Текущая разработка Kotlin

На прошлой неделе при поддержке Redmadrobot SPB в рамках SPB Kotlin User Group прошла встреча со Станиславом Ерохиным, разработчиком из JetBrains. На встрече он поделился информацией о разрабатываемых возможностях следующей мажорной версии Котлина (под номером 1.3).
В этой статье мы подытожим полученный материал, расскажем о планах.
Важно. Дизайн всех фич, о которых пойдет речь, может быть изменен до неузнаваемости. Все, что ниже — это текущие планы команды, но никаких гарантий разработчики не дают.
Посмотреть доклад можно по ссылке на YouTube.
Введение
В ближайшей мажорной версии Kotlin (1.3) ожидается много изменений. Рассказывали нам только о некоторых из них.
Основные направления:
- Корутины
- Inline классы
- Беззнаковая арифметика
- Default методы для Java
- Метаинформация для DFA (Data Flow Analysis) и смарткастов
- Аннотации для управления type inference
- SAM для Java методов
- SAM для Kotlin методов и интерфейсов
- Smart inference для билдеров
- Изменения в схеме компилятора
Корутины
В версии 1.3 планируется долгожданный релиз корутин в Котлине, в результате чего они переберутся из пакета kotlin.coroutines.experimental в kotlin.coroutines.
Позже планируется выпустить support library для поддержки существующего API корутин.
Основные изменения в корутинах
- JetBrains активно работают над производительностью. Например, планируется, что в новой версии не будут генерироваться state-machine там, где они не нужны. За счет этого количество генерируемых объектов уменьшится
- Ведутся работы над полноценной поддержкой suspend для inline функций
- Добавится поддержка callable reference для suspend функций
- Изменится интерфейс
Continuation
В данный момент Continuation содержит два метода, которые позволяют пробросить либо результат, либо ошибку.
interface Continuation {
fun resume(value: T)
fun resumeWithException(exception: Throwable)
} В новой версии планируется использовать типизированный класс Result, содержащий в себе в каком-то виде значение или ошибку, а в Continuation оставить один метод resume(result: Result:
class Result {
val value: T?
val exception: Throwable?
}
interface Continuation {
fun resume(result: Result)
} Такая реализация сделает удобнее разработку библиотек для корутин, поскольку разработчикам не придется выполнять проверки перед каждым пробросом значения/ошибки. API этого решения точно будет изменено, но смысл сохранится.
К сожалению, у такого решения есть проблема. Чтобы все работало в текущей реализации Котлина, необходимо каждое значение оборачивать во wrapper Result, что приводит к созданию лишнего объекта на каждый вызов resume. Решением этой проблемы станут inline классы.
Inline классы
Пример для Result:
inline class Result(val o: Any?) {
val value: T?
get() = if (o is Box) null else o as T
val exception: Throwable?
get() = (o as? Box).exception
}
private class Box(val exception: Throwable) Преимущество inline классов в том, что во время выполнения объект будет храниться просто как val o, переданный в конструкторе, согласно примеру выше, а exception останется в обертке Box. Это обусловлено тем, что ошибки пробрасываются довольно редко, и генерация обертки не повлияет на производительность. Геттеры value и exception будут сгенерированы в статические методы, а сам wrapper исчезает. Это решает проблему с созданием лишних объектов при вызове Continuation.resume.
Ограничения inline классов
- Пока возможно создать inline класс только с одним полем, так как во время выполнения обертка стирается и остается только значение поля
- Если используются generics, то
Resultвсе равно будет обернут, так как после распаковки неизвестно, обернутый вернулся объект или нет (например, если мы используемList)
Беззнаковая арифметика
Одно из возможных следствий появления inline классов — unsigned типы:
inline class UInt(val i: Int)
inline class ULong(val l Long)
...В стандартной библиотеке для каждого примитива будут описаны соответствующие беззнаковые варианты, в которых будут реализована работа с арифметическими операторами, а также базовые методы, такие как toString().
Также будет добавлена поддержка литералов и неявное преобразование.
Default методы
В интерфейсах Котлина методы со стандартной реализацией появились раньше, чем в Java.
Если интерфейс написан на Котлине, а реализация — на Java 8, то для методов со стандартной реализацией можно будет использовать аннотацию @JvmDefault, чтобы с точки зрения Java этот метод был помечен как default.
Метаинформация для DFA и смарткастов
Ещё одна интересная разрабатываемая штука — контракты, с помощью которых можно добавлять метаинформацию для DFA (Data Flow Analysis) и смарткастов. Рассмотрим пример:
fun test(x: Any) {
check(x is String)
println(x.length)
}В функцию check(Boolean) передается результат проверки на принадлежность x типу String. На данном уровне неизвестно, что эта функция делает внутри, поэтому следующая строка кода вызовет ошибку (smart-cast в данном случае невозможен). Компилятор не может быть уверен, что x это String. Объяснить ему это помогут контракты.
