[Перевод] Неожиданная находка, которая освобождает 20 GB неиспользованного индексного пространства

Как освободить место без удаления индексов или данных
Раз в несколько месяцев мы получаем предупреждения от системы мониторинга базы данных о том, что свободное место скоро закончится. Обычно мы просто выделяем больше места и забываем об этом, однако в этот раз мы мы были на карантине и система была нагружена меньше, чем обычно. И тут мы подумали, что это хорошая возможность провести чистку.
Начнем с конца: в итоге нам удалось освободить более чем 70 GB не оптимизированного и неиспользуемого пространства без удаления индексов и данных.
Используя обычные приемы, такие как перестроение индексов и таблиц, мы очистили много пространства, но затем одна удивительная находка помогла нам освободить дополнительно примерно 20 GB неиспользуемых индексированных значений.
Диаграмма свободного места в одной из наших баз данных выглядела следующим образом:
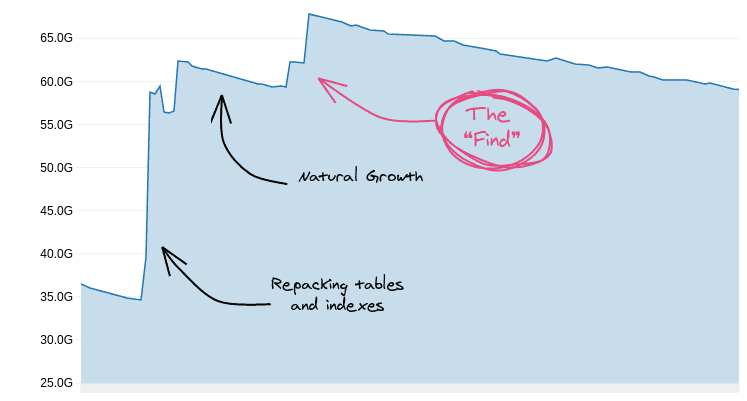 На графике показано увеличение количества свободного места с течением времени
На графике показано увеличение количества свободного места с течением времени
Обычные подозреваемые
Время от времени мы увеличиваем объемы хранилища, но перед тем, как швыряться деньгами, мы хотим убедиться в том, что уже имеющееся хранилище используется максимально эффективно. Давайте начнем с главных подозреваемых.
Неиспользуемые индексы
Неиспользуемые индексы — это палка о двух концах; вы создаете их с целью повышения производительности, но заканчивается всё тем, что они занимают место и замедляют операции вставки и обновления. Неиспользуемые индексы — это первое, что мы проверяем, когда нужно очистить место.
Для поиска неиспользуемых индексов можно использовать следующий запрос:
SELECT
relname,
indexrelname,
idx_scan,
idx_tup_read,
idx_tup_fetch,
pg_size_pretty(pg_relation_size(indexrelname::regclass)) as size
FROM
pg_stat_all_indexes
WHERE
schemaname = 'public'
AND indexrelname NOT LIKE 'pg_toast_%'
AND idx_scan = 0
AND idx_tup_read = 0
AND idx_tup_fetch = 0
ORDER BY
pg_relation_size(indexrelname::regclass) DESC;Этот запрос ищет индексы, которые не использовались для scan и fetch с момента последнего сброса статистики.
Некоторые индексы могут выглядеть как неиспользуемые, но на самом деле это не так:
В документации приведены примеры сценариев, когда подобная ситуация становится возможной. Например, если оптимизатор использует метаданные из индекса, но не сам индекс.
Индексы для обеспечения ограничений уникальности или первичного ключа в таблицах, которые давно не обновлялись. Индексы будут выглядеть как неиспользуемые, однако это не означает, что мы можем избавиться от них.
Для поиска неиспользуемых индексов, которые действительно можно удалить, обычно для принятия решения приходится анализировать весь список индексов один за другим и в итоге принять решение. Первые пару раз на это может потребоваться много времени, но как только вы избавитесь от большей части неиспользуемых индексов, станет легче.
