[Из песочницы] Анализ Minor Violations Java кода на платформе Duerank.com (часть 1)

Введение
Что мы знаем об ошибках в коде приложений, написанных на Java? Ну, мы наверняка знаем, что они там встречаются. А насколько часто встречаются? Как много делает разнообразных ошибок в своём коде разработчик? Под ошибками мы понимаем не только баги, но и наличие различных code smell, vulnerabilities, violations. Можно ли это все измерить? Можно ли на основе этих измерений определить качество кода репозитория, разработчики и продукта в целом? Можно ли таким образом сравнивать качество кода различных разработчиков и выбирать себе в партнёры более сильного? Можно ли получить повышение зарплаты, показав прирост качества своего кода и снижение уровня своего технического долга? Задача команды как раз и состоит в том, чтобы утвердительно ответить на все эти вопросы.
В этой работе мы будем рассматривать Minor Violations в Java коде, которые потенциально могут влиять на продуктивность разработчика как, например:
- неиспользование code convention;
- finalizer ничего не делает, кроме вызова finalizer суперкласса;
- слишком длинные строки;
- switch должен иметь не менее 3 опций и т. д.
Начало работы
Наши исследования основываются на анализе показателей качества исходного кода, написанного на Java, и полученного из открытых репозиториев GitHub. Результаты исследования компоновались в один большой csv-файл, а анализ полученных данных производился с помощью уже ставшего де-факто стандартом стека: scipy, numpy, pandas, matplotlib.
Стандартный импорт необходимых инструментов:
import scipy
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import statsmodels.api as sm
Читаем данные из csv-файла, отбрасываем все строки, в которых есть неполные данные, выбираем для дальнейшего анализа все данные которые относятся к языку Java и выведем некоторую предварительную статистику, чтобы узнать, что из себя представляют данные:
df = pd.read_csv('ScanGitHub.csv')
df = df.dropna()
df_Java = df[df['Repository Language'] == 'Java']
print(np.sum(df_Java['Lines Of Code']))
df_Java[['Lines Of Code', 'Minor Violations']].describe()
Как результат, мы получили, что на 60 959 просканированных репозиториев приходится 276 015 051 строк кода. В среднем в одном репозитории содержится 4528 строк кода и 150 Minor Violations:

Интересно, что 50% от всех просканированных нами репозиториев являются достаточно небольшими — количество строк кода составляет 711, а количество Minor Violations составляет 22.
Но эти показатели достаточно неинформативны, также как и средняя температура по палате. Необходимо дальнейшее изучение.
Давайте посмотрим, как распределены репозитории по количеству строк кода:
f, ax = plt.subplots(1)
ax.hist(df_Java['Lines Of Code'], color='#00ab6c', bins=100, alpha=0.5, rwidth=0.85, label='SLOC distribution')
ax.grid(True)
ax.set_xlabel('SLOC')
ax.set_ylabel('# of repositories')
ax.legend(loc='best')
df_Java['Lines Of Code'].describe()
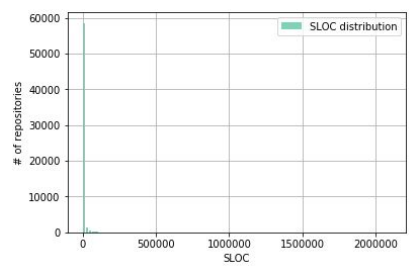
Те, кто ожидал тут увидеть нормальное распределение, думаю, разочаровались. Но о том, что его тут быть не может, нам подсказывала предыдущая табличка! Как можно объяснить этот результат? Очень большое количество проектов имеет относительно очень маленькое количество строк кода, поскольку в открытый доступ на GitHub выкладываются в основном индивидуальные проекты и небольшие open-source коллаборации.
Для уменьшения масштаба по осям применяют различные техники, но в данном случае будет удобно логарифмировать значение количества строк кода. Давайте посмотрим, что из этого получится:
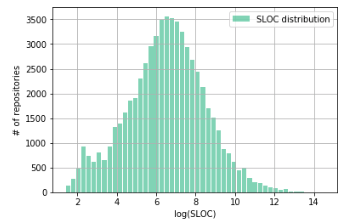
Действительно, после логарифмирования наше распределение больше похоже на нормальное. Есть небольшая аномалия в районе 2–3 (что соответствует ~7–20 строк кода), связанная, по видимому, с большим количеством HelloWorld проектов.
