Состязательные атаки (adversarial attacks) в соревновании Machines Can See 2018
Или как я оказался в команде победителей соревнования Machines Can See 2018 adversarial competition.
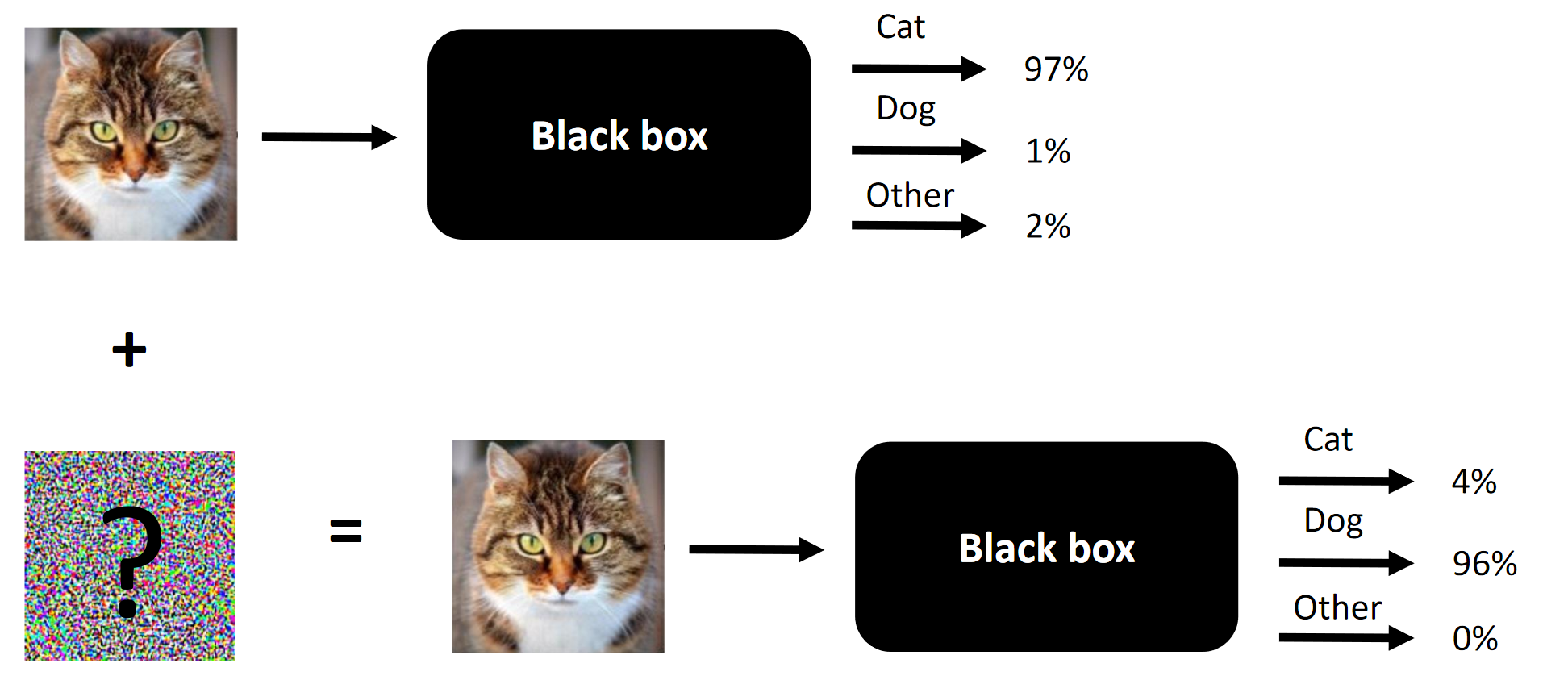
Суть любых состязательных атак на примере.
Так уж получилось, что мне довелось поучаствовать в соревновании Machines Can See 2018. Я присоединился к соревнованию я поздновато (примерно за неделю до окончания), но в конечном итоге оказался в команде из 4 человек, где вклад троих из нас (включая меня) был необходим для победы (убрать одну составляющую — и мы бы оказались в аутсайдерах).
Цель соревнования — изменять лица людей так, что сверточная нейросеть, предоставленная как черный ящик организаторами, не могла различить лицо-источник от лица-цели. Допустимое количество изменений было ограничено SSIM.
