Исследования Яндекса: как жизнь отражается в данных
Мы часто публикуем в блоге результаты исследований, проведённых аналитиками Яндекса. Исследования посвящены самым разным темам — из них, например, можно узнать, какие музеи пользуются у туристов наибольшей популярностью или правописание каких слов вызывает у людей больше всего вопросов. В основе любого такого рассказа лежат данные от сервисов Яндекса. Какие бывают данные и что с ними можно делать, рассказывает руководитель отдела внешних исследований Яндекса Наталия Крупенина.

руководитель отдела внешних исследований Яндекса
Данные
С тех пор как люди стали собирать и хранить по-настоящему большие массивы информации, прошло не так много лет, однако за это время многие компании успели накопить огромное количество данных. Это финансовые и медицинские организации, крупные розничные сети, IT-компании — в общем, все те, кто изначально записывал очень много информации.
У Яндекса, как всем известно, тоже есть много разных данных. Во-первых, это данные, благодаря которым работают сервисы. В основе КиноПоиска лежит огромная база фильмов, на Маркете есть описания и характеристики товаров, Карты хранят базы географических объектов, организаций и информацию о скорости движения автомобилей, Афиша знает всё о всевозможных мероприятиях. Во-вторых, это данные, которые накапливаются в результате работы людей с сервисами, — логи. В них хранятся записи о действиях пользователей: какие страницы они посещают, на какие ссылки кликают, какие поисковые запросы задают. Разумеется, вся информация в логах обезличена.
Статистика сервисов очень полезна — она даёт возможность развивать их, делая более удобными для пользователей. Скажем, Яндекс.Музыка, зная, какую музыку слушают люди, может порекомендовать им что-то новое, что они ещё не слышали и что может им понравиться.
Когда данных действительно много, проанализировав их с помощью методов машинного обучения, можно получить значительные результаты в какой-либо области. Например, опираясь на автоматический анализ данных медицинского исследования — там могут быть десятки или сотни параметров, и учесть их все не в состоянии ни один врач (и вообще любой человек), — возможно значительно улучшить методы диагностики различных болезней. Подобными задачами занимается Yandex Data Factory.
Помимо этого, с помощью анализа данных можно просто узнавать что-то новое — об окружающем мире, обществе, о том, что и как меняется. Это направление называют «дата-журналистикой». По сути это истории, созданные на основе статистики. Эти истории могут быть полезными (например, информация о том, как люди покупают автомобили), любопытными (проверка утверждения о том, что все люди в мире связаны через пять или шесть рукопожатий, с помощью данных социальной сети) или просто забавными (рассказ о том, какую музыку слушают люди в разных регионах России).
Также современные данные дают возможность хотя бы приблизительно измерить то, что раньше считалось принципиально неизмеримым и существовало только в ощущениях людей, иногда диаметрально противоположных. Мы можем посмотреть, произведения каких поэтов больше ищут в поиске — и таким образом узнать, чьё творчество оказалось более востребованным. Или проанализировать слова, в написании которых пользователи не уверены — и таким образом понять, какие правила русского языка на практике оказываются самыми сложными для его носителей.
Всё это принципиально новые возможности, которые появились только сейчас — благодаря огромному количеству данных и методов их анализа.
Принципы
Чтобы история получилась, необходимы несколько условий. Во-первых, эта история должна существовать. Десять лет назад сама возможность достоверно измерить и описать какие-то явления поражала. Достаточно было выяснить, в какое время начинает расти загруженность дорог Москвы, определить границы часов пик и рассчитать разницу между часом пик и спокойным временем — это уже было интересно. Сейчас информация о пробках больше не выглядит как увлекательный рассказ — это обыденная сводка, которая каждый час звучит в новостях наравне с прогнозом погоды. А вот если мы с помощью данных определим, например, где в дорожной системе находятся наиболее опасные участки — те, где происходит больше всего аварий, — это будет интереснее.

Во-вторых, история должна иметь отношение к реальности — если, конечно, мы хотим рассказывать о чём-то осмысленном, а не плодить нездоровые сенсации. Часто оказывается, что даже очень красивые объяснения, в которые хочется поверить, на самом деле не соответствуют действительности. Поэтому необходимо всегда и всё проверять. Допустим, мы видим сильный рост какого-то класса запросов — например, о садоводстве. За последние два года стали больше искать рассаду, саженцы, семена и подобные вещи. Очень соблазнительно подумать про кризис — мол, вот и тут его видно, людям приходится выращивать еду самостоятельно. Но выясняется, что рост есть только в абсолютных значениях, а в относительных — нет. Увеличилось количество запросов вообще, а не только о садоводстве, так что реального роста интереса нет. Красивое и очевидное объяснение объясняет несуществующий факт.
