[Из песочницы] Анализ популярности YouTube видео участников Евровидения 2020
13 марта на официальном YouTube канале Евровидения была выложена композиция группы Little Big, которая будет представлять Россию на конкурсе. Посмотрев клип, захотелось сравнивать статистику видео нашей группы, с видео других участников; какие ролики самые просматриваемые, у кого самый большой процент лайков, кого чаще всего комментируют. Гугление готовой статистики ни к чему не привело. Поэтому было решено самому собрать нужную статистику.
Открыв плейлист участников можно увидеть 39 роликов, по факту там 38 песен, композиция Hurricane — Hasta La Vista — Serbia задваивается, поэтому статистика по ней будет просуммирована. Для сбора статистики будем использовать R.
Нам понадобятся следующие пакеты:
library(tuber) # пакет взаимодействует с API YouTube, выгрузит нам статистику по роликам
library(dplyr) # пакет для работы с таблицами
library(ggplot2) # рисует графики
Для начала переходим в консоль разработчика google и создаем ключ OAuth на api «YouTube Data API v3». Получив ключ авторизуемся из R.
yt_oauth("Идентификатор клиента", "Секретный код клиента")
Теперь можем собирать статистику:
# получаем список роликов из плэйлиста
list_videos <- get_playlist_items(filter = c(playlist_id = "PLmWYEDTNOGUL69D2wj9m2onBKV2s3uT5Y"))
# Собираем статистику по просмотрам, функция get_stats
stats_videos <- lapply(as.character(list_videos$contentDetails.videoId), get_stats) %>%
bind_rows()
stats_videos <- stats_videos %>%
mutate_at(vars(-id), as.integer)
# Получаем названия роликов, функция get_video_details
description_videos <- lapply(as.character(list_videos$contentDetails.videoId), get_video_details)
description_videos <- lapply(description_videos, function(x) {
list(
id = x[["items"]][[1]][["id"]],
name_video = x[["items"]][[1]][["snippet"]][["title"]]
)
}) %>%
bind_rows()
Т.к. названия роликов имеют шаблон Исполнитель — Название песни — Страна [Код страны] — Official Music Video — Eurovision 2020, то все что находится после страны, можно удалить. Удаляем и объединяем таблицу статистики с таблицей названий роликов.
# Удаляем лишнюю часть названия ролика
description_videos$name_video <- description_videos$name_video %>%
gsub("[^[:alnum:][:blank:]?&/\\-]", '', .) %>%
gsub("( .*)|( - Offic.*)", '', .)
# Объединяем таблицу названий роликов со статистикой
df <- description_videos %>%
left_join(stats_videos, by = 'id') %>%
rowwise() %>%
mutate( # считаем долю лайков
proc_like = round(likeCount / (likeCount + dislikeCount), 2)
) %>%
ungroup()
# Hurricane - Hasta La Vista - Serbia две композиции в одном плейлисте, суммируем их
df <- df %>%
group_by(name_video) %>%
summarise(
id = first(id),
viewCount = sum(viewCount),
likeCount = sum(likeCount),
dislikeCount = sum(dislikeCount),
commentCount = sum(commentCount),
proc_like = round(likeCount / (likeCount + dislikeCount), 2)
)
df$color <- ifelse(df$name_video == 'Little Big - Uno - Russia','red','gray')
Теперь у нас есть итоговая таблица для анализа и можно начать смотреть кто самый популярный. Формируем графики.
# Кол-во просмотров
ggplot(df, aes(x = reorder(name_video, viewCount), y = viewCount, fill = color)) +
geom_col() +
coord_flip() +
theme_light() +
labs(x = NULL, y = "Кол-во просмотров") +
guides(fill = F) +
scale_fill_manual(values = c('gray', 'red')) +
scale_y_continuous(labels = scales::number_format(big.mark = " "))
# Доля лайков к дизлайкам
ggplot(df, aes(x = reorder(name_video, proc_like), y = proc_like, fill = color)) +
geom_col() +
coord_flip() +
theme_light() +
labs(x = NULL, y = "Доля лайков к дизлайкам") +
guides(fill = F) +
scale_fill_manual(values = c('gray', 'red')) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1))
# Кол-во комментариев
ggplot(df, aes(x = reorder(name_video, commentCount), y = commentCount, fill = color)) +
geom_col() +
coord_flip() +
theme_light() +
labs(x = NULL, y = "Кол-во комментариев") +
guides(fill = F) +
scale_fill_manual(values = c('gray', 'red')) +
scale_y_continuous(labels = scales::number_format(big.mark = " "))
# Доля комментариев к просмотрам
ggplot(df, aes(x = reorder(name_video, commentCount/viewCount), y = commentCount/viewCount, fill = color)) +
geom_col() +
coord_flip() +
theme_light() +
labs(x = NULL, y = "Доля комментариев к просмотрам") +
guides(fill = F) +
scale_fill_manual(values = c('gray', 'red')) +
scale_y_continuous(labels = scales::percent_format(accuracy = 0.25))
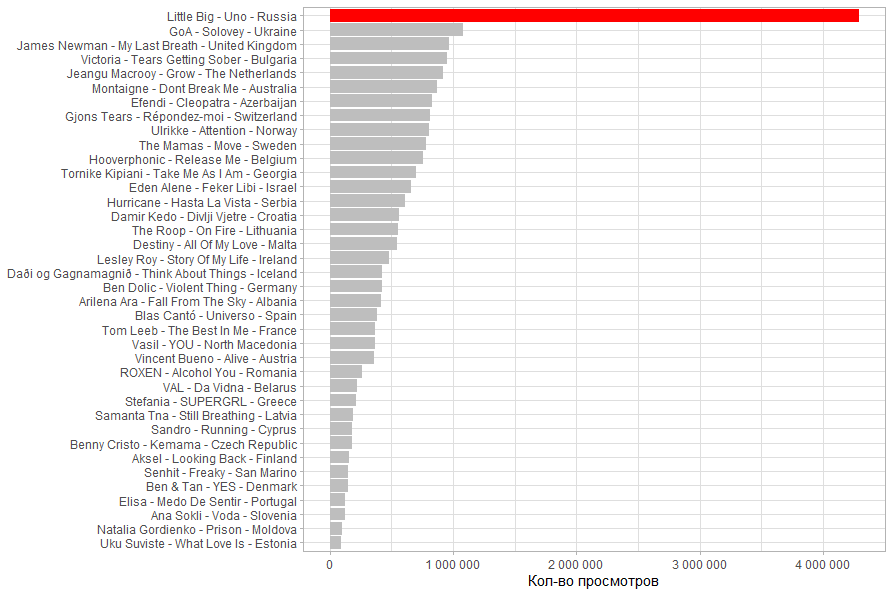
Небольшая ремарка, когда я задался темой статьи у Little Big было меньше 1 млн просмотров, и часть показателей не так сильно отличалась от других участников.