Оригинальная статья размещена тут.
Прим. Корявый перевод терминологии или его отсутствие продиктованы отсутствием устоявшейся терминологии в русском языке. Вы можете предложить свои варианты в комментариях.

Суть соревнования — изменить лицо на входе так, что черный ящик не смог бы различить два лица (по крайней мере, с точки зрения L2/ евклидова расстояния)
Что работает в состязательных атаках и что сработало в нашем случае:
- Fast Gradient Sign Method (FGSM). Добавление эвристик сделало его ЧУТЬ лучше;
- Fast Gradient Value Method (FGVM). Добавление эвристик сделало его СИЛЬНО лучше;
- Genetic differential evolution (великолепная статья про данный метод) + попиксельные атаки;
- Ансамбли моделей (топовое решение… 6 «настаканных» ResNet34);
- Умный обход комбинаций изображений-таргетов;
- По сути, early stopping во время FGVM атаки;
Что не сработало в нашем случае:
- Добавление «момента инерции» к FGVM (хотя это сработало для команды, занявшей место ниже, так что, возможно ли, что ансамбли + эвристики сработали лучше, чем добавление момента?);
- C&W attack (по сути end-to-end атака нацеленная на логиты модели-белого-ящика) — работает для белого-ящика (БЯ), не работает для черного ящика (ЧЯ);
- Подход, основанный на end-to-end сиамском LinkNet (архитектура, схожая с UNet, но основывающаяся на ResNet). Тоже работал только для БЯ;
Что мы не попробовали (не успели, не хватило усилий или поленились):
- Толковое тестирование аугментаций для student learning (пришлось бы пересчитывать дескрипторы тоже — это легко, но такая простая идея пришла не сразу);
- Аугментации во время атаки — например «отзеркалить» картинки слева-направо;
О соревновании в целом:
- Датасет был «мелковат» (1000 5+5 комбинаций);
- Датасет для обучения Student net был относительно большой (1 млн. + изображений);
- ЧЯ был представлен в виде набора прекомпилированных моделей на Caffe (естественно на наших окружениях сначала они выдавали баги). Это также вносило некоторую сложность, так как ЧЯ не принимал изображения батчами;
- У соревнования был великолепный бейзлайн (базовое решение), без которого, на мой взгляд, мало кто бы стал прямо серьезно участвовать;
Ресурсы:
1. Обзор соревнования Machines Can See 2018 и как я в него попал
Соревнование и подходы
Честно говоря, меня привлекли новая интересная область, GTX 1080Ti Founders' Edition в призах, и относительно низкая конкуренция (что как бы вообще не сравнить с 4000 людей в каком-нибудь соревновании на Kaggle против всего ODS с 20 GPU на команду).
Как уже упоминалось выше, целью соревнования служил обман ЧЯ модели, чтобы последняя не смогла отличить двух разных людей (в смысле L2-нормы / евклидова расстояния). Ну и так как это был черный ящик, нам пришлось дистиллировать Student-сети на предоставленных данных и надеяться, что градиенты ЧЯ и БЯ будут достаточно похожи для осуществления атаки.
Если прочитать обзоры статей (например, вот и вот, хотя такие статьи реально не говорят, что работает на практике) и скомпилировать то, чего достигли топовые команды, то можно кратко описать такие лучшие практики:
- Самые простые в имплементации атак предполагают БЯ или знание внутренней структуры сверточной нейросети (или просто архитектуры), на которую производится атака;
- Кто-то в чате предложил проследить за временем inference на ЧЯ и попробовать угадать его архитектуру;
- Имея доступ к достаточному количеству данных, можно эмулировать ЧЯ хорошо натренированным БЯ
- Предположительно, наиболее продвинутые методы:
- End-to-end C&W атака (не сработала в данном случае);
- Умные расширения FGSM (то есть момент инерции +хитрые ансамбли);
Честно говоря, мы еще были сбиты с толку тем, что два абсолютно разных end-to-end подхода, имплементированные независимо двумя разными людьми из команды, тупо не работали на ЧЯ. По сути такое могло означать, что в нашей интерпретации постановки задачи где-то в запряталась утечка данных, которую мы не заметили (или что руки кривые). Во многих современных computer vision задачах end-to-end решения (например, перенос стиля, deep watershed, генерация изображений, чистка от шума и артефактов и др.) получаются либо сильно лучше чем все что было до этого, либо вообще не работают. Meh.
