
Искусственный интеллект впервые в мире победил чемпиона по го
Это был AlphaGo от компании Google
Подразделение DeepMind компании Google заявило о том, что искусственный интеллект компании смог победить европейского чемпиона по настольной игре го. Система AlphaGo обыграла человека в 5 из 5 игр. До этого го была одной из немногих логических игр, профессиональные игроки в которую выигрывали у компьютеров.
Одним из наглядных показателей развития искусственного интеллекта является победа в логических играх. ИИ может обыграть чемпиона по какой-либо логической игре, что продемонстрирует, что алгоритм умеет решать задачу лучше человека. С годами число покорённых игр растёт: сдались и шашки, и шахматы. В 1996 году алгоритм впервые выиграл у лучшего игрока в шахматы: это был поединок компьютера Deep Blue против Каспарова. А уже в 2005 году человек в последний раз выиграл у лучшего алгоритма. С тех пор компьютерные программы могут обыграть любого игрока в шахматы. Поддаются и другие игры: айбиэмовский Watson играл и выигрывал в Jeopardy, а в 2014 году искусственный интеллект поискового гиганта Google самостоятельно освоил 49 старых аркадных игр Atari.
Но некоторые игры ещё не покорены. Одной из невзятых долгое время оставалась го. Это настольная игра, зародившаяся в Древнем Китае несколько тысяч лет назад. Прямоугольная доска 19×19 линий заполняется чёрными и белыми камнями. Перед каждым из игроков стоит задача отгородить на игровой доске камнями территорию большего размера, чем противник. Игра обладает несколькими правилами, которые осложняли создание эффективной системы искусственного интеллекта для победы над человеком. К примеру, возможных позиций камней на стандартной доске более, чем в гугол (10100) раз больше, чем в шахматах. Число возможных позиций больше, чем атомов во Вселенной. Просто так просчитать все ходы невозможно, и пока что лучшие компьютерные системы играют на уровне любителей.
Многие ходы в го диктуются простой интуицией, а подобное трудно уложить в алгоритм. Именно эта сложность привлекает внимание специалистов по искусственному интеллекту. DeepMind — это разработчик систем искусственного интеллекта, которого компания Google приобрела в 2014 году. В DeepMind смогли создать программное обеспечение, которое в состоянии обыграть чемпионов.
Составление дерева поиска здесь не подходит, поэтому была создана система AlphaGo. Она основана на поиске Монте-Карло и глубоких нейросетях. Нейросети пропускают описание состояния доски го через 12 различных слоёв, состоящих из миллионов нейроподобных соединений. Одна из сетей, «сеть политики», выбирает следующий ход. Другая, «сеть ценности», предсказывает победителя.
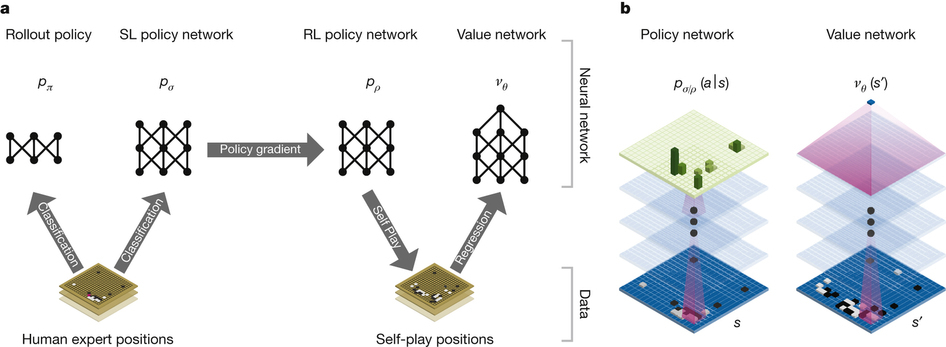
Нейросеть обучали на 30 млн ходов партий реальных людей. Был достигнут результат корректного предсказания следующего хода в 57% случаев. До AlphaGo лучший результат составлял 44%. Но целью была победа, а не просто подражание человеку. AlphaGo научилась этому путём тысяч партий между собственными нейросетями и с помощью улучшения соединений в процессе обучения с подкреплением. При этом весь процесс требовал немалой вычислительной мощи, поэтому всё запускалось в облаке Google Cloud Platform.
Сначала полученный продукт протестировали с другими лучшими решениями. AlphaGo выиграла 499 матчей из 500. Затем были приглашёны судья из Британской федерации го, редактор журнала Nature и трёхкратный чемпион Европы Фань Хуэй. Этот профессиональный игрок занимается азиатской настольной игрой го с 12 лет. Матч за закрытыми дверями проводился в лондонском офисе Google в октябре прошлого года.
Чтобы запустить алгоритм, потребовался вычислительный кластер из 170 видеокарт и 1200 процессоров (вероятно, имелись в виду отдельные ядра). Фань с удивлением обнаружил, что он проиграл компьютеру в первой игре. Чемпион списал поражение на собственный неагрессивный стиль. Он посчитал, что это была лишь разминка, и начал играть агрессивнее. Но Фань проиграл все из четырёх последующих партий. Алгоритм AlphaGo выиграл в пяти из пяти игр.
Как говорят в Google, это первый случай, когда программа смогла победить профессионального игрока в го. Следующим логическим шагом является матч в Сеуле в марте против легендарного корейского го-профессионала Ли Седоля — лучшего игрока в го за последнее десятилетие. Для этого матча производительность системы улучшат, чтобы её можно было запускать на более скромном оборудовании.
В го играют десятки миллионов человек по всему миру. Постепенное покорение ещё одной логической игры — это важно. Но также интересно, что AlphaGo не была создана с помощью заданных вручную правил. Выигрывать помогло машинное обучение.
В Google надеются использовать полученный опыт для решения проблем реального мира. Факт использования методов общего назначения означает, что подобные алгоритмы смогут найти применение во многих системах: от климатического моделирования и анализа заболеваний до торговли акциями на бирже.
В среду результаты исследования были опубликованы в научном журнале Nature.
Подобной разработкой занимаются и в Facebook. Марк Цукерберг сообщил в среду, что его исследователи близки к покорению китайской игры. Цукерберг в буквальном смысле пристально следит за процессом разработки: автор проекта сидит в шести метрах от стола исполнительного директора Facebook.
Исследование Facebook: arXiv:1511.06410 [cs.LG]
Geektimes прочитано 10384 раза
