Упарываемся по максимуму: от ORM до анализа байткода
Как известно, настоящий программист в своей жизни должен сделать 3 вещи: создать свой язык программирования, написать свою операционную систему и сделать свой ORM. И если язык я написал уже давно (возможно, расскажу как-нибудь в другой раз), а ОС еще ждет впереди, то про ORM я хочу поведать прямо сейчас. А если точнее, то даже не про сам ORM, а про реализацию одной маленькой, локальной и, как изначально казалось, совсем простой фичи.
Мы с вами вместе пройдем весь путь от радости нахождения простого решения до горечи осознания его хрупкости и некорректности. От использования исключительно публичного API до грязных хаков. От «почти без рефлекшена», до «по колено в интерпретаторе байт-кода».
Кому интересно как анализировать байт-код, какие сложности это в себе таит и какой потрясающий результат можно получить в итоге, добро пожаловать под кат.
Содержание
1 — С чего все началось.
2–4 — На пути к байткоду.
5 — Кто такой байткод.
6 — Сам анализ. Именно ради этой главы все и затевалось и именно в ней самые кишочки.
7 — Что еще можно допилить. Мечты, мечты…
Послесловие — Послесловие.
UPD: Сразу после публикации были потеряны части 6–8 (ради которых все и затевалось). Пофиксил.
Часть первая. Проблема
Представим, что у нас есть простенькая схема. Существует клиент, у него есть несколько счетов. Один из них является дефолтным. Так же у клиента может быть несколько сим-карт и у каждой симки счет может быть явно задан, а может использоваться дефолтный клиентский.
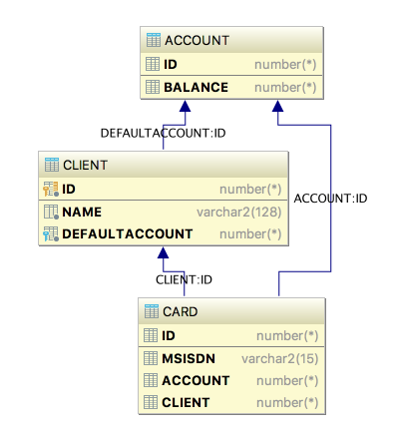
Вот как эта модель описывается у нас в коде (опуская геттеры/сеттеры/конструкторы/…).
@JdbcEntity(table = "CLIENT")
public class Client {
@JdbcId
private Long id;
@JdbcColumn
private String name;
@JdbcJoinedObject(localColumn = "DEFAULTACCOUNT")
private Account defaultAccount;
}
@JdbcEntity(table = "ACCOUNT")
public class Account {
@JdbcId
private Long id;
@JdbcColumn
private Long balance;
@JdbcJoinedObject(localColumn = "CLIENT")
private Client client;
}
@JdbcEntity(table = "CARD")
public class Card {
@JdbcId
private Long id;
@JdbcColumn
private String msisdn;
@JdbcJoinedObject(localColumn = "ACCOUNT")
private Account account;
@JdbcJoinedObject(localColumn = "CLIENT")
private Client client;
}
В самом ORM у нас наложено требование на отсутствие проксей (мы должны создать инстанс именно этого класса) и единственный запрос. Соответственно, вот какой sql отправляется в базу при попытке получить карту.
select CARD.id id,
CARD.msisdn msisdn,
ACCOUNT_2.id ACCOUNT_2_id,
ACCOUNT_2.balance ACCOUNT_2_balance,
CLIENT_3.id CLIENT_3_id,
CLIENT_3.name CLIENT_3_name,
CLIENT_1.id CLIENT_1_id,
CLIENT_1.name CLIENT_1_name,
ACCOUNT_4.id ACCOUNT_4_id,
ACCOUNT_4.balance ACCOUNT_4_balance
from CARD
left outer join CLIENT CLIENT_1 on CARD.CLIENT = CLIENT_1.id
left outer join ACCOUNT ACCOUNT_2 on CARD.ACCOUNT = ACCOUNT_2.id
left outer join CLIENT CLIENT_3 on ACCOUNT_2.CLIENT = CLIENT_3.id
left outer join ACCOUNT ACCOUNT_4 on CLIENT_1.DEFAULTACCOUNT = ACCOUNT_4.id;
Уупс. Клиент и счет задублировались. Правда, если подумать, то это вполне объяснимо — фреймворк ведь не знает что клиент карты и клиент счета карты — это один и тот же клиент. А запрос надо сгенерить статически и только один (помните ограничение в единственность запроса?).
Кстати, ровно по этой же причине здесь вообще нет полей Card.account.client.defaultAccount и Card.client.defaultAccount.client. Только мы знаем что client и client.defaultAccount.client всегда совпадают. А фреймворк не знает, для него это произвольная ссылка. И что делать в таких случаях не очень понятно. Я знаю 3 варианта:
- Явно описывать инварианты в аннотациях.