Также хорошей идеей является периодический сброс счетчиков статистики — обычно после обработки списка кандидатов на удаление. В PostgreSQL есть несколько функций для сброса статистики на разных уровнях. Мы сбрасываем счетчики таблицы обычно, когда находим индекс, который, как нам кажется, не используется, или при создании новых индексов вместо старых:
-- Find table oid by name
SELECT oid FROM pg_class c WHERE relname = 'table_name';
-- Reset counts for all indexes of table
SELECT pg_stat_reset_single_table_counters(14662536);Проделываем мы это регулярно, поэтому в нашем случае не оказалось неиспользуемых индексов, которые стоило бы удалить.
Раздувание индекса и таблицы
Когда вы обновляете строки в таблице, PostgreSQL помечает кортеж как удаленный и добавляет обновленный кортеж в следующее доступное место. Это процесс приводит к так называемому «раздуванию» (bloat), из-за чего таблицы могут занимать больше места, чем им на самом деле требуется. Раздувание также затрагивает индексы, поэтому на этот момент стоит обратить внимание.
Оценка раздутости таблиц и индексов, по всей видимости, непростая задача. На наше счастье, какие-то хорошие люди на просторах интернета уже сделали за нас всю тяжелую работу и написали запросы для анализа таблиц и индексов. После запуска этих запросов вы ее обнаружите с высокой вероятностью, так что следующим шагом будет очистка места.
Устранение раздувания индексов
Для устранения раздувания индексы нужно перестроить. Есть несколько способов это сделать:
Пересоздать индекс: в случае пересоздания индекса он будет построен оптимальным образом.
Перестроить индекс: вместо того, чтобы удалять и создавать индекс вручную, PostgreSQL дает возможность перестроить существующий индекс с помощью команды REINDEX:
REINDEX INDEX index_name;Неблокирующее перестроение индекса: предыдущие методы запрашивают блокировку таблицы и предотвращают от изменений во время выполнения операции, что обычно неприемлемо. Чтобы избежать блокировки, можно перестроить индекс с параметром CONCURRENTLY:
REINDEX INDEX CONCURRENTLY index_name;При использовании REINDEX CONCURRENTLY PostgreSQL создает новый индекс с именем, содержащим суффикс _ccnew, и синхронизирует любые изменения, произошедшие в таблице. По завершении перестроения старый индекс заменяется на новый и удаляется.
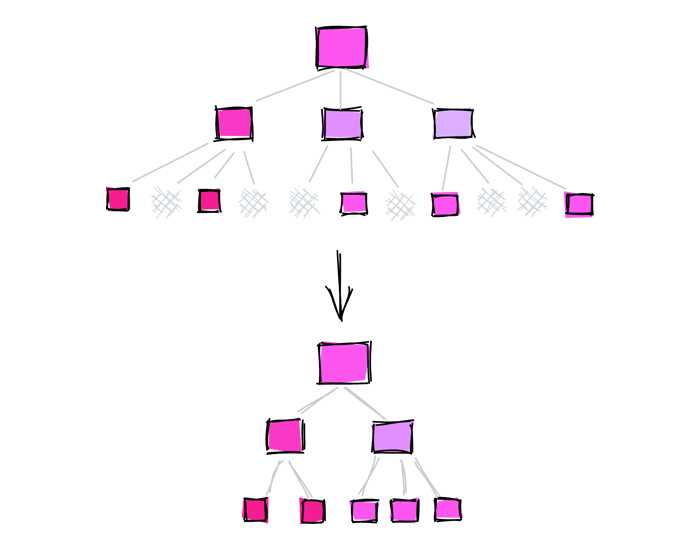 Устранение раздувания индексов
Устранение раздувания индексов
Если по какой-то причине вам пришлось остановить процесс перестройки индекса в середине процесса, новый индекс не будет удален. Вместо этого он останется в некорректном состоянии и будет занимать место. Чтобы распознать некорректные индексы, созданные во время REINDEX, используйте следующий запрос:
-- Identify invalid indexes that were created during index rebuild
SELECT
c.relname as index_name,
pg_size_pretty(pg_relation_size(c.oid))
FROM
pg_index i
JOIN pg_class c ON i.indexrelid = c.oid
WHERE
-- New index built using REINDEX CONCURRENTLY
c.relname LIKE '%_ccnew'
-- In INVALID state
AND NOT indisvalid
LIMIT 10;Как только процесс перестройки завершит работу, можно безопасно удалить все оставшиеся невалидные индексы.
