Тестируем поиск 2ГИС: единороги и счастье пользователя
2ГИС — миллионы организаций и геообъектов, которые ищут в поиске. И чем точнее работает поиск, тем лучше для пользователя.
Я Эля Снежкова, лид команды тестирования. Мы проверяем, насколько быстро и эффективно работает поиск в 2ГИС. Расскажу, как мы тестируем, про единорогов в тестировании и как мы измеряем счастье пользователя.
Что тестируем в поиске
Мы следим за несколькими метриками одновременно.
Смотрим, что находится по адекватному запросу. Проверяем также, чтобы по неадекватным запросам вроде «vdscl%^)kd ()jm438u:, nhdsjdcn» ничего не находилось.
Следим за ранжированием результатов, чтобы в первую очередь показывали самое релевантное.
По запросу «Апельсины» пользователю не нужны все организации с названием «Апельсин» или все места, где продаётся этот прекрасный фрукт, поэтому мы ещё проверяем и фильтрацию результатов, чтобы не было лишнего.

Следим за персонализацией выдачи у авторизованных пользователей — 2ГИС учитывает избранное и адрес при формировании результатов.
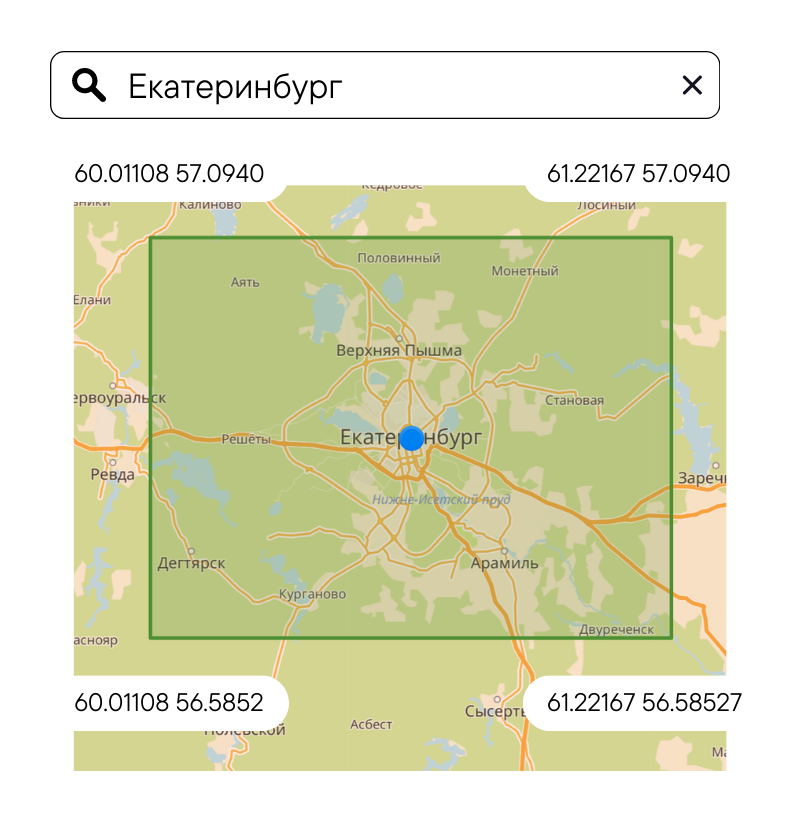
Проверяем корректность области интересов и что в этой области есть результаты. Ведь когда пользователь что-то ищет, ему нужно видеть, где на карте находится объект. Поэтому мало показать объект в списке выдачи, нужно передвинуть карту на искомый объект.
Классические тесты
Раньше мы использовали классические тесты по модели: Запрос → Результат. Например, Фастфуд → KFC.
Так мы проводили около 700 тыс. проверок, сравнивая запрос с результатом. Тесты создавали генератором. Например, нам нужно было проверить, что улицы находятся по названию. В генераторе выбирали, например, 100 улиц и формировали 100 запросов. Добавляли слово «улица» — формировали ещё 100 запросов. Брали точку пользователя рядом с улицей и где-то подальше. Так перебирали все параметры, которые могут повлиять на выдачу. И из 100 улиц у нас возникало до 1600 кейсов. Например:
Ленина | Ленина + пользователь рядом с улицей |
Советская | Советская + пользователь рядом с улицей |
1-я | 1-я + пользователь рядом с улицей |
улица Ленина | улица Ленина + пользователь рядом с улицей |
улица Советская | улица Советская + пользователь рядом с улицей |
улица 1-я | улица 1-я + пользователь рядом с улицей |
Несмотря на большое количество проверок и достаточно большое покрытие, у нас возникали трудности.