- Делать рекурсивные запросы (
with recursive/connect by). - Забить.
Угадайте, какой вариант выбрали мы? Правильно. В итоге, все рекурсивные филды сейчас вообще не заполняются и там всегда null.
Но если присмотреться, то за дублированием можно увидеть второю проблему, и она гораздо хуже. Мы ведь что хотели? Номер и баланс карты. А что получили? 4 джойна и 10 колонок. И эта штука растет экспоненциально! Ну т.е. мы реально имеем ситуацию, когда сначала ради красоты и целостности полностью описываем модель на аннотациях, а потом, ради 5 полей, идет запрос на 15 джойнов и 150 колонок. И вот в этот момент становится реально страшно.
Часть вторая. Рабочее, но неудобное решение
Сразу же напрашивается простое решение. Надо тащить только те колонки, которые будут использоваться! Легко сказать. Самый очевидный вариант (написать селект руками) мы отбросим сразу. Ну не затем же мы описывали модель, чтобы не использовать ее. Довольно давно был сделан специальный метод — partialGet. Он, в отличии от простого get, принимает List — имена полей, которые надо заполнить. Для этого сначала надо прописать алиасы таблицам
@JdbcJoinedObject(localColumn = "ACCOUNT", sqlTableAlias = "a")
private Account account;
@JdbcJoinedObject(localColumn = "CLIENT", sqlTableAlias = "c")
private Client client;
А потом наслаждаться результатом.
List requiredColumns = asList("msisdn", "c_a_balance", "a_balance");
String query = cardMapper.getSelectSQL(requiredColumns, DatabaseType.ORACLE);
System.out.println(query);
select CARD.msisdn msisdn,
c_a.balance c_a_balance,
a.balance a_balance
from CARD
left outer join ACCOUNT a on CARD.ACCOUNT = a.id
left outer join CLIENT c on CARD.CLIENT = c.id
left outer join ACCOUNT c_a on c.DEFAULTACCOUNT = c_a.id;
И вроде бы все хорошо, но, на самом деле, нет. Вот как оно будет использовано в реальном коде.
Card card = cardDAO.partialGet(cardId, "msisdn", "c_a_balance", "a_balance");
...
...
...
много много кода
...
...
...
long clientId = card.getClient().getId();//ой, NPE. А что, id клиента не был заполнен?!
И получается что пользоваться partialGet сейчас можно только если расстояние между ним и использованием результата только несколько строчек. А вот если результат уходит далеко или, не дай бог, передается внутрь какого-то метода, то понять потом какие поля у него заполнены, а какие нет, уже крайне сложно. Более того, если где-то случился NPE, то еще надо понять действительно ли это из базы null вернулся, или же мы просто данный филд и не заполняли. В общем, очень ненадежно.
Можно, конечно, просто написать еще один объект со своим маппингом специально под запрос, или же вообще полностью руками весь селект и собрать его в какой-нибудь Tuple. Собственно, реально сейчас в большинстве мест именно так и делаем. Но все-таки хотелось бы и не писать селекты руками, и не дублировать маппинг.
Часть третья. Удобное, но нерабочее решение.
Если еще немного подумать, то довольно быстро в голову приходит ответ — надо использовать интерфейсы. Тогда достаточно просто объявить
public interface MsisdnAndBalance {
String getMsisdn();
long getBalance();
}
И использовать
MsisdnAndBalance card = cardDAO.partialGet(cardId, ...);
И все. Ничего лишнего больше не вызвать. Более того, с переходом на котлин/десятку/ломбок даже от этого страшного типа можно будет избавиться. Но здесь все еще опущен самый главный момент. Какие аргументы нужно передавать в partialGet? Стринги, как раньше, уже не хочется, ибо слишком велик риск ошибиться и написать не те филды, которые нужны. А хочется чтобы можно было как-нибудь так
MsisdnAndBalance card = cardDAO.partialGet(cardId, MsisdnAndBalance.class);
Или еще лучше на котлине через reified generics
val card = cardDAO.paritalGet(cardId)
Эхх, ляпота. Собственно, весь дальший рассказ — это именно реализация данного варианта.
Часть четвертая. На пути к байткоду
Ключевая проблема заключается в том, что из интерфейса идут методы, а аннотации стоят над филдами. И нам нужно по методам найти эти самые филды. Первая и самая очевидная мысль — использовать стандартную Java Bean конвенцию. И для тривиальных свойств это даже работает. Но получается очень нестабильно. Например, стоит переименовать метод в интерфейсе (через идеевский рефакторинг), как все моментально разваливается. Идея достаточно умная чтобы переименовать методы в классах-реализациях, но недостаточно чтобы понять что это был геттер и надо переименовать еще и само поле. А еще подобное решение приводит к дублированию полей. Например, если мне в моем интерфейсе нужен метод getClientId(), то я не могу его реализовать единственно правильным способом
public class Client implements HasClientId {
private Long id;
@Override
public Long getClientId() {
return id;
}
}
public class Card implements HasClientId {
private Client client;
@Override
public Long getClientId() {
return client.getId();
}
}
А вынужден я дублировать поля. И в Client тащить и id, и clientId, а в карте рядом с клиентом иметь явно clientId. И еще следить чтобы все это не разъехалось. Более того, хочется чтобы работали еще и геттеры с нетривиальной логикой, например
public class Card implements HasBalance {
private Account account;
private Client client;
public long getBalance() {
if (account != null)
return account.getBalance();
else
return client.getDefaultAccount().getBalance();
}
}
Так что вариант с поисками по именам отпадает, нужно что-то более хитрое.