В-третьих, нужно быть уверенными, что наши данные говорят о людях, а не об особенностях того сервиса или платформы, с помощью которых их собирали. Некоторые особенности могут сильно искажать статистику. Скажем, если на главной странице Яндекса появляется подсказка, ведущая на результаты поиска по какому-то запросу, количество таких запросов резко увеличивается, и это ничего не значит. В момент активной рекламной кампании число пользователей сервиса обычно растёт — это связано не с внезапным интересом к тематике сервиса, а только с действием рекламы. Если у сервиса узкая специфическая аудитория, из его статистики нельзя делать выводы о других группах людей, и так далее.
Методы
Типов данных и методов работы с ними очень много. Здесь речь пойдёт только о поиске, поскольку он предоставляет больше всего возможностей для анализа и интерпретации. Люди задают поисковые запросы на все темы, присутствующие в повседневной жизни, — от авто до кулинарии. Благодаря этому можно узнать, из чего состоит интерес общества к каждой из этих тем и как он изменяется. В поиске так или иначе отражаются все значимые события. Перед любым праздником или крупной премьерой растёт количество запросов об этих событиях, во время сезонных эпидемий гриппа тоже виден рост. Когда появляются новые слова или понятия, появляются и запросы про них, так что можно увидеть не только момент возникновения, но и дальнейший рост популярности.

Все запросы, которые люди задают поисковой системе, записываются в лог. Каждый день Яндекс получает более 250 миллионов поисковых запросов, и каждому из них соответствует запись в логе. Кроме самого текста запроса, там есть много других сведений — дата и время, автоматически определившийся регион, техническая информация о браузере и операционной системе, уникальный идентификатор пользователя и ещё много всего. Важно отметить, что конкретного человека по этим данным идентифицировать нельзя — в них не содержится ни имён, ни логинов. Вся статистика анализируется обезличенно и обобщённо.
Самый простой способ отобрать из миллионов и миллиардов запросов те, которые относятся к той или иной теме, — например, ко снам, — выделить слова-маркеры. Мы предполагаем, что абсолютное большинство запросов о снах содержит одно из нескольких слов — «сон», «сонник», «снится». Это понятное простое правило. Мы можем достать из поисковых логов все запросы с этими словами за какой-то период. Например, в неделю пользователи задают около 300 тысяч подобных запросов. Дальше мы можем выделить словоформы, которые чаще всего встречаются в этих запросах, — и таким образом узнать, что снится россиянам. Или, по крайней мере, толкование каких снов чаще ищут в интернете.
Маркеры пригодятся и в случаях, когда мы хотим выбрать все запросы, сформулированные похожим образом. Например, запросы, содержащие вопросительные слова (запросы в виде вопросов), или запросы со словами «что такое» и «что это». Таких запросов больше, чем про сны — более 20 миллионов в месяц или 0,4% всех поисковых запросов к Яндексу. Топы подобных запросов за несколько лет показывают, какие понятия и новые непонятные слова вызывали у пользователей поиска больше всего вопросов. В них отражаются все важные изменения и нововведения в обществе.
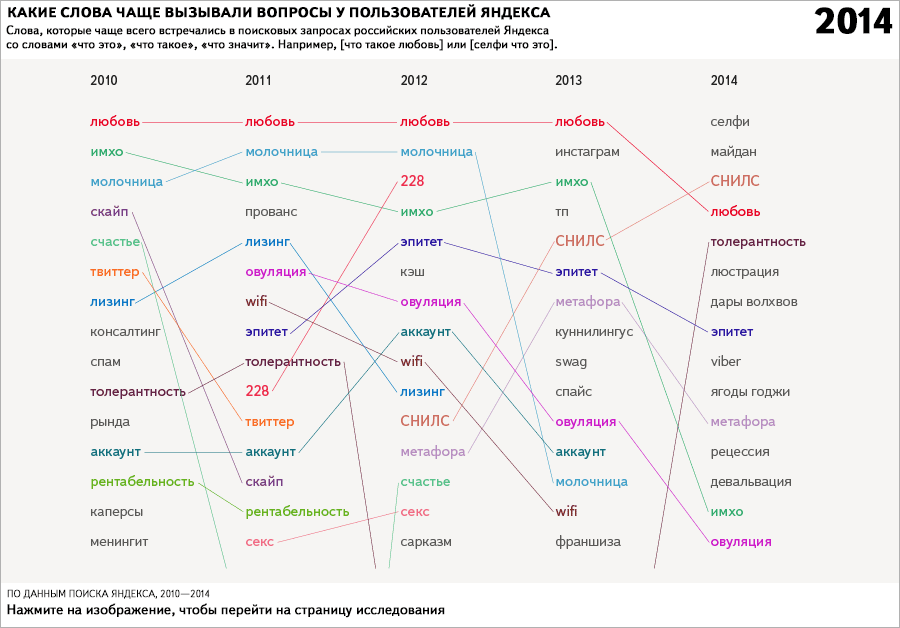
Такие запросы — о снах и о непонятных словах — хороший пример принципиально новых данных. Раньше, когда человек хотел узнать значение слова, он открывал словарь или спрашивал у знакомых, а толкования снов искал в бумажном соннике. Не было никакого способа узнать, ни что снится людям, ни какие новые непонятные вещи появились в жизни. Это стало возможным только сейчас, благодаря интернету и его статистике.
