T-test. Зависимость от независимости
Привет, Хабр! Теме А/Б-тестирования посвящено достаточно много статей, и вот держите ещё одну. Тема экспериментов для выявления эффективности внедрения доработок популярна не только последний год и она, скорее всего, освещена уже со всех возможных сторон:
Но большинство этих статей объединяет одна черта — они рассматривают случай сравнения независимых выборок. А вот найти информацию по тестированию зависимых оказалось не такой тривиальной задачей.
Что же такое тестирование зависимых выборок и почему так мало информации?
Самый распространённый пример тестирования зависимых выборок, на который я натыкался, выглядит примерно так:
»… пусть выбрана группа людей X и на периоде T1 замерена их характеристика. Затем на периоде T2 они подвергаются воздействию и характеристика замеряется повторно. Таким образом мы изучаем воздействие в контексте одних и тех же людей, поэтому выборки (а вообще говоря выборка) являются зависимыми. Для этого воспользуемся …»
Такой пример на практике встречается достаточно редко, так как с течением времени на наши объекты исследования влияет множество факторов помимо нашего воздействия. Но сам случай тестирования зависимых выборок на практике встречается достаточно часто и, возможно, даже чаще, чем тестирование независимых выборок. Ведь само понятие «независимые выборки» подразумевает случайный подбор групп из генеральной совокупности, а такой способ в конкретном случае может подобрать весьма различающиеся между собой группы.
А если мы дизайним какой-то важный эксперимент, кто из нас не посмотрит на то, как различаются подобранные нами группы до эксперимента? А ещё лучше — посмотрим на то, чтобы они ещё и сходились на протяжении какого-то периода в динамике. А если они не сходятся, то «случайно» переподберём ещё разок, и ещё, пока не получим удовлетворительный результат. А если проверять долго, то лучше заранее задумаемся о том, каким бы таким алгоритмом найти похожие друг на друга объекты и распределить их в обе наших группы?
И вот в таких случаях наше предположение о независимости начинает сыпаться. Конечно, оно разрушается не полностью, и обычно возникает следующая ситуация: мы проводим множество АА-тестов с нашим алгоритмом подбора, получаем ошибку первого рода меньше ожидаемой и принимаем решение из разряда «ну, меньше — не больше, значит, хуже точно не будет, катим».
Поэтому данную статью я бы хотел посвятить именно разбору случая тестирования зависимых выборок на простых примерах.
P.S. Я не против комментариев «эта тема уже 100500 раз разбиралась», только прошу, подкрепляйте эти слова соответствующими ссылками. Так мы сделаем эту статью только полезнее)
Про код
В ходе статьи я буду приводить примеры кода, но, скорее всего, их будет не очень удобно собирать воедино. Поэтому оставляю здесь ссылку на шаблон статьи, который я собирал непосредственно в тетрадке.
Библиотечки, которые нам сегодня понадобятся
import numpy as np
import pandas as pd
from scipy import stats
import matplotlib.pyplot as plt
import seaborn as sns
from tqdm import tqdm
from sklearn import metricsКлассический случай
Предлагаю начать наш разбор с самого классического случая. Предположим, что интересующая нас метрика на генеральной совокупности распределена нормально  , где
, где  ,
,  .
.
Мы хотим провести А/Б-эксперимент на таком множестве, и для этого нам нужно зафиксировать основные параметры этого эксперимента. Предположим, что:
Зададим параметры
# Параметры ген.совокупности
mu = 1000
sigma = 100
dist_gen = stats.norm(loc=mu, scale=sigma)
# Параметры эксперимента
mde = 5
alpha = 0.05
beta = 0.2
power = 1 - betaТеперь, чтобы начать наш эксперимент, нам осталось только определить размер группы. Для этого можем воспользоваться классической формулой, которая будет несколько видоизменяться в зависимости от случая.
1. В случае, если мы хотим проверить гипотезу о том, что среднее нашей выборки отлично от некоторого заданного  , формула будет выглядеть следующим образом:
, формула будет выглядеть следующим образом:
 — значения стандартного нормального распределения, соответствующее
— значения стандартного нормального распределения, соответствующее 
 — стандартное отклонение нашей выборки. Так как размер выборки мы планируем брать большой, то можно принять это значение равным
— стандартное отклонение нашей выборки. Так как размер выборки мы планируем брать большой, то можно принять это значение равным  генеральной совокупности
генеральной совокупности
2. В случае же, если мы сравниваем между собой среднее двух выборок одинакового размера, то  . А так как обе выборки мы будем набирать из одной генеральной совокупности, то
. А так как обе выборки мы будем набирать из одной генеральной совокупности, то  и в числителе просто появится двойка.
и в числителе просто появится двойка.