Следующий вариант был совсем безумный и прожил в моей голове недолго, но для полноты истории все же опишу и его. На этапе парсинга мы можем создать пустую сущность и просто по очереди писать какие-нибудь значения в филды, а после этого дергать геттеры и смотреть изменилось что они возвращают или нет. Так мы увидим что от записи в поле name значение getClientId не меняется, а вот от записи id — меняется. Более того, здесь автоматически поддерживается ситуация когда геттер и филд разных типов (типа isActive() = i_active != 0). Но здесь есть как минимум три серьезные проблемы (может и больше, но дальше уже не думал).
- Очевидным требованием к сущности при таком алгоритме является возврат «одного и того же» значения из геттера если «соответствующий» филд не менялся. «Одного и того же» — с точки зрения выбранного нами оператора сравнения.
==им, очевидно, быть не может (иначе перестанет работать какой-нибудьgetAsInt() = Integer.parseInt(strField)). Остается equals. Значит, если геттер возвращает какую-нибудь пользовательскую сущность, генерируемую по филдам при каждом вызове, то у нее обязан быть переопределенequals. - Сжимающие отображения. Как в примере с
int -> booleanвыше. Если мы будем проверять на значениях 0 и 1, то изменение увидим. Но вот если на 40 и 42, то оба раза получим true. - Могут быть сложные конвертеры в геттерах, рассчитывающие на определенные инварианты в филдах (например, спец. формат строки). А на наших сгенеренных данных они будут кидать исключения.
Так что в целом вариант тоже не рабочий.
В процессе обсуждения всего этого дела я, изначально в шутку, произнес фразу «ну нафиг, проще в байткод посмотреть, там все написано». На тот момент я даже не продполагал что эта идея поглотит меня, и как далеко все зайдет.
Часть пятая. Что такое байткод и как он работает
new #4, dup, invokespecial #5, areturn
Если вы понимаете, что здесь написано и что данный код делает, то можете сразу переходить к следующей части.
Disclaimer 1. К сожалению, для понимания дальнейшего рассказа требуется хотя бы базовое понимание того, как выглядит джавовый байткод, так что напишу про это пару абзацев. Ни в коей мере не претендую на полноту.
Disclaimer 2. Речь пойдет исключительно про тела методов. Ни про constant pool, ни про структуру класса в целом, ни даже про сами декларации методов, я не скажу ни слова.
Главное, что нужно понимать про байткод — это ассемблер к стековой виртуальной машине Java. Это значит что аргументы для инструкций берутся со стека и возвращаемые значения из инструкций кладутся обратно на стек. С этой точки зрения можно сказать, что байткод записан в обратной польской нотации. Помимо стэка в методе есть еще массив локальных переменных. При входе в метод в него записывается this и все аргументы этого метода, и в процессе выполнения там же хранятся локальные переменные. Вот простенький пример.
public class Foo {
private int bar;
public int updateAndReturn(long baz, String str) {
int result = (int) baz;
result += str.length();
bar = result;
return result;
}
}
Я буду писать комментарии в формате
# [(:)*], [()*]
Вершина стэка слева.
public int updateAndReturn(long, java.lang.String);
Code:
# [0:this, 1:long baz, 3:str], ()
0: lload_1
# [0:this, 1:long baz, 3:str], (long baz)
1: l2i
# [0:this, 1:long baz, 3:str], (int baz)
2: istore 4
# [0:this, 1:long baz, 3:str, 4:int baz], ()
4: iload 4
# [0:this, 1:long baz, 3:str, 4:int baz], (int baz)
6: aload_3
# [0:this, 1:long baz, 3:str, 4:int baz], (str, int baz)
7: invokevirtual #2 // Method java/lang/String.length:()I
# [0:this, 1:long baz, 3:str, 4:int baz], (length(str), int baz)
10: iadd
# [0:this, 1:long baz, 3:str, 4:int baz], (length(str) + int baz)
11: istore 4
# [0:this, 1:long baz, 3:str, 4:length(str) + int baz], ()
13: aload_0
# [0:this, 1:long baz, 3:str, 4:length(str) + int baz], (this)
14: iload 4
# [0:this, 1:long baz, 3:str, 4:length(str) + int baz], (length(str) + int baz, this)
16: putfield #3 // Field bar:I
# [0:this, 1:long baz, 3:str, 4:length(str) + int baz], (), сумма записана в поле bar
19: iload 4
# [0:this, 1:long baz, 3:str, 4:length(str) + int baz], (length(str) + int baz)
21: ireturn
# возвратили int с вершины стэка, там как раз была наша сумма
Всего инструкций очень много. Полный список нужно смотреть в шестой главе JVMS, на википедии есть краткий пересказ. Большое количество инструкций дублируют друг друга для разных типов, (например, iload для инта и lload для лонга). Так же для работы с 4 первыми локальными переменными выделены свои инструкции (в примере выше, например, есть lload_1 и он не принимает аргументов вообще, но еще есть просто lload, он будет принимать аргументом номер локальной переменной. В примере выше есть подобный iload).
