Как работает чудо-нейросеть DALL·E 2, которая генерирует любое изображение по тексту. Объясняем подробно
Как научить неживое делать что-то глубоко человеческое?
В начале 2022 года компания OpenAI (основана в том числе Илоном Маском) представила систему на базе искусственного интеллекта DALL·E 2, которая создаёт изображения из описания. И чем подробнее будет написан запрос, тем лучше проявится картинка.
В народе её называют «нейросеть», но по своей сути и составу это готовый продукт, основанный на нескольких предыдущих разработках OpenAI.
Картинка на выходе не просто соответствует запросу, а пугающе точно воспроизводит его контекст.
Если загуглите тему в рунете или зайдёте в зарубежные источники, почти точно не поймёте даже самую простую схему работы этого алгоритма. Я перерыл сотни источников и сделал доступный каждому мини-гайд по механизмам DALL·E 2, которые из фразы делают произведения искусства.
Ниже я подробно на трёх уровнях — абстрактном, базовом и поэтапном — объясню, как создатели «убийцы художников» (не совсем убийцы) разработали магический алгоритм.
Содержание:
Сначала посмотрите, на что способен DALL·E 2

Красивая женщина смотрит в старое окно, покрытое каплями дождя.
Туманно, солнце светит ей на лицо. Вид с улицы


Женщина облакачивается на металлическую дверь, жёсткие тени деревьев падают ей на лицо.
Фото высокого качества


Поникший мужчина сидит в спальне. Яркий солнечный свет

Фотография склада с одним идеально сформированным облаком, плавающим в центре комнаты.
Освещение одним прожектором, снято на Canon 5D Mark II

Соник нашёл кольцо всевластия


Реалистичное фото хайтек-Санкт-Петербурга
из далёкого будущего с красивым закатом и дождём

"Снимок как Дарт Вейдер ждет в очереди в Макдональдсе в 90-х годах"

Мальчик играет в ретро-консоль перед старым телевизором

Портрет мужчины с лицом совы

Матрёшка смотрит на саму себя в зеркале

Лара Крофт в Санкт-Петербурге на закате


Молодая красивая девушка в жёлтом кимоно стоит в тропической теплице.
Снято на зеркальную камеру

Молодая красивая девушка в жёлтом кимоно в скафандре стоит в тропической теплице.
Снято на зеркальную камеру


Молодая красивая девушка в жёлтом кимоно с совой и перьями в волосах
стоит в тропической теплице. Снято на зеркальную камеру

Молодая красивая девушка в жёлтом кимоно стоит в тропической теплице.
Снято на плёночную мыльницу со вспышкой

Молодой парень в жёлтом кимоно стоит в тропической теплице.
Снято на зеркальную камеру

Молодой парень в футуристичных очках в жёлтом кимоно стоит в тропической теплице.
Снято на зеркальную камеру

Пожилая женщина в очках с венком на голове в жёлтом кимоно стоит в тропической теплице.
Снято на зеркальную камеру

Развалины деревянного дома посреди пустыни

Ученый на работе тратит время в соцсетях


iPhone найден на месте раскопок

iPhone, нарисованный в стиле Ханса Руди Гигера (дизайнер Чужого)

Реалистичный портрет Карла Маркса,
который пьёт кофе из Старбакса и смотрит в iPhone

Макрофото геймпада Xbox, покрытого крошками от Читоса. Студийное освещение

Девушка, одетая в чёрное, в дождливом Токио с прозрачным зонтиком.
Вид сзади, глубина резкости, реализм, объектив 200 мм, 4К

Альберт Эйнштейн в Зверополисе (2016)

Иконка приложения знакомств для престарелых демонов

Реалистичный Марио ест спагетти

Джабба Хатт в Золотых девочках

Портретное фото Гомера Симпсона в виде реального человека

Винтажное фото Марио и Луиджи, выступающих перед массами, 1942 год

Апокалипсис красоты, картина эпохи Возрождения

Древние крики с раскатистым эхо

Картина Босха о том, как кто-то улыбается и делает селфи, когда вокруг него апокалипсис"

Зомби в режиме Бога во время Апокалипсиса с расколотой Луной и метеорами, падающими с неба


3D-рендер конфет M&M's в 4K

Дьявол носит Prada (2006), постер

"Золотая статуя дьявола из Империи Jove (Eve Online)



Портал в Рай

Новое блюдо KFC: только кожица

Бруталистская современная вилла под марокканским влиянием.
Бетонные стены, с большими деревянными панелями в качестве акцента, сад с бассейном.
Пасмурное освещение, архитектура, 4K, 14 мм, f/2.5, ISO 300

Марокканская вилла, бетонные стены, большой сад с бассейном.
Пасмурное освещение, архитектура, 4K, 14 мм, f/2.5, ISO 300


Оригинальная картина маслом Рембрандта о том, что ученый представляет
первый запечатлённый НЛО на конгрессе в Манхэттене.
Люди с трепетом смотрят на огромный НЛО перед ними


Ученый раскрывает первый в мире пойманный НЛО на научном конгрессе в Манхэттене
Люди с трепетом смотрят на огромный черный матовый НЛО перед ними.
50 мм, Canon EOS, информационное агенство Reuters
Авиационный ангар, инженеры, поднимающиеся по лестнице, захваченные американскими военными, 14 мм, канон EOS, f1.8, кинематографическое капризное освещение, Reuters

