[Перевод] Лучшие методики тестирования в JavaScript и Node.js

Это исчерпывающее руководство по обеспечению надёжности в JavaScript и Node.js. Здесь собраны десятки лучших постов, книг и инструментов.
Сначала разберитесь с общепринятыми методиками тестирования, которые лежат в основе любого приложения. А затем можно углубиться в интересующую вас сферу: фронтенд и интерфейсы, бэкенд, CI или всё перечисленное.
0. Золотое правило: Придерживайтесь бережливого тестирования
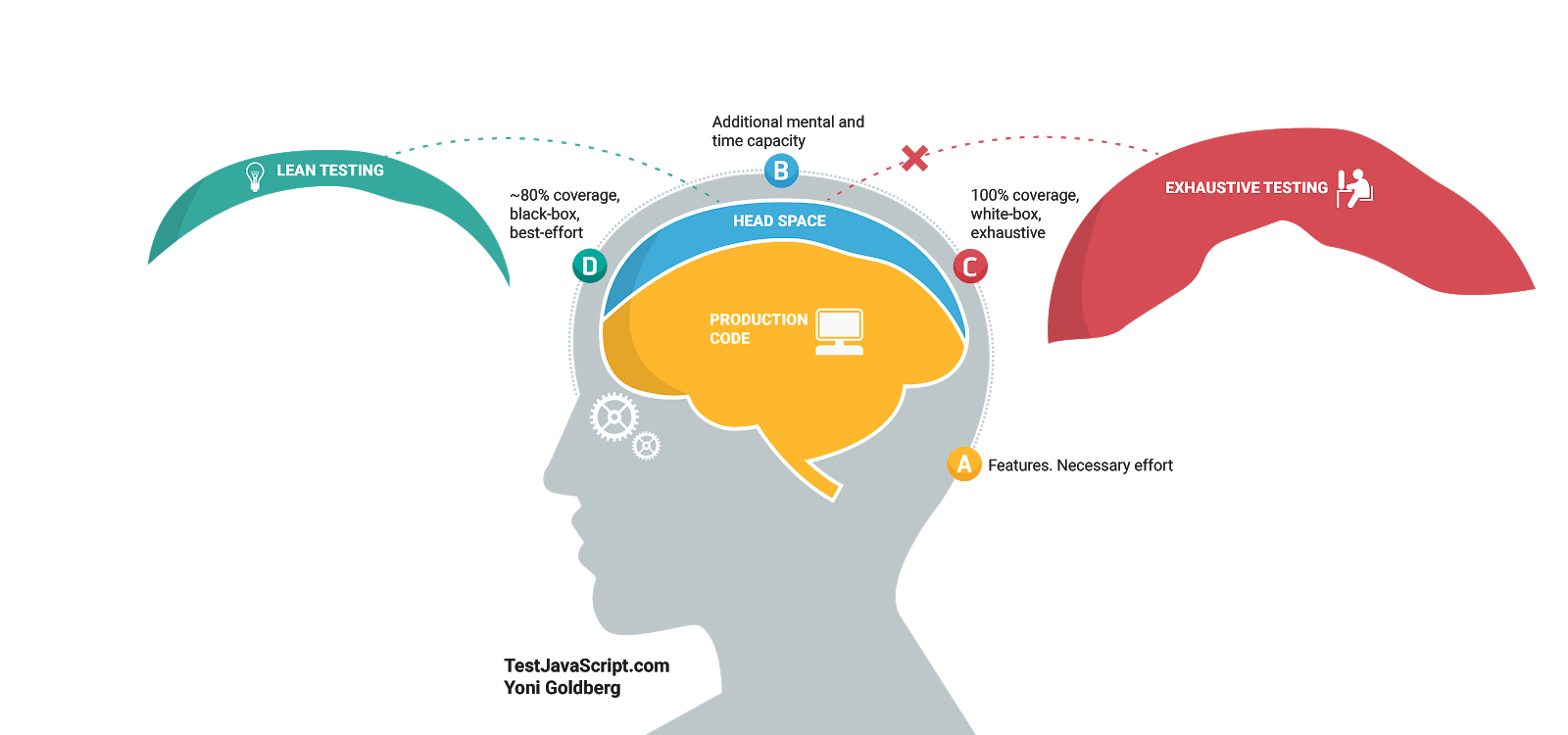
Что сделать. Тестовый код отличается от того, что идёт в эксплуатацию. Делайте его максимально простым, коротким, свободным от абстракций, единым, замечательным в работе и бережливым. Другой человек должен посмотреть на тест и сразу понять, что он делает.
Наши головы заняты production-кодом, в них нет свободного места для дополнительной сложности. Если мы будем пихать в свой бедный разум новую порцию сложного кода, это замедлит работу всей команды над задачей, ради решения которой мы и проводим тестирование. По сути, из-за этого многие команды просто избегают тестов.
Тесты — это возможность получить дружелюбного и улыбчивого помощника, с которым очень хорошо работать и который даёт огромную отдачу при небольших вложениях. Учёные считают, что в нашем мозге существует две системы: одна для действий, которые не требуют усилий, вроде езды по пустой дороге, и вторая для сложных операций, требующих осознанности, вроде решения математических уравнений. Создавайте свои тесты для первой системы, что при взгляде на код у вас возникало ощущение простоты, сравнимой с редактированием HTML-документа, а не с решением 2X(17 × 24).