Глобально нас будут интересовать следующие группы инструкций:
*load*,*store*— чтение/запись локальной переменной*aload,*astore— чтение/запись элемента массива по индексуgetfield,putfield— чтение/запись поляgetstatic,putstatic— чтение/запись статического поляcheckcast— каст между объектными типами. Нужен т.к. на стэке и в локальных переменных лежат типизированные значения. Например, выше был l2i для каста long → int.invoke*— вызов метода*return— возврат значения и выход из метода
Часть шестая. Главная
Для тех, кто пропустил столь затянувшееся вступление, а так же дле того, чтобы отвлечься от исходной задачи и рассуждать в терминах библиотеки, сформулируем задачу более точно.
Нужно, имея на руках экземпляр
java.lang.reflect.Method, получить список всех нестатических филдов (и текущего, и всех вложенных объектов), чтения которых (напрямую или транзитивно) будут внутри данного метода.
Например, для такого метода
public long getBalance() {
Account acc;
if (account != null)
acc = account;
else
acc = client.getDefaultAccount();
return acc.getBalance();
}
Нужно получить список из двух филдов: account.balance и client.defaultAccount.balance.
Я буду писать, по-возможности, обобщенное решение. Но в паре мест придется использовать знание об исходной задаче для решения неразрешимых, в общем случае, проблем.
Для начала нужно получить сам байткод тела метода, но напрямую через джаву это сделать нельзя. Но т.к. изначально метод существует внутри какого-то класса, то проще получить сам класс. Глобально я знаю два варианта: вклиниться в процесс загрузки классов и перехватывать уже прочитанный byte[] там, либо просто найти сам файл ClassName.class на диске и прочитать его. Перехват загрузки на уровне обычной библиотеки не сделать. Нужно либо подключать javaagent, либо использовать кастомный ClassLoader. В любом случае, требуются дополнительные действия по настройке jvm/приложения, а это неудобно. Можно поступить проще. Все «обычные» классы всегда находятся в одноименном файле с расширением ».class», путь к которому — это пакет класса. Да, так не получится найти динамически добавленные классы или классы, загруженные каким-нибудь кастомным класслоадером, но нам это нужно для модели jdbc, так что можно с уверенностью сказать что все классы будут запакованы «дефолтным способом» в джарники. Итого:
private static InputStream getClassFile(Class clazz) {
String file = clazz.getName().replace('.', '/') + ".class";
ClassLoader cl = clazz.getClassLoader();
if (cl == null)
return ClassLoader.getSystemResourceAsStream(file);
else
return cl.getResourceAsStream(file);
}
Ура, массив байт прочитали. Что будем делать с ним дальше? В принципе в джаве для чтения/записи байткода есть несколько библиотек, но для самой низкоуревневой работы обычно используется ASM.Т. к. он заточен под высокую производительность и работу налету, то основным там является visitor API — асм последовательно читает класс и дергает соответствующие методы
public abstract class ClassVisitor {
public void visit(int version, int access, String name, String signature, String superName, String[] interfaces) {...}
public FieldVisitor visitField(int access, String name, String desc, String signature, Object value) {...}
public MethodVisitor visitMethod(int access, String name, String desc, String signature, String[] exceptions) {...}
...
}
public abstract class MethodVisitor {
protected MethodVisitor mv;
public MethodVisitor(final int api, final MethodVisitor mv) {
...
this.mv = mv;
}
public void visitJumpInsn(int opcode, Label label) {
if (mv != null) {
mv.visitJumpInsn(opcode, label);
}
}
...
}
Пользователю же предлагается переопределять интересующие его методы и писать там свою логику анализа/трансформации. Отдельно, на примере MethodVisitor, хотелось бы обратить внимание что у всех визиторов есть дефолтная реализация через делегирование.
В дополнение к основному апи из коробки есть еще Tree API. Если Core API является аналогом SAX парсера, то Tree API — это аналог DOM. Мы получаем объект, внутри которого хранится вся информация о классе/методе и можем анализировать ее как хотим с прыжками в любое место. По сути, этот апи является реализациями *Visitor, которые внутри методов visit* просто сохраняют информацию. Примерно все методы там выглядят так:
public class MethodNode extends MethodVisitor {
@Override
public void visitJumpInsn(final int opcode, final Label label) {
instructions.add(new JumpInsnNode(opcode, getLabelNode(label)));
}
...