Активация дедупликации индекса B-дерева
В PostgreSQL 13 появился новый эффективный способ хранения дублирующихся значений в индексах B-дерева, который называется «Дедупликация В-дерева».
Для каждого индексированного значения индекс B-дерева будет содержать как значение, так и указатель на строку (TID). Чем больше проиндексированные значения, тем больше индекс. Вплоть до PostgreSQL 12, когда индекс содержал много дублирующихся значений, все эти дублирующиеся значения сохранялись в индексных листьях. Это не очень эффективно и может занимать много места.
 Дедупликация индекса B-дерева
Дедупликация индекса B-дерева
Начиная с PostgreSQL 13, при активации дедупликации B-дерева повторяющиеся значения сохраняются только один раз. Это может сильно повлиять на размер индексов с большим количеством повторяющихся значений.
В PostgreSQL 13 дедупликация индекса включена по умолчанию, пока вы ее не отключите:
-- Activating de-deduplication for a B-Tree index, this is the default:
CREATE INDEX index_name ON table_name(column_name) WITH (deduplicate_items = ON)Если вы мигрируете с PostgreSQL версии меньше 13, вам нужно перестроить индексы с помощью команды REINDEX, для того чтобы получить все преимущества дедупликации индексов.
Для иллюстрации влияния дедупликации B-дерева на размер индекса, создадим таблицу с двумя столбцами: уникальным и не уникальными заполним ее миллионом строк. Для каждого столбца создадим два индекса В-дерева, один с включенной дедупликацией, другой — с выключенной:
db=# CREATE test_btree_dedup (n_unique serial, n_not_unique integer);
CREATE TABLE
db=# INSERT INTO test_btree_dedup (n_not_unique)
SELECT (random() * 100)::int FROM generate_series(1, 1000000);
INSERT 0 1000000
db=# CREATE INDEX ix1 ON test_btree_dedup (n_unique) WITH (deduplicate_items = OFF);
CREATE INDEX
db=# CREATE INDEX ix2 ON test_btree_dedup (n_unique) WITH (deduplicate_items = ON);
CREATE INDEX
db=# CREATE INDEX ix3 ON test_btree_dedup (n_not_unique) WITH (deduplicate_items = OFF);
CREATE INDEX
db=# CREATE INDEX ix4 ON test_btree_dedup (n_not_unique) WITH (deduplicate_items = ON);
CREATE INDEXТеперь сравним размеры четырех индексов:
Столбец | Дедупликация | Размер |
Неуникальный | Да | 6840 kB |
Неуникальный | Нет | 21 MB |
Уникальный | Да | 21 MB |
Уникальный | Нет | 21 MB |
Как и ожидалось, дедупликация не повлияла на уникальный индекс, но оказала существенное влияние на индекс, в котором было много дублирующихся значений.
К сожалению, PostgreSQL 13 в то время был еще молод, и наш облачный провайдер тогда не поддерживал его, поэтому у нас не было возможности использовать дедупликацию для очистки места.
Устранение раздувания таблиц
Как и индексы, таблицы также могут содержать неиспользуемые кортежи, которые приводят к раздуванию и фрагментации. Однако, в отличие от индексов, которые содержат данные из связанной таблицы, таблицу нельзя просто взять и пересоздать. Чтобы пересоздать таблицу, вам придется создать новую, провести миграцию данных, сохраняя их синхронизацию с новыми данными, создать все индексы, ограничения и любые ссылочные ограничения в других таблицах. Только после того, как все это сделано, можно переключиться со старой таблицы на новую.
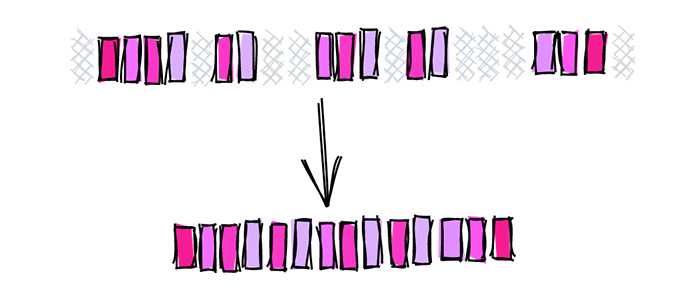 Устранение раздувания таблиц
Устранение раздувания таблиц
Есть несколько способов перестроить таблицу и уменьшить степень раздувания:
Пересоздать таблицу: использование выше обозначенного метода часто требует серьезной разработки, особенно в случае если таблица активно используется во время процесса перестроения.
