Mozilla развивает свою систему распознавания речи
В рамках проекта по развитию собственной открытой системы распознавания речи компания Mozilla ввела в строй сервис Common Voice, нацеленный на организацию совместной работы по накоплению базы голосовых шаблонов, учитывающей всё разнообразие голосов и манер речи. Пользователям предлагается озвучить выводимые на экран фразы или поучаствовать в оценке качества данных, добавленных другими пользователями.
Целью инициативы является накопление 10 тысяч часов c записями различного произнесения типовых фраз человеческой речи. На основе полученных данных будет сформирована открытая и бесплатная база данных, которую без ограничений можно будет использовать в системах машинного обучения и в исследовательских проектах. В текущем виде база Common Voice формируется только для английского языка, но в дальнейшем планируется запустить аналогичные проекты по сбору голосовой информации и для других языков.
В настоящее время исследователям и разработчикам доступны только ограниченные наборы, а стоимость полноценных коллекций голосовых выборок исчисляется десятками тысяч долларов, что сильно тормозит независимые исследования в области распознавание речи. Например, накопленная база может оказаться полезной для других открытых проектов в области распознавания речи, таких как ххhttps://cmusphinx.github.io/ Sphinx]], Kaldi, VoxForge, ISIP, HTK и Julius.
Сервис запущен как дополнение к более глобальному проекту, в рамках которого планируется выпустить полностью свободную систему распознавания речи, которая использует современные методы машинного обучения. В отличие от уже имеющихся решений проект Mozilla подразумевает построение и открытие качественной модели для систем машинного обучения, а также реализацию расширенных алгоритмов для более точного выделения речи при наличии постороннего шума. В основе проекта Mozilla лежит движок DeepSpeech, реализованный с использованием открытой компанией Google платформы машинного обучения TensorFlow. DeepSpeech реализует в коде одноимённую архитектуру распознавания речи, предложенную исследователями из компании Baidu.
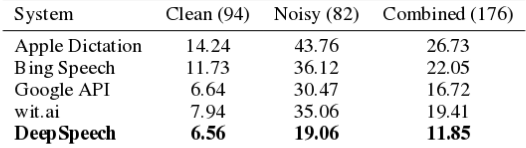
Система DeepSpeech значительно проще традиционных систем и при этом обеспечивает более высокое качество распознавания при наличии постороннего шума. Из достоинств также отмечается отсутствие необходимости подключения отдельных компонентов для моделирования различных отклонений, таких как шум, эхо и особенности речи. DeepSpeech не использует традиционные акустические модели и концепцию фонем, вместо которых предлагается использовать хорошо оптимизированную систему машинного обучения на основе нейронной сети. По уровню ошибок DeepSpeech демонстрирует заметно лучшие результаты, по сравнению с коммерческими системами Google Speech, Bing Speech и Apple Dictatio.
Обратной стороной DeepSpeech является то, что для получения качественного распознавания данная архитектура требует значительно большего объёма данных для осуществления обучения и их разнородного качества (недостаточно просто диктовки фраз в студии, нужны варианты в реальных условиях с разными голосами, шумами, фоновой речью, акцентом и т.п.). Уже существующие открытые проекты, такие как LibriSpeech, уже накопили базу в примерно 1 тысячу часов, в то время как для достижения приемлемого уровня ошибок в DeepSpeech требуется как минимум 10 тысяч часов. Кроме того, данные LibriSpeech в основном отражают только каноническое произношение носителем языка, в то время как проект Mozilla пытается охватить любые произношения и обеспечить хороший уровень распознавания английского языка не только для американцев и англичан.
Для использования распознавания речи в online-приложениях и на мобильных устройствах Mozilla разрабатывает систему Pipsqueak, представляющую собой серверное решение на основе архитектуры DeepSpeech. Для взаимодействия с движком планируется использовать Web Speech API. При этом движок будет достаточно легковесным и способным работать даже на портативных системах, таких как Raspberry Pi 3.
© OpenNet