Добиться этого можно с помощью тщательного подбора методик, инструментов и целей для тестирования, чтобы они были экономичны и давали большой ROI. Тестируйте лишь столько, сколько необходимо, старайтесь подходить гибко. Иногда стоит даже отбросить какие-то тесты и пожертвовать надёжностью ради скорости и простоты.
Большинство рекомендаций, представленных ниже, являются производными от этого принципа.
Готовы?
1.1 Имя каждого теста должно состоять из трёх частей
Что сделать. Отчёт о тестировании должен свидетельствовать о том, удовлетворяет ли текущая ревизия приложения требованиям тех людей, которые не знакомы с кодом: тестировщиков, занимающихся деплоем DevOps-инженеров, а также вас самих через два года. Лучше всего будет, если тесты сообщают информацию на языке требований, а их наименования состоят из трёх частей:
- Что именно тестируется? Например, метод
ProductsService.addNewProduct. - При каких условиях и сценарии? Например, методу не передаётся цена.
- омным накладным расходам, как опКакой ожидается результат? Например, новый продукт не одобрен.
В противном случае. Деплой не удаётся, сбоит тест под названием «Add product». Вы понимаете, что именно работает не так?
Примечание. В каждой главе есть пример кода, а иногда и иллюстрация. См. в спойлерах.
//1. unit under test
describe('Products Service', function() {
describe('Add new product', function() {
//2. scenario and 3. expectation
it('When no price is specified, then the product status is pending approval', ()=> {
const newProduct = new ProductService().add(...);
expect(newProduct.status).to.equal('pendingApproval');
});
});
});1.2 Структурируйте тесты согласно паттерну AAA
Что сделать. Каждый тест должен состоять из трёх чётко разделённых разделов: Arrange (подготовка), Act (действие) и Assert (результат). Соблюдение такой структуры гарантирует, что читающему ваш код не придётся задействовать мозговой процессор, чтобы понять план теста:
Arrange: весь код, который приводит систему в состояние согласно тестовому сценарию. Сюда может входить создание экземпляра модуля в конструкторе тестов, добавление записей в базу данных, создание заглушек вместо объектов, и любой другой код, подготавливающий систему к прогону теста.
Act: исполнение кода в рамках теста. Обычно всего одна строка.
Assert: убеждаемся, что полученное значение удовлетворяет ожиданиям. Обычно всего одна строка.
В противном случае. Вы не только будете тратить долгие часы на работу с основным кодом, но ваш мозг будет пухнуть ещё и от того, что должно быть простой работой — от тестирования.
describe.skip('Customer classifier', () => {
test('When customer spent more than 500$, should be classified as premium', () => {
//Arrange
const customerToClassify = {spent:505, joined: new Date(), id:1}
const DBStub = sinon.stub(dataAccess, "getCustomer")
.reply({id:1, classification: 'regular'});
//Act
const receivedClassification = customerClassifier.classifyCustomer(customerToClassify);
//Assert
expect(receivedClassification).toMatch('premium');
});
});
Пример антипаттерна. Никакого разделения, одним куском, сложнее интерпретировать.
test('Should be classified as premium', () => {
const customerToClassify = {spent:505, joined: new Date(), id:1}
const DBStub = sinon.stub(dataAccess, "getCustomer")
.reply({id:1, classification: 'regular'});
const receivedClassification = customerClassifier.classifyCustomer(customerToClassify);
expect(receivedClassification).toMatch('premium');
});1.3 Описывайте ожидания на языке продукта: констатируйте в стиле BDD
Что сделать. Программирование тестов в декларативном стиле позволяет пользователю сразу понять суть, не тратя ни одного цикла мозгового процессора. Когда вы пишете императивный код, упакованный в условную логику, читателю приходится прилагать массу усилий. С этой точки зрения нужно описывать ожидания на языке, похожем на человеческий, в декларативном BDD-стиле с использованием expect/should и не применяя кастомный код. Если в Chai и Jest нет нужной констатации (assertion), которая часто повторяется, то можно расширить сопоставитель (matcher) Jest или написать свой плагин для Chai.
В противном случае. Команда будет писать меньше тестов и декорировать раздражающие тесты with .skip().
Пример антипаттерна. чтобы понять суть теста, пользователь вынужден продраться через довольно длинный императивный код.
it("When asking for an admin, ensure only ordered admins in results" , ()={
//assuming we've added here two admins "admin1", "admin2" and "user1"
const allAdmins = getUsers({adminOnly:true});
const admin1Found, adming2Found = false;
allAdmins.forEach(aSingleUser => {
if(aSingleUser === "user1"){
assert.notEqual(aSingleUser, "user1", "A user was found and not admin");
}
if(aSingleUser==="admin1"){
admin1Found = true;
}
if(aSingleUser==="admin2"){
admin2Found = true;
}
});
if(!admin1Found || !admin2Found ){
throw new Error("Not all admins were returned");
}
});
Как делать правильно. Чтение этого декларативного теста не вызывает затруднений.