Очистить таблицу с помощью VACUUM: PostgreSQL предлагает способ очистки места, занятого раздуванием и «мертвыми» кортежами в таблице с помощью команды VACUUM FULL, которая требует блокировки таблицы. Поэтому это нельзя назвать идеальным решением для таблиц, которые должны оставаться доступными в процессе очистки.
-- Will lock the table
VACUUM FULL table_name;Названные два способа требуют либо значительных усилий, либо какого-то времени простоя.
Использование pg_repack
Оба встроенных варианта перестройки таблицы не идеальны, если только вы не можете позволить себе простои. Одним из популярных решений для перестройки таблиц и индексов без простоев является расширение pg_repack.
Поскольку pg_repack — это довольно популярное расширение, то скорее всего, оно доступно в вашем пакетном менеджере или уже установлено облачным провайдером. Чтобы использовать pg_repack, сначала нужно создать расширение:
CREATE EXTENSION pg_repack;Чтобы «переупаковать» таблицу вместе с ее индексами, введите следующую команду в консоли:
$ pg_repack -k --table table_name db_nameЧтобы перестроить таблицу без простоев, расширение создает новую таблицу, загружает в нее данные из исходной таблицы, поддерживая ее в актуальном состоянии с новыми данными, а затем также перестраивает индексы. По завершении процесса две таблицы меняются местами, а исходная таблица удаляется. Подробнее см. здесь.
Расширение pg_repack поддерживается в Amazon RDS. Здесь можно узнать подробнее, как использовать pg_repack в AWS RDS.
При использовании pg_repack для перестроения таблиц следует помнить следующее:
Требуется объем хранилища, примерно равный объему перестраиваемой таблицы: расширение создает еще одну таблицу для копирования данных, поэтому ему требуется дополнительное хранилище, примерно равное размеру таблицы и ее индексов.
Может возникнуть потребность в некоторой ручной очистке: если процесс «переупаковки» упал или был остановлен вручную, он может оставить промежуточные объекты, из-за чего может потребоваться выполнить ручную очистку.
Несмотря на это, pg_repack — отличный вариант для перестроения таблиц и индексов без простоев. В то же время, поскольку оно требует дополнительного хранилища, это не лучший вариант в том случае, когда у вас уже закончилось свободное место. Рекомендуется следить за свободным пространством для хранения данных и планировать перестроение заранее.
Та самая находка
К этому времени мы уже использовали все возможные обычные техники и освободили много места. Мы удалили неиспользуемые индексы и избавили таблицы и индексы от раздувания, но… все еще оставалось пространство, которое можно было освободить!
Эврика
Когда мы анализировали размеры индексов после их перестройки, нам на глаза попалась интересная вещь.
В одной из самых больших таблиц хранятся данные о транзакциях. В нашей системе после совершения платежа пользователь может отменить его и получить возврат. Это происходит не очень часто, и в итоге отменяется лишь небольшая часть транзакций.
В таблице transactions есть внешние ключи для пользователя, совершающего покупку (purchasing user), и для пользователя, отменяющего покупку (cancelling user), и для каждого поля определен индекс B-дерева. Purchasing user имеет ограничение NOT NULL, поэтому все строки содержат значение. Cancelling user, с другой стороны, может принимать значение NULL, и только небольшая часть строк содержит какие-либо данные. Большинство значений в cancelling user равны NULL.
