[Перевод] Откройте для себя весь потенциал побитовых операторов. Без математики

При изучении нового языка программирования в его документации мы обычно находим таблицу, где перечислены различные операторы, которые можно использовать с числами. Помимо хорошо знакомых нам +, -, * и /, в ней всегда присутствует раздел, который многие пропускают. Я имею ввиду раздел с побитовыми операторами: >, &, ^ и |.
И хотя поначалу они могут казаться туманными, не особо нужными и востребованными только теми, кто пишет на низкоуровневых языках, на деле эти операторы имеют немалое значение. Причём некоторые из наиболее эффективных способов их применения совсем не требуют математики.
Побитовые операторы позволяют управлять двоичным представлением данных, что на деле оказывается очень полезной возможностью. Поэтому предлагаю познакомиться с этим инструментом и научиться грамотно его использовать.
▍ Дайте мне биты
Фундаментально компьютеры понимают только 1 и 0. На уровне же восприятия человеком смысл этим 1 и 0 придаёт контекст. Тут можно провести аналогию со словами в английском языке, смысл которых изменяется в зависимости от контекста. К примеру, слово «present» в зависимости от ситуации может означать «подарок» или «настоящее время».
Одним из типичных примеров, в котором важен контекст двоичного представления, связан с кодированием текста. Если вам доводилось открывать файл с неверной кодировкой, то вы могли видеть в нём символы Null (�). Этот символ используется, когда компьютер не может декодировать определённые строки бит, составляющие текст документа. Переключение на корректную кодировку устранит эти символы, и вы увидите фактический текст файла. Как бы то ни было, для компьютера все файлы являются лишь двоичными представлениями, смысл которым придаёт их формат.
Один бит практически бесполезен для выполнения задач, поэтому обычно мы работаем с их группами. С помощью 2 битов можно представить 2^2 значений, или 4 разных числа, через следующие комбинации:
- 00
- 01
- 10
- 11
С помощью 3 битов можно представить уже 2^3 чисел, используя 8 разных комбинаций:
- 000
- 001
- 010
- 011
- 100
- 101
- 110
- 111
И так далее. В современном программировании мы обычно работаем со стандартизованными группами бит, которые имеют собственные особые имена:
- Полубайт — 4 бита. 2^4, или 16, значений.
- Байт — 8 бит. 2^8, или 256, значений.
- Слово — 4 байта в 32-битных системах, 8 байтов в 64-битных.
Большинство людей могли никогда не слышать эти термины, но наверняка знают о 32- и 64-битных архитектурах. Эта характеристика означает максимальный размер числа, который компьютер нативно поддерживает. При этом сами числа обрабатываются частями по 8 бит (1 байту) за раз.
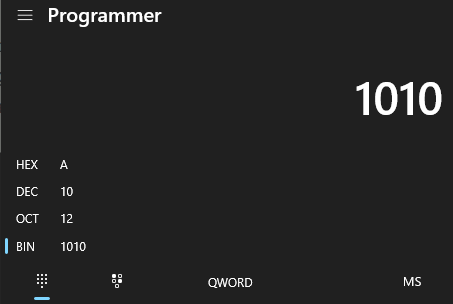
Отличный способ визуализировать общую группу бит — это открыть окно калькулятора Windows, кликнуть по иконке меню в верхнем левом углу и сменить режим со стандартного на режим программиста. Теперь вы будете видеть числа в их шестнадцатеричной (hex), десятичной, восьмеричной и двоичной формах. Над кнопкой битового сдвига >> можно ограничить максимальный/минимальный целочисленный размер, который может вместиться в байт, слово, двойное слово и так далее.
