[Перевод] Разработка белков в облаке с помощью Python и Transcriptic или Как создать любой белок за $360
Что, если у вас идея для классного, полезного белка, и вы хотите получить его в реальности? Например, хотите создать вакцину против H. pylori (как словенская команда на iGEM 2008), создав гибридный белок, который сочетает фрагменты флагеллина E. coli, стимулирующие иммунный ответ с обычным флагеллином H. pylori?

Дизайн гибридного флагеллина вакцины против H. pylori, представленный командой Словении на iGEM 2008
Удивительно, но мы очень близки к тому, чтобы создать любой белок, какой хотим, не выходя из блокнота Jupyter, благодаря последним разработкам в геномике, синтетической биологии и совсем недавно — в облачных лабораториях.
В этой статье я покажу код Python от идеи белка до его экспрессии в бактериальной клетке, не прикасаясь к пипетке и не разговаривая ни с одним человеком. Общая стоимость составит всего несколько сотен долларов! Используя терминологию Виджая Панде из A16Z, это Биология 2.0.
Конкретнее, в статье питоновский код облачной лаборатории делает следующее:
- Синтез последовательность ДНК, которая кодирует любой белок, который я хочу.
- Клонирование этой синтетической ДНК в вектор, который может её экспрессировать.
- Трансформация бактерии с этим вектором и подтверждение, что происходит экспрессия.
Во-первых, общие настройки Python, которые нужны для любого блокнота Jupyter. Импортируем некоторые полезные модули Python и создаём некоторые служебные функции, в основном, для визуализации данных.
import re
import json
import logging
import requests
import itertools
import numpy as np
import seaborn as sns
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
from io import StringIO
from pprint import pprint
from Bio.Seq import Seq
from Bio.Alphabet import generic_dna
from IPython.display import display, Image, HTML, SVG
def uprint(astr): print(astr + "\n" + "-"*len(astr))
def show_html(astr): return display(HTML('{}'.format(astr)))
def show_svg(astr, w=1000, h=1000):
SVG_HEAD = ''''''
SVG_START = ''''))
def table_print(rows, header=True):
html = [""]
html_row = "".join(k for k in rows[0])
html.append(" {} ".join(row)
html.append(" {:}
")
show_html(''.join(html))
def clean_seq(dna):
dna = re.sub("\s","",dna)
assert all(nt in "ACGTN" for nt in dna)
return Seq(dna, generic_dna)
def clean_aas(aas):
aas = re.sub("\s","",aas)
assert all(aa in "ACDEFGHIKLMNPQRSTVWY*" for aa in aas)
return aas
def Images(images, header=None, width="100%"): # to match Image syntax
if type(width)==type(1): width = "{}px".format(width)
html = ["".format(width)]
if header is not None:
html += ["{} ".format(h) for h in header] + [" "]
for image in images:
html.append("
")
show_html(''.join(html))
def new_section(title, color="#66aa33", padding="120px"):
style = "text-align:center;background:{};padding:{} 10px {} 10px;".format(color,padding,padding)
style += "color:#ffffff;font-size:2.55em;line-height:1.2em;"
return HTML('{}'.format(style, title))
# Show or hide text
HTML("""
""")
# Plotting style
plt.rc("axes", titlesize=20, labelsize=15, linewidth=.25, edgecolor='#444444')
sns.set_context("notebook", font_scale=1.2, rc={})
%matplotlib inline
%config InlineBackend.figure_format = 'retina' # or 'svg'
Как у AWS или любого вычислительного облака, у облачной лаборатории есть оборудование для молекулярной биологии, а также роботы, которых она сдаёт в аренду через интернет. Вы можете выдавать инструкции своим роботам, нажав несколько кнопок в интерфейсе или написав код, который самостоятельно их программирует. Необязательно писать собственные протоколы, как я сделаю здесь, значительная часть молекулярной биологии — это стандартные рутинные задачи, поэтому обычно лучше полагаться на надёжный чужой протокол, который показал хорошее взаимодействие с роботами.
В последнее время появился целый ряд компаний с облачными лабораториями: Transcriptic, Autodesk Wet Lab Accelerator (бета, и построена на основе Transcriptic), Arcturus BioCloud (бета), Emerald Cloud Lab (бета), Synthego (ещё не запустилась). Есть даже компании, построенные поверх облачных лабораторий, такие как Desktop Genetics, которая специализируется на CRISPR. Начинают появляться научные статьи об использовании облачных лабораторий в реальной науке.
На момент написания статьи в открытом доступе только Transcriptic, поэтому будем использовать её. Насколько я понимаю, большая часть бизнеса Transcriptic построена на автоматизации общих протоколов, а написание собственных протоколов на Python (как я буду делать в этой статье) менее распространено.

«Рабочая ячейка» Transcriptic с холодильниками внизу и различным лабораторным оборудованием на стенде
Я выдам роботам Transcriptic инструкции на автопротоколе. Autoprotocol — это язык на основе JSON для написания протоколов для лабораторных роботов (и людей, как бы). Autoprotocol в основном сделан на этой библиотеке Python. Язык был первоначально создан и до сих пор поддерживается Transcriptic, но, как я понимаю, он полностью открыт. Есть хорошая документация.
Интересная идея, что на автопротоколе можно писать инструкции для людей в удалённых лабораториях — скажем, в Китае или Индии — и потенциально получить некоторые преимущества от использования и людей (их суждение), и роботов (отсутствие суждения). Здесь нужно упомянуть protocols.io, это попытка стандартизировать протоколы для повышения воспроизводимости, но для людей, а не роботов.
"instructions": [
{
"to": [
{
"well": "water/0",
"volume": "500.0:microliter"
}
],
"op": "provision",
"resource_id": "rs17gmh5wafm5p"
},
...
]
Пример фрагмента autoprotocol
Кроме импорта стандартных библиотек, мне понадобятся некоторые специфические молекулярно-биологические утилиты. Этот код в основном для автопротокола и Transcriptic.
В коде часто встречается концепция «мёртвого объёма» (dead volume). Это означает последнюю каплю жидкости, который роботы Transcriptic не могут взять пипеткой из пробирок (потому что они не видят!). Приходится тратить много времени, чтобы убедиться, что в колбах достаточный объём материала.
import autoprotocol
from autoprotocol import Unit
from autoprotocol.container import Container
from autoprotocol.protocol import Protocol
from autoprotocol.protocol import Ref # "Link a ref name (string) to a Container instance."