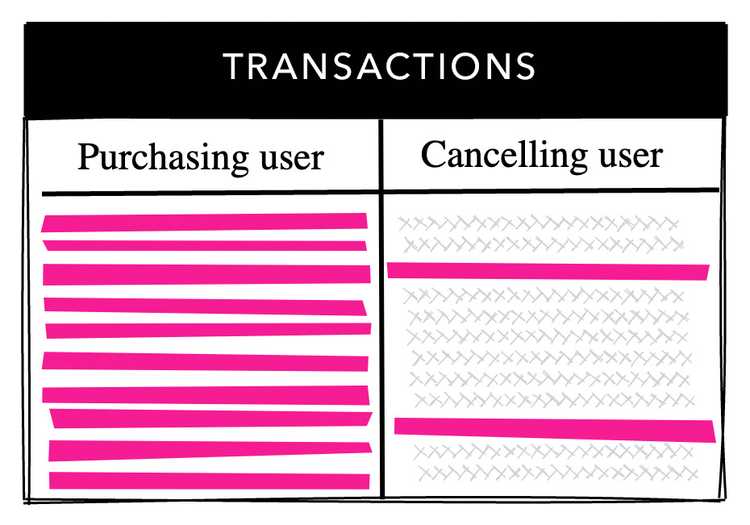 Таблица транзакций с FK покупающего и отменяющего пользователя
Таблица транзакций с FK покупающего и отменяющего пользователя
Мы ожидали, что индекс пользователя, отменяющего оплату, будет значительно меньше индекса пользователя, совершающего покупку, но они оказались одинаковыми. Я всегда думал, что значения NULL не индексируются, но в PostgreSQL они индексируются! Мы пришли к осознанию того, что мы зря индексируем множество ненужных значений.
Это был исходный индекс, который у нас был для отменяющего пользователя:
CREATE INDEX transaction_cancelled_by_ix ON transactions(cancelled_by_user_id);Чтобы проверить нашу гипотезу, мы заменили индекс частичным индексом, исключающим пустые значения:
DROP INDEX transaction_cancelled_by_ix;
CREATE INDEX transaction_cancelled_by_part_ix ON transactions(cancelled_by_user_id)
WHERE cancelled_by_user_id IS NOT NULL;Полный индекс после переиндексации весил 769 МБ, с более чем 99% пустых значений. Вес частичного индекса, исключающего пустые значения, был меньше 5 МБ. Что составляет более 99% мертвого веса, сброшенного с индекса!
Индекс | Размер |
Полный индекс | 769 MB |
Частичный индекс | 5 MB |
Разница | -99% |
Чтобы убедиться в том, что эти значения NULL действительно не нужны, мы сбросили статистику таблицы и немного подождали. Вскоре после этого мы заметили, что индекс используется так же, как и старый. Мы только что убрали более 760 МБ неиспользуемых индексированных кортежей без негативного влияния на производительность!
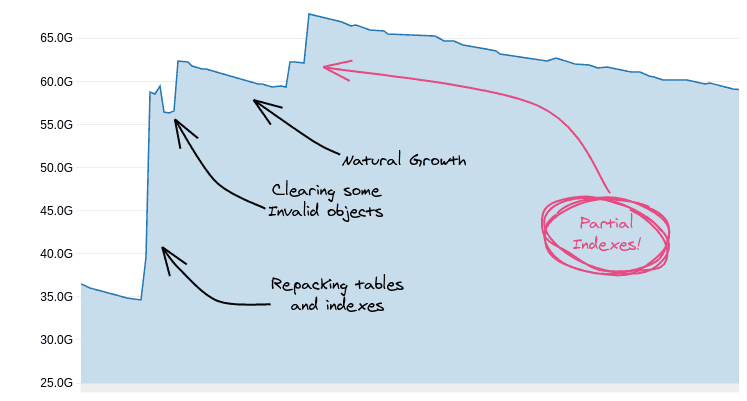 Очистка пространства, шаг за шагом
Очистка пространства, шаг за шагом
Использование частичных индексов
После успешного опыта работы с одним частичным индексом нам пришла в голову мысль, что таких индексов может быть больше. Чтобы найти кандидатов для частичного индекса, мы написали запрос для поиска индексов для полей с высоким значением null_frac, процентом значений столбца, которые PostgreSQL оценивает как NULL:
-- Find indexed columns with high null_frac
SELECT
c.oid,
c.relname AS index,
pg_size_pretty(pg_relation_size(c.oid)) AS index_size,
i.indisunique AS unique,
a.attname AS indexed_column,
CASE s.null_frac
WHEN 0 THEN ''
ELSE to_char(s.null_frac * 100, '999.00%')
END AS null_frac,
pg_size_pretty((pg_relation_size(c.oid) * s.null_frac)::bigint) AS expected_saving
-- Uncomment to include the index definition
--, ixs.indexdef
FROM
pg_class c
JOIN pg_index i ON i.indexrelid = c.oid
JOIN pg_attribute a ON a.attrelid = c.oid
JOIN pg_class c_table ON c_table.oid = i.indrelid
JOIN pg_indexes ixs ON c.relname = ixs.indexname
LEFT JOIN pg_stats s ON s.tablename = c_table.relname AND a.attname = s.attname
WHERE
-- Primary key cannot be partial
NOT i.indisprimary
-- Exclude already partial indexes
AND i.indpred IS NULL
-- Exclude composite indexes
AND array_length(i.indkey, 1) = 1
-- Larger than 10MB
AND pg_relation_size(c.oid) > 10 * 1024 ^ 2
ORDER BY
pg_relation_size(c.oid) * s.null_frac DESC;Результат запроса может выглядеть подобным образом:
oid | index | index_size | unique | indexed_column | null_frac | expected_saving
---------+--------------------+------------+--------+----------------+-----------+-----------------
138247 | tx_cancelled_by_ix | 1418 MB | f | cancelled_by | 96.15% | 1363 MB