Функция расчёта размера выборки
def calc_sample_size(mde, alpha, beta, sigma, one_sample=False):
"""Функция расчёта размера выборки"""
# расчёт дисперсии в зависимости от того, сравниваем мы 2 выборки, или 1 с константой
if not one_sample:
sigma = np.sqrt(2) * sigma
# расчёт размера выборки
norm_dist = stats.norm()
fi_alpha = norm_dist.ppf(1 - alpha / 2)
fi_beta = norm_dist.ppf(1 - beta)
sample_size = ((fi_alpha + fi_beta) ** 2) * (sigma ** 2) / (mde ** 2)
return int(sample_size)sample_size = calc_sample_size(mde, alpha, beta, sigma, one_sample=False)
print(sample_size)
6279
В нашем случае мы хотим именно сравнить две выборки, поэтому подставив все параметры в формулу, мы получим, что размер нашей группы будет равен 6279 элементам.
Все параметры эксперимента зафиксированы, мы — дизайнеры хоть куда. Давайте проверим теперь, что мы всё сделали верно. Для этого нам потребуется провести искусственный эксперимент несколько сотен раз и посчитать ошибки первого и второго рода. Благо, на синтетических данных это не представляет никакого труда. Более подробно с методикой проверки корректности А/Б тестов можно ознакомиться здесь.
Все нужные нам функции
def select_samples_random(sample_size):
"""Набираем 2 случайные группы заданного размера из генеральной совокупности"""
a = dist_gen.rvs(size=sample_size).reshape(-1, 1)
b = dist_gen.rvs(size=sample_size).reshape(-1, 1)
samples = np.concatenate((a, b), axis=1)
return samples
def calc_pvalue_iid(samples):
"""Считаем уровень значимости в случае двух независимых выборок"""
return stats.ttest_ind(samples[:, 0], samples[:, 1])[1]
def check_ttest(mde, sample_selector, sample_size, pvalue_calculator, n_boots=2000):
"""Считаем эффекты на n_boots случайных подборах"""
dist_effect = stats.norm(loc=mde, scale=mde)
p_values_aa = []
p_values_ab = []
for _ in tqdm(range(n_boots)):
# Рассчитываем p-value без эффекта
samples = sample_selector(sample_size)
p_values_aa.append(pvalue_calculator(samples))
# Рассчитываем p-value c эффектом
effect = dist_effect.rvs(size=sample_size)
samples[:, 1] += effect
p_values_ab.append(pvalue_calculator(samples))
p_values_aa = np.array(p_values_aa)
p_values_ab = np.array(p_values_ab)
return p_values_aa, p_values_ab
def plot_pvalue_distribution(pvalues_aa, pvalues_ab, alpha, subtitle=''):
"""Рисует графики распределения p-value."""
estimated_first_type_error = np.mean(pvalues_aa < alpha)
estimated_second_type_error = np.mean(pvalues_ab >= alpha)
y_one = estimated_first_type_error
y_two = 1 - estimated_second_type_error
X = np.linspace(0, 1, 1000)
Y_aa = [np.mean(pvalues_aa < x) for x in X]
Y_ab = [np.mean(pvalues_ab < x) for x in X]
plt.figure(figsize=(14,7))
plt.plot(X, Y_aa, label='A/A')
plt.plot(X, Y_ab, label='A/B')
plt.plot([alpha, alpha], [0, 1], '--k', alpha=0.8)
plt.plot([0, alpha], [y_one, y_one], '--b', alpha=0.8, label=f'Ошибка первого рода = {estimated_first_type_error:.2f}')
plt.plot([0, alpha], [y_two, y_two], '--', alpha=0.8, label=f'Мощность = {y_two:.2f}')
plt.plot([0, 1], [0, 1], '--k', alpha=0.8)
title = 'Оценка распределения p-value.\n'
title += subtitle
plt.title(title, size=16)
plt.xlabel('p-value', size=12)
plt.legend(fontsize=12)
plt.grid()
plt.show()Запускаем эксперименты
pvalues_aa, pvalues_ab = check_ttest(
mde, select_samples_random, sample_size, calc_pvalue_iid
)
plot_pvalue_distribution(pvalues_aa, pvalues_ab, alpha, 'Двухвыборочный тест. Случайный подбор.');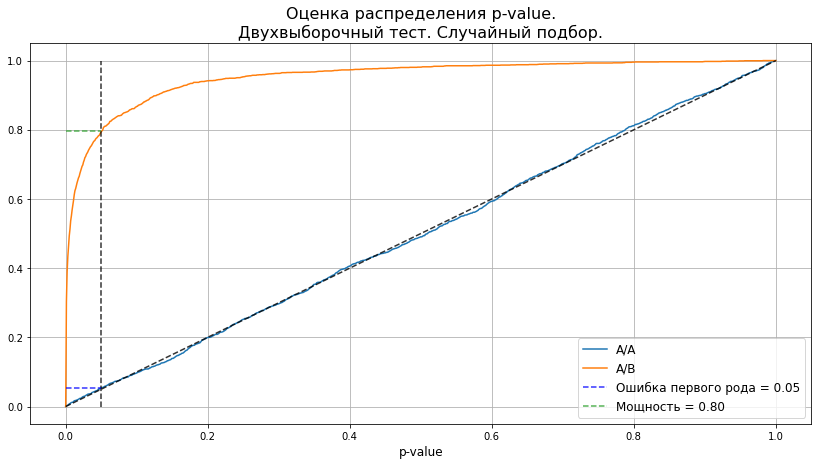
График показывает, что p-value в случае А/А-теста распределён равномерно и уровень ошибок первого рода сохраняется на уровне 5%. А в случае, когда мы добавили синтетический эффект, мощность теста близка к 80%. Всё, как мы и ожидали.