import requests
import logging
# Transcriptic authorization
org_name = 'hgbrian'
tsc_headers = {k:v for k,v in json.load(open("auth.json")).items() if k in ["X_User_Email","X_User_Token"]}
# Transcriptic-specific dead volumes
_dead_volume = [("96-pcr",3), ("96-flat",25), ("96-flat-uv",25), ("96-deep",15),
("384-pcr",2), ("384-flat",5), ("384-echo",15),
("micro-1.5",15), ("micro-2.0",15)]
dead_volume = {k:Unit(v,"microliter") for k,v in _dead_volume}
def init_inventory_well(well, headers=tsc_headers, org_name=org_name):
"""Initialize well (set volume etc) for Transcriptic"""
def _container_url(container_id):
return 'https://secure.transcriptic.com/{}/samples/{}.json'.format(org_name, container_id)
response = requests.get(_container_url(well.container.id), headers=headers)
response.raise_for_status()
container = response.json()
well_data = container['aliquots'][well.index]
well.name = "{}/{}".format(container["label"], well_data['name']) if well_data['name'] is not None else container["label"]
well.properties = well_data['properties']
well.volume = Unit(well_data['volume_ul'], 'microliter')
if 'ERROR' in well.properties:
raise ValueError("Well {} has ERROR property: {}".format(well, well.properties["ERROR"]))
if well.volume < Unit(20, "microliter"):
logging.warn("Low volume for well {} : {}".format(well.name, well.volume))
return True
def touchdown(fromC, toC, durations, stepsize=2, meltC=98, extC=72):
"""Touchdown PCR protocol generator"""
assert 0 < stepsize < toC < fromC
def td(temp, dur): return {"temperature":"{:2g}:celsius".format(temp), "duration":"{:d}:second".format(dur)}
return [{"cycles": 1, "steps": [td(meltC, durations[0]), td(C, durations[1]), td(extC, durations[2])]}
for C in np.arange(fromC, toC-stepsize, -stepsize)]
def convert_ug_to_pmol(ug_dsDNA, num_nts):
"""Convert ug dsDNA to pmol"""
return float(ug_dsDNA)/num_nts * (1e6 / 660.0)
def expid(val):
"""Generate a unique ID per experiment"""
return "{}_{}".format(experiment_name, val)
def µl(microliters):
"""Unicode function name for creating microliter volumes"""
return Unit(microliters,"microliter")
Несмотря на связь с современной синтетической биологией, синтез ДНК — довольно старая технология. Мы в течение десятилетий умели делать оликонуклеотиды (то есть последовательности ДНК до 200 оснований). Однако это всегда было дорого, и химия никогда не допускала длинных последовательностей ДНК. В последнее время стало возможным по разумной цене синтезировать целые гены (до тысяч оснований). Это достижение действительно открывает эпоху «синтетической биологии».
Компания Synthetic Genomics Крейга Вентера продвинула синтетическую биологию дальше всего, синтезировав целый организм — более миллиона оснований в длину. По мере увеличения длины ДНК проблемой становится уже не синтез, а сборка (т. е. сшивание вместе синтезированных последовательностей ДНК). При каждой сборке вы можете увеличить длину ДНК в два раза (или больше), поэтому после десятка или около того итераций получается довольно длинная молекула! Различие между синтезом и сборкой довольно скоро должно стать понятным конечному пользователю.
Цена синтеза ДНК падает довольно быстро, с более $0,30 за основание два года назад до около $0,10 сегодня, но она развивается больше как бактерии, чем процессоры. Напротив, цены на секвенирование ДНК падают быстрее, чем закон Мура. Цель $0,02 за основание намечена как точка перегиба, где вы можете заменить много трудоёмких манипуляций с ДНК простым синтезом. Например, при такой цене вы можете синтезировать целую плазмиду 3kb за $60 и пропустить кучу молекулярной биологии. Надеюсь, мы достигнем этого через пару лет.
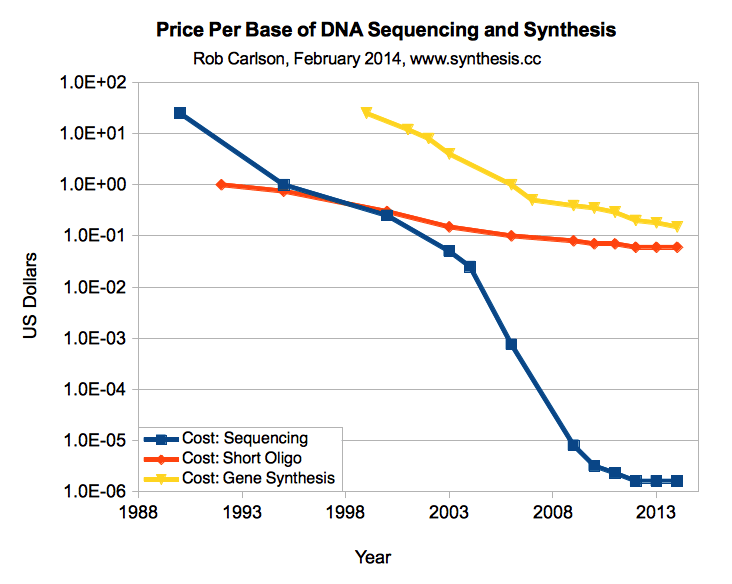
Цены на синтез ДНК по сравнению с ценами на секвенирование ДНК, цена за 1 основание (Carlson, 2014)
В области синтеза ДНК есть несколько крупных компаний: IDT является крупнейшим производителем оликонуклеотидов, а также может производить более длинные (до 2kb) «фрагменты генов» (gBlocks). Gen9, Twist и DNA 2.0 обычно специализируются на более длинных последовательностях ДНК — это компании по синтезу генов. Есть также некоторые интересные новые компании, такие как Cambrian Genomics и Genesis DNA, которые работают над методами синтеза следующего поколения.
Другие компании, такие как Amyris, Zymergen и Ginkgo Bioworks, используют синтезированную этими компаниями ДНК для работы на уровне организма. Synthetic Genomics тоже делает это, но сама синтезирует ДНК.
Недавно Ginkgo заключила сделку с Twist на изготовление 100 миллионов оснований: самая крупная сделка, что я видел. Это доказывает, что мы живём в будущем, Twist даже рекламировала промокод в Twitter: когда вы покупаете 10 миллионов оснований ДНК (почти весь геном дрожжей!), вы получаете ещё 10 миллионов бесплатно.

Нишевое предложение Twist в твиттере
Зелёный флуоресцентный белок
В этом эксперименте синтезируем последовательность ДНК для простого, зелёного флуоресцентного белка (GFP). Протеин GFP впервые был найден в медузе, которая флуоресцирует под ультрафиолетовым светом. Это чрезвычайно полезный белок, потому что легко обнаружить его экспрессию, просто измеряя флуоресценцию. Существуют варианты GFP, которые производят жёлтый, красный, оранжевый и другие цвета.
Интересно посмотреть, как различные мутации влияют на цвет белка, и это потенциально интересная проблема машинного обучения. Совсем недавно для этого пришлось бы потратить немало времени в лаборатории, но сейчас я вам покажу, что это (почти) так же просто, как редактирование текстового файла!
Технически, мой GFP является суперфолдер-вариантом (sfGFP) с некоторыми мутациями для улучшения качеств.
