Статический временной анализ demystified. Часть 2
Многие начинающие разработчики не до конца понимают значение таких параметров триггера как время установки (Setup) и удержания (Hold). Про метастабильность и природу этих двух параметров написано достаточно много (https://habrahabr.ru/post/254869/), поэтому сосредоточимся на том, как бороться с нарушениями Seup и Hold в процессе проектирования схем.
В начале дадим определения Setup и Hold:
- Время установки Setup — минимальное время от момента завершения переходных процессов на входе данных до момента прихода фронта клока на тактовый вход триггера.
- Время удержания Hold — минимальное время от момента прихода фронта клока на тактовый вход до начала новых переходных процессов на входе данных триггера.
Почему я пишу о событиях на входах триггеров? Потому что статический временной анализ строит граф для расчета задержек, и входы элементов являются вершинами это графа. Подробнее о построении графов и внутренней «кухне» статического временного анализа можно почитать в первой заметке https://habrahabr.ru/post/273849/.
Теперь, поговорим о том, как проверяются нарушения Setup и Hold. В синхронных схемах все переходные процессы начинаются на тактовом входе (вернее — на выходе внешнего генератора или PLL, но статический анализ за пределы микросхемы не заглядывает, поэтому говорим лишь о тактовом входе микросхемы). Итак, переходной процесс (клок, тактовый импульс) распространяется по цепям до тактовых входов триггеров, расщепляясь уже на множество переходных процессов, которые проходят через триггеры до их выходов, попадают в логику, и заканчиваются на входах данных триггеров-приемников. Основное условие работы синхронных схем: все переходные процессы обязаны закончится за один такт. Или, точнее, не за один такт, а ко времени прихода следующего тактового импульса, которое для каждого триггера в действительности разное, поскольку цепь тактирования в реальной микросхеме строится по принципу дерева.
О дереве. Очевидно, что цепь тактирования имеет настолько большое число нагрузок, что ни один логический элемент не имеет достаточной мощности, чтобы прокачать их все. Поэтому, цепь тактирования проектируется в виде дерева, вершина которого — тактовый вход микросхемы, ветви — умощняющие буферы или инверторы, а листья — тактовые входы триггеров. Дерево не идеально (часто его делают таким специально), поэтому всегда существует неодновременность прихода такта на различные триггеры. Из-за этого получается, что в одних участках схемы переходные процессы должны закончиться раньше, а на других участках позже — лишь бы успеть за время Tsetup до прихода тактового импульса. Посмотрим на следующую картинку (картинка и формулы позаимствованы из англоязычной статьи http://www.edn.com/design/systems-design/4392195/Equations-and-Impacts-of-Setup-and-Hold-Time)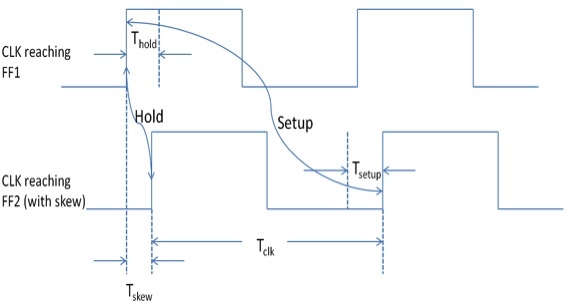
На картинке показаны вейвформы прихода тактового импульса на триггеры FF1 и FF2, между которыми расположена некоторая комбинационная схема, задерживающая сигнал. Другими словами, FF1 — триггер источник сигнала, FF2 — приемник, а задержка сигнала через логику, в зависимости от некоторых входных условий, может доходить как очень быстро, так и очень медленно. Разберемся с обозначениями: Tskew — перекос дерева тактирования, из-за которой такт на FF2 приходит позже чем на FF1 на величину Tskew. Tc2q — задержка сигнала внутри триггера между тактовым входом и выходом данных. Напомню, что в синхронных схемах источником всех переходных процессов является тактовый импульс, поэтому путь сигнала идет через тактовый вход на выход данных триггера, и затем через логику. Tcomb -задержка сигнала в логике, Tclk -период тактового импульса, а Tsetup — характеристика триггера, определение которой (Setup) было дано выше.