it("When asking for an admin, ensure only ordered admins in results" , ()={
//assuming we've added here two admins
const allAdmins = getUsers({adminOnly:true});
expect(allAdmins).to.include.ordered.members(["admin1" , "admin2"])
.but.not.include.ordered.members(["user1"]);
});1.4 Придерживайтесь тестирования по методу «чёрного ящика»: тестируйте только публичные методы
Что сделать. Тестирование внутренностей приведёт к огромным накладным расходам и почти ничего не даст. Если ваш код или API предоставляет правильные результаты, стоит ли тратить три часа на тестирование того, КАК это работает внутри, а затем ещё и поддерживать эти хрупкие тесты? Когда вы проверяете публичное поведение, вы одновременно неявным образом проверяете и саму реализацию, ваши тесты будут сбоить только при наличии конкретной проблемы (например, неправильные выходные данные). Этот подход также называют поведенческим тестированием. С другой стороны, если вы тестируете внутренности (метод «белого ящика»), то вместо планирования выходных данных компонентов вы сосредоточитесь на мелких подробностях, и ваши тесты могут сломаться из-за мелких переделок кода, пусть даже с результатами всё будет в порядке, а на сопровождение будет уходить гораздо больше ресурсов.
В противном случае. Ваши тесты будут вести себя как мальчик, кричавший «Волк!»: громко сообщать о ложно-положительных срабатываниях (например, тест сбоит из-за изменения имени частной переменной). Неудивительно, что скоро люди начнут игнорировать CI-уведомления, и однажды пропустят настоящий баг…
Пример с использованием Mocha.
class ProductService{
//this method is only used internally
//Change this name will make the tests fail
calculateVAT(priceWithoutVAT){
return {finalPrice: priceWithoutVAT * 1.2};
//Change the result format or key name above will make the tests fail
}
//public method
getPrice(productId){
const desiredProduct= DB.getProduct(productId);
finalPrice = this.calculateVATAdd(desiredProduct.price).finalPrice;
}
}
it("White-box test: When the internal methods get 0 vat, it return 0 response", async () => {
//There's no requirement to allow users to calculate the VAT, only show the final price. Nevertheless we falsely insist here to test the class internals
expect(new ProductService().calculateVATAdd(0).finalPrice).to.equal(0);
});1.5 Выбирайте правильные имитированные реализации: избегайте фальшивых объектов в пользу заглушек и шпионов
Что сделать. Имитированные реализации (test doubles) — это необходимое зло, потому что они связаны с внутренностями приложения, а некоторые имеют огромную ценность (освежите в памяти информацию об имитированных реализациях: фальшивые объекты (mocks), заглушки (stubs) и объекты-шпионы (spies)). Однако не все методики эквивалентны. Шпионы и заглушки предназначены для тестирования требований, но имеют неизбежный побочный эффект — также они слегка затрагивают и внутренности. А фальшивые объекты предназначены для тестирования внутренностей, что приводит к огромным накладным расходам, как описано в главе 1.4.
Прежде чем использовать имитированные реализации, задайте себе простейший вопрос: «Я использую это для тестирования функциональности, которая появилась или может появиться в документации с требованиями?» Если нет, то попахивает тестированием по методу «белого ящика».
Например, если вы хотите выяснить, ведёт ли приложение себя как положено при недоступности платёжного сервиса, вы можете сделать вместо него заглушку и возвращать «Нет ответа», чтобы проверить возвращение правильного значения тестируемым модулем. Так можно проверять поведение/ответ/выходные данные приложения при определённых сценариях. Вы также можете с помощью шпиона подтвердить, что при недоступности сервиса письмо было отправлено, это тоже поведенческое тестирование, которое лучше отразить в документации с требованиями («Отправить письмо, если нельзя сохранить информацию о платеже»). В то же время, если вы сделаете фальшивый платёжный сервис и удостоверитесь, что он вызывался с помощью правильных JS-типов, тогда ваш тест нацелен на внутренности, не имеющие отношения к функциональности приложения и которые наверняка будут часто меняться.
В противном случае. Любой рефакторинг кода подразумевает поиск и обновление всех фальшивых объектов в коде. Тесты из друга-помощника превращаются в обузу.
Пример с использованием Sinon.
it("When a valid product is about to be deleted, ensure data access DAL was called once, with the right product and right config", async () => {
//Assume we already added a product
const dataAccessMock = sinon.mock(DAL);
//hmmm BAD: testing the internals is actually our main goal here, not just a side-effect
dataAccessMock.expects("deleteProduct").once().withArgs(DBConfig, theProductWeJustAdded, true, false);
new ProductService().deletePrice(theProductWeJustAdded);
mock.verify();
});
Как делать правильно. Шпионы предназначены для тестирования требований, но есть побочный эффект — они неизбежно затрагивают внутренности.
it("When a valid product is about to be deleted, ensure an email is sent", async () => {
//Assume we already added here a product
const spy = sinon.spy(Emailer.prototype, "sendEmail");
new ProductService().deletePrice(theProductWeJustAdded);
//hmmm OK: we deal with internals? Yes, but as a side effect of testing the requirements (sending an email)
});1.6 Не применяйте «foo», используйте реалистичные входные данные
Что сделать. Часто production-баги проявляются при очень специфических и удивительных входных данных. Чем реалистичнее данные в ходе тестирования, тем больше шансов вовремя выловить баги. Для генерирования псевдонастоящих данных, имитирующих разнообразие и вид production-данных, используйте специальные библиотеки, например, Faker. Такие библиотеки могут генерировать реалистичные телефонные номера, ники пользователей, банковские карты, названия компаний, даже текст «lorem ipsum». Вы можете создавать тесты (поверх модульных, а не вместо них), которые рандомизируют фальшивые данные для подгонки модуля под тест, или даже импортировать настоящие данные из production-окружения. Хотите пойти ещё дальше? Читайте следующую главу (о тестировании на основе свойств).