Неслучайный подбор групп
Несмотря на то, что в классическом случае мы получили верный результат, в левом нижнем углу графика собрались кейсы, которые мы вряд ли бы допустили в эксперимент (те случаи, когда выборки расходятся ещё до эксперимента). Обычно, чтобы не допустить случая расхождения групп на этапе их подбора, используются алгоритмы поиска похожих элементов. Давайте рассмотрим, как поведёт себя статистика в случае использования такого алгоритма.
О самом алгоритме сделаем предположение, что он в среднем подбирает похожие объекты, но в нём присутствует некоторый элемент случайности. То есть  .
.
При этом предположим, что стандартное отклонение подбора хотя бы в 2 раза меньше, чем стандартное отклонение генеральной совокупности  .
.
Генерация «похожих» выборок
def select_samples_similar(sample_size, sigma_s=50):
"""Подбор "похожих" групп"""
# дисперсии выборок
var_x = var_y = sigma ** 2
# ковариация
var_xy = var_x - sigma_s ** 2
cov_xy = (var_x + var_xy) / 2
# генерация зависимых выборок
mean = [mu, mu]
cov = [[var_x, cov_xy], [cov_xy, var_y]]
samples = np.random.multivariate_normal(mean, cov, sample_size)
return samples
# Проверим, что никого не обманули
s = select_samples_similar(100000, sigma_s=50)
x = s[:, 0]
diff = s[:, 0] - s[:, 1]
print(f'Распределение выборки: mean = {x.mean():.1f}, std = {x.std():.1f}')
print(f'Распределение разностей: mean = {diff.mean():.1f}, std = {diff.std():.1f}')Распределение выборки: mean = 999.7, std = 100.1
Распределение разностей: mean = -0.4, std = 50.1
Запускаем эксперименты
pvalues_aa, pvalues_ab = check_ttest(
mde, select_samples_similar, sample_size, calc_pvalue_iid
)
plot_pvalue_distribution(pvalues_aa, pvalues_ab, alpha, 'Двухвыборочный тест. Неслучайный подбор.');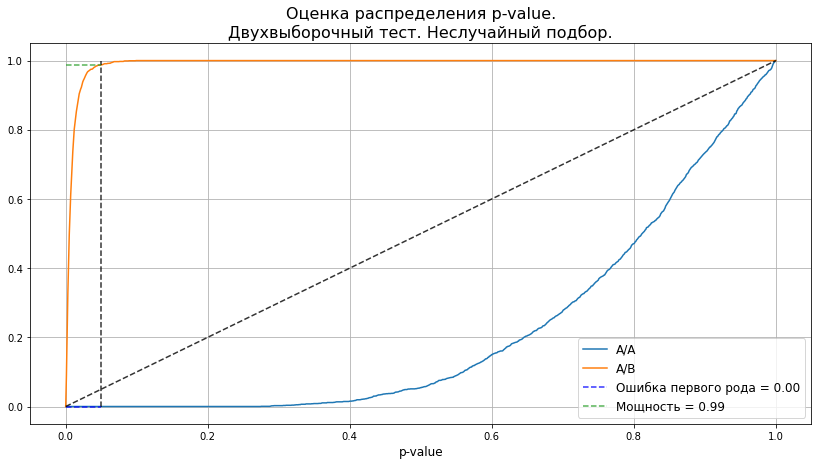
График показывает, что такой алгоритм действительно улучшил результаты, и мы исключили случаи подбора статистически различных групп. Если говорить о пойманных эффектах, то мощность теста также значительно подросла.
То есть критерий Стьюдента для независимых выборок вроде и работает, а вроде и нет, так как мы получаем хоть и меньшие, но явно не те ошибки. Выборки-то у нас уже получились весьма зависимыми. А в случае зависимых выборок предлагается посмотреть в сторону одновыборочного критерия Стьюдента и применить его для попарных разностей зависимых элементов.
Одновыборочный критерий попарных разностей
В данном случае мы переформулируем задачу. Вместо того, чтобы проверять нулевую гипотезу о том, что средние двух независимых выборок равны, поступим следующим образом:
Составим выборку попарных разностей
 , где
, где 
 ,
, 
В силу ЦПТ выборочное среднее выборки  .
.
Выглядит, как «перемена мест слагаемых» — то есть мы просто взглянули на задачу под другим углом. А если это так, то этот критерий должен работать и в нашем классическом кейсе случайного подбора. Давайте в этом убедимся.