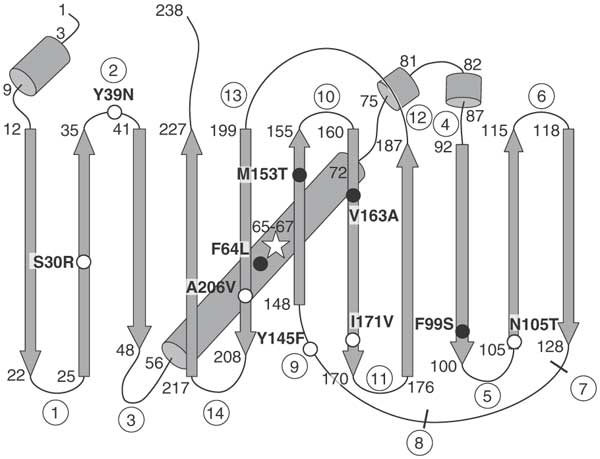
В суперфолдер-GFP (sfGFP) некоторые мутации придают ему определённые полезные свойства
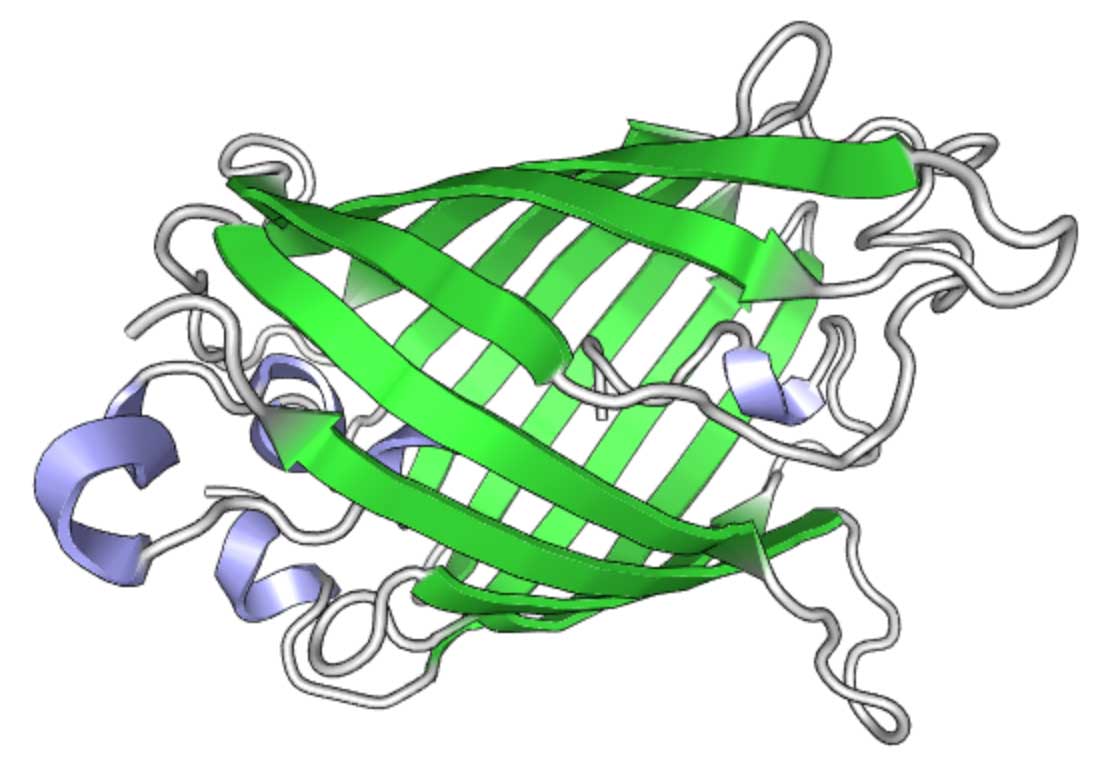
Структура GFP (визуализируется с помощью PV)
Синтез GFP в Twist
Мне посчастливилось попасть в альфа-программу тестирования Twist, поэтому я использовал их сервис для синтеза ДНК (они любезно разместили мой крошечный заказ — спасибо, Twist!). Это новая компания в нашей области, с новым упрощённым процессом синтеза. Цены у них в районе $0,10 за основание или ниже, но они всё ещё в бета-версии, а альфа-программа, в которой я принимал участие, закрылась. Twist поднял около $150 млн, так что их технология вызывает живой энтузиазм.
Я отправил свою последовательность ДНК в Twist в виде электронной таблицы Excel (пока нет API, но я предполагаю, что скоро будет), а они отправили синтезированную ДНК прямо на мой ящик в лаборатории Transcriptic (я также использовал для синтеза IDT, но они не отправили ДНК прямо в Transcriptic, что немного портит удовольствие).
Очевидно, этот процесс ещё не стал типичным случаем использования и требует некоторой поддержки, но он сработал, так что весь конвейер остаётся виртуальным. Без этого мне, вероятно, понадобился бы доступ в лабораторию — многие компании не будут отправлять ДНК или реагенты на домашний адрес.
GFP безвреден, поэтому подсвечивается любой вид
Плазмидный вектор
Чтобы экспрессировать этот белок в бактериях, гену нужно где-то жить, иначе синтетическая ДНК, кодирующая ген, просто мгновенно деградирует. Как правило, в молекулярной биологии мы используем плазмиду, кусочек круглой ДНК, который живёт вне бактериального генома и экспрессирует белки. Плазмиды — удобный способ для бактерий делиться полезными автономными функциональными модулями, такими как устойчивость к антибиотикам. В клетке могут быть сотни плазмид.
Широко используемая терминология заключается в том, что плазмида является вектором, а синтетическая ДНК — инсерцией (вставкой). Итак, здесь мы пытаемся клонировать инсерцию в вектор, а затем трансформировать бактерии с помощью вектора.
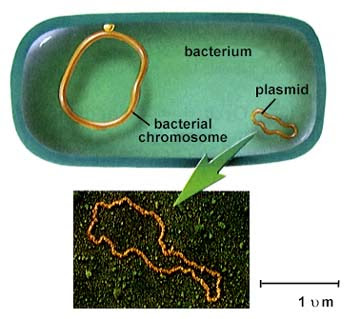
Бактериальный геном и плазмида (не в масштабе!) (Википедия)
pUC19
Я выбрал довольно стандартную плазмиду в серии pUC19. Эта плазмида очень часто используется, и поскольку она доступна как часть стандартного инвентаря Transcriptic, нам не нужно ничего им отправлять.
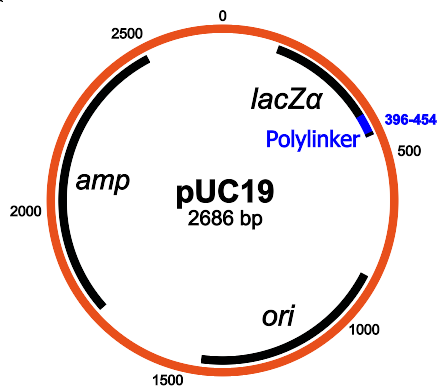
Структура pUC19: основными компонентами являются ген устойчивости к ампициллину, lacZα, MCS/полилинкер и происхождение репликации (Википедия)
У pUC19 есть приятная функция: поскольку он содержит ген lacZα, его можно использовать на сине-белом экране и посмотреть, в каких колониях успешно прошла инсерция. Нужны два химиката: IPTG и X-gal, и схема работает следующим образом:
- IPTG индуцирует экспрессию lacZα.
- Если lacZα деактивирован через ДНК, вставленную в место множественного клонирования (MCS/полилинкер) в lacZα, то плазмида не может осуществлять гидролиз X-gal, и эти колонии будут белыми вместо синих.
- Поэтому успешная инсерция производит белые колонии, а неудачная инсерция производит синие колонии.
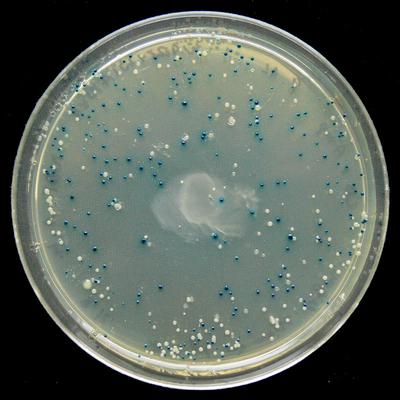
Сине-белый экран показывает, где была деактивирована экспрессия lacZα (Википедия)
Документация по openwetware говорит:
DH5α E. coli не требует IPTG, чтобы вызвать экспрессию от промотора lac, даже если в штамме экспрессируется репрессор Lac. Число копий большинства плазмид превышает число репрессоров в клетках. Если вам нужен максимальный уровень экспрессии, добавьте IPTG к конечной концентрации 1 mM.
Последовательность ДНК sfGFP
Легко получить последовательность ДНК для sfGFP, взяв последовательность белка и кодируя её кодонами, подходящими для организма-хозяина (здесь, E. coli). Это белок среднего размера с 236 аминокислотами, так что при 10 центах за основание синтез ДНК стоит около $70.