Астронавт верхом на лошади катается по Луне на фоне звёздного неба

Вывеска Макдональдса на раскопках Помпеи


Суп с порталом в другой мир

Детализированное фото обезьяны

Группа роботов, устраивающих пикник на природе. Масло, стиль Саймона Сталенхага
Как видите, поле для творчество в вопросе объектов кажется безграничным, ровно как и стили, в которых можно сделать запрос. Фотореализм, стиль определённого художника, эпохи, направления живописи развязывают руки.
Более того, DALL·E 2 умеет изменять и достраивать элементы картинки, а ещё добавлять новые детали в готовую сцену.
Ниже разберёмся, каким образом эта магия происходит на трёх уровнях глубины. А в конце взглянем на проблемы, которые пока остаются.
Уровень 1. Самое простое объяснение

DALL·E 2 состоит из трёх больших частей, базу для которых разработали в Google, но «собрали» в OpenAI.
Первая нейросеть «читает» текст и рисует «черновик» будущего изображения.
Вторая нейросеть превращает «черновик» в маленькое конечное изображение.
Третья нейросеть увеличивает эту маленькую картинку в 16 раз, добавляя необходимые детали.
Готово!
Поэтапно это происходит так:
1. Первая нейросеть называется CLIP, она переводит наш написанный (человеческий) текст в компьютерный язык в виде цифр.
2. Далее CLIP превращает этот набор цифр в таблицу с другими цифрами. Такая таблица играет роль «наброска» или «скелета», по которому создаётся конечное изображение. Чтобы всё сработало, CLIP тренировали на 600 миллионах картинок и подписям к ним.
3. «Черновик» переходит во вторую нейросеть под названием GLIDE.
4. Вторая нейросеть GLIDE берёт первоначальный компьютерный текст из пункта 1 и полученную схему из пункта 2, совмещает данные с них. На основе такого микса она создаёт серый зернистый квадрат, из которого постепенно убирает зерно и тем самым проявляет картинку в плохом качестве. Этот метод проявки называется «применение Диффузной модели».
5. Третья нейросеть увеличивает качество картинки в 16 раз и показывает нам финальный результат.