Случайный подбор
Если из генеральной совокупности  мы выберем 2 группы одинакового размера и поэлементно вычтем из одной другую, то мы получим выборку с распределением
мы выберем 2 группы одинакового размера и поэлементно вычтем из одной другую, то мы получим выборку с распределением  .
.
Далее воспользуемся формулой расчёта размера выборки для одновыборочного критерия, которая должна дать нам тот же результат 6279.
Код
sample_size = calc_sample_size(mde, alpha, beta, np.sqrt(2) * sigma, one_sample=True)
print(sample_size)6279
Ну и затем применим на случайных выборках одновыборочный критерий для попарных разностей.
Запускаем эксперименты
def calc_pvalue_rel(samples):
"""Считаем уровень значимости в случае двух зависимых выборок"""
return stats.ttest_rel(samples[:, 0], samples[:, 1])[1]
pvalues_aa, pvalues_ab = check_ttest(
mde, select_samples_random, sample_size, calc_pvalue_rel
)
plot_pvalue_distribution(pvalues_aa, pvalues_ab, alpha, 'Одновыборочный тест. Случайный подбор.');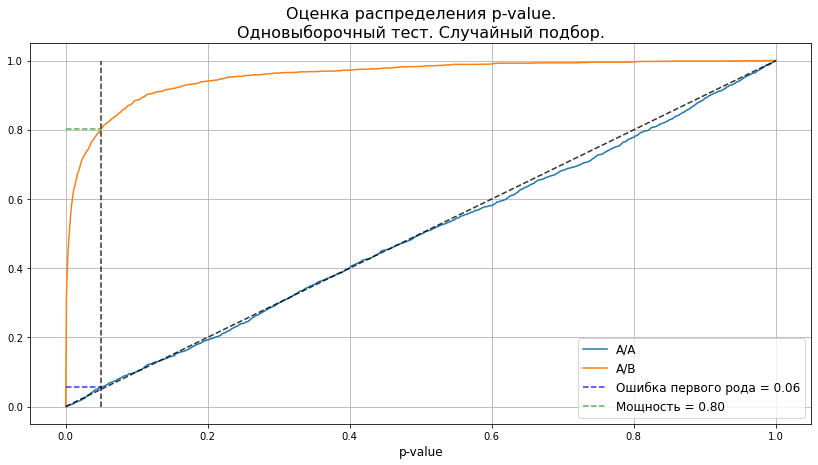
Бинго, критерий работает! А значит, мы движемся в верном направлении и можем переходить к кейсу неслучайного подбора.
Зависимые выборки
В нашем случае мы достоверно знаем, что дисперсия выборки попарных разностей будет равна заданной ( ). Подставим в формулу и получим размер выборки 784.
). Подставим в формулу и получим размер выборки 784.
Код
sample_size = calc_sample_size(mde, alpha, beta, 50, one_sample=True)
print(sample_size)784
Даже такое, казалось бы, незначительное снижение стандартного отклонения существенно сказывается на размере выборки. Это происходит в силу двух факторов:
При случайном подборе, как мы говорили, отклонение разностей
 . Поэтому даже если бы выбранным алгоритмом мы получили отклонение разностей
. Поэтому даже если бы выбранным алгоритмом мы получили отклонение разностей  , то мы бы выиграли относительно случайного подбора, так как при случайном мы бы получили стандартное отклонение не
, то мы бы выиграли относительно случайного подбора, так как при случайном мы бы получили стандартное отклонение не  , а
, а  .
.Согласно формуле, зависимость размера выборки от стандартного отклонения носит квадратичный характер. Поэтому снижение этого отклонения в 2 раза приводит к 4-кратному снижению размера выборки.
Осталось проверить, действительно ли этой выборки хватит.
Запускаем эксперименты
pvalues_aa, pvalues_ab = check_ttest(
mde, select_samples_similar, sample_size, calc_pvalue_rel
)
plot_pvalue_distribution(pvalues_aa, pvalues_ab, alpha, 'Одновыборочный тест. Неслучайный подбор.');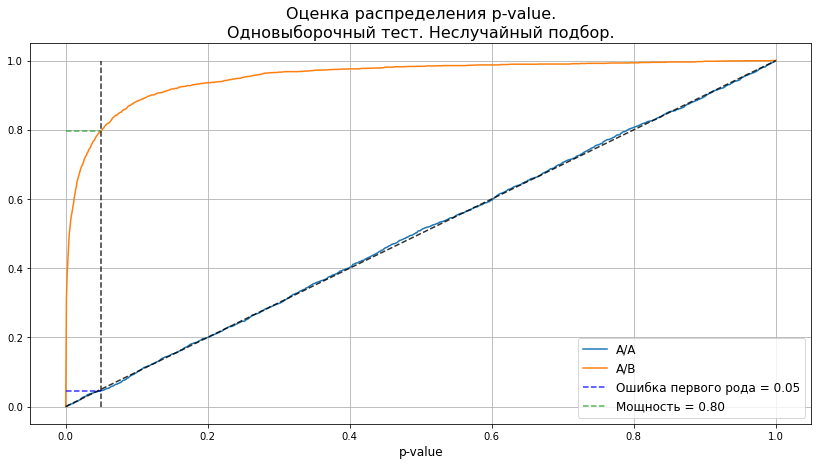
Получили знакомую нам верную картину. Таким образом, при значительном снижении размера выборки мы можем добиться заложенных при дизайне эксперимента уровней ошибок.