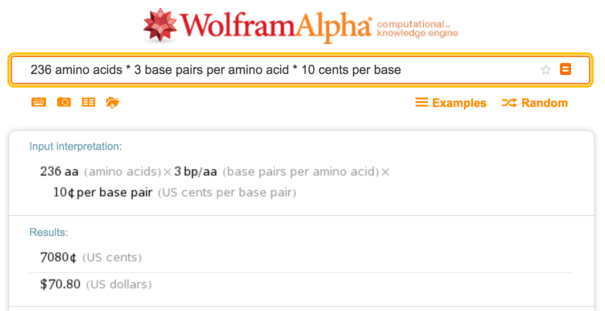
Wolfram Alpha, расчёт стоимости синтеза
Первые 12 оснований нашего sfGFP — это последовательность Шайна — Дельгарно, которую я добавил сам, что теоретически должно увеличить экспрессию (AGGAGGACAGCT, затем ATG (старт-кодон) запускает белок). Согласно вычислительному инструменту, разработанному Salis Lab (слайды лекции), мы можем ожидать от средней до высокой экспрессии нашего белка (скорость инициации перевода 10 000 «произвольных единиц»).
sfGFP_plus_SD = clean_seq("""
AGGAGGACAGCTATGTCGAAAGGAGAAGAACTGTTTACCGGTGTGGTTCCGATTCTGGTAGAACTGGA
TGGGGACGTGAACGGCCATAAATTTAGCGTCCGTGGTGAGGGTGAAGGGGATGCCACAAATGGCAAAC
TTACCCTTAAATTCATTTGCACTACCGGCAAGCTGCCGGTCCCTTGGCCGACCTTGGTCACCACACTG
ACGTACGGGGTTCAGTGTTTTTCGCGTTATCCAGATCACATGAAACGCCATGACTTCTTCAAAAGCGC
CATGCCCGAGGGCTATGTGCAGGAACGTACGATTAGCTTTAAAGATGACGGGACCTACAAAACCCGGG
CAGAAGTGAAATTCGAGGGTGATACCCTGGTTAATCGCATTGAACTGAAGGGTATTGATTTCAAGGAA
GATGGTAACATTCTCGGTCACAAATTAGAATACAACTTTAACAGTCATAACGTTTATATCACCGCCGA
CAAACAGAAAAACGGTATCAAGGCGAATTTCAAAATCCGGCACAACGTGGAGGACGGGAGTGTACAAC
TGGCCGACCATTACCAGCAGAACACACCGATCGGCGACGGCCCGGTGCTGCTCCCGGATAATCACTAT
TTAAGCACCCAGTCAGTGCTGAGCAAAGATCCGAACGAAAAACGTGACCATATGGTGCTGCTGGAGTT
CGTGACCGCCGCGGGCATTACCCATGGAATGGATGAACTGTATAAA""")
print("Read in sfGFP plus Shine-Dalgarno: {} bases long".format(len(sfGFP_plus_SD)))
sfGFP_aas = clean_aas("""MSKGEELFTGVVPILVELDGDVNGHKFSVRGEGEGDATNGKLTLKFICTTGKLPVPWPTLVTTLTYG
VQCFSRYPDHMKRHDFFKSAMPEGYVQERTISFKDDGTYKTRAEVKFEGDTLVNRIELKGIDFKEDGNILGHKLEYNFNSHNVYITADKQKN
GIKANFKIRHNVEDGSVQLADHYQQNTPIGDGPVLLPDNHYLSTQSVLSKDPNEKRDHMVLLEFVTAAGITHGMDELYK""")
assert sfGFP_plus_SD[12:].translate() == sfGFP_aas
print("Translation matches protein with accession 532528641")Read in sfGFP plus Shine-Dalgarno: 726 bases long Translation matches protein with accession 532528641
Последовательность ДНК pUC19
Сначала я проверяю, что у последовательности pUC19, которую я загрузил из NEB, правильная длина и она включает в себя ожидаемый полилинкер.
pUC19_fasta = !cat puc19fsa.txt
pUC19_fwd = clean_seq(''.join(pUC19_fasta[1:]))
pUC19_rev = pUC19_fwd.reverse_complement()
assert all(nt in "ACGT" for nt in pUC19_fwd)
assert len(pUC19_fwd) == 2686
pUC19_MCS = clean_seq("GAATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTT")
print("Read in pUC19: {} bases long".format(len(pUC19_fwd)))
assert pUC19_MCS in pUC19_fwd
print("Found MCS/polylinker")Read in pUC19: 2686 bases long Found MCS/polylinker
Делаем некоторые основные QC, чтобы убедиться, что EcoRI и BamHI присутствуют в pUC19 только один раз (следующие ограничительные ферменты имеются в инвентаре Transcriptic по умолчанию: PstI, PvuII, EcoRI, BamHI, BbsI, BsmBI).
REs = {"EcoRI":"GAATTC", "BamHI":"GGATTC"}
for rename, res in REs.items():
assert (pUC19_fwd.find(res) == pUC19_fwd.rfind(res) and
pUC19_rev.find(res) == pUC19_rev.rfind(res))
assert (pUC19_fwd.find(res) == -1 or pUC19_rev.find(res) == -1 or
pUC19_fwd.find(res) == len(pUC19_fwd) - pUC19_rev.find(res) - len(res))
print("Asserted restriction enzyme sites present only once: {}".format(REs.keys()))
Теперь смотрим на последовательность lacZα и проверяем, что нет ничего неожиданного. Например, она должна начинаться с Met и заканчиваться стоп-кодоном. Также легко подтвердить, что это полный 324bp lacZα ORF, загрузив последовательность pUC19 в бесплатный инструмент просмотра snapgene.
lacZ = pUC19_rev[2217:2541]
print("lacZα sequence:\t{}".format(lacZ))
print("r_MCS sequence:\t{}".format(pUC19_MCS.reverse_complement()))
lacZ_p = lacZ.translate()
assert lacZ_p[0] == "M" and not "*" in lacZ_p[:-1] and lacZ_p[-1] == "*"
assert pUC19_MCS.reverse_complement() in lacZ
assert pUC19_MCS.reverse_complement() == pUC19_rev[2234:2291]
print("Found MCS once in lacZ sequence")lacZ sequence: ATGACCATGATTACGCCAAGCTTGCATGCCTGCAGGTCGACTCTAGAGGATCCCCGGGTACCGAGCTCGAATTCACTGGCCGTCGTTTTACAACGTCGTGACTGGGAAAACCCTGGCGTTACCCAACTTAATCGCCTTGCAGCACATCCCCCTTTCGCCAGCTGGCGTAATAGCGAAGAGGCCCGCACCGATCGCCCTTCCCAACAGTTGCGCAGCCTGAATGGCGAATGGCGCCTGATGCGGTATTTTCTCCTTACGCATCTGTGCGGTATTTCACACCGCATATGGTGCACTCTCAGTACAATCTGCTCTGATGCCGCATAG r_MCS sequence: AAGCTTGCATGCCTGCAGGTCGACTCTAGAGGATCCCCGGGTACCGAGCTCGAATTC Found MCS once in lacZ sequence
Сборка ДНК означает просто сшивание фрагментов. Обычно вы собираете несколько фрагментов ДНК в более длинный сегмент, а затем клонируете его в плазмиду или геном. В этом эксперименте я хочу клонировать один сегмент ДНК в плазмиду pUC19 ниже промотора lac для экспрессии в E. coli.