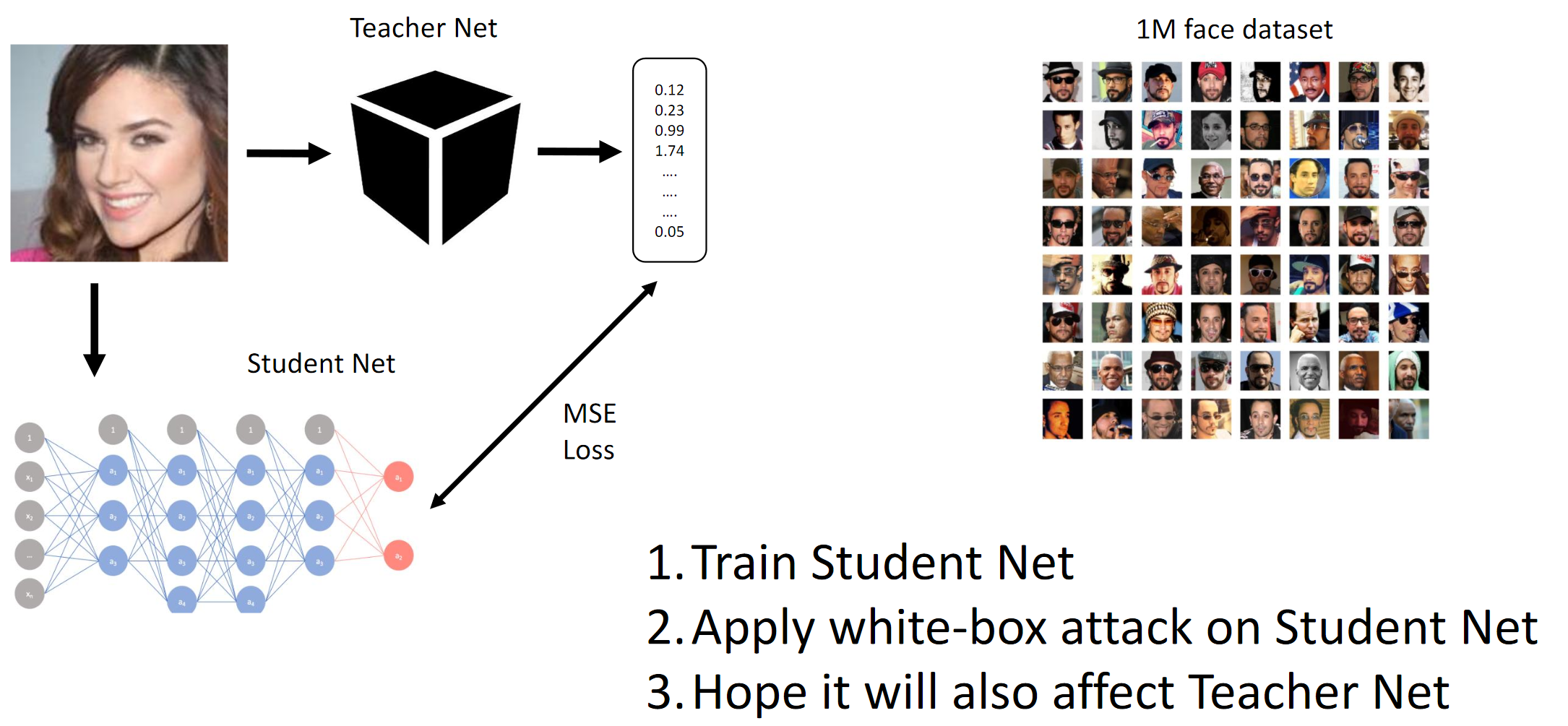
1. Натренировать Student Net. 2. Применить БЯ атаку на Student Net. 3. Надеяться, что на Teacher Net атака тоже распространится
Как работает метод градиентов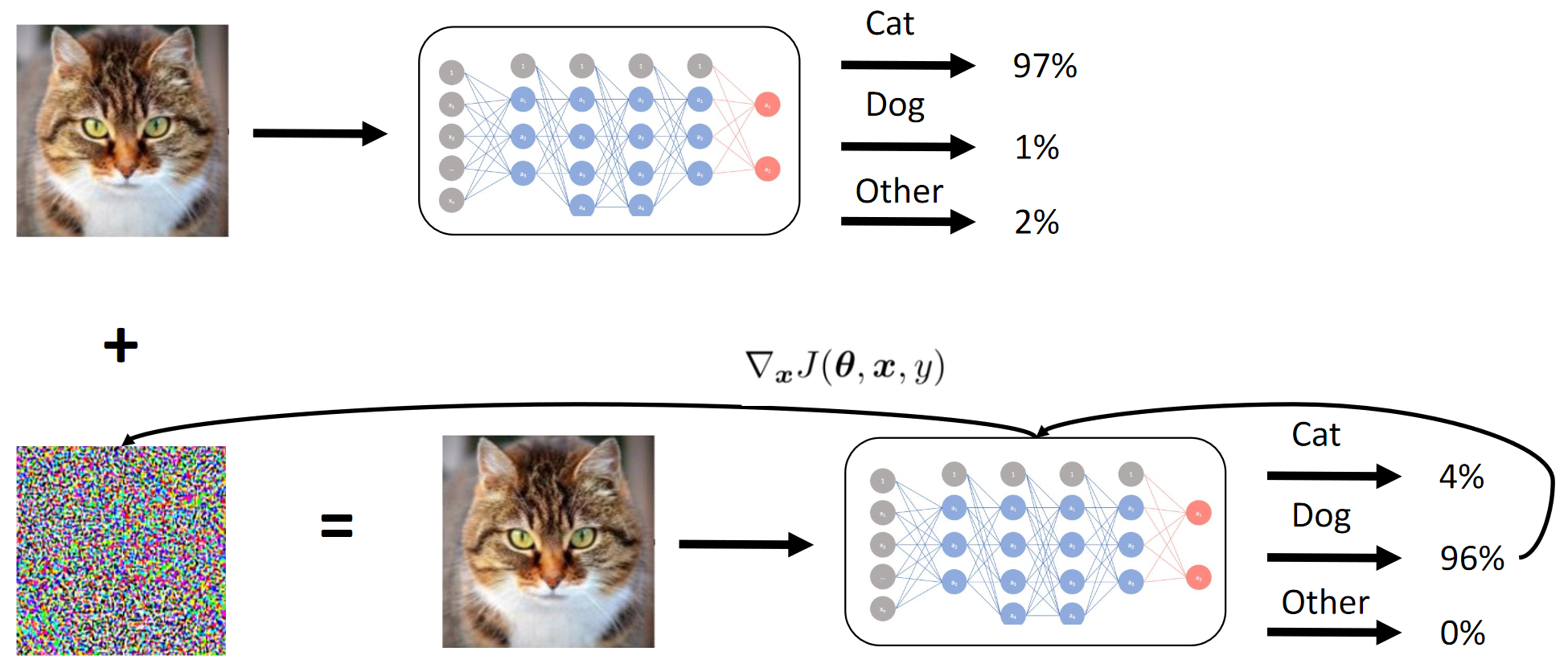
Мы по сути добиваемся при помощи дистилляции того, что БЯ подражает ЧЯ. Потом считаются градиенты изображений на входе относительно вывода модели. Секрет, как обычно, заключается в эвристиках.
Целевая метрика
Целевой метрикой была средняя L2 норма (евклидово расстояние) между всеми 25 комбинациями изображений источников и таргетов (5×5 = 25).
Из-за ограничений платформы (CodaLab), вероятно, подсчет приватного скора (и слияние команд) осуществлялись вручную, что как бы такая себе история.