Исследуем теперь распределение Minor Violations.
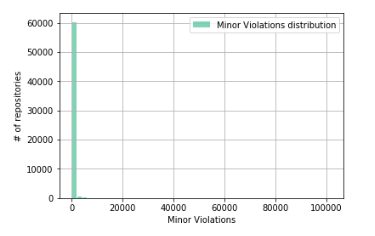
Что-то похожее на то, что было в случае распределения количества строк кода в репозитории? Действительно, было бы наивным полагать, что Minor Violations будут распределены иначе, если считать, что в среднем количество Minor Violations, приходящихся на одну строку кода, является постоянной величиной.
Снова проделаем трюк с логарифмированием:
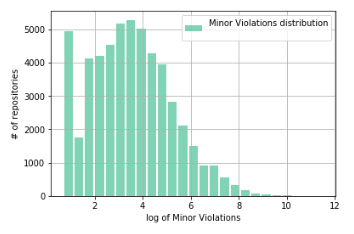
И снова мы получаем искажение распределения в области малых значений Minor Violations, соответствующих малым значениям количества строк кода.
Отфильтруем данные по количеству строк кода и посмотрим, что получится (почему мы фильтруем по количеству строк кода > 1000 будет понятно ниже):
sample = df_Java[(df_Java['Minor Violations'] > 1)&(df_Java['Lines Of Code']>1000)]['Minor Violations']
ax.hist(np.log(sample), color='#00ab6c', bins=25, alpha=0.5, rwidth=0.85, label='Minor Violations distribution\nSLOC > 1000')
ax.grid(True)
ax.set_xlabel('log of Minor Violations')
ax.set_ylabel('# of repositories')
ax.legend(loc='best')
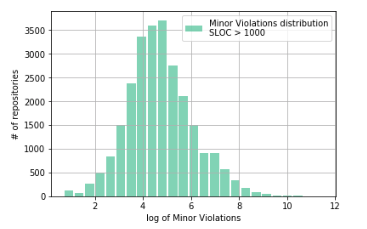
Вот, другое дело! Как видно из графика, наша гипотеза об искажении распределения данными, соответствующими репозиториям с малым (до 1000) количеством строк кода, подтвердилась.
Поиск связи между SLOC и Minor Violations
Приступим теперь к исследованию корреляции между количеством строк кода и Minor Violations и попытаемся ответить на сакральный вопрос: что происходит с качеством кода, если его объем растет.
ax.scatter(df_Java['Lines Of Code'], df_Java['Minor Violations'], c='#00ab6c', alpha=0.30, edgecolors='none', marker='.', label='Java')
ax.set_xlabel('SLOC')
ax.set_ylabel('Minor Violations')
ax.legend(loc='best')
ax.grid(True)
И-и-и-и… Это, наверное, снова не то, что мы ожидали увидеть!
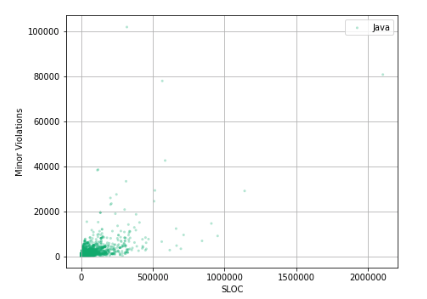
Большая часть данных сосредоточена в интервале 0–500000 строк кода и 0–2000 Minor Violations. Увеличим этот участок и посмотрим, что там.
ax.scatter(df_Java['Lines Of Code'], df_Java['Minor Violations'], c='#00ab6c', alpha=0.30, edgecolors='none', marker='.', label='Java')
ax.set_xlabel('SLOC')
ax.set_ylabel('Minor Violations')
ax.legend(loc='best')
ax.grid(True)
ax.set_xlim(0, 50000)
ax.set_ylim(0, 5000)
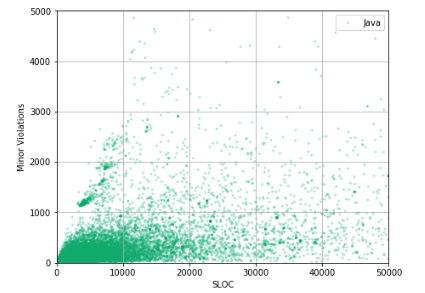
Сложно сказать, есть ли какая-либо корреляция между количеством строк кода и количеством Minor Violations в репозитории. Для того, чтобы выявить эту корреляцию, необходимо линеаризировать эту зависимость, провести feature engineering.