Но, как мы помним, двухвыборочный тест в случае зависимых выборок тоже давал лучшие результаты. Давайте проверим, не сработает ли он для нового размера выборки?
Запускаем эксперименты
pvalues_aa, pvalues_ab = check_ttest(
mde, select_samples_similar, sample_size, calc_pvalue_iid
)
plot_pvalue_distribution(pvalues_aa, pvalues_ab, alpha, 'Двухвыборочный тест. Неслучайный подбор.');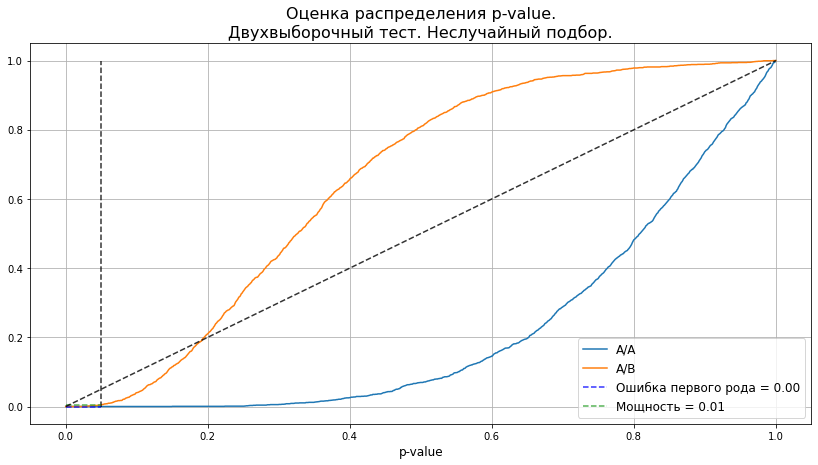
Нет, как видим, двухвыборочный критерий для таких выборок не работает. Ошибка первого рода остаётся заниженной, а эффект мы обнаружить не можем. Иными словами, для двухвыборочного критерия выборки слишком похожи.
Теоретические итоги
Итак, напомним, что у нас была генеральная совокупность, на которой метрика была распределена нормально  . На такой генеральной совокупности мы проводили синтетический эксперимент, для которого фиксировали следующие параметры:
. На такой генеральной совокупности мы проводили синтетический эксперимент, для которого фиксировали следующие параметры:
Эффект



Мы рассмотрели два варианта подбора и применили к ним два типа критериев. Результаты можно представить в таблице соответствия итоговых уровней ошибок заявленным:

Итого, можно сказать следующее.
При использовании неслучайного алгоритма подбора групп можно использовать классический двухвыборочный тест Стьюдента. Проблема в том, что при оценке размера группы с использованием дисперсии генеральной совокупности, мы получим весьма завышенный размер группы. Как следствие, ошибки первого и второго рода в таком эксперименте будут сильно отличаться от заявленных, хоть и в меньшую сторону.
Одновыборочный же критерий Стьюдента хорошо себя чувствует как в классическом кейсе случайного подбора, так и в случае подбора одной выборки под другую. Аналогичные выводы можно найти в статье от Авито в разделе про «парную стратификацию». Но проблемы у одновыборочного критерия тоже есть. Во-первых, этот критерий требует одинакового размера выборок. Во-вторых, в наших теоретических кейсах мы задавали дисперсию руками, а вот в реальности её нужно будет как-то оценить.
Так что теория — это хорошо. Но давайте проверим, насколько она применима к реальным данным.
Реальные данные
Для проверки нашей теории на реальных данных были собраны три группы пользователей, соответствующие трём последовательным временным периодам. Для каждого из этих периодов были посчитаны значения интересующей нас метрики, а также значения некоторых признаков пользователей, основанных на их поведении в прошлом. Естественно, всё было нормированно. Давайте посмотрим на эти данные.