}
Теперь мы, наконец-то, можем загрузить метод для анализа.
private static class AnalyzerClassVisitor extends ClassVisitor {
private final String getterName;
private final String getterDesc;
private MethodNode methodNode;
public AnalyzerClassVisitor(Method getter) {
super(ASM6);
this.getterName = getter.getName();
this.getterDesc = getMethodDescriptor(getter);
}
public MethodNode getMethodNode() {
if (methodNode == null)
throw new IllegalStateException();
return methodNode;
}
@Override
public MethodVisitor visitMethod(int access, String name, String desc, String signature, String[] exceptions) {
//Проверяем что это именно наш метод
if (!name.equals(getterName) || !desc.equals(getterDesc))
return null;
return new AnalyzerMethodVisitor(access, name, desc, signature, exceptions);
}
private class AnalyzerMethodVisitor extends MethodVisitor {
public AnalyzerMethodVisitor(int access, String name, String desc, String signature, String[] exceptions) {
super(ASM6, new MethodNode(ASM6, access, name, desc, signature, exceptions));
}
@Override
public void visitEnd() {
//Данный метод вызывается в самом конце, после него других вызовов MethodVisitor уже не будет
if (methodNode != null)
throw new IllegalStateException();
methodNode = (MethodNode) mv;
}
}
}
Возвращается не напрямую MethodNode, а обертка с парой доп. полей, т.к. они нам позже тоже понадобятся. Точка входа (и единственный публичный метод) — readMethod(Method): MethodInfo.
public class MethodReader {
public static class MethodInfo {
private final String internalDeclaringClassName;
private final int classAccess;
private final MethodNode methodNode;
public MethodInfo(String internalDeclaringClassName, int classAccess, MethodNode methodNode) {
this.internalDeclaringClassName = internalDeclaringClassName;
this.classAccess = classAccess;
this.methodNode = methodNode;
}
public String getInternalDeclaringClassName() {
return internalDeclaringClassName;
}
public int getClassAccess() {
return classAccess;
}
public MethodNode getMethodNode() {
return methodNode;
}
}
public static MethodInfo readMethod(Method method) {
Class clazz = method.getDeclaringClass();
String internalClassName = getInternalName(clazz);
try (InputStream is = getClassFile(clazz)) {
ClassReader cr = new ClassReader(is);
AnalyzerClassVisitor cv = new AnalyzerClassVisitor(internalClassName, method);
cr.accept(cv, SKIP_DEBUG | SKIP_FRAMES);
return new MethodInfo(internalClassName, cv.getAccess(), cv.getMethodNode());
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private static InputStream getClassFile(Class clazz) {
String file = clazz.getName().replace('.', '/') + ".class";
ClassLoader cl = clazz.getClassLoader();
if (cl == null)
return ClassLoader.getSystemResourceAsStream(file);
else
return cl.getResourceAsStream(file);
}
private static class AnalyzerClassVisitor extends ClassVisitor {
private final String className;
private final String getterName;
private final String getterDesc;
private MethodNode methodNode;
private int access;
public AnalyzerClassVisitor(String internalClassName, Method getter) {
super(ASM6);
this.className = internalClassName;
this.getterName = getter.getName();
this.getterDesc = getMethodDescriptor(getter);
}
public MethodNode getMethodNode() {
if (methodNode == null)
throw new IllegalStateException();
return methodNode;
}
public int getAccess() {
return access;
}
@Override
public void visit(int version, int access, String name, String signature, String superName, String[] interfaces) {
if (!name.equals(className))
throw new IllegalStateException();
this.access = access;
}
@Override
public MethodVisitor visitMethod(int access, String name, String desc, String signature, String[] exceptions) {
if (!name.equals(getterName) || !desc.equals(getterDesc))
return null;
return new AnalyzerMethodVisitor(access, name, desc, signature, exceptions);
}
private class AnalyzerMethodVisitor extends MethodVisitor {
public AnalyzerMethodVisitor(int access, String name, String desc, String signature, String[] exceptions) {
super(ASM6, new MethodNode(ASM6, access, name, desc, signature, exceptions));
}
@Override
public void visitEnd() {
if (methodNode != null)
throw new IllegalStateException();
methodNode = (MethodNode) mv;
}
}
}
}
Самое время заняться непосредственно анализом. Как его делать? Первая мысль — смотреть все инструкции getfield. У каждого getfield статически написано какой это филд и какого класса. Можно считать за необходимые все филды нашего класса, к которым был доступ. Но, к сожалению, это не работает. Первая проблема здесь заключается в том, что происходит захват лишнего.