Но эти этапы озвучены весьма упрощённо: на самом деле в DALL·E 2 работают не сами нейросети, а только их части. Например, изначально CLIP вообще не умела рисовать изображения, её задача была ровно противоположной: описывать текстом то, что она видит.
Рассмотрим эти моменты подробнее.
Уровень 2. Как всё работает вместе
Для начала небольшая справка, чтобы вы поняли текст дальше.
Вектор, text embedding, image embedding — набор цифр, который описывает каждое слово или часть изображения. В каждой нейросети он свой.Энкодер, кодировщик, encoder — нейросеть, которая шифрует человеческий текст и изображения в понятный другой нейросети язык в виде векторов.
Декодер, decoder — нейросеть, которая превращает векторы в понятный человеку язык или изображение.
Трансформер — общее название для энкодеров и декодеров.
Диффузная модель — метод проявки изображений из чистого шума, с помощью которого работает декодер.
Латентное пространство, prior — место, где после тренировки нейросети в ней хранятся все векторы текстов и изображений в особом, понятном ей взаимоотношении друг к другу. Представьте огромное поле, где каждый предмет лежит на правильном месте по принципу, понятному только охраннику этого места. Только это не 2D-плоскость, а состоящая из более чем 300 пространств.
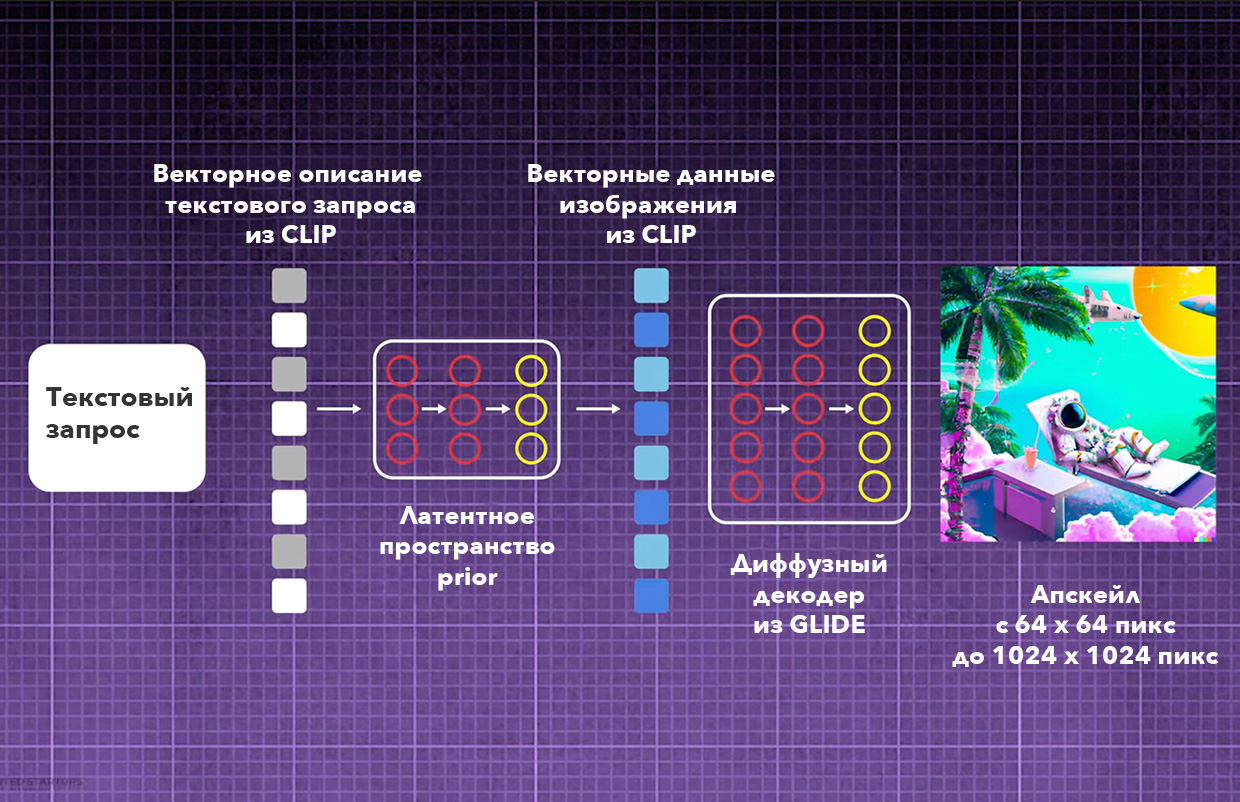
Общая структура DALL·E 2 в сухом виде звучит так:
1. Кодировщик Word2Vec превращает слова в математические векторы, которыми оперирует нейросеть CLIP.
2. Векторы отправляются в латентное пространство. Это такое место, где все слова находятся на разном расстоянии друг от друга в зависимости от своих категорий, понятных только нейросети. В DALL·E 2 это место называют prior.
2. В пространстве prior векторы текста используются, чтобы подобрать векторы будущего изображения. Этим тоже занимается часть нейросети CLIP.
3. Диффузная модель берёт текстовые и визуальные векторы и выдаёт картинку в разрешении 64×64.