Существует множество способов клонирования (например, NEB, openwetware, addgene). Здесь я буду использовать сборку методом Гибсона (разработанную Даниэлем Гибсоном в Synthetic Genomics в 2009 году), которая не обязательно является самым дешёвым методом, зато простая и гибкая. Нужно только поместить ДНК, которую вы хотите собрать (с соответствующими перекрытиями) в пробирку со смесью Gibson Assembly Master Mix, и она собирается сама!
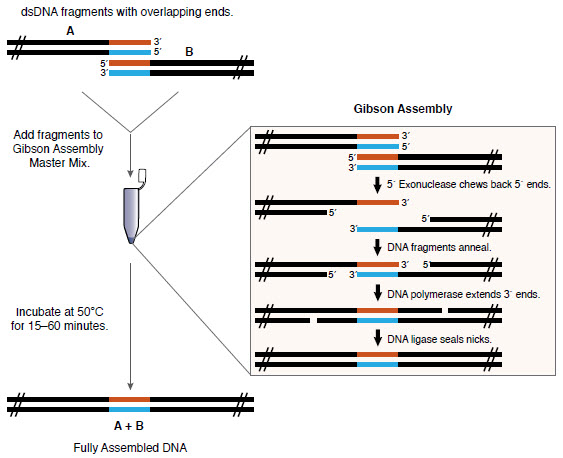
Обзор сборки Гибсона (NEB)
Исходный материал
Начинаем со 100 нг синтетической ДНК в 10 мкл жидкости. Это равняется 0,21 пикомолей ДНК или концентрации 10 нг/мкл.
pmol_sfgfp = convert_ug_to_pmol(0.1, len(sfGFP_plus_SD))
print("Insert: 100ng of DNA of length {:4d} equals {:.2f} pmol".format(len(sfGFP_plus_SD), pmol_sfgfp))Insert: 100ng of DNA of length 726 equals 0.21 pmol
Согласно протоколу сборки NEB, это достаточно исходного материала:
NEB рекомендует в общей сложности 0,02–0,5 пикомолей фрагментов ДНК, когда в вектор собирается 1 или 2 фрагмента, или 0,2–1,0 пикомолей фрагментов ДНК, когда собираются 4–6 фрагментов.0.02–0.5 пмолей * X мкл
* Оптимизированная эффективность клонирования составляет 50–100 нг векторов с 2–3-кратным избытком инсерций. Используйте в 5 раз больше инсерций, если размер меньше 200 bps. Общий объём нефильтрованных фрагментов PCR в реакции сборки Гибсона не должен превышать 20%.
NEBuilder для сборки Гибсона
NEBuilder от компании Biolab — это действительно отличный инструмент для создания протокола сборки Гибсона. Он даже генерирует вам всеобъемлющий четырёхстраничный PDF со всей информацией. С помощью этого инструмента разрабатываем протокол для вырезания pUC19 с EcoRI, а затем используем PCR [ПЦР, полимеразная цепная реакция позволяет добиться значительного увеличения малых концентраций определённых фрагментов ДНК в биологическом материале — прим. пер.] для добавления фрагментов соответствующего размера в инсерцию.
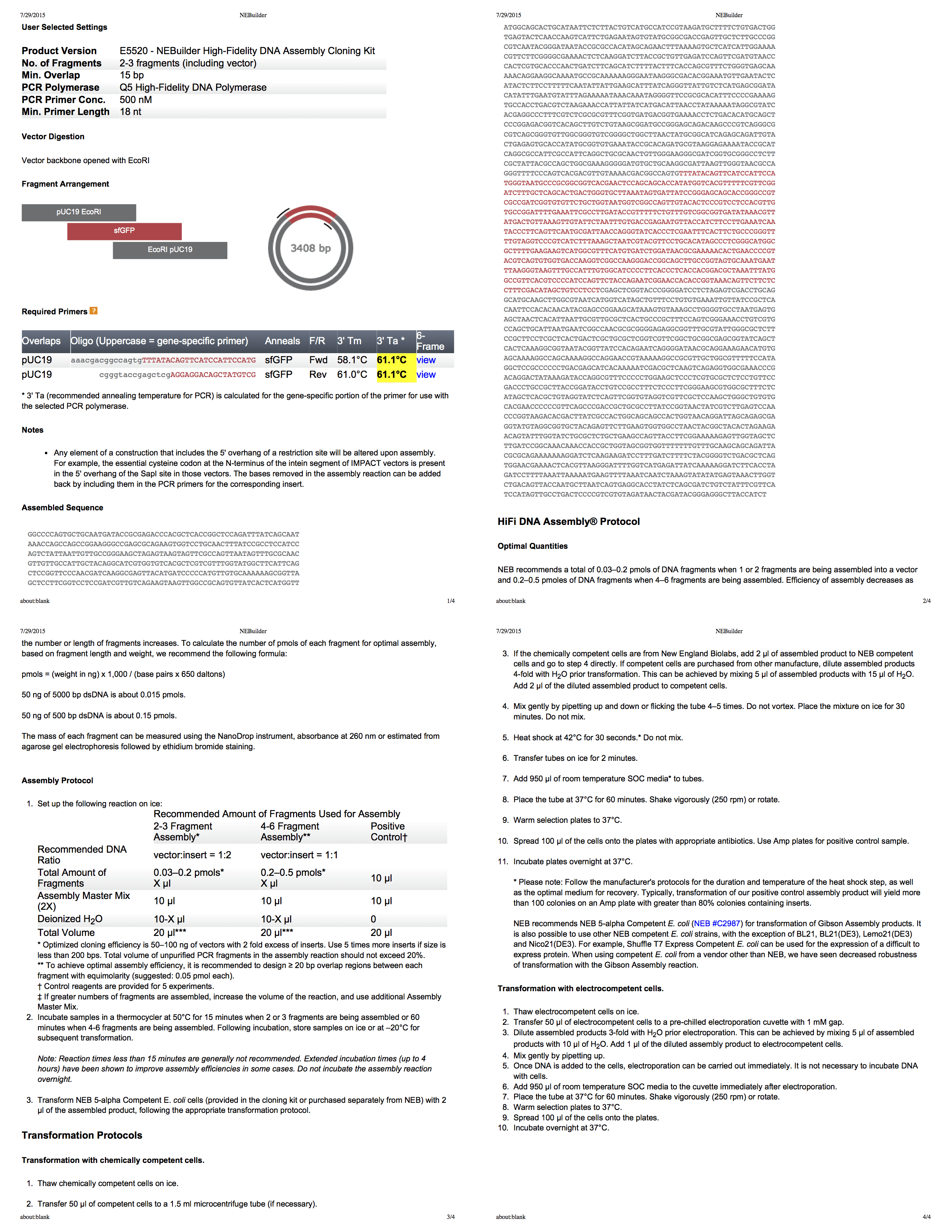
Эксперимент состоит из четырёх этапов:
- Полимеразная цепная реакция инсерции для добавления материала с фланкирующей последовательностью.
- Резка плазмиды для размещения инсерции.
- Сборка методом Гибсона инсерции и плазмиды.
- Трансформация бактерий с помощью собранной плазмиды.
Шаг 1. PCR инсерции
Сборка Гибсона зависит от последовательности ДНК, которую вы собираете, имея некоторую перекрывающуюся последовательность (см. выше протокол NEB с подробными инструкциями). Кроме простой амплификации, PCR также позволяет добавлять фланкирующую последовательность ДНК, просто включив дополнительную последовательность в праймеры (также можно клонировать, используя только OE-PCR).