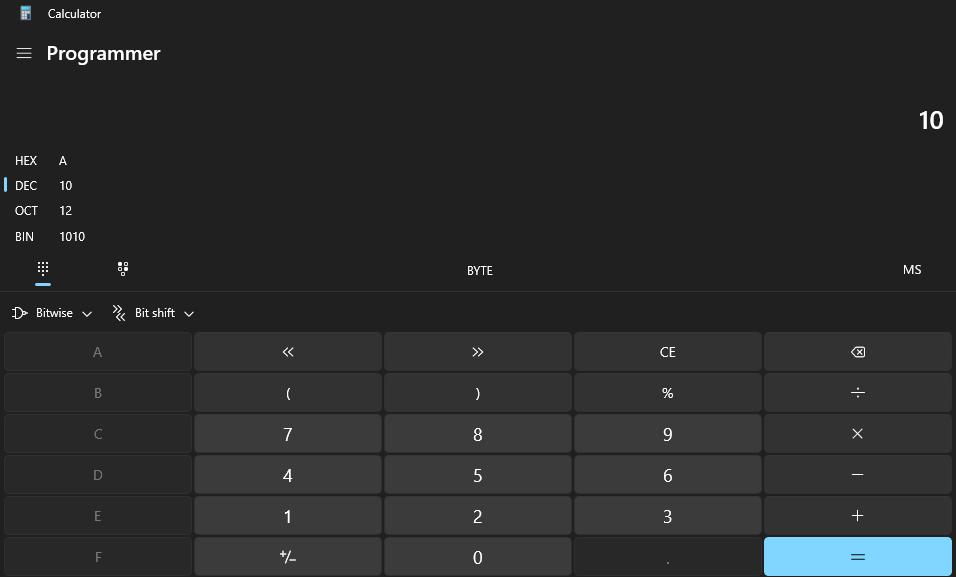
Вы даже можете переключиться в двоичный режим, кликнув по кнопке из точек, расположенной под BIN-форматом значения, чтобы получить возможность самостоятельно инвертировать биты. Это позволит вам выработать более интуитивное понимание представления 0 и 1, а также понять, как они переводятся в другие численные форматы.

Целые числа являются знаковыми, то есть поддерживают как положительный, так и отрицательный диапазоны
Для пользователей Linux отдельно скажу, что в этой системе аналогичную функциональность реализует приложение gnome-calculator.
В MacOS режим программиста в калькуляторе можно запустить путём ввода в стандартном режиме ⌘ и числа 3.
Кодирование чисел в двоичную форму обеспечивает уникальное преимущество перед их десятичным представлением. Такая кодировка позволяет использовать само двоичное представление в качестве своеобразной команды, в которой сегменты двоичного числа соответствуют определённой функциональности. Инвертируя различные единицы и нули, можно управлять программой эффективным и компактным способом при относительно небольших размерах чисел.
Разберём пример. Предположим, у нас есть байт данных (пробел здесь только для лучшей читаемости), 0010 0011, и мы хотим получить число, в котором установлены только 2 младших бита — 0000 0011. Как это можно сделать? С помощью логической операции И (AND), которая реализуется через символ амперсанда &.
Но прежде, чем мы сможем получить итоговый результат, нам нужно создать ещё одно двоичное число, которое называется маской. Маска — это двоичное число, в котором определённые биты установлены как 1 или 0, чтобы при использовании с побитовым оператором нужным образом маскировать элементы исходного двоичного числа. Вот пример:
0010 0011 (исходное значение)
& -> 0000 0011 (итоговое значение)
0000 0011 (маска)
Каковы будут десятичные представления этих 3 двоичных чисел? Это не важно. Нам важно лишь, чтобы определённые биты в итоговом двоичном числе оказались 1 или 0. Реализуется это таким образом — операция & сравнивает биты в каждом индексе двух чисел, создавая в результате нуль или единицу. Вот правила, по которым работает это сравнение:
- Если оба бита 0, то итоговый бит равен 0.
- Если оба бита 1, то итоговый равен 1.
- Если один бит 0, а второй 1, то итоговый будет равен 0.
Здесь правила #1 и #2 можно объединить, сказав: «Если бит в первом двоичном числе совпадает с битом во втором, в итоговом двоичном числе создаётся тот же бит». Используя эти свойства, мы получаем число 0000 0011 с нужным нам битовым паттерном.
Разберём ещё один пример. Предположим, у нас есть байт 1011 0011, и мы хотим получить другой байт — 1011 0000. Получается, нам нужно инвертировать два последних бита. На секунду обратитесь к перечисленным правилам, чтобы придумать подходящую маску самостоятельно. А теперь взгляните на пример ниже:
1011 0011
& -> 1011 0000
1011 0000
Если вы придумали правильную маску, то можете себя похвалить. Если же ошиблись, то ничего страшного, это новая тема, и на её усвоение может потребоваться некоторое время. Я хочу ещё раз подчеркнуть, что нам не нужно знать десятичные представления этих чисел, как и то, каким будет математический результат этих операций. Здесь мы просто создаём маски, которые позволят получить желаемые битовые паттерны.