4. Финальное изображение масштабируется до 1024×1024 пикселей с помощью двух дополнительных диффузных моделей.
По своей сути DALL·E 2 это не нейросеть, а собранный из разных программ продукт, в профессиональной среде его называют генеративной моделью. Условно он работает на базе двух ранних продуктов компании-разработчика OpenAI: CLIP и GLIDE. В конце применяется третья нейросеть для увеличения разрешения картинки.
Взяты именно элементы из CLIP и GLIDE, а не программы целиком. У первой заимствовали метод понимания контекста, у второй качество его визуализации.
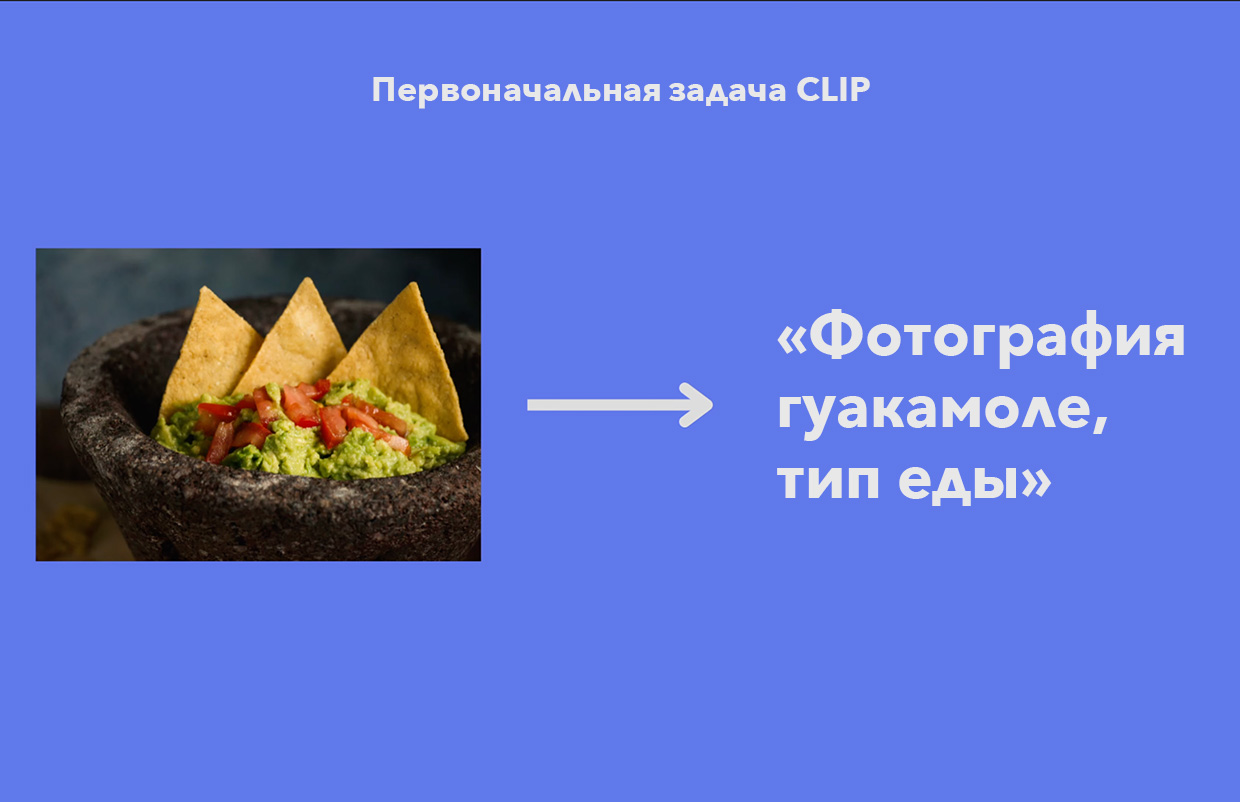
Изначально нейросеть CLIP обучена правильно описывать то, что происходит на картинке — то есть заниматься противоположной DALL·E 2 задачей. CLIP тренировали таким образом: давали несколько пар [пиксельное изображение — текст], нейросеть переводила их в две сопоставимые метрики в виде чисел, которые затем соотносились друг с другом по степени похожести.
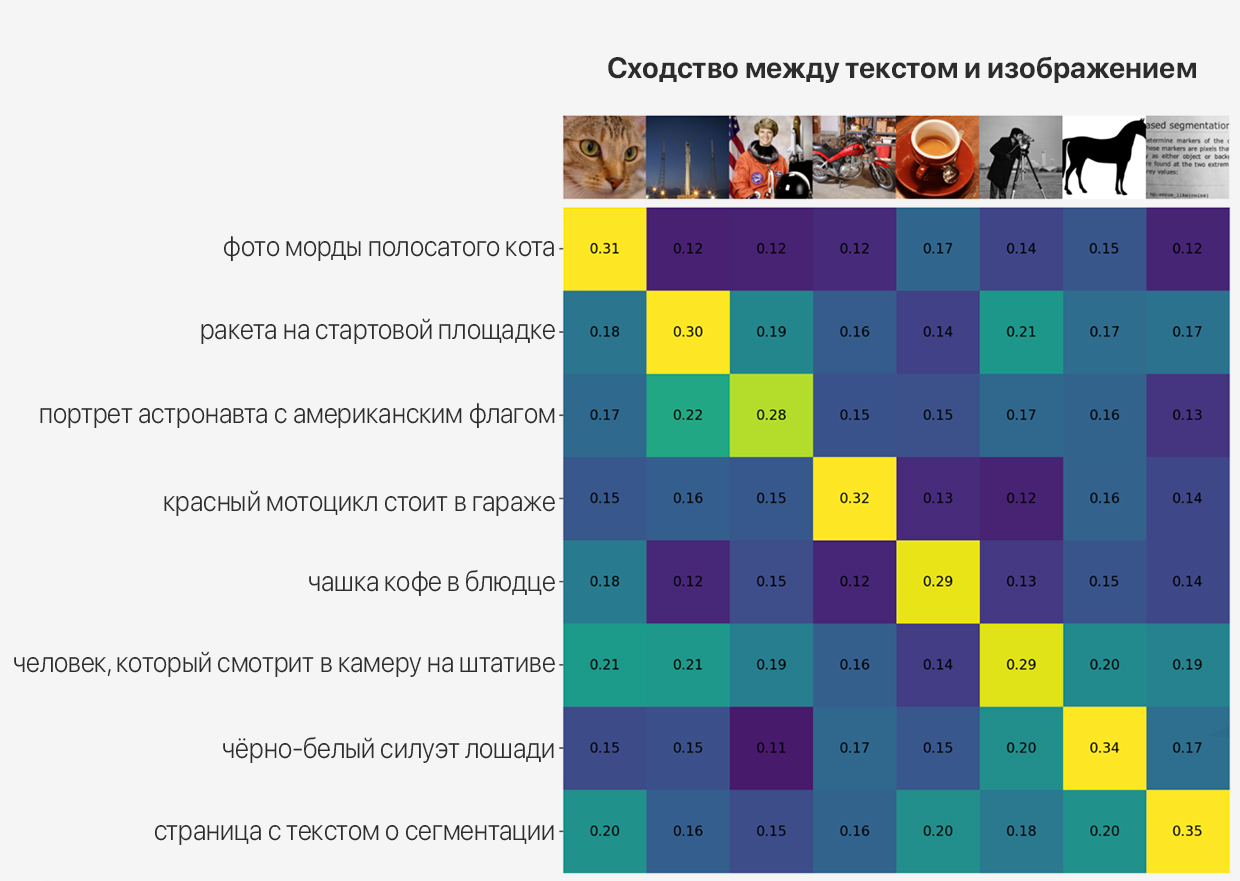
Схема тренировки CLIP на базе схожести, а не точного поиска пар
И тем самым CLIP училась подбирать описание к изображению. Все связи между словами хранятся в виде векторов внутри Латентного пространства. Векторами они являются, потому что находятся на разном расстоянии друг от друга и в зависимости от скрытой категории эта связь то дальше, то ближе.
Это умение чувствовать контекст пригодилось в DALL·E 2.
Представьте рисунок домика с деревом и солнцем. То, каким вы представили рисунок, и есть результат CLIP.
Вы будете ощущать детали этого видения, но не сможете вообразить мелкие элементы моментально.
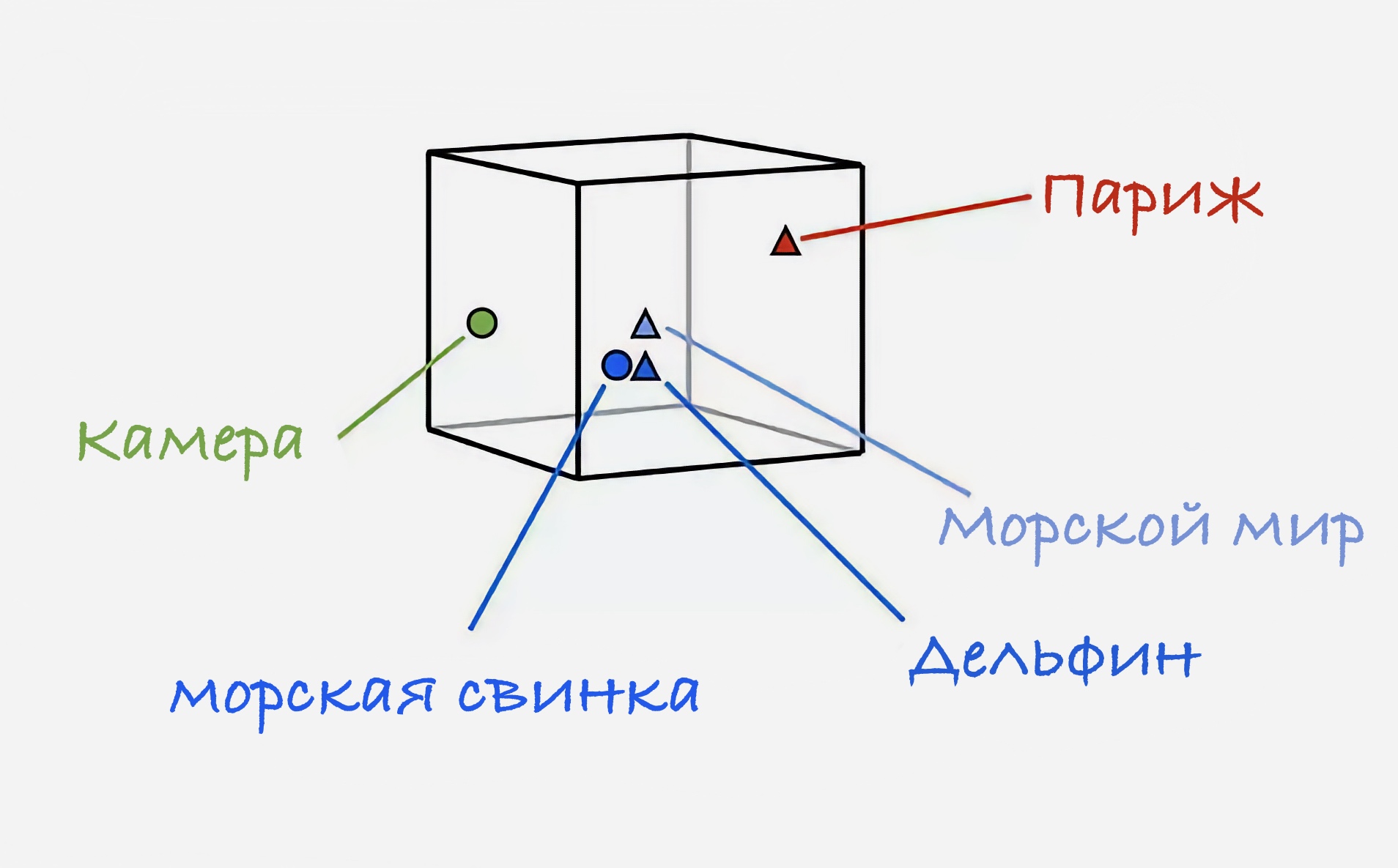
Так схематично выглядит латентное пространство
CLIP превращает текст в text embedding — цифровое описание букв. Но это не шифрование лексики вроде двоичного кода, а кодирование слов по их смыслу в виде токенов и векторов. Во время тренировки они ранжируются более чем в 300 категориях, точного состава и ранжирования которого разработчики не знают, поскольку CLIP сформировала их сама.