Синтезируем праймеры в соответствии с протоколом NEB выше. Я попробовал протокол Quickstart на сайте Transcriptic, но есть ещё команда автопротокола. Transcriptic сама не производит синтез олигонуклеотидов, поэтому после 1–2 дней ожидания эти праймеры волшебным образом появляются в моём инвентаре (обратите внимание, что ген-специфическая часть праймеров ниже указана в верхнем регистре, но это просто косметические вещи).
insert_primers = ["aaacgacggccagtgTTTATACAGTTCATCCATTCCATG", "cgggtaccgagctcgAGGAGGACAGCTATGTCG"]Анализ праймеров
Можно проанализировать свойства этих праймеров с помощью IDT OligoAnalyzer. при отладке эксперимента PCR полезно знать температуры плавления и вероятность побочного эффекта primer dimer, хотя протокол NEB почти наверняка выберет праймеры с хорошими свойствами.
Gene-specific portion of flank (uppercase) Melt temperature: 51C, 53.5C Full sequence Melt temperature: 64.5C, 68.5C Hairpin: -.4dG, -5dG Self-dimer: -9dG, -16dG Heterodimer: -6dG
Я прошёл через много итераций PCR, прежде чем получить удовлетворительные результаты, включая эксперименты с несколькими различными марками смесей PCR. Поскольку каждая из этих итераций может занять несколько дней (в зависимости от длины очереди в лабораторию), стоит заранее потратить время на отладку: это экономит много времени в долгосрочной перспективе. По мере увеличения мощности облачной лаборатории эта проблема должна стать менее острой. Тем не менее, вряд ли ваш первый протокол будет успешным — здесь слишком много переменных.
""" PCR overlap extension of sfGFP according to NEB protocol.
v5: Use 3/10ths as much primer as the v4 protocol.
v6: more complex touchdown pcr procedure. The Q5 temperature was probably too hot
v7: more time at low temperature to allow gene-specific part to anneal
v8: correct dNTP concentration, real touchdown
"""
p = Protocol()
# ---------------------------------------------------
# Set up experiment
#
experiment_name = "sfgfp_pcroe_v8"
template_length = 740
_options = {'dilute_primers' : False, # if working stock has not been made
'dilute_template': False, # if working stock has not been made
'dilute_dNTP' : False, # if working stock has not been made
'run_gel' : True, # run a gel to see the plasmid size
'run_absorbance' : False, # check absorbance at 260/280/320
'run_sanger' : False} # sanger sequence the new sequence
options = {k for k,v in _options.items() if v is True}
# ---------------------------------------------------
# Inventory and provisioning
# https://developers.transcriptic.com/v1.0/docs/containers
#
# 'sfgfp2': 'ct17yx8h77tkme', # inventory; sfGFP tube #2, micro-1.5, cold_20
# 'sfgfp_puc19_primer1': 'ct17z9542mrcfv', # inventory; micro-2.0, cold_4
# 'sfgfp_puc19_primer2': 'ct17z9542m5ntb', # inventory; micro-2.0, cold_4
# 'sfgfp_idt_1ngul': 'ct184nnd3rbxfr', # inventory; micro-1.5, cold_4, (ERROR: no template)
#
inv = {
'Q5 Polymerase': 'rs16pcce8rdytv', # catalog; Q5 High-Fidelity DNA Polymerase
'Q5 Buffer': 'rs16pcce8rmke3', # catalog; Q5 Reaction Buffer
'dNTP Mixture': 'rs16pcb542c5rd', # catalog; dNTP Mixture (25mM?)
'water': 'rs17gmh5wafm5p', # catalog; Autoclaved MilliQ H2O
'sfgfp_pcroe_v5_puc19_primer1_10uM': 'ct186cj5cqzjmr', # inventory; micro-1.5, cold_4
'sfgfp_pcroe_v5_puc19_primer2_10uM': 'ct186cj5cq536x', # inventory; micro-1.5, cold_4
'sfgfp1': 'ct17yx8h759dk4', # inventory; sfGFP tube #1, micro-1.5, cold_20
}
# Existing inventory
template_tube = p.ref("sfgfp1", id=inv['sfgfp1'], cont_type="micro-1.5", storage="cold_4").well(0)
dilute_primer_tubes = [p.ref('sfgfp_pcroe_v5_puc19_primer1_10uM', id=inv['sfgfp_pcroe_v5_puc19_primer1_10uM'], cont_type="micro-1.5", storage="cold_4").well(0),
p.ref('sfgfp_pcroe_v5_puc19_primer2_10uM', id=inv['sfgfp_pcroe_v5_puc19_primer2_10uM'], cont_type="micro-1.5", storage="cold_4").well(0)]
# New inventory resulting from this experiment
dilute_template_tube = p.ref("sfgfp1_0.25ngul", cont_type="micro-1.5", storage="cold_4").well(0)
dNTP_10uM_tube = p.ref("dNTP_10uM", cont_type="micro-1.5", storage="cold_4").well(0)
sfgfp_pcroe_out_tube = p.ref(expid("amplified"), cont_type="micro-1.5", storage="cold_4").well(0)
# Temporary tubes for use, then discarded
mastermix_tube = p.ref("mastermix", cont_type="micro-1.5", storage="cold_4", discard=True).well(0)
water_tube = p.ref("water", cont_type="micro-1.5", storage="ambient", discard=True).well(0)
pcr_plate = p.ref("pcr_plate", cont_type="96-pcr", storage="cold_4", discard=True)
if 'run_absorbance' in options:
abs_plate = p.ref("abs_plate", cont_type="96-flat", storage="cold_4", discard=True)
# Initialize all existing inventory
all_inventory_wells = [template_tube] + dilute_primer_tubes
for well in all_inventory_wells:
init_inventory_well(well)
print(well.name, well.volume, well.properties)
# -----------------------------------------------------
# Provision water once, for general use
#
p.provision(inv["water"], water_tube, µl(500))
# -----------------------------------------------------
# Dilute primers 1/10 (100uM->10uM) and keep at 4C
#
if 'dilute_primers' in options:
for primer_num in (0,1):
p.transfer(water_tube, dilute_primer_tubes[primer_num], µl(90))
p.transfer(primer_tubes[primer_num], dilute_primer_tubes[primer_num], µl(10), mix_before=True, mix_vol=µl(50))
p.mix(dilute_primer_tubes[primer_num], volume=µl(50), repetitions=10)
# -----------------------------------------------------
# Dilute template 1/10 (10ng/ul->1ng/ul) and keep at 4C
# OR
# Dilute template 1/40 (10ng/ul->0.25ng/ul) and keep at 4C
#
if 'dilute_template' in options:
p.transfer(water_tube, dilute_template_tube, µl(195))
p.mix(dilute_template_tube, volume=µl(100), repetitions=10)
# Dilute dNTP to exactly 10uM
if 'dilute_DNTP' in options:
p.transfer(water_tube, dNTP_10uM_tube, µl(6))
p.provision(inv["dNTP Mixture"], dNTP_10uM_tube, µl(4))
# -----------------------------------------------------
# Q5 PCR protocol
# www.neb.com/protocols/2013/12/13/pcr-using-q5-high-fidelity-dna-polymerase-m0491
#
# 25ul reaction
# -------------
# Q5 reaction buffer 5 µl
# Q5 polymerase 0.25 µl
# 10mM dNTP 0.5 µl -- 1µl = 4x12.5mM
# 10uM primer 1 1.25 µl
# 10uM primer 2 1.25 µl
# 1pg-1ng Template 1 µl -- 0.5 or 1ng/ul concentration
# -------------------------------
# Sum 9.25 µl
#
#
# Mastermix tube will have 96ul of stuff, leaving space for 4x1ul aliquots of template
p.transfer(water_tube, mastermix_tube, µl(64))