class Foo {
private int bar;
private int baz;
public int test() {
return bar + new Foo().baz;
}
}
При таком алгоритме мы посчитаем, что филд baz нужен, хотя, на самом деле, нет. Но на эту проблему еще можно было бы и забить. Но что делать с методами?
public class Client implements HasClientId {
private Long id;
public Long getId() {
HasClientId obj = this;
return obj.getClientId();
}
@Override
public Long getClientId() {
return id;
}
}
Если искать вызовы методов так же, как мы ищем чтение филдов, то getClientId мы не найдем. Ибо здесь нет вызова Client.getClientId, а есть только вызов HasClientId.getClientId. Можно, конечно, считать используемыми все методы на текущем классе, всех его суперклассах и всех интерфейсах, но это уже совсем перебор. Так можно случайно и toString захватить, а в нем распечатка вообще всех филдов.
Более того, мы ведь хотим чтобы вызовы геттеров у вложенных объектов тоже работали
public class Account {
private Client client;
public long getClientId() {
return client.getId();
}
}
И здесь вызов метода Client.getId к классу Account вообще никак не относится.
При большом желании еще можно какое-то время попридумывать хаки под частные случаи, но довольно быстро приходит понимание, что «так дела не делаются» и нужно полноценно следить за потоком исполнения и перемещением данных. Интересовать нас должны те и только те getfield, которые вызываются либо непосредственно на this, либо на каком-нибудь филде от this. Вот пример:
class Client {
public long id;
}
class Account {
public long id;
public Client client;
public long test() {
return client.id + new Account().id;
}
}
class Account {
public Client client;
public long test();
Code:
0: aload_0
1: getfield #2 // Field client:LClient;
4: getfield #3 // Field Client.id:J
7: new #4 // class Account
10: dup
11: invokespecial #5 // Method "":()V
14: getfield #6 // Field id:J
17: ladd
18: lreturn
}
1: getfieldнам интересен потому что в момент его выполнения на вершине стэка будет лежатьthis, загруженный туда инструкциейaload_0.4: getfield— потому что он будет вызываться на клиенте, возвращенном из предыдущего1: getfield, и, транзативно, наthis.14: getfieldнам не интересен. Т.к. не смотря на то, что что это филд текущего класса (Account), вызывается он не наthis, а на новом объекте, созданном и положенном на стэк в7: new.
Итого, после анализа данного метода видно что филд Account.client.id используется, а Account.id — нет. Это был пример про филды, с методами больше нюансов, но в целом примерно то же самое.
В этот момент опускаются руки — надо писать полноценный интерпретатор, детектить паттерны не выйдет, ведь между aload_0 и getfield может быть масса кода с перекладыванием этого несчастного this в локалы, касты, засовывания его в методы и возврат из них. Короче, боль. Это плохая новость. Но есть и хорошая — такой интерпретатор уже написан! И не где-нибудь, а прямо в асме. И интерпретирует он именно MethodNode, полученный нами ранее (вот же неожиданность). В потоковом режиме интерпретировать нельзя, т.к. могут быть джампы (циклы/условия/исключения) и хорошо бы не перечитывать метод после каждого.
Интерпретатор состоит из двух частей:
public class Analyzer {
public Analyzer(final Interpreter interpreter) {...}
public Frame[] analyze(final String owner, final MethodNode m) {...}
}
Analyzer уже написан и в нем (и в Frame, но про него позже) реализован сам интерпретатор. Именно он идет последовательно по инструкциям, кладет значения в локалы, читает их оттуда, модифицирует стэк, совершает прыжки если в методе есть цилкы/условия/etc.
public abstract class Interpreter {
public abstract V newValue(Type type);
public abstract V newOperation(AbstractInsnNode insn) throws AnalyzerException;
public abstract V copyOperation(AbstractInsnNode insn, V value) throws AnalyzerException;
public abstract V unaryOperation(AbstractInsnNode insn, V value) throws AnalyzerException;
public abstract V binaryOperation(AbstractInsnNode insn, V value1, V value2) throws AnalyzerException;
public abstract V ternaryOperation(AbstractInsnNode insn, V value1, V value2, V value3) throws AnalyzerException;
public abstract V naryOperation(AbstractInsnNode insn, List values) throws AnalyzerException;
public abstract void returnOperation(AbstractInsnNode insn, V value, V expected) throws AnalyzerException;
public abstract V merge(V v, V w);
}
Параметр V — это наш класс, в котором можно хранить любую информацию, ассоциированную с конкретным значением. Analyzer в процессе анализа будет вызывать соответствующие методы для каждой инструкции, передавать на вход значения, которые сейчас лежат на вершине стэка и будут использованы данной инструкцией, а нам остается вернуть новое значение. Например, getfield принимает на вход один аргумент — объект, чье поле будет вычитано, и возвращает значение этого поля. Соответственно, будет вызван unaryOperation(AbstractInsnNode insn, V value): V, где мы сможем проверить к чьему филду идет доступ и вернуть разные значения в зависимости от этого. В примере выше на 1: getfield мы вернем Value, в котором будет написано «это поле client, типа Client и нам интересно трэкать дальнейшие доступы к нему», а в 14: getfield скажем «аргумент — это какой-то неизвестный объект, так что возвращаем скучный инт и плевать на него».