▍ Побитовое ИЛИ (OR)
Мы разобрали использование побитового оператора & для маскирования битов исходного двоичного числа в состояние 0, но что, если нам нужно, наоборот, установить определённые биты на 1? В таком случае мы используем символ | для выполнения побитовой операции ИЛИ. Если, взяв предыдущий пример, мы захотим, чтобы результат был 1011 1111, то можем инвертировать два нуля в единицы с помощью ИЛИ. Для начала нужно создать маску с 1 в нужных нам позициях, после чего её применить.
1011 0011
| -> 1011 1111
1011 1111
Обратившись к правилам побитовой операции И, мы видим, что они аналогичны правилам операции ИЛИ за исключением последнего:
- Если оба бита 0, то итоговый бит равен 0.
- Если оба бита 1, то итоговый равен 1.
- Если один бит 0, а второй 1, то итоговый будет равен 1.
Понимая это, можно без проблем создать подходящую маску. Нужно будет лишь установить в ней 1 в тех позициях, в которых в исходном двоичном числе нужно инвертировать 0 в 1. Для тех же позиций исходного числа, которые должны остаться 1, в маске нужно также указать 1.
▍ Побитовое НЕ
Оператор НЕ обозначается тильдой ~. Он используется для инвертирования всех битов в противоположное состояние. Его можно назвать особенным, поскольку он не требует маски для своего применения. Этот оператор относится к унарным, что отличает его от таких операторов, как — или +, которые являются бинарными. В этом случае бинарность означает не то, что они работают только для двоичных чисел, а то, что для их функционирования необходимо два числа. Как видите, тут снова всплывает значимость контекста.
Принцип работы НЕ весьма прост. Если бит равен 1, то он становится 0, и наоборот. Обычно этот приём используется для создания маски, которая применяется совместно с оператором &. Предположим, что у нас есть число 0101 0010, и мы хотим инвертировать в нём первую 1, чтобы получить 0001 0010. Сначала мы создаём двоичное число, которое содержит 1 в интересующей нас позиции, 0100 0000. Затем мы это число инвертируем
0100 0000 ~ -> 1011 1111
Как видите, в результате инвертирования все 0 стали 1, а все 1 — 0. Теперь можно взять полученное число 1011 1111 и использовать его в качестве маски через оператор & для исходного числа 0101 0010.
0101 0010
& -> 0001 0010
1011 1111
Далее мы создаём нужное нам двоичное число, где первая 1 оказывается инвертирована в 0.
▍ Исключающее ИЛИ (XOR)
В операции исключающее ИЛИ используется символ ^. Эта операция применяется, когда необходимо инвертировать определённые биты. Например, если нам нужно инвертировать вторую 1 в числе 1001 0111, то мы построим маску, где укажем 1 в соответствующей позиции.
1001 0111
^ -> 1000 0111
0001 0000
Если взять полученное число 1000 0111 и выполнить для него XOR с прежней маской 0001 0000, то мы получим исходное число.
1000 0111
^ -> 1001 0111
0001 0000
В этом случае XOR сравнивает каждый бит и в случае их отличия возвращает 1, а в случае совпадения — 0. В большинстве контекстов это означает, что нужно создать маску, которая будет содержать 1 в тех позициях, которые требуется инвертировать. Остальные биты маски нужно оставить равными 0.
▍ Сдвиг
Осталось разобрать последние два оператора: битовый сдвиг влево, <<, и битовый сдвиг вправо, >>. Они выражаются с помощью символов «больше»/«меньше» или левыми/правыми угловыми кавычками,» ». Оператор битового сдвига влево (<<) вставляет дополнительные нули в позицию наименее значимых бит двоичного числа. О наименее значимых битах мы не говорили, но вы можете представить их следующим образом.
Возьмём, к примеру, десятичное число 123,456. Относительно него нам известно, что наименьшее число в нём — это 6, потому что оно находится в позиции исчисления единиц. При этом наибольшим числом является 1, поскольку занимает позицию исчисления сотен тысяч. В двоичных числах всё аналогично. Если читать полубайт 1110 справа налево, то 0 окажется наименее значимым, а последняя 1 слева — наиболее значимой. Если выполнить сдвиг влево на 4, то мы, по сути, прибавим 4 нуля к наименее значимой стороне числа. В результате получится следующее:
1110 << 4 -> 1110 0000
Как вы могли догадаться, если сдвиг двоичного числа влево прибавляет нули к наименее значимой стороне, то сдвиг вправо добавит их к наиболее значимой. Тогда при использовании того же исходного числа мы получим:
1110 >> 4 -> 0000
Представить операцию сдвига можно не только как прибавление нулей с одной или другой стороны, но и как то, что эти нули сдвигают исходное двоичное число влево или вправо. Отсюда и её название.