Более сложная ситуация — когда нас интересует не такая чёткая тема. Тогда список маркеров будет слишком большим — как, скажем, в случае с исследованием туристического рынка. Мы могли бы выбрать запросы с явно «туристическими» словами — «гостиница», «отель», «билеты» (при этом нужно как-то исключить билеты на концерты и в кино), — однако тема ими не исчерпывается. Люди часто ищут названия конкретных гостиниц и курортов, и нам пришлось бы включать их все в список маркеров. Иногда маркеры вообще невозможно выделить — если, например, мы хотим посмотреть, написание каких слов вызывает больше всего вопросов. Люди далеко не всегда используют слова «как пишется», чаще они просто вбивают сложное слово в поисковую строку.
В этом случае для выделения нужного класса запросов мы идём с обратной стороны. Мы предполагаем, что поисковая система работает достаточно хорошо, и используем её ответ — первые результаты поиска — для определения темы запроса. Например, составляем список наиболее авторитетных туристических сайтов (или сайтов, касающиеся правил русского языка) и считаем подходящими запросами все, по которым пользователи переходят на тот или иной сайт из этого списка. Если ответ на многие запросы интересующего нас класса люди могут увидеть прямо в результатах поиска, никуда не переходя, мы можем учитывать не только переходы, но и просто показы определённых сайтов —, но с меньшим весом или при соблюдении каких-нибудь дополнительных условий.
Визуализация
Однако данные мало получить и проанализировать. Чтобы получился интересный и понятный материал, необходимо представить их как можно более наглядно. Для этого используется инфографика — то есть изображение, которое помогает быстро понять основные выводы. Инфографику важно отличать от просто иллюстрации. Если иллюстрацией может служить картинка любого типа, даже имеющая к тексту отдалённое отношение (например, картинка с котиком для привлечения внимания), то в основе инфографики должны лежать данные. По этой же причине её не стоит городить там, где всё понятно и без дополнительных графических пояснений.
Люди придумали множество приёмов визуализации данных — некоторым из них гораздо больше лет, чем самим данным в их современном понимании. Существует множество типов изображений, от линейного графика или карты до параллельных координат или хордовой диаграммы, с помощью которых можно показать практически что угодно.
Для некоторых зависимостей лучше всего подходят стандартные графики. Если нужно показать разделение целого на несколько долей, понятнее всего будет какая-нибудь вариация на тему пай-чарта. Точно так же, если нужно отобразить изменение любой величины с течением времени, лучше всего подойдут график или гистограмма.
Другой очевидный и очень мощный приём — положить информацию на карту. Многое может стать сразу очень наглядным. Например, простое перечисление российских населённых пунктов, название которых начинается на букву «Ы», особо ни о чём не говорит. А если нарисовать их на карте, сразу видно, что большая часть городов и деревень на «Ы» находится в одном регионе. Кроме обычных карт, используются искажённые — например, такие, где площадь страны соответствует не её реальной площади, а какому-нибудь другому параметру.
От карт легко перейти к следующему типу визуализации — картам связей. По сути они представляют собой графы, то есть множество точек и связей между ними. Такая визуализация даёт возможность показать очень многое — значимы могут быть цвет и размер точек, расстояние между ними, наличие и отсутствие стрелок, наличие и отсутствие полюсов.
Но, конечно, простыми способами визуализации и их комбинациями не всегда получается обойтись. Иногда нужно показать десятки параметров, и каждый раз надо отдельно думать, каким образом их изобразить — так, чтобы информация оставалась наглядной и её восприятию ничего не мешало.

***
Данным и их обработке посвящены статьи, книги, семинары и курсы, так что мы не претендуем на то, чтобы раскрыть эту тему в одном посте. Мы описали общие принципы, которые используем при подготовке исследований, и привели несколько примеров. Посмотреть все исследования, сделанные аналитиками Яндекса, можно здесь, а если у вас есть вопросы или идеи для новых постов о работе с данными — оставляйте комментарии.
© Яндекс