Для успешного проведения feature engineering первым делом необходимо исследовать изменения формы распределение количества строк кода по мере увеличения Minor Violations, а также изменения формы распределения Minor Violations по мере увеличения количества строк кода репозитория.
Рассмотрим, как изменяется форма распределения Minor Violations с ростом количества строк кода в репозитории:
f, ax = plt.subplots(nrows=5, ncols=2)
f.set_figwidth(10)
f.set_figheight(10)
for i in range(10):
low_lim = 5000 * i - 1000
up_lim = 5000 * i + 1000
_df_Java = df_Java[(df_Java['Lines Of Code'] > low_lim) & (df_Java['Lines Of Code'] < up_lim)]
ax[i//2][i%2].hist(_df_Java['Minor Violations'],
color='#00ab6c', bins=20 if i < 9 else 20, alpha=0.5, rwidth=0.85,
label='Minor Violations distribution\n({} < SLOC < {})'.format(0 if low_lim < 0 else low_lim, up_lim))
ax[i//2][i%2].grid(True)
ax[i//2][i%2].set_xlabel('# of Minor Violations')
ax[i//2][i%2].set_ylabel('# of repositories')
ax[i//2][i%2].legend(loc='best')
f.savefig('fig.png')
В данном случае мы видим, что все распределения не являются нормальными и похожи на экспоненциальные, логнормальное, гамма-распределение или им подобные. Из графиков видно, что чем выше количество строк в репозитории, тем более разреженными становятся данные, т. е. репозитории с большим количеством строк кода встречаются реже. Что согласуется с данными, полученными нами ранее.
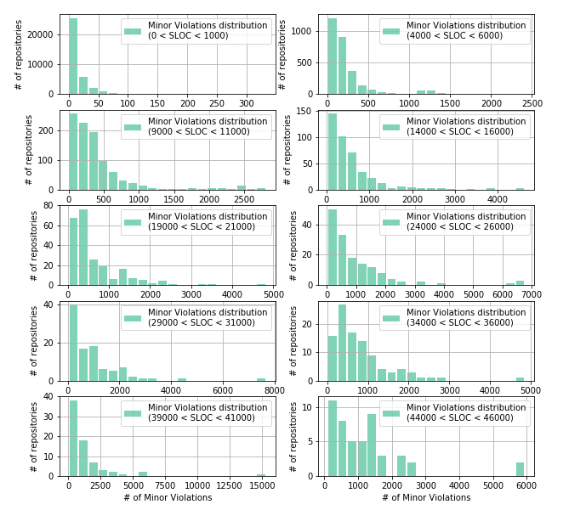
Аналогичным образом исследуем изменение структуры распределения строк кода по мере увеличения количества Minor Violations:
f, ax = plt.subplots(nrows=5, ncols=2)
f.set_figwidth(10)
f.set_figheight(10)
for i in range(10):
low_lim = 500 * i - 100
up_lim = 500 * i + 100
_df_Java = df_Java[(df_Java['Minor Violations'] > low_lim) & (df_Java['Minor Violations'] < up_lim)]
ax[i//2][i%2].hist(_df_Java['Lines Of Code'],
color='#00ab6c', bins=20 if i < 6 else 20, alpha=0.5, rwidth=0.85,
label='SLOC distribution\n({} < Minor Violations < {})'.format(0 if low_lim < 0 else low_lim, up_lim))
ax[i//2][i%2].grid(True)
ax[i//2][i%2].set_xlabel('# of SLOC')
ax[i//2][i%2].set_ylabel('# of repositories')
ax[i//2][i%2].legend(loc='best')
f.savefig('fig.png')
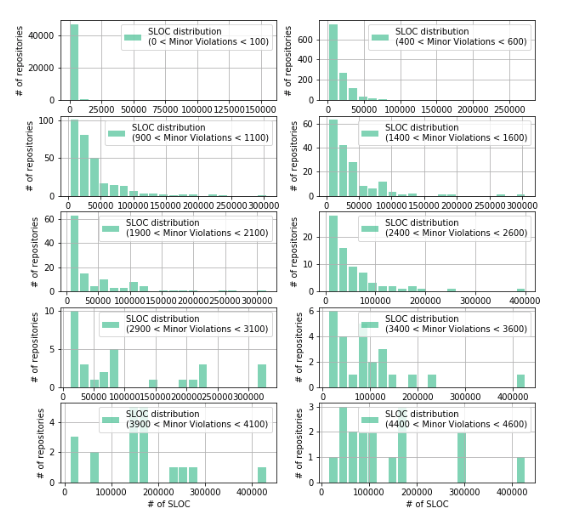
Из графиков видно, что распределение количества строк кода в репозитории отличается от нормального и очень похожи на то, что мы видели в случае распределения Minor Violation.