p.provision(inv["Q5 Buffer"], mastermix_tube, µl(20))
p.provision(inv['Q5 Polymerase'], mastermix_tube, µl(1))
p.transfer(dNTP_10uM_tube, mastermix_tube, µl(1), mix_before=True, mix_vol=µl(2))
p.transfer(dilute_primer_tubes[0], mastermix_tube, µl(5), mix_before=True, mix_vol=µl(10))
p.transfer(dilute_primer_tubes[1], mastermix_tube, µl(5), mix_before=True, mix_vol=µl(10))
p.mix(mastermix_tube, volume="48:microliter", repetitions=10)
# Transfer mastermix to pcr_plate without template
p.transfer(mastermix_tube, pcr_plate.wells(["A1","B1","C1"]), µl(24))
p.transfer(mastermix_tube, pcr_plate.wells(["A2"]), µl(24)) # acknowledged dead volume problems
p.mix(pcr_plate.wells(["A1","B1","C1","A2"]), volume=µl(12), repetitions=10)
# Finally add template
p.transfer(template_tube, pcr_plate.wells(["A1","B1","C1"]), µl(1))
p.mix(pcr_plate.wells(["A1","B1","C1"]), volume=µl(12.5), repetitions=10)
# ---------------------------------------------------------
# Thermocycle with Q5 and hot start
# 61.1 annealing temperature is recommended by NEB protocol
# p.seal is enforced by transcriptic
#
extension_time = int(max(2, np.ceil(template_length * (11.0/1000))))
assert 0 < extension_time < 60, "extension time should be reasonable for PCR"
cycles = [{"cycles": 1, "steps": [{"temperature": "98:celsius", "duration": "30:second"}]}] + \
touchdown(70, 61, [8, 25, extension_time], stepsize=0.5) + \
[{"cycles": 16, "steps": [{"temperature": "98:celsius", "duration": "8:second"},
{"temperature": "61.1:celsius", "duration": "25:second"},
{"temperature": "72:celsius", "duration": "{:d}:second".format(extension_time)}]},
{"cycles": 1, "steps": [{"temperature": "72:celsius", "duration": "2:minute"}]}]
p.seal(pcr_plate)
p.thermocycle(pcr_plate, cycles, volume=µl(25))
# --------------------------------------------------------
# Run a gel to hopefully see a 740bp fragment
#
if 'run_gel' in options:
p.unseal(pcr_plate)
p.mix(pcr_plate.wells(["A1","B1","C1","A2"]), volume=µl(12.5), repetitions=10)
p.transfer(pcr_plate.wells(["A1","B1","C1","A2"]), pcr_plate.wells(["D1","E1","F1","D2"]),
[µl(2), µl(4), µl(8), µl(8)])
p.transfer(water_tube, pcr_plate.wells(["D1","E1","F1","D2"]),
[µl(18),µl(16),µl(12),µl(12)], mix_after=True, mix_vol=µl(10))
p.gel_separate(pcr_plate.wells(["D1","E1","F1","D2"]),
µl(20), "agarose(10,2%)", "ladder1", "10:minute", expid("gel"))
#---------------------------------------------------------
# Absorbance dilution series. Take 1ul out of the 25ul pcr plate wells
#
if 'run_absorbance' in options:
p.unseal(pcr_plate)
abs_wells = ["A1","B1","C1","A2","B2","C2","A3","B3","C3"]
p.transfer(water_tube, abs_plate.wells(abs_wells[0:6]), µl(10))
p.transfer(water_tube, abs_plate.wells(abs_wells[6:9]), µl(9))
p.transfer(pcr_plate.wells(["A1","B1","C1"]), abs_plate.wells(["A1","B1","C1"]), µl(1), mix_after=True, mix_vol=µl(5))
p.transfer(abs_plate.wells(["A1","B1","C1"]), abs_plate.wells(["A2","B2","C2"]), µl(1), mix_after=True, mix_vol=µl(5))
p.transfer(abs_plate.wells(["A2","B2","C2"]), abs_plate.wells(["A3","B3","C3"]), µl(1), mix_after=True, mix_vol=µl(5))
for wavelength in [260, 280, 320]:
p.absorbance(abs_plate, abs_plate.wells(abs_wells),
"{}:nanometer".format(wavelength), exp_id("abs_{}".format(wavelength)), flashes=25)
# -----------------------------------------------------------------------------
# Sanger sequencing: https://developers.transcriptic.com/docs/sanger-sequencing
# "Each reaction should have a total volume of 15 µl and we recommend the following composition of DNA and primer:
# PCR product (40 ng), primer (1 µl of a 10 µM stock)"
#
# By comparing to the gel ladder concentration (175ng/lane), it looks like 5ul of PCR product has approximately 30ng of DNA
#
if 'run_sanger' in options:
p.unseal(pcr_plate)
seq_wells = ["G1","G2"]
for primer_num, seq_well in [(0, seq_wells[0]),(1, seq_wells[1])]:
p.transfer(dilute_primer_tubes[primer_num], pcr_plate.wells([seq_well]),
µl(1), mix_before=True, mix_vol=µl(50))
p.transfer(pcr_plate.wells(["A1"]), pcr_plate.wells([seq_well]),
µl(5), mix_before=True, mix_vol=µl(10))
p.transfer(water_tube, pcr_plate.wells([seq_well]), µl(9))
p.mix(pcr_plate.wells(seq_wells), volume=µl(7.5), repetitions=10)
p.sangerseq(pcr_plate, pcr_plate.wells(seq_wells[0]).indices(), expid("seq1"))
p.sangerseq(pcr_plate, pcr_plate.wells(seq_wells[1]).indices(), expid("seq2"))
# -------------------------------------------------------------------------
# Then consolidate to one tube. Leave at least 3ul dead volume in each tube
#
remaining_volumes = [well.volume - dead_volume['96-pcr'] for well in pcr_plate.wells(["A1","B1","C1"])]
print("Consolidated volume", sum(remaining_volumes, µl(0)))
p.consolidate(pcr_plate.wells(["A1","B1","C1"]), sfgfp_pcroe_out_tube, remaining_volumes, allow_carryover=True)
uprint("\nProtocol 1. Amplify the insert (oligos previously synthesized)")
jprotocol = json.dumps(p.as_dict(), indent=2)
!echo '{jprotocol}' | transcriptic analyze
open("protocol_{}.json".format(experiment_name),'w').write(jprotocol)WARNING:root:Low volume for well sfGFP 1 /sfGFP 1 : 2.0:microliter
sfGFP 1 /sfGFP 1 2.0:microliter {'dilution': '0.25ng/ul'}
sfgfp_pcroe_v5_puc19_primer1_10uM 75.0:microliter {}
sfgfp_pcroe_v5_puc19_primer2_10uM 75.0:microliter {}
Consolidated volume 52.0:microliter
Protocol 1. Amplify the insert (oligos previously synthesized)
---------------------------------------------------------------
✓ Protocol analyzed
11 instructions
8 containers
Total Cost: $32.18
Workcell Time: $4.32
Reagents & Consumables: $27.86
Анализ результатов в геле
В геле можно оценить правильный размер продукта после увеличения концентрации (положение полоски в геле) и правильное количество (темнота полоски). В геле есть лестница, соответствующая различным длинам и количествам ДНК, которые можно использовать для сравнения.
На гелевой фотографии ниже полосы D1, E1, F1 содержат соответственно 2 мкл, 4 мкл и 8 мкл амплифицированного продукта. Я могу оценить количество ДНК в каждой полосе по сравнению с ДНК в лестнице (50 нг ДНК на полосу в лестнице). Думаю, что результаты выглядят очень чистыми.