Отдельно хочу обратить внимание на метод merge(V v, V w): V. Он вызывается не для конкретных инструкций, а когда поток исполнения снова попадает в место, где он уже был. Например:
public long getBalance() {
Account acc;
if (account != null)
acc = account;
else
acc = client.getDefaultAccount();
return acc.getBalance();
}
Здесь к вызову Account.getBalance() можно попасть двумя разными путями. Но инструкция-то одна. И на вход она принимает единственное значение. Какое из двух? Именно на этот вопрос и призван отвечать метод merge.
Что нам осталось перед самым главным шагом — написанием SuperInterpreter extends Interpreter? Правильно. Написать этот самый SuperValue. Посколько цель у нас — найти все используемые филды и филды филдов, то логичным выглядит хранение именно пути по филдам. Но поскольку в одно и то же место можно прийти разными путями и с разными объектами, то непосредственно в качестве значения мы будем хранить множество уникальных путей.
public class Value extends BasicValue {
private final Set refs;
private Value(Type type, Set refs) {
super(type);
this.refs = refs;
}
}
public class Ref {
private final List path;
private final boolean composite;
public Ref(List path, boolean composite) {
this.path = path;
this.composite = composite;
}
}
По поводу странного флага composite. Нет ни желания, ни необходимости анализировать абсолютно все. Например, тип String лучше воспринимать неделимым. И даже если в нашем методе есть вызов String.length(), то правильнее считать, что использовано было именно основное поле name, а не name.value.length. Кстати, length — это вообще не филд, а свойство массива, получаемое отдельной инструкцией arraylength. Нам надо обрабатывать ее отдельно? Нет! Самое время первый раз вспомнить ради чего все делается — мы хотим понять какие объекты надо грузить из базы. Соответственно, минимальной и неделимой сущностью являются те объекты, которые грузятся из базы целиком, а не через джойн по филдам. Например, это Date, String, Long, и абсолютно плевать что у них внутри довольно сложная структура. Кстати, сюда же идут все типы, для которых у нас есть конвертер. Например может быть написано
class Persion {
@JdbcColumn(converter = CustomJsonConverter.class)
private PassportInfo passportInfo;
}
И тогда внутрь этого PassportInfo тоже смотреть не надо. Он целиком либо будет притянут, либо нет. Так вот, флаг composite отвечает именно за это. Надо нам заглядывать внутрь или же нет.
public class Ref {
private final List path;
private final boolean composite;
public Ref(List path, boolean composite) {
this.path = path;
this.composite = composite;
}
public List getPath() {
return path;
}
public boolean isComposite() {
return composite;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Ref ref = (Ref) o;
return Objects.equals(path, ref.path);
}
@Override
public int hashCode() {
return Objects.hash(path);
}
@Override
public String toString() {
if (path.isEmpty())
return "<[this]>";
else
return "<" + path.stream().map(Field::getName).collect(joining(".")) + ">";
}
public static Ref thisRef() {
return new Ref(emptyList(), true);
}
public static Optional childRef(Ref parent, Field field, Configuration configuration) {
if (!parent.isComposite())
return empty();
if (parent.path.contains(field))//пока можно не обращать внимание, дальше объясню
return empty();
List path = new ArrayList<>(parent.path);
path.add(field);
return of(new Ref(path, configuration.isCompositeField(field)));
}
public static Optional childRef(Ref parent, Ref child) {
if (!parent.isComposite())
return empty();
if (child.path.stream().anyMatch(parent.path::contains))//оно же, объясню позже
return empty();
List path = new ArrayList<>(parent.path);
path.addAll(child.path);
return of(new Ref(path, child.composite));
}
}
public class Value extends BasicValue {
private final Set refs;
private Value(Type type, Set refs) {
super(type);
this.refs = refs;
}
public Set getRefs() {
return refs;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
if (!super.equals(o)) return false;
Value value = (Value) o;
return Objects.equals(refs, value.refs);
}
@Override
public int hashCode() {
return Objects.hash(super.hashCode(), refs);
}
@Override
public String toString() {
return "(" + refs.stream().map(Object::toString).collect(joining(",")) + ")";
}
public static Value typedValue(Type type, Ref ref) {
return new Value(type, singleton(ref));
}
public static Optional childValue(Value parent, Value child) {
Type type = child.getType();
Set fields = parent.refs.stream()
.flatMap(p -> child.refs.stream().map(c -> childRef(p, c)))
.filter(Optional::isPresent)
.map(Optional::get)
.collect(toSet());
if (fields.isEmpty())
return empty();
return of(new Value(type, fields));
}
public static Optional childValue(Value parent, FieldInsnNode childInsn, Configuration configuration) {
Type type = Type.getType(childInsn.desc);
Field child = resolveField(childInsn);
Set fields = parent.refs.stream()
.map(p -> childRef(p, child, configuration))
.filter(Optional::isPresent)
.map(Optional::get)
.collect(toSet());
if (fields.isEmpty())
return empty();
return of(new Value(type, fields));
}
public static Value mergeValues(Collection values) {
List types = values.stream().map(BasicValue::getType).distinct().collect(toList());
if (types.size() != 1) {
String typesAsString = types.stream().map(Type::toString).collect(joining(", ", "(", ")"));
throw new IllegalStateException("could not merge " + typesAsString);
}
Set fields = values.stream().flatMap(v -> v.refs.stream()).distinct().collect(toSet());
return new Value(types.get(0), fields);
}
public static boolean isComposite(BasicValue value) {
return value instanceof Value && value.getType().getSort() == Type.OBJECT && ((Value) value).refs.stream().anyMatch(Ref::isComposite);
}
}
Ну что ж, вся подготовительная работа завершена. Поехали!