Предлоги и союзы. В тестах отсутствовали предлоги и союзы. Это связано с тем, что в данных, на которых формируются тесты, есть две отдельные сущности: рубрика «Эротические товары» и улица «Ленина». Мы не знаем каким предлогом их связать.
Частичный поиск. При проверке частичного поиска мы добавляем какую-нибудь ерунду — и это далеко от того, что может ввести реальный пользователь в поисковую строку. Например, как на картинке выше — рандомный набор букв.
Поиск с ошибками. В тестовых данных практически отсутствуют ошибки в названиях улиц, городов, организаций. Поэтому нам сложно проверять поиск с ошибками. Конечно, мы создали тесты, где преднамеренно вносили ошибки, но опять же это искусственные тесты иногда далёкие от реального мира.
Вариативность названий. В данных есть некоторые названия, например, «Детская городская клиническая больница №11». Обычно мы проверяем, что объект находится по этому названию. Но вариативность названий в автотестах проверить сложно — люди могут искать так: «Детская больница 11», «Больница №11», «Городская детская больница №11» и множеством других способов.
Даже если тест удавалось написать, возникала ещё одна проблема: как оценить результаты изменений в поисковой выдаче?
Например, у нас есть запрос «Грабли», и по нему мы находим «Леруа Мерлен», где этот товар можно купить. Кажется, хорошо! Но улучшать поиск можно бесконечно, и даже небольшое изменение может радикально изменить выдачу. Может получиться так, что по запросу «Грабли» исчезнет «Леруа Мерлен», зато появится ресторан с названием «Грабли». Как оценить, это хорошо или плохо? Может, нужно оставить в выдаче и ресторан, и магазин с инвентарем? Если оставить оба варианта, то что должно быть на первом месте? Куда позиционировать карту? Вопросов больше чем ответов.
Unicorn-тесты
В какой-то момент мы поняли, что нам не хватает более «человеческих» тестов. А как их сделать? Да и зачем, если миллионы пользователей и так генерируют миллионы запросов, осталось только взять эти запросы и сформировать из них тесты. Эти тесты мы назвали шуточно »Unicorn», т. к. оно созвучно с названием нашего поискового движка »Unisearch».
Для начала нужно собрать пользовательскую статистику, благо, что мы трекаем очень много параметров. Вот основные:
Запрос пользователя
Место на карте, куда смотрит пользователь
Локация пользователя
Его персональные объекты (объекты из избранного, история поиска)
Что делал пользователь (листал список выдачи, строил маршрут, двигал карту)
С какого устройства пришел запрос (веб или приложение)
И вот статистика собрана и бережно положена в базу. У нас есть много пользовательских запросов и много результатов, но вот как понять что пользователь хотел по конкретному запросу?

Для этого мы воспроизводим действия пользователя — строим цепочку последовательности действий. Если пользователь ввел запрос, проскролил выдачу и вышел из приложения, то такую цепочку мы не будем рассматривать, т. к. непонятна конечная цель. А если он ввел запрос, кликнул на первый результат и построил до него маршрут, такой цепочке мы рады!
Тест сформируем таким образом: запрос пользователя → ожидаемый результат (объект, до которого пользователь построил маршрут).

«Счастье пользователя»
Тест-кейсы есть! Теперь осталось понять, хороша ли поисковая выдача. Для этого мы ввели показатель хорошей выдачи — «Счастье пользователя»: поисковый движок должен с одного ввода (буква, голос, свайп) выдать один единственный релевантный для пользователя результат, до которого он, например, проложит маршрут.
Для каждого тест-кейса мы считаем метрику «Счастья пользователя», точнее не её саму, а отклонение (штраф) от неё. По факту, мы измеряем насколько пользователь несчастен, а именно насколько мы далеки от идеала. Рассмотрим на примере тех самых «Грабель» (все расчеты ниже будут условными).
Предположим, что Пользователь1 ввел запрос «Грабли» и позвонил в организацию на первом месте. Перед ним выдача:

Рассчитаем отклонение от «Счастья пользователя». Для этого определим, что 100 — это абсолютное счастье, к которому мы стремимся. За каждый критерий неидеальности будем штрафовать, но по-разному. Поехали!
Результат есть в выдаче? Да! Штраф = 0, т. е. по этому критерию не штрафуем
Результат на первом месте? Да! Штраф = 0.
Есть другие результаты в выдаче? Да… Штраф = 5 баллов. Чем больше лишних результатов в выдаче, тем сильнее стоит штрафовать.
Виден ли результат в области, куда смотрит пользователь? Да! Штраф = 0. Булевый показатель.
Если просуммировать все штрафы и посмотреть отклонение, то получаем:
100 — (0 + 0 + 5 + 0) = 95
То есть пользователь по данному кейсу счастлив на 95 из 100.
Давайте рассмотрим Пользователя2, который тоже ввёл «Грабли» и кликнул на «Леруа Мерлен». На скрине этого результата нет, предположим, этот результат на последней, 7-й позиции.
Посчитаем для него отклонение от метрики.
Результат есть в выдаче? — Да! Штраф = 0. Если ожидаемого результата нет в выдаче, то сразу данный штраф = 100, и всё остальное можно не считать.
Результат на первом месте? — Нет, штраф = 30 баллов. Чем ниже результат в выдаче, тем сильнее его следует штрафовать. Для этого мы используем логарифмическую функцию. То есть для нас важно, результат на 1-м месте или на 5-м. Но уже не так важно, на 120-м или 125-м месте.
Есть другие результаты в выдаче? — Да, штраф = 5 баллов.
Виден ли результат в области, куда смотрит пользователь? — Нет, штраф в 1 балл.
Итого:
100 — (0 + 30 + 5 + 1) = 64
То есть пользователь по этому кейсу счастлив на 64 из 100.
Из примеров можно видеть, что один пользователь хочет одного, а другой другого. Пользователей с одинаковыми запросами и одинаковыми целями мы агрегируем, и таким образом у нас появляется ещё один критерий — «Количество пользователей». Те самые штрафы мы умножаем на количество пользователей.
Пусть в нашем примере Пользователей1 будет 98, а Пользователей2 —двое.
Пользователи1 100 — (0 + 0 + 5 + 0) = 95×98 = 9310
Пользователи2 100 — (0 + 30 + 5 + 1) = 64×2 = 128
В среднем обе группы пользователей будут счастливы на 94,38 балла из 100
Чтобы упростить понимание, мы берём абсолютные значения штрафов и прямое перемножение результатов. На практике следует применять нормировку значения для сравнения разных критериев и математические функции для конкретного критерия.
Если вдруг после изменений ресторан «Грабли» исчезнет в выдаче, то 98 пользователей будут абсолютно несчастны, но при этом 2 пользователя будут счастливы, но только на 64 балла из 100. В среднем обе группы пользователей будут счастливы на 1,28 балла из 100. Такое мимо релиза не пройдёт!
Прогон тестов
Чаще всего прогон тестов мы смотрим не в чистом виде, а в сравнении с прошлым разом. Так сразу понятно в совокупности по всем кейсам, насколько хорошо или плохо повлияли изменения в коде.
Также мы нейтрализуем ложные попадания. Они могут появиться из-за расхождения в данных. В мобильной версии у пользователя могут быть скачанные данные месячной давности, в них могут быть некоторые организации, которые в тестовых данных уже закрыты. Таким образом, изначально тест-кейс может не проходить.
А ещё есть давние проблемы, которые влияют на учёт. Например, наличие лишних результатов по какому‑то запросу. Мы о них знаем, тикет заведён, но «руки не дошли посмотреть». Каждый раз смотреть на данные падения нет смысла. Таким образом, мы видим только изменения по кейсам. Бывают такие сравнения, где ничего не поменялось, после рефакторинга кода такое поведение ожидаемо. В любом случае отчёт нужно смотреть и разбираться в изменениях или отсутствии таковых.
Так мы можем смотреть на всю картину в целом, понимать, насколько хороша выдача, какой процент пользователей в данный момент счастлив и насколько. И как изменения разработчика влияют на это.
Ну, и вкратце:
Собирайте и подготавливайте пользовательскую статистику. Она поможет не только воспроизвести баги, но и оттестировать пользовательские сценарии.
Выясните, какие пользовательские сценарии вы хотите проверять.
Определите идеальный для вас пользовательский сценарий (и какое «счастье» пользователей он описывает).
И самое сложное — придумайте, как и в каких единицах измерять отклонения от этого сценария. Определите, что в вашем продукте критично для пользователя, а что нет (и насколько критичен тот или иной критерий). Исходя из этого подберите методику расчёта.