Схема векторизации слов
А вот GLIDE преобразует текст в изображение. Прямо как DALL·E 2, но с меньшим количеством шагов и меньшей точностью. Эта нейросеть вполне мог называется DALL·E 1,5, если бы OpenAI хотела давать громкое название каждой своей генеративной модели.
Метод работы GLIDE формируют тот самый реализм, который всех шокирует. Но не потому что он такой умный, а потому что у него уже есть «скелет», созданный алгоритмами CLIP.

Именно GLIDE може менять части изображения с учётом контекста
Закажите профессиональному художнику нарисовать то, что вы представили. Результат и будет работой GLIDE.
Художник отрисует каждый штрих в том стиле, в котором вы попросите, и при этом сделает это точно, потому что уже обычен технике рисования.
GLIDE «рисует» финальное изображение через Диффузную модель — это такой механизм, когда берётся серый квадрат, состоящий из пиксельного шума, и из него поэтапно убирается шум, пока не останется чёткая картинка с нужным содержимым.

Обучение диффузной модели
Как работает диффузная модель
Вы слышали слово диффузия на уроках физики: если брызнуть в воздух духи, их молекулы сначала будут сконцентрированы и сильно ощутимы, а затем постепенно равномерно смешаются с молекулами воздуха, после чего появится новая ароматная субстанция из воздуха и духов. Равномерное распределение молекул разного состава называется диффузией.
По тому же принципу тренировали GLIDE. Его обучали постепенно добавлять шум в виде пикселей к чётким фотографиями, картинам, постерам, а затем заставляли обернуть процедуру вспять.
Диффузия одних молекул в другие в воздухе
В конце специальная программа апскейла «наращивает» детализацию, в два этапа разбивая каждый пиксель на четыре, а затем ещё раз на четыре.
Уровень 3. Разбор каждого шага по отдельности
0. Контекст, разработчики и архитектура

Некоторые изображения получаются слишком жуткими
DALL·E 2 разработана организацией OpenAI, которую основали Илон Маск и инвестор-разработчик Сэм Альтман для того, чтобы «искусственный интеллект помогал человечеству, а не уничтожил его, вырвавшись из-под контроля». Сейчас Маск продолжает выделять компании деньги, но не участвует в её управлении.
Во многом OpenAI следует своим словам. Публикует исследования, описывает процессы, не держит методы работы алгоритмов за закрытыми дверьми и даёт доступ к некоторым разработкам на GItHub.
При этом компания быстро вводит свои разработки в коммерческое поле, цикл от создания до монетизации составляет примерно полгода. Так случилось с DALL·E 2: бесплатный доступ заканчивается после 50 попыток в первом месяце и после 15 попыток в последующие.
DALL·E 2, несмотря на название, стала третьей большой генеративной моделью изображений от OpenAI.
Первой была DALL·E, второй GLIDE. Наработки из них обеих используются в DALL·E 2.
В свою очередь, первая DALL·E по структуре задействует другую генеративную модель от OpenAI под названием CLIP. Она описывает изображения текстом, используя для этого трансформер, превращающий буквенный текст в text embedding (единого русскоязычного перевода для этого термина нет), а затем в image embedding, описывающий векторный состав будущего изображения.
1. Кодирование текста в язык нейросети
Источники: блоги на Medium 1, 2 и 3
Чтобы понимать человеческий текст, DALL·E 2 использует модифицированную версию нейросети Word2Vec (разработана в Google). Иначе её называют трансформеров. Прямая задача в том, чтобы превратить слова в набор векторов, которые на следующем этапе обработает другая нейросеть (CLIP).
❗️ Техническим названием для DALL·E 2 выбрали unCLIP, поскольку он использует технологию CLIP обратным путём.
Нет сложности в том, чтобы обернуть изображение в понятный для классификации набор чисел. Достаточно задать каждому цвету степень его яркости и систематизировать его оттенок. Например, чёрный это 0.00, серый будет 0.50, а белый это 1.00. Изменяя яркость, легко натренировать нейросеть на предсказание следующего числа: когда она выдала пиксель »9», а нужно получить »10», вы просто говорите «неправильно, но близко».