Чтобы успешно провести линеаризацию данных необходимо более точно определиться с типом распределения наших данных. Для этого воспользуемся двусторонним тестом Колмогорова-Смирнова. Далее приведу пример того, как это делается для Minor Violations в случае, когда 14000 < SLOC < 16000:
low_lim = 14000
up_lim = 16000
sample = df_Java[(df_Java['Lines Of Code'] > low_lim) & (df_Java['Lines Of Code'] < up_lim)]['Minor Violations']
res = []
for cdf in cdfs:
parameters = eval("stats."+cdf+".fit(sample)")
D, p = scipy.stats.kstest(sample, cdf, args=parameters)
if p > 0.05:
res.append({'stat':cdf, 'p':p, 'D':D})
res = sorted(res, key=lambda k: k['p'], reverse=True)
for i in res: print(i)
{'stat': 'johnsonsb', 'p': 0.6921277394819424, 'D': 0.03522119052695105}
{'stat': 'exponweib', 'p': 0.6661261317167249, 'D': 0.03630428488021764}
{'stat': 'invgauss', 'p': 0.6152804218017391, 'D': 0.037606319965134194}
{'stat': 'johnsonsu', 'p': 0.5647176954088229, 'D': 0.03896411311280057}
{'stat': 'gengamma', 'p': 0.5472142592213745, 'D': 0.039451029797039294}
{'stat': 'f', 'p': 0.4677860605493356, 'D': 0.04179264343902089}
Проделав такие действия для различных групп Minor Violations мы увидели, что наиболее часто с наибольшей суммой p-значения встречается именно Johnson’s SU-распределение. Поскольку Johnson’s SU-распределение в своей основе имеет экспоненциальный характер, то логичным способом линейризации наших данных является уже использованный тут приём логарифмирования.
fig, ax = plt.subplots(1)
sample = df_Java[df_Java['Minor Violations'] > 0]
ax.scatter(np.log(sample['Lines Of Code']), np.log(sample['Minor Violations']), c='#00ab6c', alpha=0.30, edgecolors='none', marker='.',
label='Linearization of $MV = f(SLOC)$')
ax.set_xlabel('log of SLOC')
ax.set_ylabel('log of Minor Violations')
ax.legend(loc='best')
ax.grid(True)
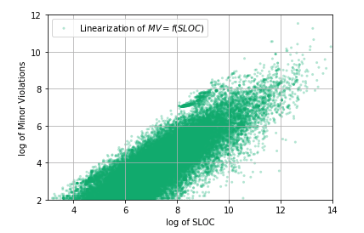
Вот так намного лучше! В логарифмических координатах хорошо вырисовывается линейная зависимость между количеством строк кода и Minor Violations: то есть между ними таки есть корреляция! А это значит, что можно строить модель качества кода, аргументом которой будет количество строк исходного кода репозитория/проекта/разработчика/компании и т. д.
