.101.100 3 msec 3 msec 3 msec
6 192.168.107.7 2 msec * 3 msec
R11#traceroute 172.16.9.1 source 10.0.11.1
Type escape sequence to abort.
Tracing the route to 172.16.9.1
VRF info: (vrf in name/id, vrf out name/id)
1 192.168.114.4 1 msec 0 msec 1 msec
2 192.168.34.3 0 msec 1 msec 0 msec
3 192.168.103.100 3 msec 3 msec 3 msec
4 192.168.109.9 2 msec * 2 msecТеперь попробуем отключить пир с ISP#1 со стороны провайдера. В результате одна из BGP-сессий на нашем бордере переходит в IDLE:
CSR#show ip bgp summary
...
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
192.168.101.1 4 65001 0 0 1 0 0 00:00:10 Idle
192.168.103.3 4 65002 26 26 9 0 0 00:16:31 3В логе мы при этом видим, что как только возникло событие %BGP-5-NBR_RESET: Neighbor 192.168.101.1 reset (Peer closed the session) сработал наш аплет и изменил префикс-лист:
*Jul 20 09:00:58.208: %BGP-5-NBR_RESET: Neighbor 192.168.101.1 reset (Peer closed the session)
*Jul 20 09:00:58.208: %BGP-5-ADJCHANGE: neighbor 192.168.101.1 Down Peer closed the session
*Jul 20 09:00:58.214: %HA_EM-4-LOG: isp: ISP #1 now is DOWN !
*Jul 20 09:00:58.214: %HA_EM-4-LOG: isp: Applying prefix list 'full-list' to the neighbor 192.168.103.3
*Jul 20 09:00:58.778: %SYS-5-CONFIG_I: Configured from console by on vty0 (EEM:isp)
*Jul 20 09:00:58.879: %HA_EM-4-LOG: isp: Soft clear BGP session 192.168.103.3Посмотрим, что теперь мы анонсируем в сторону ISP#2:
CSR#show ip bgp neighbors 192.168.103.3 advertised-routes
...
Network Next Hop Metric LocPrf Weight Path
*> 172.16.7.0/24 192.168.107.7 0 32768 ?
*> 172.16.8.0/24 192.168.108.8 0 32768 ?
*> 172.16.9.0/24 192.168.109.9 0 32768 ?
Total number of prefixes 3Т.е. теперь мы анонсируем через ISP#2 все наши префиксы. Вот как это теперь выглядит на R13:
R13>show ip bgp
...
Network Next Hop Metric LocPrf Weight Path
*>i 172.16.7.0/24 192.168.103.100 0 120 0 65000 ?
*>i 172.16.8.0/24 192.168.103.100 0 120 0 65000 ?
*>i 172.16.9.0/24 192.168.103.100 0 120 0 65000 ?А все трассировки в нашу сеть идут через одного провайдера.
При восстановлении BGP-сессии с IPS#1 аплет снова вернет префикс-лист для ISP#2 в исходное положение.
Заключение
Целью статьи было кратко рассмотреть применение Cisco EEM для управления входящим трафиком при балансировке нескольких аплинков, и, надеюсь, это удалось. Конечно, данный способ едва ли возможно назвать оптимальным. Скорее, это решение «в лоб». Однако, он работает и обеспечивает определенную степень отказоустойчивости. Для написания заметки вся схема собиралась в UNELAB на образах Cisco IOL и Cisco CSRv1000. Конфигурации всех устройств из рассматриваемго примера можно скачать по ссылке.