16988 | tx_op1_ix | 1651 MB | t | op1 | 6.11% | 101 MB
1473377 | tx_token_ix | 22 MB | t | token | 11.21% | 2494 kB
138529 | tx_op_name_ix | 1160 MB | t | name | | 0 bytesВ таблице выше мы можем распознать несколько типов результатов:
tx_cancelled_by_ix— это большой индекс с множеством значений NULL: здесь очень большой потенциал!tx_op_1_ix— большой индекс с несколькими NULL-значениями: потенциал невелик.tx_token_ix— маленький индекс с несколькими значениями NULL: я бы не стал заморачиваться с этим индексом.tx_op_name_ix— большой индекс без NULL: здесь вообще делать нечего.
Результаты показывают, что, превратив tx_cancelled_by_ix в частичный индекс, исключающий NULL, мы потенциально можем сэкономить примерно 1,3 ГБ.
Всегда ли целесообразно исключать пустые значения из индексов?
Нет. NULL несет в себе смысл, как и любое другое значение. Если ваши запросы ищут пустые значения с использованием IS NULL, эти запросы могут выиграть от полного индекса.
Получается, этот метод полезен только для значений NULL?
Использование частичных индексов для исключения значений, которые запрашиваются очень часто или вообще не запрашиваются, может быть полезно для любого значения, не только для NULL. NULL обычно указывает на отсутствие значения, а в нашем случае не так много запросов искали значения NULL, поэтому имело смысл исключить их из индекса.
И каким же образом очистить более 20 ГБ?
Внимательный читатель наверняка заметил, что в заголовке упоминается более 20 ГБ свободного места, в то время как диаграммы показывают только половину… Дело в том, что индексы также удаляются из репликаций. Когда вы высвобождаете 10 ГБ из основной базы данных, вы также освобождаете примерно такой же объем хранилища из каждой ее копии.
Бонус: миграция с Django ORM
Эта история взята из большого приложения на Django. Чтобы применить описанные выше методы на практике с Django, нужно учесть несколько моментов.
Предотвращение неявного создания индексов для внешних ключей
Если вы не установите явно db_index=False, Django будет неявно создавать индекс B-дерева для поля models.ForeignKey. Рассмотрим следующий пример:
from django.db import models
from django.contrib.auth.models import User
class Transaction(models.Model):
# ...
cancelled_by_user = models.ForeignKey(
to=User,
null=True,
on_delete=models.CASCADE,
)Модель используется для отслеживания данных транзакций. В случае отмены транзакции мы сохраняем ссылку на пользователя, который ее отменил. Как описано ранее, большинство транзакций не отменяются, поэтому мы устанавливаем в поле null=True.
В приведенном выше определении ForeignKey мы явно не задали db_index, поэтому Django неявно создаст полный индекс для поля. Чтобы вместо этого создать частичный индекс, внесите следующие изменения:
from django.db import models
from django.contrib.auth.models import User
class Transaction(models.Model):
# ...
cancelled_by_user = models.ForeignKey(
to=User,
null=True,
on_delete=models.CASCADE,
db_index=False,
)
class Meta:
indexes = (
models.Index(
fields=('cancelled_by_user_id', ),
name='%(class_name)s_cancelled_by_part_ix',
condition=Q(cancelled_by_user_id__isnull=False),
),
)Сначала мы говорим Django не создавать индекс для поля FK, а затем добавляем частичный индекс с помощью models.Index.