Исследуем структуру распределения Minor Violations, но уже в логарифмических координатах. Это нам поможет понять распределение плотности количества уязвимостей от логарифма количества строк кода:
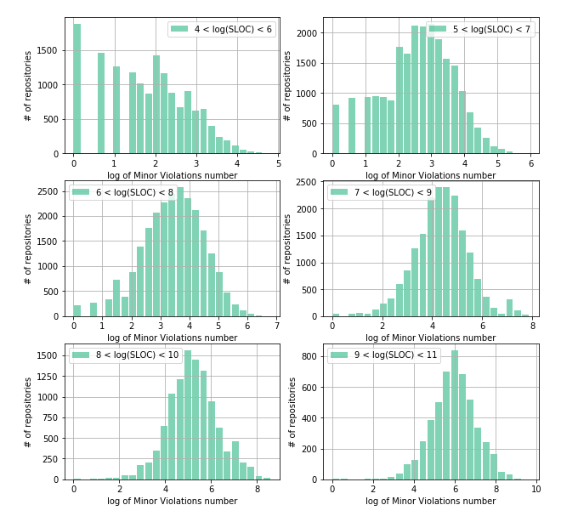
Как видно из полученных графиков распределений, структура плотности Minor Violations отличается по мере роста размера репозитория. Так, в случае малого количества строк кода (4 < log(SLOC)< 6) значительный объем репозиториев имеет количество Minor Violation равное 0 (~1900 репозиториев), а структура распределения отличается от симметричной куполообразной. Это связано с тем, что существует ограничение слева, т. е. ограничение на минимальное количество строк кода в репозитории (очевидно, что оно должно быть >=0) с одной стороны, а также большого количества репозиториев с малым количеством строк кода.
Структура распределения Minor Violation приобретает симметричную, правильную куполообразную форму только со значений количества строк кода в репозитории от ~1000 (exp (7) ≈ 1096), следовательно именно с этого момента структура распределения Minor Violation перестаёт «чувствовать» влияние ограничения слева.
Таким образом, мы определились с диапазоном изменения аргумента, а также провели feature engineering, получив линеаризацию данных в логарифмических координатах:
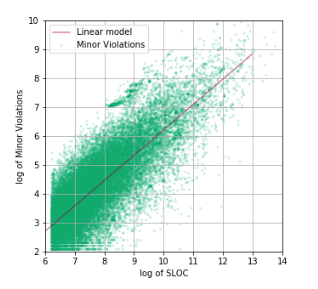
Воспользовавшись линейной регрессией, мы получили модель, описывающую корреляцию между количеством строк кода и количеством Minor Violation. Статистические характеристики полученной модели следующие:
R2 = 0.516, Fstats = 27510
А сама модель имеет вид:
log (MV) = -2.570 + 0.878 log (SLOC),
где MV — количество Minor Violation, SLOC — количество строк кода в репозитории.
Ответы на некоторые вопросы
Почему получено такое низкое значение R2? Потому что данные имеют достаточно большую дисперсию логарифма Minor Violation для выбранного значения логарифма SLOC. Это нам сразу же показалось недостатком, но потом, после размышлений стало понятно, что это не является недостатком, а наоборот — преимуществом, поскольку раскрывает всю полному данных в их многообразии. Все это является хорошей основой для дальнейшего улучшения модели, а также построения шкалы оценки качества исходного кода, которая позволит сравнивать между собой репозитории с различным количеством объёма кода.
Как можно интерпретировать смысл прямой, которую мы построили? Эта прямая может быть интерпретирована как некая граница между кодом более качественным по параметру Minor Violation и кодом менее качественным.
Где находится более качественный код? Более качественный код находится под прямой, изображенной на графике. Т.о., хоть и являясь некоторой основой для дальнейшего усовершенствования, наша модель уже может быть использована как простая линейка для оценки качества исходного кода, написанного на Java.
Заключение
Структура распределения Minor Violation в репозиториях с исходным кодом, написанным на Java, имеет нелинейную природу, а ее изучение открывает возможности разработки системы оценки и, соответственно, ранжирования качества кода. Разработанная в нашей компании система оценки качества кода позволяет разработчикам и компаниям отслеживать «здоровье» кода своего продукта, а также оперативно управлять его качеством.
Разработанная нами в этой работе простейшая модель качества исходного кода служит хорошим base line для дальнейшего ее улучшения.
P.S.
В ближайшее время мы планируем исследование качества исходного кода и для других языков программирования и метрик качества, а также ответ на самый сакраментальный вопрос всех программистов всех времён и народов: какой язык программирования лучше. Так что оставайтесь с нами!
Автор: Yevhen Krasnokutsky