users_features.head()
plt.figure(figsize=(14,7))
plt.title('Распределение метрики на периодах.', size=16)
for i in range(1, 4):
sns.kdeplot(users_features.loc[users_features['period'] == i, 'target'], label=f'period_{i}')
plt.xlim(-3, 5)
plt.grid()
plt.legend(fontsize=12);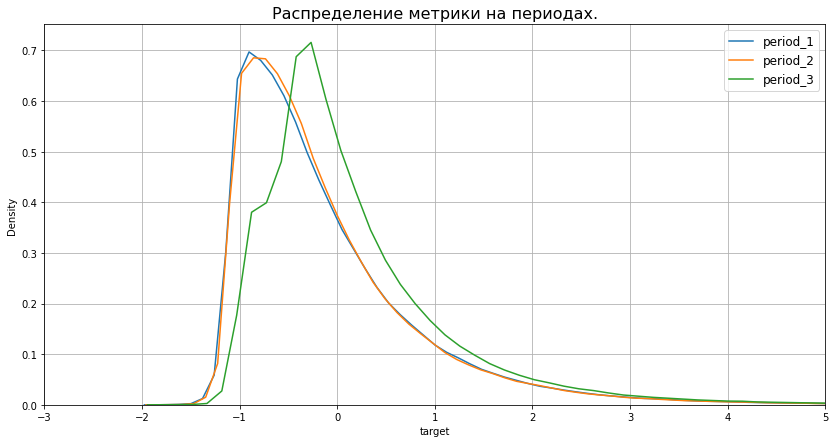
Из графика видно, что наша метрика распределена уже совсем не нормально, а на третьем периоде её распределение ещё и сильно отличается от двух предыдущих. Ну, тем веселее будет проверять (:
Алгоритм подбора групп
В реальности, помимо ненормальности распределения метрик мы сталкиваемся с ещё одной большой проблемой — изменчивость данных с течением времени. Ведь группы мы подбираем раньше, чем проводим эксперимент.
Поэтому для исследования алгоритма подбора нам потребуются два периода: на периоде 1 будем подбирать группы, а на периоде 2 будем проверять, насколько наши группы разошлись при условии, что уникальных воздействий ни на одну из групп не производилось.
Заберём нужный нам кусочек данных
data = users_features.loc[users_features['period'] == 2, :].drop(columns='period').dropna()
# отсортируем по размеру вектора признаков
data['sort_column'] = (data.iloc[:, 2:] ** 2).sum(axis=1)
data = data.sort_values('sort_column')С данными разобрались, осталось выбрать алгоритм. Для данного примера я решил выбрать алгоритм подбора групп на основе близости пользователей по косинусному расстоянию между векторами их признаков. Обычно подбор по косинусному расстоянию даёт весьма неплохие результаты, но самым большим минусом этого алгоритма является время его работы. Поэтому в данной статье я выбрал следующую его версию:
сортируем всех данные по длине вектора их признаков (это мы уже сделали);
разбиваем весь массив на количество подмассивов, равное размеру требуемой нам группы;
в каждом подмассиве выбираем случайный элемент в пилотную группу, а затем самый близкий (по косинусному расстоянию) к нему элемент из того же подмассива в контрольную группу.
Алгоритм подбора групп
def select_samples_pairwise(sample_size):
"""
Пользователи в ЦГ набираются случайно из генеральной совокупности.
Каждому пользователю в ЦГ подбирается максимально похожий в смысле косинусного расстояния
пользователь из ген.совокупности.
"""
features_cols = [col for col in data.columns if 'feature' in col]
# Разбиваем ген.совокупность на батчи
data['group'] = np.arange(len(data)) // (len(data) / sample_size)
# Инициализируем группы
pg = pd.DataFrame()
cg = pd.DataFrame()
# Из каждого батча по 1 элементу в группы
for _, group in data.groupby('group'):
# Случайный элемент в пилот
pg_sample = group.sample().drop(columns='group')
pg_sample_vector = pg_sample[features_cols].values
# Убираем выбранный элемент из группы
general_sample = group.loc[group['user_id'] != pg_sample['user_id'].iloc[0], :]
general_sample_vector = general_sample[features_cols].values
# выбираем ближайший элемент в котнроль
similarity = metrics.pairwise.cosine_similarity(pg_sample_vector, general_sample_vector)
index = np.argmax(similarity)
cg_sample = general_sample.iloc[[index], :].drop(columns='group')
pg = pg.append(pg_sample)
cg = cg.append(cg_sample)
return cg, pgДавайте посмотрим на качество подбора групп таким алгоритмом.
Код проверки
# осуществим подбор групп размером в 1000 элементов 300 раз
test_size = 1000
cg, pg = select_samples_pairwise(test_size)
for _ in tqdm(range(50)):
cg_l, pg_l = select_samples_pairwise(test_size)
cg = pd.concat((cg, cg_l))
pg = pd.concat((pg, pg_l))
# сформируем выборку попарных разностей
delta_preperiod = cg['prev_target'].to_numpy() - pg['prev_target'].to_numpy()
delta_pilot = cg['target'].to_numpy() - pg['target'].to_numpy()
sigma_d_fact = delta_pilot.std()
print(f'Характеристики генеральной совокупности: mu={data["target"].mean():.2f}, sigma={data["target"].std():.2f}')
print(f'Характеристики разностей на препериоде: mu={delta_preperiod.mean():.2f}, sigma={delta_preperiod.std():.2f}')
print(f'Характеристики разностей на периоде пилота: mu={delta_pilot.mean():.2f}, sigma={sigma_d_fact:.2f}')Характеристики генеральной совокупности: mu=-0.09, sigma=0.98
Характеристики разностей на препериоде: mu=-0.00, sigma=0.15
Характеристики разностей на периоде пилота: mu=-0.01, sigma=0.81
Видно, что в получившихся группах на периоде, где мы их подбирали, стандартное отклонение попарных разностей существенно меньше отклонения генеральной совокупности: 0.15 против 0.98. Но с течением времени группы начинают расходиться, и стандартное отклонение вырастает до 0.81, что в свою очередь всё же меньше, чем 0.98.