Те внешние ключи, которые среди множества своих значений могут содержать NULL, являются хорошими кандидатами для частичного индекса!
Чтобы предотвратить неявные функции, такие как эта, от кражи индексов, мы создаем проверки Django, чтобы поставить себя в необходимости всегда явно устанавливать db_index во внешних ключах.
Миграция из существующих полных индексов в частичные индексы
Одной из трудностей, с которыми мы столкнулись во время этой миграции, была замена существующих полных индексов частичными индексами без простоев или снижения производительности во время миграции. После того, как мы определили полные индексы, которые хотим заменить, мы предприняли следующие шаги:
Заменить полные индексы частичными индексами: настроить соответствующие модели Django и заменить полные индексы частичными индексами, как показано выше. Миграция, которая генерируется Django, сначала отключит ограничение FK (если поле является внешним ключом), удалит существующий полный индекс и создаст новый частичный индекс. Выполнение этой миграции может привести как к простою, так и к снижению производительности, поэтому мы не будем ее запускать.
Создать частичные индексы вручную: использовать утилиту Django
./manage.py sqlmigrate, чтобы создать скрипт для миграции, извлечь только операторыCREATE INDEXи настроить их для ПАРАЛЛЕЛЬНОГО создания индексов. Затем создать индексы вручную и параллельно в базе данных. Поскольку полные индексы еще не удалены, они по-прежнему могут использоваться запросами, поэтому это не должно сказаться на производительности. Создавать индексы возможно параллельно с миграциями Django, но на этот раз мы решили, что лучше сделать это вручную.
3. Сброс счетчиков статистики полных индексов: чтобы убедиться, что удаление полных индексов безопасно, мы хотели сначала проверить, что новые частичные индексы используются. Чтобы отслеживать их использование, надо сбросить счетчики для полных индексов, используя
pg_stat_reset_single_table_counters (
4. Мониторинг использования частичных индексов: после сброса статистики надо отследить как общую производительность запросов, так и использование частичного индекса с помощью наблюдения за значениями idx_scan, idx_tup_read и idx_tup_fetch в таблицах pg_stat_all_indexes как для частичных, так и для полных индексов.
5. Удаление полных индексов: как только мы убедились, что частичные индексы используются, мы удалили полные индексы. Это хороший момент, чтобы проверить размеры как частичных, так и полных индексов, чтобы узнать, сколько точно памяти вы собираетесь освободить.
6. Фейковая миграция Django: как только состояние базы данных будет эффективно синхронизировано с состоянием модели, мы имитируем миграцию с помощью ./manage.py migrate --fake. При имитации миграции Django зарегистрирует миграцию как выполненную, но на самом деле ничего не будет выполнено. Это полезно в подобных ситуациях, когда вам нужен лучший контроль над процессом миграции. Обратите внимание, что в других средах, таких как dev, QA или staging, где нет ограничений простоя, миграции Django будут выполняться нормально, а полные индексы будут заменены частичными. Чтобы узнать о более сложных операциях миграции Django, таких как «имитация», читайте статью «Как переместить модель Django в другое приложение».
Вывод
Оптимизация дисков, параметров хранения и конфигурации может сильно повлиять на производительность. В какой-то момент, чтобы не допустить снижения производительности, вам нужно внести изменения в базовые объекты. В данном случае это было определение индекса.
Подведем краткий итог всему тому, что мы предприняли, чтобы очистить как можно больше памяти:
Удалили неиспользуемые индексы.
Переупаковали таблицы и индексы (и активировали дедупликацию B-Tree, когда это возможно).
Использовали частичные индексы, чтобы индексировать только то, что необходимо.
В настоящее время все больше компаний рассматривает возможность перехода на PostgreSQL с других СУБД. Совсем скоро состоится открытое занятие «Мигрируем в PostgreSQL», на котором мы поговорим об общих проблемах миграции данных и на практике посмотрим, что предлагает для этого PostgreSQL. Рассмотрим вопросы: загрузки данных на Постгрес, переноса PostgreSQL базы с Linux на Windows (или наоборот) и настроим логическую репликацию, которая позволяет мигрировать данные с более старой версии Постгреса на новую. Регистрация доступна по ссылке для всех желающих.