В противном случае. Ваше тестирование в ходе разработки будет выглядеть успешным при использовании синтетических входных данных вроде «Foo», а на production-данных могут начаться сбои, когда хакер передаст хитрую строку вроде @3e2ddsf . ##’ 1 fdsfds . fds432 AAAA.
Пример с использованием Jest.
const addProduct = (name, price) =>{
const productNameRegexNoSpace = /^\S*$/;//no white-space allowed
if(!productNameRegexNoSpace.test(name))
return false;//this path never reached due to dull input
//some logic here
return true;
};
test("Wrong: When adding new product with valid properties, get successful confirmation", async () => {
//The string "Foo" which is used in all tests never triggers a false result
const addProductResult = addProduct("Foo", 5);
expect(addProductResult).to.be.true;
//Positive-false: the operation succeeded because we never tried with long
//product name including spaces
});
Как делать правильно. Рандомизируйте реалистичные входные данные.
it("Better: When adding new valid product, get successful confirmation", async () => {
const addProductResult = addProduct(faker.commerce.productName(), faker.random.number());
//Generated random input: {'Sleek Cotton Computer', 85481}
expect(addProductResult).to.be.true;
//Test failed, the random input triggered some path we never planned for.
//We discovered a bug early!
});1.7 С помощью тестирования на основе свойств проверяйте многочисленные комбинации входных данных
Что сделать. Обычно для каждого теста мы выбираем несколько образцов входных данных. Даже если входной формат похож на настоящие данные (см. главу «Не применяйте «foo»), мы покрываем лишь несколько комбинаций входных данных (метод (‘’, true, 1), метод ("string" , false" , 0)). Но в эксплуатации API, который вызывается с пятью параметрами, может быть вызван с тысячами различных комбинаций, одна из которых может привести к падению процесса (фаззинг). Что, если вы могли бы написать один тест, автоматически отправляющий 1000 комбинаций входных данных и фиксирующий, при каких комбинациях код не возвращает правильный ответ? То же самое мы делаем при методике тестирования на основе свойств: с помощью отправки всех возможных комбинаций входных данных в тестируемый модуль мы увеличиваем шанс обнаружения бага. Например, у нас есть метод addNewProduct(id, name, isDiscount). Поддерживающие его библиотеки будут вызывать этот метод со многими комбинациями (числа, строкового значения, булева значения), например, (1, "iPhone", false), (2, "Galaxy", true) и т.д. Вы можете тестировать на основе свойств с помощью своего любимого прогонщика тестов (Mocha, Jest и т.д.) и библиотек вроде js-verify или testcheck (у неё гораздо лучше документация). Ещё можете попробовать библиотеку fast-check, которая предлагает дополнительные возможности и активно сопровождается автором.
В противном случае. Вы бездумно выбираете для теста входные данные, которые покрывают лишь хорошо работающие пути исполнения кода. К сожалению, это снижает эффективность тестирования как средства выявления ошибок.
require('mocha-testcheck').install();
const {expect} = require('chai');
const faker = require('faker');
describe('Product service', () => {
describe('Adding new', () => {
//this will run 100 times with different random properties
check.it('Add new product with random yet valid properties, always successful',
gen.int, gen.string, (id, name) => {
expect(addNewProduct(id, name).status).to.equal('approved');
});
})
});1.8 При необходимости используйте только короткие и инлайненные снимки
Что сделать. Когда нужно протестировать на основе снимков, используйте только короткие снимки безо всего лишнего (например, в 3–7 строк), включая их в качестве части теста (Inline Snapshot), а не в виде внешних файлов. Соблюдение этой рекомендации позволит сохранить ваши тесты самоочевидными и более надёжными.
С другой стороны, руководства по «классическим снимкам» и инструментарий провоцируют нас хранить большие файлы (например, разметку отрисовки компонентов или результаты API JSON) на внешнем носителе и при каждом запуске теста сравнивать результаты с сохранённой версией. Это может, скажем, неявно связать наш тест с 1000 строк, содержащих 3000 значений, которые автор теста никогда не видел о которых не предполагал. Почему это плохо? Потому что появляется 1000 причин для сбоя теста. Даже одна строка может сделать снимок недействительным, и происходить это может часто. Насколько? После каждого пробела, комментария или мелкого изменения в CSS или HTML. Кроме того, имя теста не подскажет вам о сбое, потому что он лишь проверяет, что 1000 строк не изменились, да к тому же подталкивает автора теста принять в качестве желаемого длинный документ, который он не смог бы проанализировать и сверить. Всё это является симптомами неясного и торопливого теста, не имеющего чёткой задачи и пытающегося добиться слишком многого.