Немного о переобучении
Изменчивость во времени также не даёт нам выбрать похожих пользователей только по одной целевой метрике. Это стандартная проблема переобучения: на периоде подбора наши группы получатся идеальными, но на следующем периоде группы существенно разойдутся. Давайте убедимся:
def select_samples_target(sample_size):
"""Подбор на основе близости таргета"""
# Случайная пилотная группа
pg = data.sample(sample_size).sort_values('prev_target')
# Помечаем в генеральной совокупности случайный пилот
general = data.sort_values('prev_target')
general['pg'] = 0
general.loc[general['user_id'].isin(pg['user_id']), 'pg'] = 1
# Отбираем ближайших пользователей в контроль
cg_users = []
stack = 0
for _, v in general.iterrows():
if v['pg'] == 1:
stack += 1
continue
if stack > 0:
cg_users.append(v['user_id'])
stack -= 1
continue
cg = general[general['user_id'].isin(cg_users)].sort_values('prev_target')
return cg, pg
cg, pg = select_samples_target(30000)
delta_preperiod = cg['prev_target'].to_numpy() - pg['prev_target'].to_numpy()
delta_pilot = cg['target'].to_numpy() - pg['target'].to_numpy()
sigma_d_fact = delta_pilot.std()
print(f'Характеристики генеральной совокупности: mu={data["target"].mean():.2f}, sigma={data["target"].std():.2f}')
print(f'Характеристики разностей на препериоде: mu={delta_preperiod.mean():.2f}, sigma={delta_preperiod.std():.2f}')
print(f'Характеристики разностей на периоде пилота: mu={delta_pilot.mean():.2f}, sigma={sigma_d_fact:.2f}')Характеристики генеральной совокупности: mu=-0.09, sigma=0.98
Характеристики разностей на препериоде: mu=0.00, sigma=0.00
Характеристики разностей на периоде пилота: mu=-0.01, sigma=0.98
Как и ожидали. Дисперсия на периоде подбора нулевая, но вот на периоде, где мы собрались пилотироваться, она уже приближается к дисперсии ген.совокупности. Это, конечно, всё равно даёт нам выигрыш, так как при случайном подборе нам нужно будет умножать 0.98 на  , но всё же, если подбирать похожих пользователей в более общем смысле (по более широкому набору признаков), результат будет лучше.
, но всё же, если подбирать похожих пользователей в более общем смысле (по более широкому набору признаков), результат будет лучше.
Эксперимент
Данные у нас есть, с алгоритмом мы определились. Теперь давайте попробуем подтвердить наши теоретические выводы на практике путём проведения синтетических тестов, и начнём с фиксации параметров эксперимента. Пусть мы хотим:
отловить эффект

с ошибкой первого рода

и ошибкой второго рода

При выборе алгоритма подбора групп мы оценили cтандарное отклонение:
Подставив все эти параметры в формулу, мы получим, что размер группы для двухвыборочного критерия при случайном подборе будет равен 3076, а для обновыборочного с использованием нашего алгоритма всего 1050. Таким образом, наш алгоритм даёт нам выигрыш практически в 3 раза!
Код
mde = 0.07
alpha = 0.05
beta = 0.2
sample_size = calc_sample_size(mde, alpha, beta, 0.98, one_sample=False)
print(sample_size)3076
sample_size = calc_sample_size(mde, alpha, beta, 0.81, one_sample=True)
print(sample_size)1050
Осталось только убедиться в том, что наш алгоритм действительно работает.
Запускаем эксперименты
def select_samples_algo(sample_size):
"""Выбор ПГ и КГ из генеральной совокупности через косинусное расстояние"""
cg, pg = select_samples_pairwise(sample_size)
a = cg['target'].to_numpy().reshape(-1, 1)
b = pg['target'].to_numpy().reshape(-1, 1)
samples = np.concatenate((a, b), axis=1)
return samples
pvalues_aa, pvalues_ab = check_ttest(
mde, select_samples_algo, sample_size, calc_pvalue_rel, n_boots=300
)
plot_pvalue_distribution(pvalues_aa, pvalues_ab, alpha, 'Период 2.');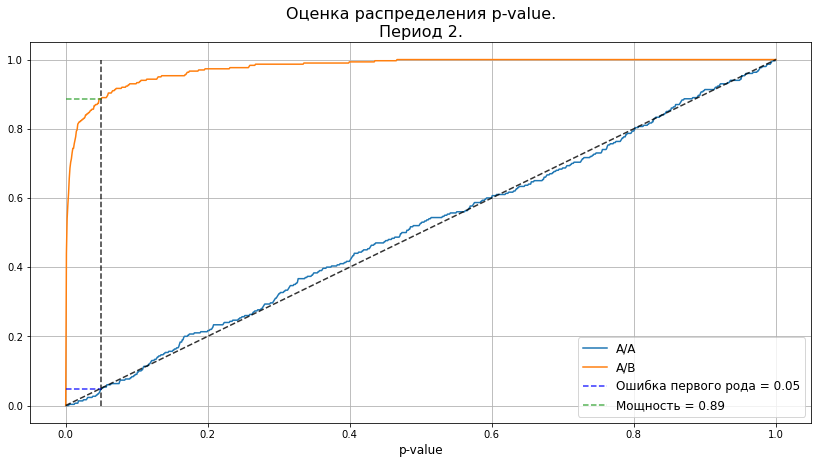
Уровень ошибок несколько отличается от заложенного. Это вызвано тем, что дисперсию мы всё-таки оценивали, а в самом подборе присутствует доля случайности. Но по графикам видно, что в целом, распределение p-value очень близко к виду, который мы получали на синтетике. А это говорит о том, что наша теория скорее работает, чем нет.