Вот реализация check с контрактом:
fun check(value: Boolean) {
contract {
returns() implies value
}
if (!value) throw ...
}Здесь добавлен вызов функции contract с довольно специфическим синтаксисом, который говорит о том, что если этот метод возвращает результат, этот результат точно true. Иначе будет выброшено исключение.
Благодаря такому контракту, компилятор сможет для x выполнить smart-cast, и при вызове println(x.length) не будет ошибки.
Помимо разрешения ситуаций с неизвестными типами, контракты позволят решать и другие проблемы. Например:
fun test() {
val x: String
run { x = "Hello" }
println(x.length)
}
fun run(block: () -> R): R {
contract {
callsInPlace(block, EXACTLY_ONCE)
}
return block()
} Контракт в функции run сообщает компилятору, что переданный block будет вызван ровно один раз, константа x корректно проинициализируется и x.length выполнится без ошибки.
Контракты используются компилятором, но не влияют на полученный в результате компиляции код. Все контракты преобразуются в метаинформацию, которая сообщает компилятору о некоторых допущениях в определенных функциях.
В IDE планируется определенная подсветка контрактов и автогенерация, где это будет возможно.
Аннотации для управления type inference
В stdlib Котлина уже есть различные фичи, которые используются только внутри. Некоторыми из них разработчики готовы поделиться. Рассмотрим новые аннотации и возможности, которые они предоставляют:
@NoInfer
Аннотация @NoInfer призвана делать type inference немного умнее.
Допустим, мы хотим отфильтровать коллекцию, используя метод filterIsInstance. В данном методе важно указать тип, по которому будет выполняться фильтрация, но компилятор может допустить вызов и без прописывания типа (попытаясь его вывести). Если же в сигнатуре использовать @NoInfer, то вызов без типа выделится, как ошибка.
fun print(c: Collection) { ... }
val c: Collection
print(c.filterIsInstance()) //ошибка
print(c.filterIsInstance())
fun Iterable<*>.filterIsInstance(): List<@NoInfer R> @Exact
Эта аннотация очень похожа на @NoInfer. Она сообщает, что тип должен быть точно равен указанному, то есть не «подтип» и не «надтип».
@OnlyInputTypes
Данная аннотация указывает, что только типы, которые были у пользователя в аргументах или в ресивере, должны быть результатами inference.
SAM для Java методов
Еще одна разрабатываемая возможность упрощает работу с SAM. Рассмотрим пример:
//Java
static void test(Factory f, Runnable r)
interface Factory {
String produce();
}
//Kotlin
fun use(f: Factory) {
test(f) { } // Factory != () -> String
}В Java объявлен метод, принимающий два функциональных интерфейса. Логично, что на уровне Котлина мы должны иметь возможность вызывать этот метод, передавая как объекты-реализации интерфейсов, так и лямбда-выражения, соответствующие сигнатурам методов этих интерфейсов в любых сочетаниях:
1. test(Factory, Runnable)
2. test(Factory, () -> Unit)
3. test(() -> String, Runnable)
4. test(() -> String, () -> Unit)Сейчас варианты 2. и 3. невозможны. Компилятор Котлина допускает только два варианта: принимающий два интерфейса и принимающий две лямбды.
Сделать возможными все 4 варианта при текущей реализации компилятора — сложная задача, но не невыполнимая. В новой системе type inference будет поддержка таких ситуаций. В среде будет видна только одна функция fun test(Factory, Runnable), но передавать можно будет как лямбды, так и объекты-реализации интерфейсов в любом сочетании.
SAM для Kotlin методов и интерфейсов
В случае, если в Котлине определен метод, принимающий Котлин-интерфейс, то чтобы происходила автоматическая конверсия (можно передавать как реализацию интерфейса, так и лямбду), необходимо пометить интерфейс ключевым словом sam.
sam interface Predicate {
fun test(t: T): Boolean
}
fun Collection.filter(p: Predicate): Collection { ... }
fun use() {
test { println("Hello") }
val l = listOf(-1, 2, 3)
l.filter { it > 0 }
} Для Java интерфейсов конверсия будет работать всегда.
Smart inference для билдеров
Представим, что мы хотим написать билдер:
fun buildList(l: MutableList.() -> Unit): List { ... } И хотим его использовать вот так:
val list = buildList {
add("one")
add("two")
}В данный момент это невозможно, так как тип T не выводится из вызовов add(String). Поэтому приходится писать так:
val list = buildList {
add("one")
add("two")
} Планируется, что можно будет использовать первый вариант (без явного указания типа).