Стоит отметить, что есть несколько ситуаций, в которых приемлемо использовать длинные и внешние снимки, например, при подтверждении схемы, а не данных (извлечение значений и сосредоточенность на полях), или когда получаемые документы редко изменяются.
В противном случае. UI-тесты сбоят. Код выглядит нормально, на экране отображаются идеальные пиксели, что же происходит? Ваше тестирование с помощью снимков только что выявило различие между исходным документом и только что полученным — в разметке добавился один символ пробела…
it('TestJavaScript.com is renderd correctly', () => {
//Arrange
//Act
const receivedPage = renderer
.create( Test JavaScript < /DisplayPage>)
.toJSON();
//Assert
expect(receivedPage).toMatchSnapshot();
//We now implicitly maintain a 2000 lines long document
//every additional line break or comment - will break this test
});
Как делать правильно. Ожидания видимы и находятся в центре внимания.
it('When visiting TestJavaScript.com home page, a menu is displayed', () => {
//Arrange
//Act
receivedPage tree = renderer
.create( Test JavaScript < /DisplayPage>)
.toJSON();
//Assert
const menu = receivedPage.content.menu;
expect(menu).toMatchInlineSnapshot(`
- Home
- About
- Contact
`);
}); 1.9 Избегайте глобальных тестовых стендов и начальных данных, добавляйте данные в каждый тест по отдельности
Что сделать. Согласно золотому правилу (глава 0), каждый тест должен добавлять и работать в рамках собственного набора строк в базе данных, чтобы избегать связываний, а пользователям было легче разобраться в работе теста. В реальности тестеры часто нарушают это правило, перед прогоном тестов заполняя БД начальными данными (seeds) (также это называют «тестовым стендом») ради повышения производительности. И хотя производительность действительно является важной задачей, ведь она может уменьшиться (см. главу «Тестирование компонентов»), однако сложность тестов куда вреднее и именно она должна чаще всего управлять нашими решениями. Практически каждый тестовый случай должен явно добавлять в БД необходимые записи и работать только с ними. Если производительность критически важна, то в качестве компромисса можно заполнять начальными данными только те тесты, которые не изменяют информацию (например, запросы).
В противном случае. Несколько тестов провалены, развёртывание прервано, теперь команда потратит драгоценное время, у нас баг? Давайте искать, блин, кажется, два теста меняли одни и те же начальные данные.
before(() => {
//adding sites and admins data to our DB. Where is the data? outside. At some external json or migration framework
await DB.AddSeedDataFromJson('seed.json');
});
it("When updating site name, get successful confirmation", async () => {
//I know that site name "portal" exists - I saw it in the seed files
const siteToUpdate = await SiteService.getSiteByName("Portal");
const updateNameResult = await SiteService.changeName(siteToUpdate, "newName");
expect(updateNameResult).to.be(true);
});
it("When querying by site name, get the right site", async () => {
//I know that site name "portal" exists - I saw it in the seed files
const siteToCheck = await SiteService.getSiteByName("Portal");
expect(siteToCheck.name).to.be.equal("Portal"); //Failure! The previous test change the name :[
});
Как делать правильно. Можно оставаться в рамках теста, каждый тест работает только со своими данными.
it("When updating site name, get successful confirmation", async () => {
//test is adding a fresh new records and acting on the records only
const siteUnderTest = await SiteService.addSite({
name: "siteForUpdateTest"
});
const updateNameResult = await SiteService.changeName(siteUnderTest, "newName");
expect(updateNameResult).to.be(true);
});
1.10 Не ловите ошибки, а ожидайте их
Что сделать. Желая подтвердить, что какие-то входные данные приводят к ошибке, вы можете прибегнуть к try-catch-finally и доказать, что было введено условие поимки ошибки. В результате получается неприглядный и громоздкий тест (пример ниже), который скрывает простое намерение проверки и ожидания результатов.
Более элегантным решением будет использование однострочной проверки Chai: expect(method).to.throw (или в Jest: expect(method).toThrow()). Также абсолютно необходимо убедиться в том, что исключение содержит свойство, позволяющее узнать тип ошибки. Иначе, если будет некая общая ошибка, то приложение сможет показать пользователю лишь раздражающее сообщение.
В противном случае. Из отчётов о тестировании (например, CI-отчётов) будет сложно понять, что пошло не так.
/it("When no product name, it throws error 400", async() => {
let errorWeExceptFor = null;
try {
const result = await addNewProduct({name:'nest'});}
catch (error) {
expect(error.code).to.equal('InvalidInput');
errorWeExceptFor = error;
}
expect(errorWeExceptFor).not.to.be.null;
//if this assertion fails, the tests results/reports will only show
//that some value is null, there won't be a word about a missing Exception
});
Как делать правильно. Удобный для восприятия человеком код, который легко понять, возможно, даже сотрудникам QA или техническим менеджерам проектов.
it.only("When no product name, it throws error 400", async() => {
expect(addNewProduct)).to.eventually.throw(AppError).with.property('code', "InvalidInput");
});
1.11 Размечайте свои тесты
Что сделать. Разные тесты должны прогоняться для разных сценариев:
- быстрые smoke-тесты,
- IO-less,
- тесты, которые должны выполняться, когда разработчик сохраняет или коммитит файл,
- полные сквозные тесты, которые обычно выполняются при отправке новых pull request«ов, и так далее.