Количество просмотров. У композиции Little Big виден огромный отрыв, но это больше связано с тем что ролик попал в тренды. А вот самое маленькое кол-во просмотров у эстонской группы.
Доля лайков среди суммы лайков, дизлайков. Больше всего смотревшим понравились композиции Грузии и Литвы. А вот самая плохая композиция у Чехии.

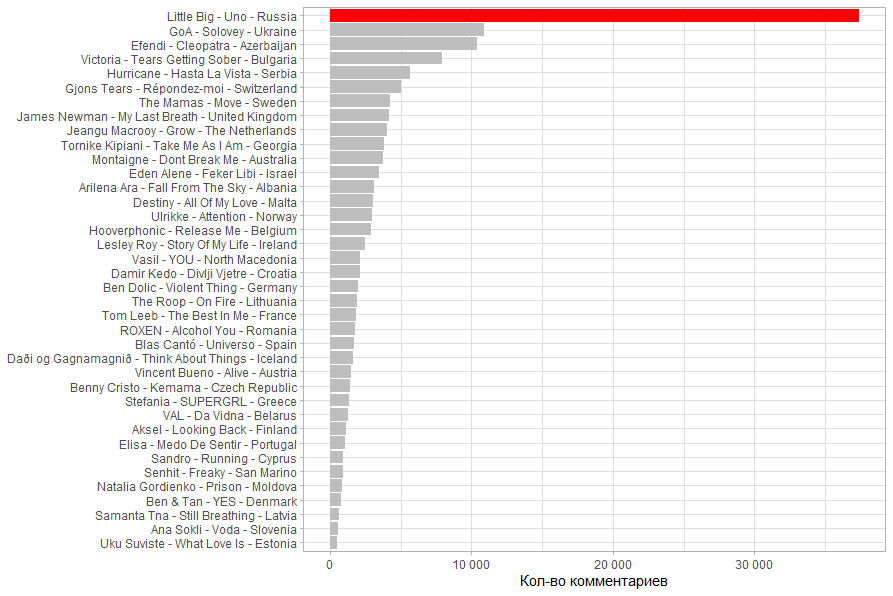
Количество комментариев коррелирует с количеством просмотров.
Доля комментариев к просмотрам(комментарии / просмотры). Чем больше комментариев по отношению к просмотрам тем более вероятна заинтересованность просмотревших. Наибольший интерес вызывает клип Азербайджана и Украины.
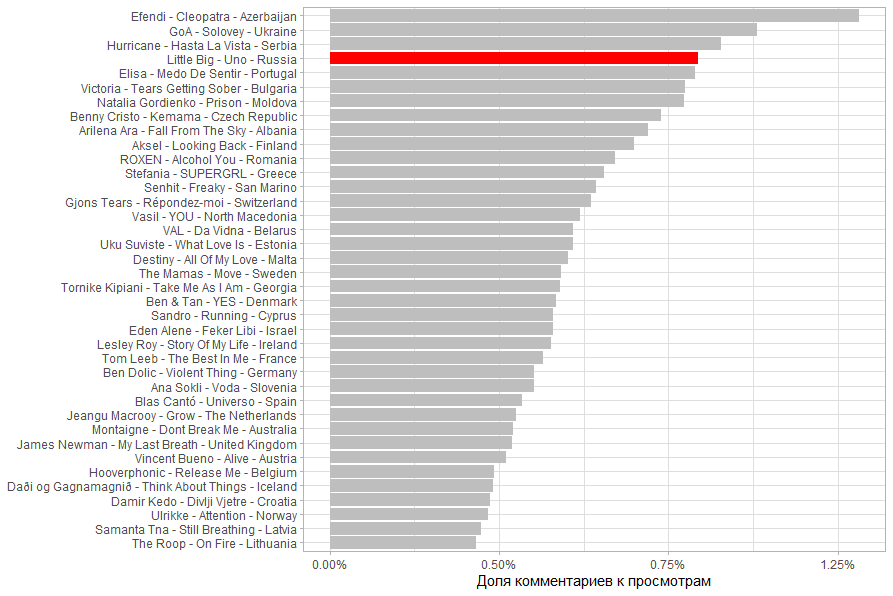
Итого по состоянию на 13.03.2020 18:00 в той или иной мере у пользователей вызывают интерес клипы России, Грузии, Литвы, Азербайджана и Украины.