Схема «разведения» слов по смыслу и вероятным связям внутри нейросети
С текстом так не получается: если систематизировать его по словарю тем же принципом, то порядковые номера по алфавиту дадут мало толка. При ошибке выбор будет ограничен между «да» или «нет». Не получится указать нейросети, что она была близко, когда вместо «кот» выдала «крот».
Со словами их связь формируется за счёт их общего контекста. Например, словам «кот» и «пёс» будут близки «домашнее животное», «кормить», «играть», «хороший» и так далее.
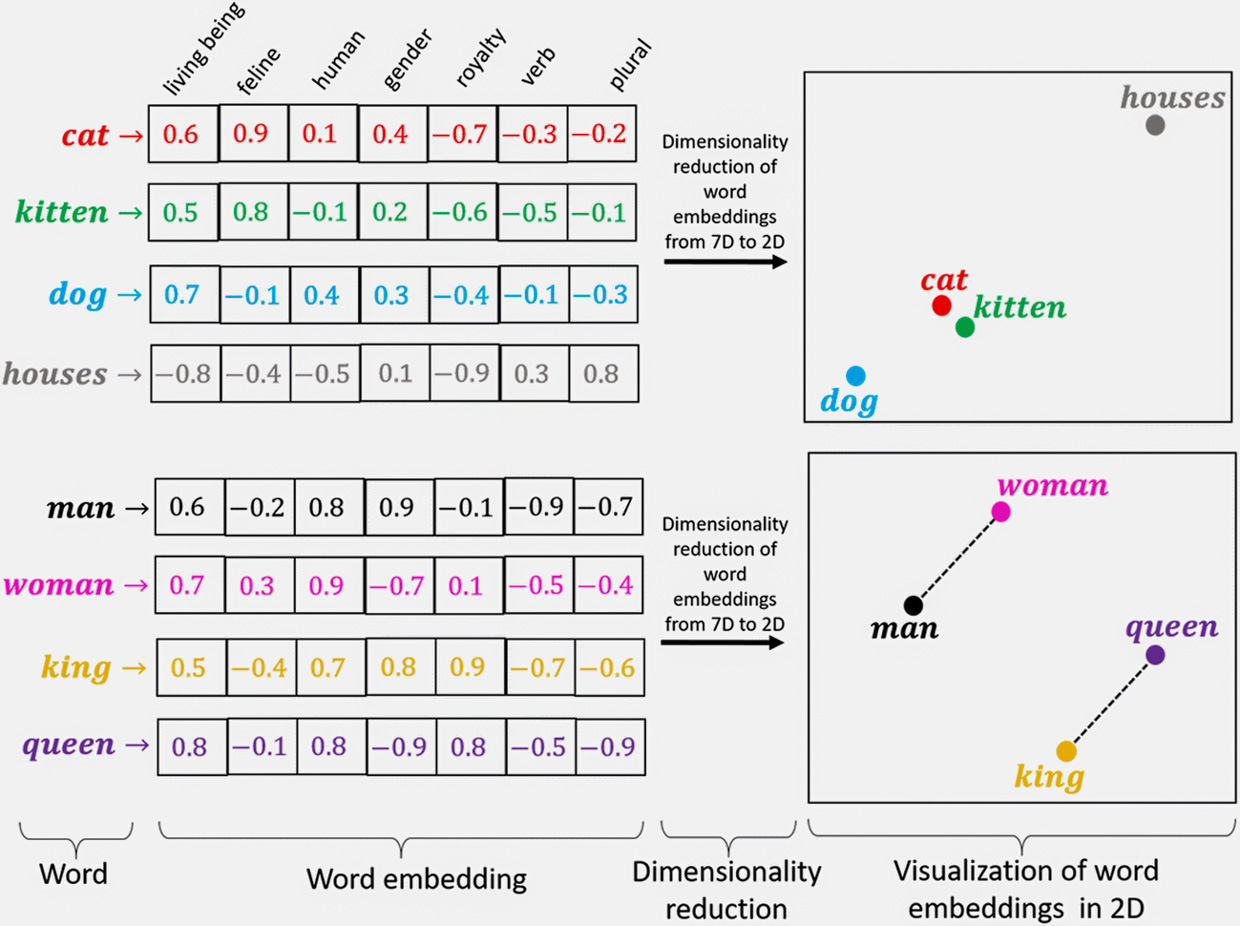
Поэтому слова превращают в векторы: набор чисел, которые, если смотреть на это визуально, выглядит как многопространственный график, где каждый объект находятся близко или далеко друг от друга.
Для тренировки этого процесса загружается огромный объём данных (вся Википедия, к примеру), который прогоняется через мощные компьютеры. Задаются правила, по которым в разных предложениях нужно подставить слово. Например, в «Хорошего вам … !» нейросеть должна найти слово «дня». Во время обучения отбирается группа слов, которые нейросеть сжимает до понятных ей групп и на выходе находит связь между этими словами, их близость друг к другу.
В итоге каждое слово выглядит как набор характеристик в понятных нейросети категориях по отношению к другим словам. Например:
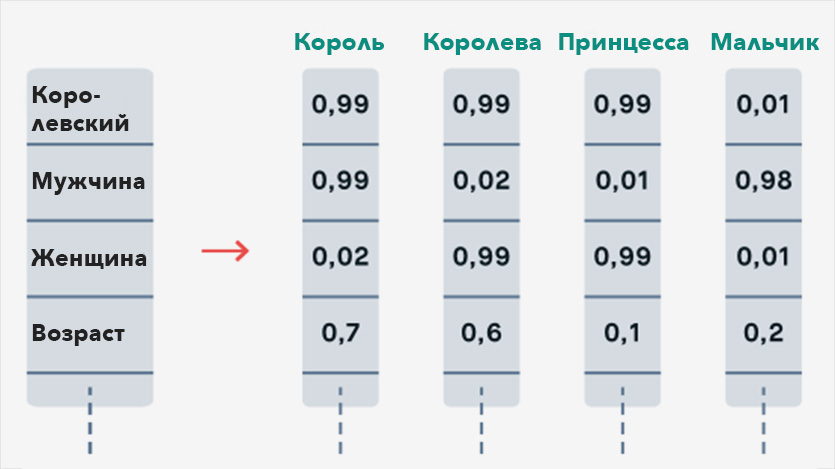
Видно, что «женщина» относится к слову «король» как [0,02] (почти никак), к слову «королева» как [0,99] (почти однозначно), к слову «принцесса» как [0,99] и к «мальчику» как [0,01].
Далее для каждого слова набор этих характеристик контекстуально сжимается. Постепенно нейросеть учится понимать, какие слова чаще всего бывают до и после другой слова — и так на пять частей речи вперёд и назад.
Энкодер натренирован на 650 миллионах изображений (данные OpenAI, раздел С).
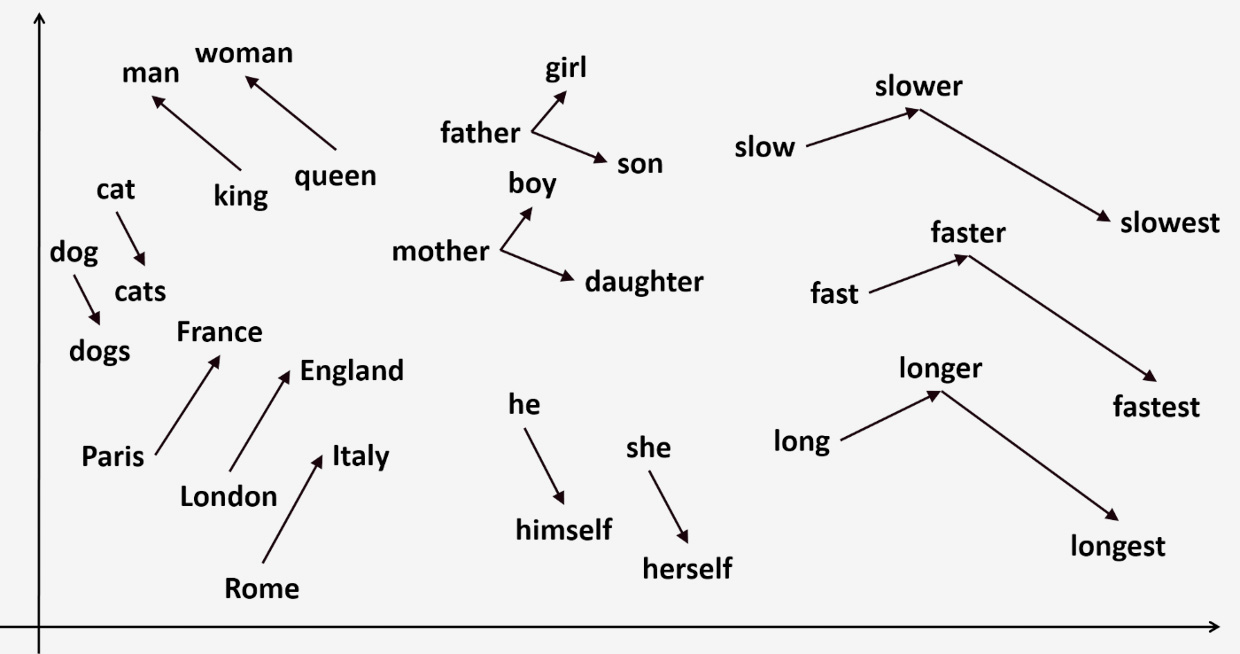
Такая глубокая связь между словами позволяет не только создавать реалистичные картинки, но и создавать их вариации. Модель работает таким образом, что умеет вычитать и складывать смысл одного слова с другим. Если сделать уравнение
«женщина» + «король» – «мужчина»,
то на выходе будет
«королева».
Визуально это можно применить к чему угодно, и нейросеть разберётся, что ей нужно сделать — не только в конечном результате, но и в разной градацией. Например, вписав:
«фото викторианского дома» + «современный дом» – «викторианский дом»
получаем поразительную трансформацию:
Но такой визуализации не было бы без других компонентов.
После тренировки текстовых векторов данные попадают в «Латентное пространство» (latent space).
2. Создание наброска картинки в Латентном Пространстве