Команда
Я присоединился к команде, после того как натренировал Student сетки, лучше чем у всех остальных на лидерборде (насколько мне известно), и после небольшого обсуждения с Atmyre (она помогла с правильно скомпилированным ЧЯ, так как сама столкнулась с тем же). Потом мы поделились нашими локальными скорами без шеринга подходов и кода и собственно за 2–3 дня до финишной прямой произошло следующее:
- Мои непрерывные модели зафейлились (да, и в данном случае тоже);
- У меня были лучшие Student модели;
- У них (команды) были лучшие вариации эвристик для FGVM (их код основывался на бейзлайне);
- Я только распробовал модели с градиентами и достиг локального скора около 1.1 — изначально я не рвался использовать бейзлайн из личных предпочтений (бросил себе вызов);
- У них не хватало вычислительных мощностей на тот момент;
- В конце концов, мы попытали удачу и объединили усилия — я вложил свои вычислительные мощности / сверточные нейросети / набор ablation тестов. Команда вложила свою базу кода, которую они полировали в течение пары недель;
Еще раз хотел бы поблагодарить ее за бесценный совет и организационные навыки.
Состав команды:
github.com/atmyre — исходя из действий, была капитаном команды изначально. Добавила genetic differential evolution атаку в финальном сабмите;
github.com/mortido — лучшая имплементация FGVM атаки с великолепными эвристиками + натренировал 2 модели, используя код бейзлайна;
github.com/snakers4 — помимо всяких тестов на сокращение количества вариантов в поиске решения, натренировал 3 Student модели с наилучшими метриками + предоставил вычислительные мощности + помогал в фазе финального сабмита и презентации результатов;
github.com/stalkermustang;
В итоге мы все узнали много нового благодаря друг другу, и я рад, что мы попытали удачу в данном соревновании. Отсутствие хотя бы одного вклада из трех привело бы к поражению.
2. Дистилляция Student CNN
Мне удалось получить лучший скор при тренировке Student моделей, так как я использовал свой собственный код вместо кода бейзлайна.
Ключевые моменты / что сработало:
- Подбор режима тренировки для каждой архитектуры индивидуально;
- Сначала тренировка при помощи Adam + LR decay;
- Тщательное наблюдение за недо- и оверфиттингом и емкостью модели;
- Ручная настройка режимов тренировки. Не стоит полностью доверять автоматическим схемам: они могут работать, но если хорошо выставить настройки, время на тренировку может сократиться в 2–3 раза. Это особенно важно в случае тяжелых моделей вроде DenseNet;
- Тяжелые архитектуры показывали результаты лучше, чем легкие, не считая VGG;
- Тренировка с L2 лоссом вместо MSE тоже работает, но чуть хуже;
Что не сработало:
- Архитектуры на основе Inception (не подходят из-за высокого down-sampling и более высокого разрешения на входе). Хотя команда на третьем месте смогла каким-то образом использовать Inception-v1 и фулл-рез изображения (~ 250×250);
- Архитектуры на основе VGG (over-fitting);
- «Легкие» архитектуры (SqueezeNet / MobileNet — underfitting);
- Аугментации изображений (без модификации дескрипторов — хотя команда с третьего места как-то это вытянула);
- Работа с фулл-сайз изображениями;
- Также в конце нейросетей, предоставленных организаторами соревнования, был слой batch-norm. Это не помогло моим коллегам, и я использовал свой код, так как я не очень понял, почему этот слой там оказался;
- Использование saliency maps вместе попиксельными атаками. Полагаю, это более применимо к фулл-сайз изображениям (просто сравните 112×112xпространство_поиска и 299×299xпространство_поиска);
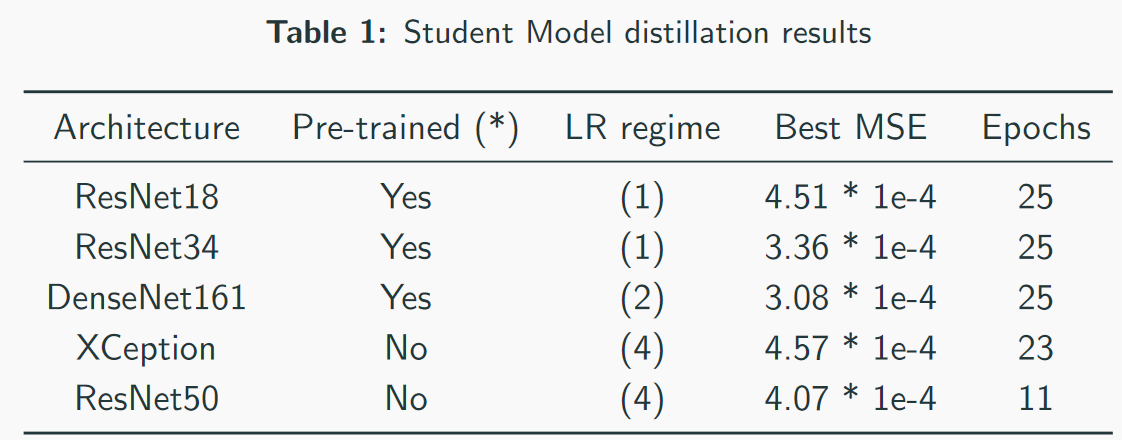
Наши лучшие модели — заметьте, что лучший скор — 3×1e-4. Судя по сложности моделей, можно примерно представить, что ЧЯ — это ResNet34. В моих тестах ResNet50+ показал себя хуже чем ResNet34.