Добиться этого можно, если помечать тесты ключевыми словами, например, #cold #api #sanity. Тогда вы сможете грепать свои инструменты тестирования и вызывать нужный набор тестов. Например, таким способом можно в Mocha вызывать группу тестов на работоспособность: mocha — grep ‘sanity’.
В противном случае. Если при любом, даже самом мелком изменении, которое сделал разработчик, прогонять все тесты, включая те, что выполняют десятки запросов к базе данных, то рабочий процесс очень сильно замедлится, а разработчики будут стараться избегать тестирования.
//this test is fast (no DB) and we're tagging it correspondingly
//now the user/CI can run it frequently
describe('Order service', function() {
describe('Add new order #cold-test #sanity', function() {
it('Scenario - no currency was supplied. Expectation - Use the default currency #sanity', function() {
//code logic here
});
});
});1.12 Другие общие правила гигиены тестирования
Что сделать. Эта статья посвящена советам, которые относятся к Node.js или могут быть иллюстрированы с его помощью. А в этой главе я опишу несколько хорошо известных советов, не связанных с Node.
Изучайте и применяйте принципы TDD. Они очень полезны для многих, но не расстраивайтесь, если они не подойдут под ваш стиль, не вы первые с этим столкнулись. Попробуйте писать тесты до написания кода в стиле красный-зелёный-рефакторинг, тогда каждый тест будет проверять только что-то одно. Когда найдёте баг, то перед его исправлением напишите тест, который определит этот баг в будущем. Позвольте тесту сбоить хотя бы один раз, прежде чем исправить баг. Начинайте модуль с быстрого написания упрощённого кода, удовлетворяющего тесту, а затем постепенно его рефакторьте, доводя до эксплуатационного уровня, избегая зависимостей от среды (путей, ОС и т.д.).
В противном случае. Вы лишитесь мудрости, накопленной программистами за десятилетия.
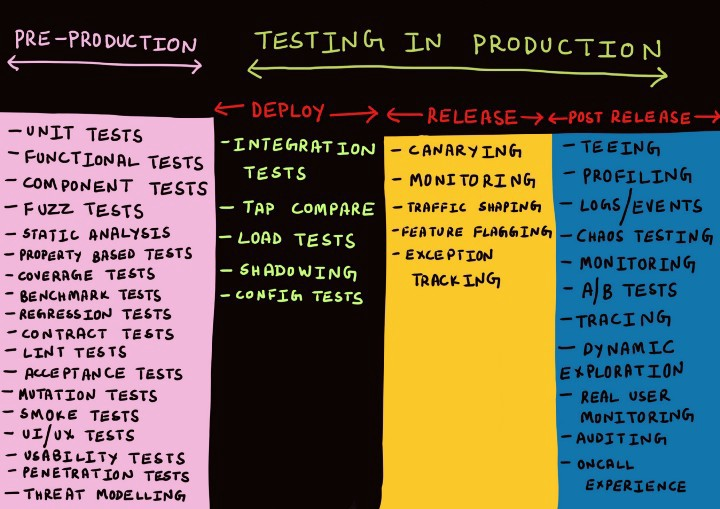
️2.1 Расширьте свой арсенал тестирования: не ограничивайтесь модульными тестами и пирамидой тестирования
Что сделать. Хотя концепции пирамиды тестирования уже 10 лет, эта прекрасная и актуальная модель предлагает три типа тестов и оказывает влияние на стратегию тестирования большинства разработчиков. Однако в тени пирамиды развилось немало других замечательных методик. Учитывая драматические изменения, которые мы наблюдали за последние 10 лет (микросервисы, облака, внесерверная обработка данных), возможно ли такое, что всего одна, довольно старая модель будет удовлетворять всем типам приложений? Не должно ли сообщество тестировщиков приветствовать новые методики тестирования?
Не поймите меня неправильно: в 2019-м пирамида тестирования, TDD и модульные тесты всё ещё остаются мощными методиками, которые, вероятно, лучше всего подходят для многих приложений. Но, как и любая другая модель, несмотря на свою пользу, иногда они могут ошибаться. Возьмём IoT-приложение, которая передаёт много событий в шину сообщений наподобие Kafka или RabbitMQ, которые затем попадают в хранилище, и в конце концов их запрашивает какой-то аналитический интерфейс. Целесообразно ли тратить половину бюджета тестирования на создание модульных тестов, проверяющих приложение, которое заточено под интеграцию и почти не содержит логики? Чем больше разнообразие типов приложений (боты, криптография, голосовые ассистенты), тем выше шанс столкнуться со сценариями, для которых пирамида тестирования не слишком-то годится.
Пришла пора расширить ваш арсенал тестирования и познакомиться с новыми видами тестирования (ниже я предложу ряд идей) и моделями вроде пирамиды, а также сопоставить виды тестирования с реальными проблемами, возникающими перед вами («У нас сломался API, давай напишем тестирование контрактов, управляемых клиентами!» (consumer-driven contracts)). Диверсифицируйте свои тесты словно инвестор, создающий портфолио на основе анализа рисков: оцените, где могут возникнуть проблемы, и решите, какие меры могут снизить риски.