В этой статье мы никак не затрагиваем математические аспекты, но забавно то, что сдвиг влево числа на 1 равнозначен умножению числа на 2^1, то есть его удваиванию. Сдвиг влево на 2 будет равнозначен умножению числа на 2^2, то есть его учетверению. И так далее.
Сдвиг вправо ведёт к противоположному результату. При использовании тех же приведённых выше чисел он половинит число или делит его на 4. Если вам нужно поделить или умножить число на степень 2, то операция сдвига окажется для этого очень быстрым решением. При этом она является типичной оптимизацией, выполняемой внутренне во время компиляции программ. Хотя для наших целей мы рассматриваем этот оператор просто как прибавляющий 0 в начало или конец двоичного числа или как смещающий это число влево/вправо на указанное количество нулей.
▍ Какая от этого польза?
Помимо нескольких грамотных приёмов оптимизации, как ещё можно использовать эти операторы на практике? Чтобы ответить на этот вопрос, нам нужно познакомиться с ещё одним принципом — шестнадцатеричными числами.
Шестнадцатеричные числа представляют альтернативный способ выражения чисел в вычислительной технике. В отличие от двоичных, которые имеют основание 2, эти числа имеют основание 16. Это означает, что в них используется уже не две цифры — 0 и 1 –, а 16 символов, которые включают цифры от 0 до 9, а также буквы A, B, C, D, E и F, выражающие 10, 11, 12, 13, 14 и 15.
В вычислительной технике hex-числа важны тем, что позволяют более сжато выражать двоичные числа. Одно hex-значение может выразить четыре двоичных цифры (полубайт), то есть с помощью двух можно представить целый байт. Во многих языках программирования hex-числа обозначаются путём добавления приставки 0x, позволяющей отличать их от двоичных и десятичных значений. Получается, если вы захотите представить число 1234 в шестнадцатеричном виде, то его нужно будет записать как 0×1234.
Внимание. Не нужно путать десятичное число 1234 и шестнадцатеричное 0×1234. Первое — это десятичное значение 1,234, а второе — это десятичное значение 4,660.
Чтобы преобразовать двоичное число в шестнадцатеричное, нужно разбить его на группы полубайтов, начиная с правой стороны, и затем заменить каждый полубайт соответствующей hex-цифрой.
Например, двоичное число 1101 1010 можно разбить на 1101 и 1010. Преобразование каждой группы в шестнадцатеричное значение даст DA. Следовательно, двоичное представление 1101 1010 равнозначно шестнадцатеричному 0хDA. Если же у вас под рукой всё ещё запущен калькулятор в режиме программиста, то эти вычисления можно поручить ему. Просто введите двоичную форму числа, и он сообщит вам его hex-эквивалент.
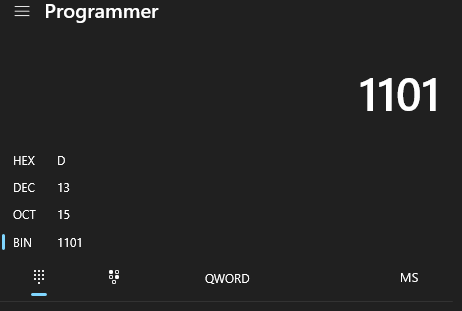

Шестнадцатеричные числа также используются в вычислительной технике для представления адресов памяти. Дело в том, что эти адреса обычно выражаются в виде 32- или 64-битных чисел, которые могут быть довольно длинными и сложными для чтения в двоичном виде. Представляя адреса памяти в hex-форме, мы делаем их более сжатыми и простыми для восприятия. Ниже показан пример DA в виде 32-битного двоичного числа:
0000 0000 0000 0000 0000 0000 1101 1010
vs
0000 00DA▍ Побитовые операторы в эмуляторах
Теперь, обладая всей этой информацией, мы можем разобрать типичный практический случай — интерпретатор Chip-8. Этот интерпретатор станет хорошим стартовым проектом для людей, только начинающих знакомство с эмуляцией. В нём используется всего 36 инструкций, каждая длиной 2 байта, или 16 бит. Поскольку работать с 16 битами в двоичной форме сложно, мы будем представлять их в шестнадцатеричном виде. Напомню, что каждое шестнадцатеричное значение имеет размер 4 бита. И это удобно, потому что минимальный сегмент инструкции Chip-8, с которым нам придётся работать, составляет 4 бита.