Я попытался использовать для анализа изображения и оценки концентрации GelEval, и вполне успешно, хотя я не уверен, что это намного точнее, чем более наивный метод. Однако небольшие изменения в расположении и размере полос привели к большим изменениям в оценке количества ДНК. Моя лучшая оценка количества ДНК в моём амплифицированном продукте с использованием GelEval составляет 40 нг/мкл.
Если предположить, что мы ограничены количеством праймера в смеси, а не количеством dNTP или фермента, то, поскольку у меня есть 12,5 пмоль каждого праймера, это означает теоретический максимум 6 мкг ДНК 740bp в 25 мкл. Поскольку моя оценка общего количества ДНК с использованием GelEval составляет 40 нг x 25 мкл (1 мкг или 2 пмоля), эти результаты очень разумны и близки к тому, что я должен ожидать в идеальных условиях.
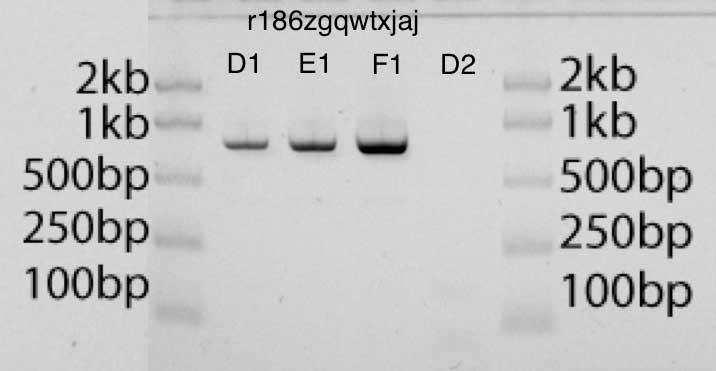
Гель-электрофорез EcoRI-среза pUC19, различные концентрации (D1, E1, F1), плюс контроль (D2)
Диагностика результатов PCR
Недавно Transcriptic начала предоставлять интересные и полезные диагностические данные от своих роботов. На момент написания статьи они недоступны для загрузки, поэтому пока у меня есть только изображение температур во время термоциклирования.
Данные выглядят хорошо, без неожиданных пиков или впадин. В общей сложности 35 циклов PCR, но некоторые из этих циклов проводятся при очень высокой температуре в рамках тачдауна PCR. В моих предыдущих попытках амплифицировать этот сегмент — которых было несколько! — возникали проблемы с гибридизацией праймеров, поэтому здесь PCR довольно много времени работает на высоких температурах, что должно повысить точность.

Термоциклическая диагностика для тачдауна PCR: температуры блока, образца и крышки в течение 35 циклов и 42 минут
Шаг 2. Резка плазмиды
Чтобы вставить нашу ДНК sfGFP в pUC19, сначала нужно разрезать плазмиду. Следуя протоколу NEB, я делаю это с помощью ограничительного фермента EcoRI. В стандартном инвентаре Transcriptic есть реагенты, которые мне нужны: это NEB EcoRI и 10x CutSmart буфер, а также плазмида NEB pUC19.
Для информации, ниже цены из их инвентаря. На самом деле плачу только часть цены, так как Transcriptic берёт оплату за фактически потреблённое количество:
Item ID Amount Concentration Price ------------ ------ ------------- ----------------- ------ CutSmart 10x B7204S 5 ml 10 X $19.00 EcoRI R3101L 50,000 units 20,000 units/ml $225.00 pUC19 N3041L 250 µg 1,000 µg/ml $268.00
Я максимально следовал протоколу NEB:
Перед использованием буфер должен быть полностью разморожен. Разбавьте запас 10X с dH2O до конечной концентрации 1X. Сначала добавьте воду, затем буфер, раствор ДНК и, наконец, фермент. Типичная реакция 50 мкл должна содержать 5 мкл 10x NEBuffer с остальной частью объёма из раствора ДНК, фермента и dH2O.Одна единица определяется как количество фермента, необходимое для освоения 1 мкг λ ДНК в течение 1 часа при 37°C в общем объёме реакции 50 мкл. В целом, мы рекомендуем 5–10 единиц фермента на мкг ДНК и 10–20 единиц геномной ДНК в 1-часовом процессе.
Для освоения 1 мкг субстрата рекомендуется реакционный объём 50 мкл.
"""Protocol for cutting pUC19 with EcoRI."""
p = Protocol()
experiment_name = "puc19_ecori_v3"
options = {}
inv = {
'water': "rs17gmh5wafm5p", # catalog; Autoclaved MilliQ H2O; ambient
"pUC19": "rs17tcqmncjfsh", # catalog; pUC19; cold_20
"EcoRI": "rs17ta8xftpdk6", # catalog; EcoRI-HF; cold_20
"CutSmart": "rs17ta93g3y85t", # catalog; CutSmart Buffer 10x; cold_20
"ecori_p10x": "ct187v4ea85k2h", # inventory; EcoRI diluted 10x
}
# Tubes and plates I use then discard
re_tube = p.ref("re_tube", cont_type="micro-1.5", storage="cold_4", discard=True).well(0)
water_tube = p.ref("water_tube", cont_type="micro-1.5", storage="cold_4", discard=True).well(0)
pcr_plate = p.ref("pcr_plate", cont_type="96-pcr", storage="cold_4", discard=True)
# The result of the experiment, a pUC19 cut by EcoRI, goes in this tube for storage
puc19_cut_tube = p.ref(expid("puc19_cut"), cont_type="micro-1.5", storage="cold_20").well(0)
# -------------------------------------------------------------
# Provisioning and diluting.
# Diluted EcoRI can be used more than once
#
p.provision(inv["water"], water_tube, µl(500))
if 'dilute_ecori' in options:
ecori_p10x_tube = p.ref("ecori_p10x", cont_type="micro-1.5", storage="cold_20").well(0)
p.transfer(water_tube, ecori_p10x_tube, µl(45))
p.provision(inv["EcoRI"], ecori_p10x_tube, µl(5))
else:
# All "inventory" (stuff I own at transcriptic) must be initialized
ecori_p10x_tube = p.ref("ecori_p10x", id=inv["ecori_p10x"], cont_type="micro-1.5", storage="cold_20").well(0)
init_inventory_well(ecori_p10x_tube)
# -------------------------------------------------------------
# Restriction enzyme cutting pUC19
#
# 50ul total reaction volume for cutting 1ug of DNA:
# 5ul CutSmart 10x
# 1ul pUC19 (1ug of DNA)
# 1ul EcoRI (or 10ul diluted EcoRI, 20 units, >10 units per ug DNA)
#
p.transfer(water_tube, re_tube, µl(117))
p.provision(inv["CutSmart"], re_tube, µl(15))
p.provision(inv["pUC19"], re_tube, µl(3))
p.mix(re_tube, volume=µl(60), repetitions=10)
assert re_tube.volume == µl(120) + dead_volume["micro-1.5"]
print("Volumes: re_tube:{} water_tube:{} EcoRI:{}".format(re_tube.volume, water_tube.volume, ecori_p10x_tube.volume))
p.distribute(re_tube, pcr_plate.wells(["A1","B1","A2"]), µl(40))
p.distribute(water_tube, pcr_plate.wells(["A2"]), µl(10))
p.distribute(ecori_p10x_tube, pcr_plate.wells(["A1","B1"]), µl(10))
assert all(well.volume == µl(50) for well in pcr_plate.wells(["A1","B1","A2"]))
p.mix(pcr_plate.wells(["A1","B1","A2"]), volume=µl(25), repetitions=10)
# Incubation to induce cut, then heat inactivation of EcoRI
p.seal(pc