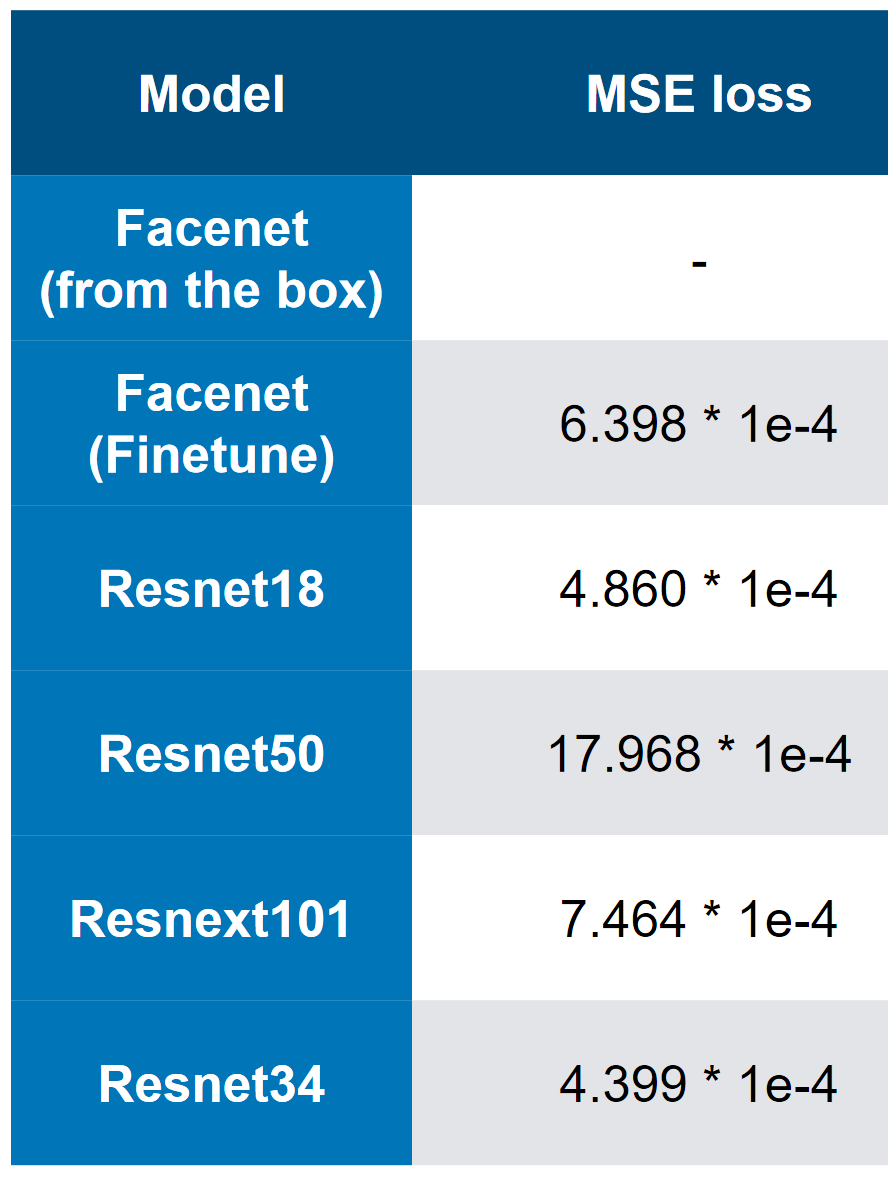
MSE лоссы первого места
3. Финальный скор и «ablation» анализ
Мы собирали свой скор примерно так: 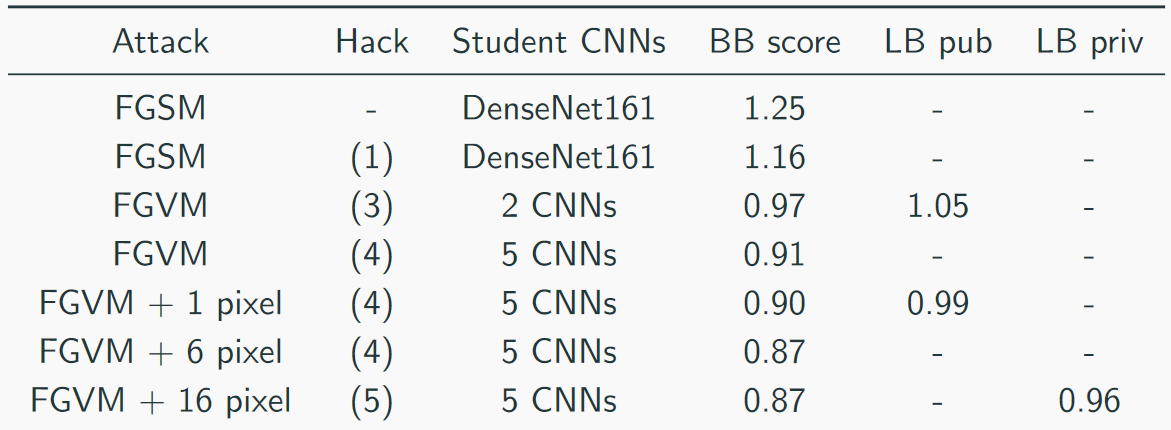
Топовое решение выглядело так (да, были шутки на тему того, что просто стакая резнет, можно угадать, что ЧЯ является резнетом): 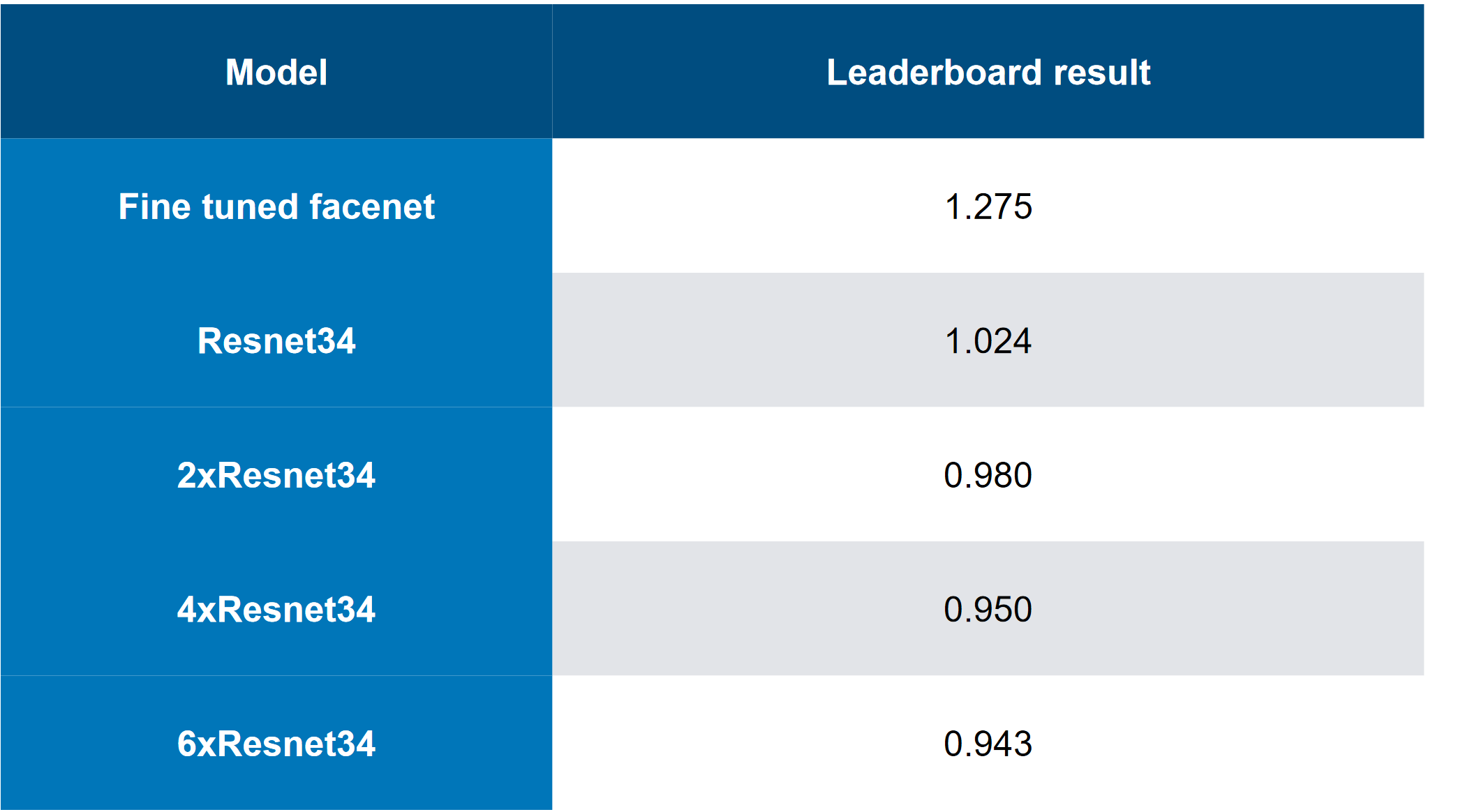
Другие полезные подходы от других команд:
- Адаптивный параметр эпсилон;
- Аугментация данных;
- Момент инерции;
- Момент Нестерова;
- Зеркальные отражения картинок;