Игра Space Intercept, запущенная на Telmac 1800 через эмулятор Chip-8 (Джозеф Уэйсбекер, 1978 год)
Также нужно иметь ввиду, что инструкции отличаются своими компонентами. Справка по Chip-8 от Cowdog прекрасно поясняет действия каждой из них. Разберём простой случай с инструкциями, которые относятся к диапазону 0х1000. В качестве примера мы будем использовать эмулятор Crystal Chip-8. Напомню, что эти числа представлены в hex-виде.
case op & 0xF000
#nnn или addr - A 12-битное значение, младшие 12 бит инструкции.
#n или nibble - A 4-битное значение, младшие 4 бита инструкции.
#x – 4-битное значение, младшие 4 бита старшего байта инструкции.
#y – 4-битное значение, старшие 4 бита младшего байта инструкции.
#kk или byte – 8-битное значение, младшие 8 бит инструкции.
when 0x1000
#1nnn
#установить счётчик команд на nnn, представляющее 3 младших байта.
@pc = op & 0x0FFF;
Предполагая, что нам представлена инструкция 0x1ABC, сначала нужно определить её наиболее значимый байт. Это позволит понять, как его интерпретировать. Обратившись к документации Cowdog, мы видим, что инструкции, содержащие в качестве наиболее значимого байта 1, устанавливают счётчик команд на последние 12 бит инструкции. При определении инструкции нам нужно сохранить наиболее значимый бит и очистить остальные 12, которые нас не интересуют. Этот процесс должен быть вам знаком.
Можно написать оператор условия, который позволит нам создать несколько ветвлений на основе получаемой инструкции. Мы возьмём код операции 0x1ABC и выполним побитовую операцию & с маской 0xF000, чтобы получить наиболее значимый бит нашей инструкции 0x1000. Это гарантирует, что любая входящая инструкция, которая начинается с 0x1, всегда будет отправлена по верной ветви, будь это 0x1DDD, 0x1012 и так далее.
Теперь, когда мы организовали правильное перенаправление инструкции, нужно получить её младшие 12 бит и установить наш счётчик команд на это значение. Опять же, для этого можно использовать &. Выполнив & для нашего кода операции и маски 0x0FFF, мы получим число 0x0ABC. Затем можно добавить это число в наш счётчик команд.
Вас может несколько запутать процесс перевода шестнадцатеричных значений обратно в двоичные, как мы делали в предыдущих примерах. Для большей ясности я покажу, как это происходит в текущем примере. Здесь 0x1ABC переводится в 0001 1010 1011 1100, а 0xF000 переводится в 1111 0000 0000 0000.
Выполнив для этих чисел операцию &, мы получим:
0001 1010 1011 1100
& -> 0001 0000 0000 0000
1111 0000 0000 0000
Результатом стало значение 0001 0000 0000 0000, которое просто является кодом операции с наиболее значимым битом. Как вы могли догадаться, 0001 0000 0000 0000 — это 0x1000 в двоичном виде, почему оно и отправляется по ветви 0x1000 нашего оператора ветвления.
Та же логика касается и получения младших 12 бит нашей операции. В этом случае нас интересуют все числа, кроме первых 4 бит, поэтому их нужно убрать. На сей раз мы используем значение 0x0FFF, которое переводится в 0000 1111 1111 1111. Выполнив для него побитовое &, мы получим:
0001 1010 1011 1100
& -> 0000 1010 1011 1100
0000 1111 1111 1111
И это как раз то, что нам нужно. Последний вопрос, который у вас мог остаться: «Почему мы используем в hex-числе F, а не 1, как в двоичном?» Дело в том, что F в двоичном виде соответствует 1111. Поэтому, если нам нужно сохранить этот битовый паттерн в данном индексе нашего исходного hex-значения, то можно просто использовать в нём F.
Какой бы ни была комбинация 0 и 1 — при выполнении & она всегда будет сохранена. Поскольку мы хотели сохранить последние 12 бит нашего hex-значения, мы указали в нём три F. А так как для перехода по нужной ветви оператора ветвления нужно было сохранить только битовый паттерн наиболее значимых 4 бит, мы указали всего одну F в первой позиции hex-маски.