Связанность всех векторов в латентном пространстве позволяет делать такие интересные переходы
Источники: блог одного и создателей DALLE 2, статьи на Medium 1 и 2, официальные документы алгритмов энкодеров 1, 2 и 3.
Следующим этапом DALL·E 2 создаёт «костяк» будущего изображения. Скелет, набросок, структуру — приблизительно этим занимаются составляющие нейросети CLIP.
Как упоминал ранее, сама по себе CLIP была создана для того, чтобы давать описание загруженной в неё картинке. И, на самом деле, энкодер из первого пункта, превращающий текст в text embedding, является составной частью CLIP. Потому что для умения понимать контекст изображение и и текст должны быть в едином «языковом» пространстве — пространстве векторов.
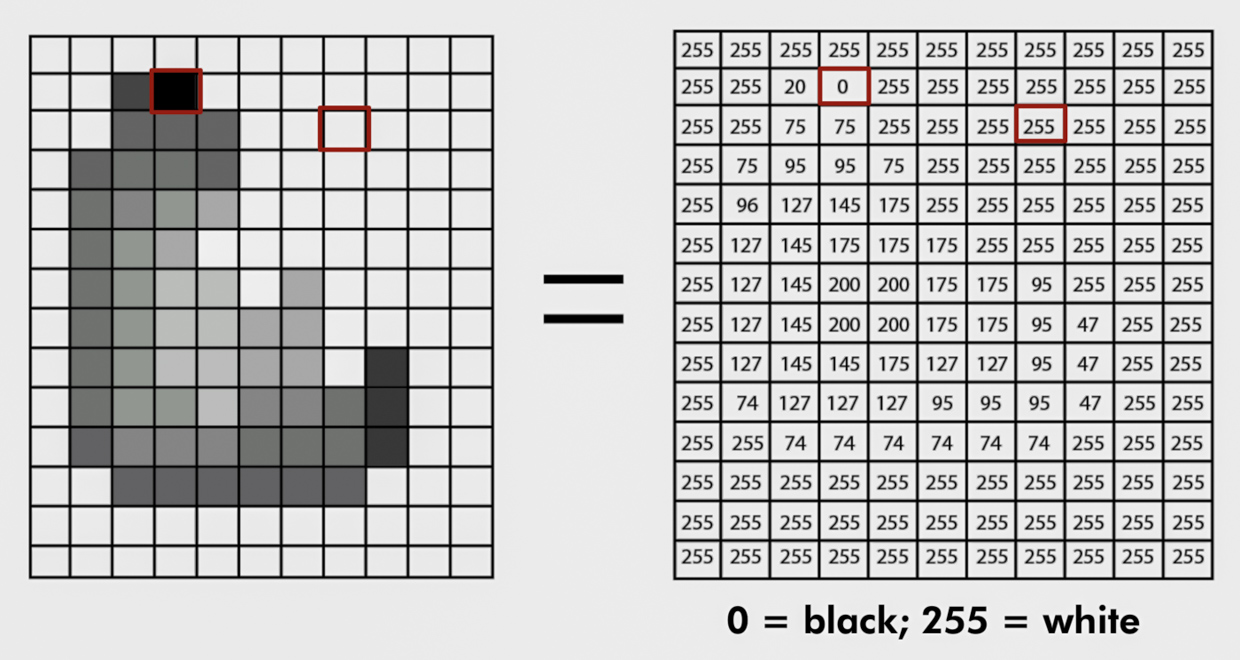
Схема тренировки CLIP следующая:
Текст переводится в text embedding методом из пункта выше. За базу взята нейросеть Word2Vec, созданная Google.
Изображение превращается в image embedding так, что оно сжимается и разбирается на зашифрованные пиксели. За базу взяты несколько разработок ResNet, тренированных на мощных компьютерах в течение трёх недель. Алгоритмы разработаны Google и модифицированы OpenAI.
Как кодируются изображения для тренировки CLIP.
Сначала картинка превращается в таблицу: каждая ячейка — число, которое формируется из девяти числовых значений красного, синего, зелёного и чёрно-белого слоя вокруг вокруг этого пикселя и его самого.
Далее нейросеть ищет объекты, на которые, вероятнее всего, нужно сделать акцент. Через длительную тренировку кодировщика она учится различить их и сопоставлять друг с другом, чтобы найти сходства. Оперируя тем самым кодом на базе пикселей.
Представьте апельсин на столе, который вполне себе хорошо видно посреди комнаты. А теперь попытайтесь разглядеть его из космоса в масштабе Млечного Пути — ничего получится, на таком уровне апельсина не существует.
По этому принципу компьютерное зрение определяет объекты в кадре. Просто превратить фотографию в таблицу из чисел будет не самым умным решением. Для тренировки достаточно ужать его до минимального разрешения и оперировать набором зашифрованных пикселей, чем сохранять все ненужные элементы.
Фактически такое закодированное изображение тоже становится «вектором» — математической интерпретацией, которая зависит от состава пикселей.
На каждом шагу тренировки CLIP получает большой и разнородный список изображений с их подписями. Они кодируются методами выше и помещаются в Латентном Пространстве.
Используя эту данные, формируются два вида пар: корректная, где изображению соотносят его верное описание, и некорректная, где изображению соотносят любое другое описание из группы.
Оба кодировщика, хоть и используют наработки Google, модифицированы OpenAI. В данном случае они натренированы находить корректные пары, чтобы создавать «тепловую карту» в виде показателей от 0.00 (не совпадают) до 1.00 (точно совпадают).
Повторяю метод, по которому тренировали CLIP
То есть главная и прорывная особенность этой системы была не в том, чтобы точно идентифицировать и запоминать пару текст-изображение, а учиться находить пару среди других, которую с наибольшей вероятностью можно было считать правильным. Это, обратно говоря, развило гибкость мышления CLIP.
CLIP как ключики к двери подбирает наиболее подходящий набор векторов-изображений под заданные векторы из текста.
☝