- Немного «хакнуть» данные — там было всего 1000 уникальных изображений и 5000 комбинаций изображений => можно было нагенерить больше данных (сделать не 5 таргетов, а 10, т.к. картинки повторялись);
Полезные эвристики для FGVM:
- Генерация шума по правилу: Noise = eps * clamp (grad / grad.std (), -2, 2);
- Ансамбль нескольких CNN через взвешивание их градиентов;
- Сохранять изменения только если они сокращают средний лосс;
- Использовать комбинации таргетов для более устойчивого таргетинга;
- Использовать только те градиенты, что выше чем mean + std (для FGSM);
Краткое саммари:
- На первом месте оказалось более «топорное» решение
- У нас было наиболее «диверсифицированное» решение;
- На третьем месте оказалось самое «изящное» решение;
End-to-end решения
Пусть даже они и провалились, их стоит еще раз попробовать в будущем на новых задачах. См. детали в репозитории, а по сути мы попробовали следующее:
- C&W атака;
- Сиамский LinkNet;
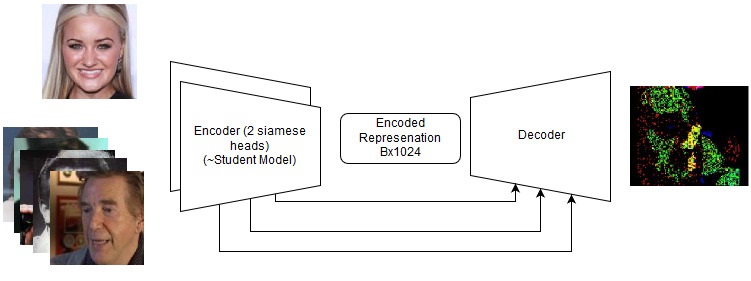
Непрерывная (end-to-end) модель
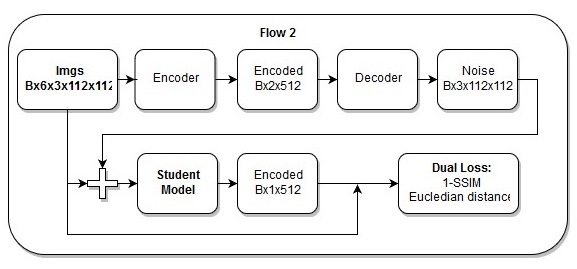
Последовательность действий в end-to-end модели
Еще я думаю, что мой лосс просто прекрасен.
5. Ссылки и дополнительные материалы для чтения