Осталось подсветить последний момент: использование периода 2 для эксперимента не совсем корректно, так как на нём мы оценивали дисперсию нашего алгоритма. В реальности, мы не можем знать, насколько наши группы разойдутся на пилоте. Поэтому давайте посмотрим, насколько хорошо работает наша оценка дисперсии на периоде 3. При этом мы помним, что само распределение метрики на периоде 3 существенно отличается от периодов 1 и 2.
Запускаем эксперименты
data = users_features.loc[users_features['period'] == 3, :].drop(columns='period').dropna()
# отсортируем по размеру вектора признаков
data['sort_column'] = (data.iloc[:, 2:] ** 2).sum(axis=1)
data = data.sort_values('sort_column')
pvalues_aa, pvalues_ab = check_ttest(
mde, select_samples_algo, sample_size, calc_pvalue_rel, n_boots=300
)
plot_pvalue_distribution(pvalues_aa, pvalues_ab, alpha, 'Период 3.');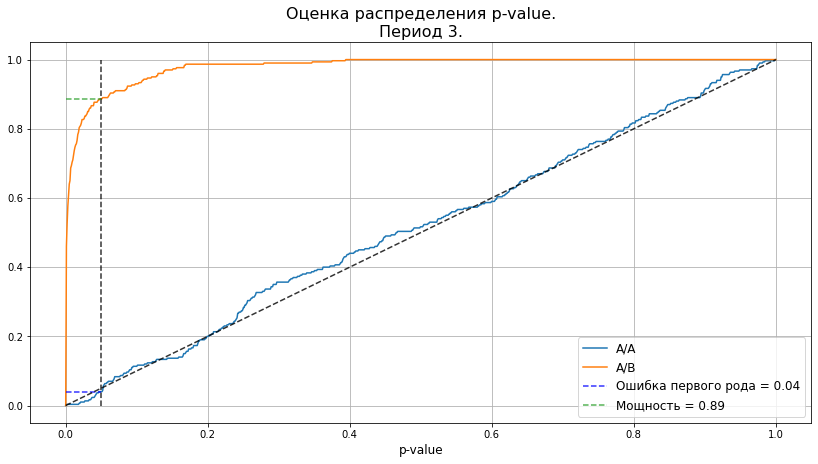
Даже на данных периода 3 реальность несильно уходит от наших предположений. Таким образом, у нас получилось сократить размер группы в 3 раза без потери качества эксперимента. Конечно, в текущем примере и 3 000 пользователей не выглядят катастрофой, но в данном примере малые размеры были выбраны намеренно, для ускорения расчётов. Если бы мы хотели поймать эффект порядка 0.01, то размеры выборки были бы порядка 100 000 пользователей. А в таком случае, сокращение объёма в 3 раза уже начинает играть роль.
Заключение
На этом я заканчиваю свой обзор использования теста Стьюдента в случаях, когда наши выборки не являются независимыми. Основные выводы были озвучены к моменту, когда мы закончили исследовать синтетику и перешли к реальным данным. Во второй части статьи мы только подтверждали их на практике. Заключались выводы в следующем:
Если мы выбираем КГ и ЦГ из генеральной совокупности случайным образом, то ни к формуле оценки размера групп, ни к двухвыборочному критерию Стьюдента вопросов нет.
В случае, если выборки в п. 1 одинакового размера, можно воспользоваться и одновыборочным критерием Стьюдента для выборки попарных разностей. Главное — не забыть умножить
 генеральной совокупности на
генеральной совокупности на  при подсчёте размера выборки.
при подсчёте размера выборки.Если мы подбираем одну группу под другую неслучайным образом, и пользуемся формулой, подставляя в неё дисперисию генеральной совокупности, то оценка размера групп будет завышенной. Использование двухвыборочного критерия будет слишком консервативным.
В случае поэлементного подбора одной группы под другую можно воспользоваться одновыборочным критерием Стьюдента для попарных разностей двух выборок. Такой подход позволит сократить размер выборки.