Смотрим на картинку, и видим, что максимальное время окончания переходных процессов на входе данных триггера должно удовлетворять следующему неравенству (1): Tc2q + Max(Tcomb) + Tsetup ≤ Tclk + Tskew (1)
Здесь Max (Tcomb) — максимально возможное значение Tcomb. Из формулы следует, что с нарушением неравенства можно бороться двумя путями: двигать вправо момент прихода тактового импульса на FF2, меняя Tskew, либо уменьшать задержку в логике Max (Tcomb).
Теперь попробуем разобраться с нарушениями Hold. Если нарушение Setup, вообще говоря, имеет отношение к следующему такту, поскольку сравнивается с моментом прихода следующего тактового импульса, то нарушение Hold следует проверять уже в текущем такте. Как же может произойти нарушение Hold? Согласно картинке, если сигнал с выхода FF1 через логику пройдет настолько быстро, что успеет испортить данные на входе FF2 — мы получим нарушение в текущем такте. Из чего следует условие, что сигнал с выхода FF1 не может придти быстрее, чем за время Thold, с поправкой на Tskew. Получаем неравенство (2)Tc2q + Min(Tcomb) ≥ Thold + Tskew (2)
Здесь Min (Tcomb) — минимально возможное значение Tcomb. Из этой формулы так же следует, что с нарушением можно бороться, двигая Tskew, либо увеличивая задержки в логике Min (Tcomb).
Далее, поговорим о том, как с устранением нарушений борется САПР. Первоочередной его задачей является вытягивание быстродействия проектируемой схемы. Предположим, нам надо получить частоту схемы 1 ГГц, при том, что в паре мест в дизайне присутствует задержка логики 1.2 нс. САПР может попытаться ужать эту логику до 1нс, либо перекосить тактовое дерево таким образом, что Tskew у триггера — приемника окажется равным 200 пс. Что-то подобное изображено на картинке выше. Поскольку логику обычно ужать не удается, то первое, что делает САПР, это перестраивает дерево тактового импульса, устраняя тем самым нарушения Tsetup. Необходимо отметить, что с увеличением Tskew, растет и риск нарушения Hold.
По достижении нужной частоты наступает черед исправления Hold. На этот раз САПР не трогает тактовое дерево, и использует второй прием — увеличение Min (Tcomb), т.е. минимальных задержек в логике, где присутствует нарушения Hold. Задержки увеличиваются очень просто — вставкой буферных элементов. Хотя лишние буферы, безусловно, увеличивают потребление схемы.
Любопытно, что увеличение задержек в схеме ввиду нагрева, снижения питания, накопления дозы радиации, либо старения, можно парировать снижением рабочей частоты микросхемы. Ведь как видно из формулы (1), если задержки увеличиваются — надо снижать Tclk. Но если задержки в схеме уменьшаются, по причине чрезмерного охлаждения либо повышения напряжения питания, то нарушения Hold в микросхеме уже не исправишь ничем — микросхема просто перестанет работать, что следует из формулы (2). Как же тогда проектируются микросхемы для низких и даже сверхнизких температур? Чаще всего такие схемы проектируют обычным способом, но закладывают огромный запас по Hold. Чем больше запас, тем больше можно охлаждать микросхему ниже расчетных температур, но насколько — покажет только эксперимент. Вероятность нарушений также снижается и при отказе от перекошенного тактового дерева в пользу максимально ровного (чаще всего используют т.н. H-tree) с сопутствующим уменьшением производительности. А самый надежный способ — проектировать асинхронные (SI, DI) схемы, полностью устойчивые к параметрическим отказам.
Ну и в заключении, а при чем тут ПЛИС? Во-первых, раздела по ASIC на хабре нет. Во-вторых, хороший ПЛИСовод рано или поздно дорастает до проектирования ASIC. Ну и в третьих, хоть возможности манипуляций с Clock Skew у ПЛИС и кастрированные, но они все равно есть. Надеюсь, кому-нибудь статья окажется полезной.