Закончим эту тему ещё одним примером, в котором используются операторы сдвига.
when 0x5000
#5xy0
#Пропустить следующую инструкцию, если Vx = Vy.
#Сравнивает регистр Vx с регистром Vy.
#Если они равны, инкрементирует счётчик команд на 2.
x = (op & 0x0F00) >> 8
y = (op & 0x00F0) >> 4
#индекс регистра
if @reg[x] == @reg[y]
@pc +=2
end
Предположим, что наша следующая инструкция — это 0x5120. Нам нужно создать маску, которая будет направлять нашу операцию по ветви 0x5000 оператора ветвления. Для её создания нужно сохранить наиболее значимую цифру (первую hex-цифру), установив все остальные на 0. Попробуйте самостоятельно разобраться, как это сделать.
Далее мы видим, что инструкции, относящиеся к диапазону 0x5000, дают нам значения x и y, которые можно использовать для обращения к регистрам в x и y. Следовательно, нам нужно каким-то образом получить из операции эти значения. Также, как в предыдущих примерах, можно поместить Fпо индексу интересующего нас hex-значения и 0 в остальных индексах. Для значения x это будет маска 0x0F00, а для значения y — — 0x00F0.
Мы узнали, что сдвиг вправо прибавляет 0 к наиболее значимой стороне двоичного числа. И хотя в большинстве случаев это верно, что должно происходить, когда ваше число имеет фиксированную длину? В Chip-8 минимальная двоичная инструкция соответствует 0000 0000 0000 0000, а максимальная — 1111 1111 1111 1111. В обоих случаях они ограничены 16 битами. Здесь мы не можем просто прибавить нули к наиболее значимой стороне, например так: 0000 1111 1111 1111 1111, поскольку тогда мы получим уже 20-битную инструкцию при том, что Chip-8 поддерживает лишь 16-битные. Придётся чем-то пожертвовать.
Работает это в данном случае так. Числа с наименее значимой стороны вытесняются, освобождая место для нулей с наиболее значимой стороны. Это означает, что число 1111 1111 1111 1111 при сдвиге вправо на 4 станет:
(1111 1111 1111 1111 >> 4) 0000 1111 1111 1111
Сегмент 1111 был вытеснен для освобождения места под 0000. Сколько раз нам нужно сдвинуть инструкцию вправо, чтобы получить x и y? Если взглянуть на шаблон инструкции для инструкций 0x5000 — 5xy0 — мы увидим, что x смещён от наименее значимой стороны на 8 бит. Поскольку один сдвиг перемещает целое число на 1 бит, то для перемещения x к наименее значимой стороне двоичного числа потребуется 8 таких сдвигов. А поскольку y находится всего в 4 битах от наименее значимой стороны инструкции, то для него потребуется лишь 4 сдвига. Таким образом, чтобы получить значения x и y, мы выполняем сдвиг на 8 и на 4 соответственно.
x = (op & 0x0F00) >> 8
y = (op & 0x00F0) >> 4
После получения значений x и y следующим действием будет сравнение нашего регистра в x с регистром в y на предмет их равенства. Если они равны, то мы инкрементируем счётчик команд.
#индекс регистра
if @reg[x] == @reg[y]
@pc +=2
end
Здесь я не буду разбирать все инструкции, поскольку это получится очень долго, но если взглянуть на некоторые инструкции для Chip-8, например, на расположенные в диапазоне 0x8000:
8xy1 - OR Vx, Vy
Set Vx = Vx OR Vy.
8xy3 - XOR Vx, Vy
Set Vx = Vx XOR Vy.
То вы увидите, что в итоге мы используем все побитовые функции, с которыми познакомились в первой части статьи. Надеюсь, этот материал позволил вам понять важность побитовых операторов в программировании, а также послужил практическим примером их конкретного использования.
Эмуляторы — это не единственный случай применения, поэтому я рекомендую поискать и другие. Но в следующий раз, когда вы будете запускать свой эмулятор с легально полученными или собственными образами ROM, помните, что за его работой стоят побитовые операторы.
Если вы хотите получше разобраться в принципах работы эмуляторов, то советую создать собственный интерпретатор Chip-8, поскольку это будет очень ценным опытом. В качестве же справочного материала советую обращаться к документации от Cowdog, которая лично в моём опыте с Chip-8 оказала бесценную помощь.
Telegram-канал с розыгрышами призов, новостями IT и постами о ретроиграх