Изменения в схеме компилятора
В JetBrains ведется активная работа над Kotlin Native. Как следствие появилось еще одно звено в схеме компилятора — Back-end Internal Representation (BE IR).
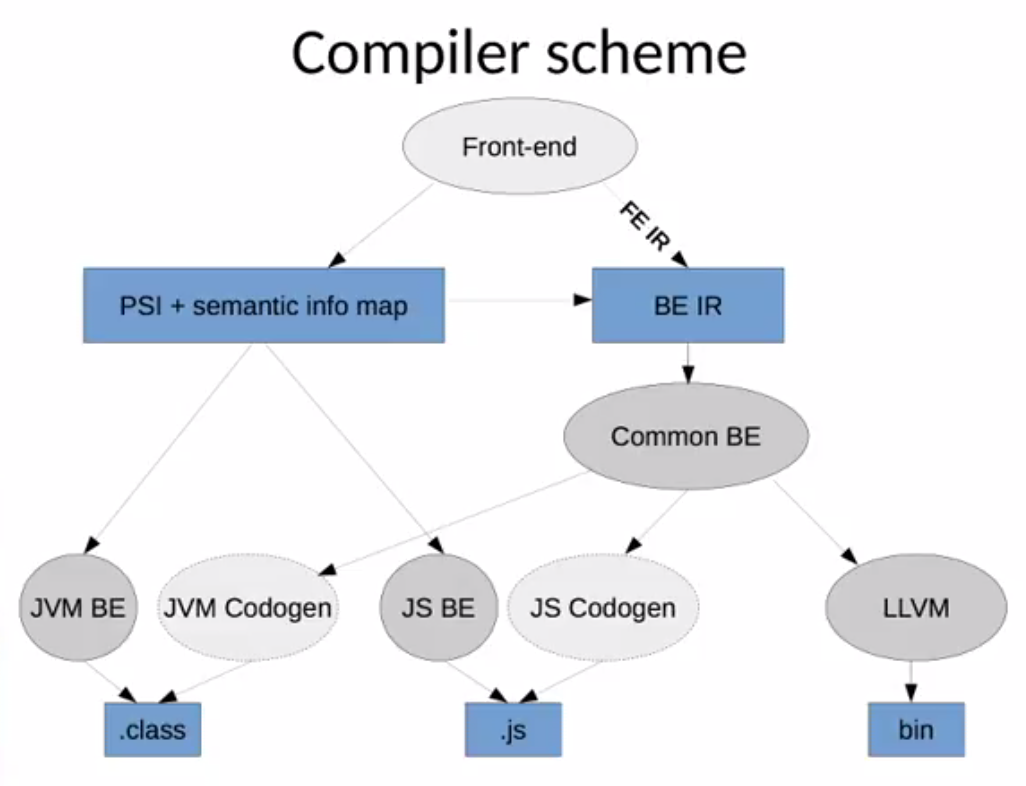
BE IR — это промежуточное представление, содержащее всю семантику исходного кода, который может быть скомпилирован под исполняемые файлы любой платформы, включая бинарный код системы. Сейчас BE IR используется только в Kotlin Native, но его планируется использовать для всех платформ, вместо PSI с дополнительной информацией о семантике. Для JVM и JS уже есть прототипы, и они активно дорабатываются.
В итоге весь исходный код будет преобразовываться в BE IR, а затем в исполняемые файлы целевой платформы.
Резюме
Как было написано выше, неизвестно, какие новшества дойдут до релиза, в каком виде и в какой версии языка. Есть только текущие планы команды Kotlin, но разработчики никаких гарантий не дают:
- Релиз и финализация API корутин — 1.3
- Inline классы — экспериментальная возможность в 1.3
- Беззнаковая арифметика — экспериментальная возможность в 1.3 или 1.4
- @JvmDefault — экспериментальная возможность в 1.2.x, релиз в 1.3
- Метаинформация для DFA и смарткастов — частично релиз в 1.3
- Аннотации для управления type inference — экспериментальная возможность в 1.2.x
- Новый движок type inference (включая SAM и Smart inference для билдеров) — экспериментальная возможность в 1.3
Kotlin — без сомнения, состоявшийся язык программирования, но с увеличением пользовательской базы расширяется и спектр его применения. Появляются новые требования, платформы и варианты использования. Накапливается старый код, который требуется поддерживать. Разработчики языка понимают сложности и проблемы и работают с ними, в результате новые версии позволят еще удобнее им пользоваться в большем количестве ситуаций.