public class FieldsInterpreter extends BasicInterpreter {
Чтобы полностью не писать поддержку всех команд, можно относледоваться от BasicInterpreter. Он работает с BasicValue (именно поэтому можно было заметить, что мой Value был extends BasicValue) и реализует простую работу с типами.
public class BasicValue implements Value {
public static final BasicValue UNINITIALIZED_VALUE = new BasicValue(null);
public static final BasicValue INT_VALUE = new BasicValue(Type.INT_TYPE);
public static final BasicValue FLOAT_VALUE = new BasicValue(Type.FLOAT_TYPE);
public static final BasicValue LONG_VALUE = new BasicValue(Type.LONG_TYPE);
public static final BasicValue DOUBLE_VALUE = new BasicValue(Type.DOUBLE_TYPE);
public static final BasicValue REFERENCE_VALUE = new BasicValue(Type.getObjectType("java/lang/Object"));
public static final BasicValue RETURNADDRESS_VALUE = new BasicValue(Type.VOID_TYPE);
private final Type type;
public BasicValue(final Type type) {
this.type = type;
}
}
Это позволит нам не только наслаждаться обилием кастов ((Value)basicValue) в коде, но и писать только значимую часть с нашими композитными значениями, а всю тривиальную логику (вида «инструкция iconst возвращает инт») не писать.
Начнем с newValue. Этот метод отвечает за первичное создание значение, когда они появляются не как результат инструкции, а «из воздуха». Это параметры метода, this и исключение в блоке catch. В принципе, нас бы устроил дефолтный вариант, если бы не одно но. Для объектных типов BasicInterpreter вместо BasicValue(actualType) возвращает просто BasicValue.REFERENCE_VALUE. А нам хотелось бы иметь реальный тип.
@Override
public BasicValue newValue(Type type) {
if (type != null && type.getSort() == OBJECT)
return new BasicValue(type);
return super.newValue(type);
}
Теперь entry point. Весь наш анализ начинается с this. Соответственно, нужно как-нибудь сказать, что там, где лежит this, на самом деле не BasicValue(actualType), а Value.typedValue(actualType, Ref.thisRef()). Вообще, как я уже писал выше, изначально значение this устанавливается через вызов newValue, только вот неизвестно какой именно. И даже на сам тип операться нельзя, т.к. один из аргументов метода может быть такого же типа, как и this. Получается что напрямую записать this правильным мы не можем. Ок, можно выкрутиться. Известно, что при вызове метода this всегда идет как локальная переменная номер 0. Напрямую с локальными переменными ничего делать нельзя, их можно только читать и записывать. А это значит, что мы можем перехватить чтение данной переменной и вернуть не оригинальное значение, а правильное. Ну и на всякий случай стоит проверить что данная переменная не была перезаписана.
@Override
public BasicValue copyOperation(AbstractInsnNode insn, BasicValue value) throws AnalyzerException {
if (wasUpdated || insn.getType() != VAR_INSN || ((VarInsnNode) insn).var != 0) {
return super.copyOperation(insn, value);
}
switch (insn.getOpcode()) {
case ALOAD:
return typedValue(value.getType(), thisRef());
case ISTORE:
case LSTORE:
case FSTORE:
case DSTORE:
case ASTORE:
wasUpdated = true;
}
return super.copyOperation(insn, value);
}
Идем дальше. Мержить значения довольно просто. Если они разных типов, то кидаем исключение, если одно нам интересно, а другое — нет, то берем интересное. Если интересны оба, то объединяем все пути.
@Override
public BasicValue merge(BasicValue v, BasicValue w) {
if (v.equals(w))
return v;
if (v instanceof Value || w instanceof Value) {
if (!Objects.equals(v.getType(), w.getType())) {
if (v == UNINITIALIZED_VALUE || w == UNINITIALIZED_VALUE)