Предостережение: аргумент с TDD в мире ПО обретает типичный фальшиво-дихотомичный образ. Одни проповедуют использовать TDD повсеместно, другие считают это кознями дьявола. Ошибаются все, кто занимают абсолютистские точки зрения.
В противном случае. Вы упустите некоторые инструменты с превосходным ROI, вроде Fuzz, линтинга и мутаций, которые докажут свою ценность за 10 минут.
️Пример:
2.2 Компонентное тестирование может оказаться вашим лучшим решением
Что сделать. Каждый модульный тест покрывает небольшую часть приложения, а покрыть его целиком сложно. При этом сквозное тестирование охватывает большую часть приложения, но работает медленнее и неустойчиво. Почему бы не найти компромиссное решение и не написать тесты, которые крупнее модульных, но меньше сквозных? Компонентное тестирование — это недооценённый бриллиант. Эти тесты взяли всё лучшее от двух миров: приличную производительность и возможность применения TDD-паттернов, а также широкое тестовое покрытие.
Компонентные тесты сосредоточены на микросервисном «модуле», они работают через API, не имитируют то, что принадлежит самому микросервису (например, настоящую базу данных, или хотя бы её in-memory версию), однако создают заглушки для всего внешнего, скажем, вызовы других микросерисов. Таким образом мы тестируем то, что развернули, работаем с приложением по принципу «от внешнего к внутреннему», за разумное время обретая уверенность в качестве продукта.
В противном случае. Вы можете потратить много дней на создание модульных тестов, а потом обнаружить, что достигли покрытия системы всего в 20%.

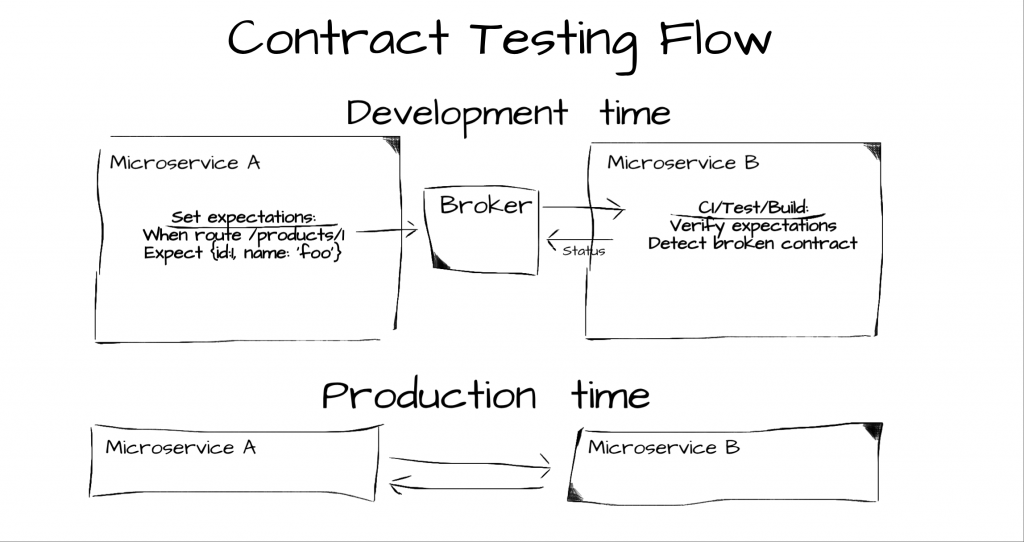
️2.3 Удостоверьтесь, что новые релизы не ломают использование API
Что сделать. У вашего микросервиса много клиентов, и ради совместимости вы запускаете много версий (чтобы все были счастливы). Однажды вы меняете какое-нибудь поле, и бах! — один из важных клиентов, для которого это поле играло важную роль, разозлился. Это «Уловка-22» в мире интеграции: на серверной стороне очень трудно учесть все ожидания многочисленных клиентов, при этом клиенты не могут выполнять тестирование, потому что сервер управляет датами релизов. Для формализации этого процесса с помощью очень деструктивного подхода придумали управляемые клиентами контракты (consumer-driven contracts) и фреймворк PACT: план тестирования сервера определяется не им самим, а… клиентами! PACT может записывать клиентские ожидания и складывать их в общее хранилище — «брокер», откуда сервер может их брать и запускать при каждой сборке. С помощью PACT-библиотеки сервер может определять расторгнутые контракты — не оправдавшиеся ожидания клиентов. Таким образом, все несовпадения API между сервером и клиентом обнаруживаются на ранних стадиях сборки или CI, что может спасти вас от сильного разочарования.
В противном случае. Альтернатива — изнурительное ручное тестирование или страхи при деплое.
2.4 Тестируйте промежуточное ПО изолированно
Что сделать. Многие избегают тестирования промежуточного ПО, поскольку оно составляет лишь небольшую часть системы и требует работающего Express-сервера. Всё это заблуждения. Промежуточное ПО невелико, но влияет на все запросы или большую их часть, и его можно легко тестировать как чистые функции, получающие JS-объекты {req, res}. Чтобы протестировать такую промежуточную функцию, нужно вызвать её и отследить (например, с помощью Sinon) взаимодействия с объектами {req, res}, чтобы удостовериться, что они всё делают правильно. Библиотека node-mock-http идёт ещё дальше и индексирует объекты {req, res} с отслеживанием их поведения. Например, она может проверить, соответствует ли ожиданиям HTTP-статус, присвоенный res-объекту (см. пример ниже).
В противном случае. Баг в Express-ПО === баг во всех запросах или большинстве из них.
//the middleware we want to test
const unitUnderTest = require('./middleware')
const httpMocks = require('node-mocks-http');
//Jest syntax, equivalent to describe() & it() in Mocha
test('A request without authentication header, should return http status 403', () => {
const request = httpMocks.createRequest({
method: 'GET',
url: '/user/42',
headers: {
authentication: ''
}
});
const response = httpMocks.createResponse();
unitUnderTest(request, response);
expect(response.statusCode).toBe(403);
});
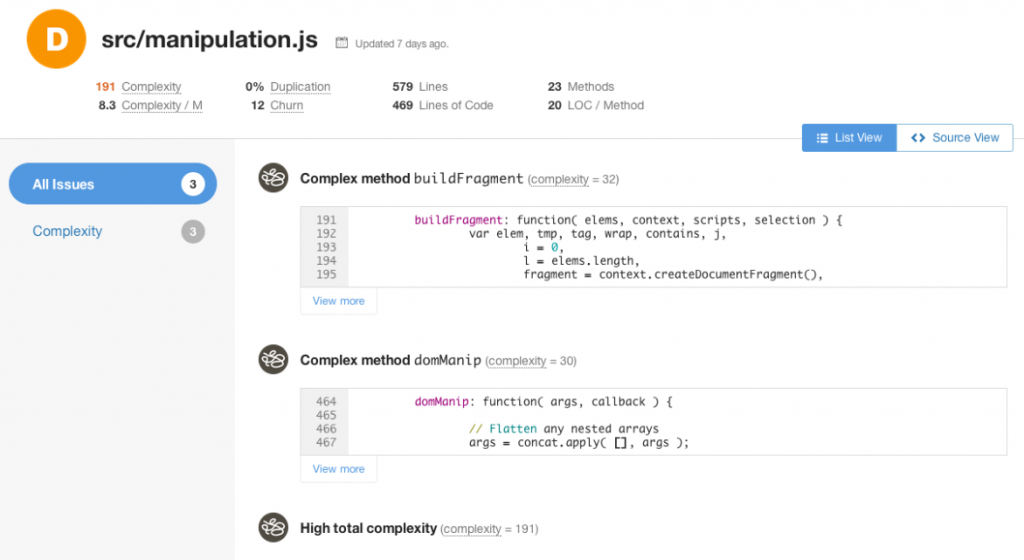
2.5 Оценивайте и рефакторьте с помощью инструментов статического анализа
Что сделать. Использование инструментов статического анализа даёт объективные способы улучшения качества кода и позволяет поддерживать его в пригодном для сопровождения виде. Можете добавить в CI-сборку инструменты статического анализа, чтобы они прерывали работу при обнаружении недостатков в коде. Главное преимущество таких инструментов перед обычным линтингом заключается в возможности оценки качества с точки зрения многочисленных файлов (например, для определения дублей), для выполнения сложного анализа (например, оценки сложности кода), а также для отслеживания истории и развития проблем в коде. Могу порекомендовать Sonarqube (2600+ звёзд) и Code Climate (1500+ звёзд). Автор: Keith Holliday
В противном случае. При плохом коде у вас всегда будут проблемы с багами и производительностью, которые не смогут решить даже шикарные новые библиотеки и самые лучшие фичи.
2.6 Проверьте, готовы ли вы к хаосу Node
Что сделать. Как ни странно, большинство тестов программного обеспечения касаются только логики и данных. Но самые худшие проблемы (которые действительно трудно минимизировать) случаются с инфраструктурой. Например, вы когда-либо проверяли, что происходит при перегрузке памяти процесса? Или при умирании сервера или процесса? А ваша система мониторинга может понять, что API стал работать на 50% медленнее? Чтобы проверить и минимизировать подобные проблемы, в Netflix разработали концепцию хаос-инжиниринга (Chaos Engineering). Её цель: обеспечить нашу осведомленность, а также предоставить фреймворки и инструменты для тестирования устойчивости наших приложений к хаотичным ситуациям. Например, один из знаменитых инструментов Netflix, chaos monkey, случайным образом убивает серверы, чтобы проверить, продолжает ли сервис обслуживать пользователей, а не полагается на какой-то один сервер (есть также версия Kubernetes под названием kube-monkey, которая убивает поды). Все эти инструменты работают на уровне хостинга или платформы, но вы можете захотеть сгенерировать и протестировать чистый хаос. Например, проверить, как ваш Node-процесс справляется с не пойманными ошибками, необработанными отказами промисов, с перегруженной памятью v8 с лимитом в 1,7 Гб, или остаётся ли UX удовлетворительным, если цикл событий часто блокируется? Я написал node-chaos (альфа-версия), который поможет вам в тестировании всех хаотических проблем, связанн
