Сети для самых маленьких. Часть четырнадцатая. Путь пакета
A forwarding entity always forwards packets in per-flow order to
zero, one or more of the forwarding entity«s own transmit interfaces
and never forwards a packet to the packet«s own receive interface.
Brian Petersen. Hardware Designed Network
Одно из удивительнейших достижений современности — это то, как, сидя в Норильске, человек может чатиться со своим другом в Таиланде, параллельно покупать билет на вечерний самолёт к нему, расплачиваясь банковской картой, в то время, как где-то в Штатах на виртуалочке его бот совершает сделки на бирже со скоростью, с которой его сын переключает вкладки, когда отец входит в комнату.
А через 10 минут он закажет такси через приложение на телефоне, и ему не придётся даже брать с собой в дорогу наличку.
В аэропорту он купит кофе, расплатившись часами, сделает видеозвонок дочери в Берлин, а потом запустит кинцо онлайн, чтобы скоротать час до посадки.
За это время тысячи MPLS-меток будут навешаны и сняты, миллионы обращений к различным таблицам произойдут, базовые станции сотовых сетей передадут гигабайты данных, миллиарды пакетов больших и малых в виде электронов и фотонов со скоростью света понесутся в ЦОДы по всему миру.
Это ли не электрическая магия?
В своём вояже к QoS, теме обещанной многократно, мы сделаем ещё один съезд. На этот раз обратимся к жизни пакета в оборудовании связи. Вскроем этот синий ящик и распотрошим его.

Кликабельно и увеличабельно.
Сегодня:
- Коротко о судьбе и пути пакета
- Плоскости (они же плейны): Forwarding/Data, Control, Management
- Кто как и зачем обрабатывает трафик
- Типы чипов: от CPU до ASIC’ов
- Аппаратная архитектура сетевого устройства
- Путешествие длиною в жизнь
Забегая вперёд, немного поговорим о плоскостях и введём некоторые определения.
Итак, есть две плоскости весьма чёткое деление архитектуры сетевого устройства на две части: Control и Data Plane. Это элегантное решение, которое годы назад позволило абстрагировать путь трафика от физической топологии, зародив пакетную коммутацию, и которое является фундаментом всей индустрии сегодня.
Data Plane — это пересылка трафика со входных интерфейсов в выходные — чуть ближе к точке назначения. Data Plane руководствуется таблицами маршрутизации/коммутации/меток (далее будем называть их таблицами пересылок). Здесь мет места задержкам — всё происходит быстро.
Control Plane — это уровень протоколов, контролирующих состояние сети и заполняющих таблицы пересылок (BGP, OSPF, LDP, STP, BFD итд.). Тут можно помедленнее — главное — построить правильные таблицы.
Для чего такое разделение оказалось нужным, читайте в соответствующей главе.
Поскольку все предыдущие 14 частей СДСМ были так или иначе про плоскость управления, в этот раз мы будем говорить о плоскости пересылки.
И в первую очередь введём понятие транзитных и локальных пакетов.
Транзитные — это пакеты, обрабатывающиеся исключительно на Data Plane и не требующие передачи на плоскость управления. Они пролетают через узел быстро и прозрачно.
Преимущественно это пользовательские (клиентские) данные, адрес источника и назначения которых за пределами данного устройства (и, скорее всего, сети провайдера вообще).
Среди транзитного трафика могут быть и протокольные — внутренние для сети провайдера, но не предназначенные данному узлу.
Например, BGP или Targeted LDP.
Локальные делятся на три разных вида:
- Предназначенные приложению на данном устройстве.
То есть либо адрес назначения принадлежит ему (настроен на нём).
Либо адрес назначения броадкастовый (ARP) или мультикастовый (OSPF Hello), который устройство должно прослушивать.Здесь важно понимать, что речь об адресе самого внутреннего заголовка пересылки: например, для BGP или OSPF — это IP, для ISIS или STP — MAC.
При этом пакет, DIP которого внешний, а DMAC — локальный, остаётся транзитным, поскольку пакет нужно доставить на выходной интерфейс вовне, а не на Control Plane. - Сгенерированные данным устройством. То есть созданные на ЦПУ, на Control Plane, и отправленные на Data Plane.
- Транзитные пакеты, требующие обработки на плоскости управления. Примерами могут служить пакеты, у которых истёк TTL — нужно генерировать ICMP TTL Expired in Transit. Или пакеты с установленными IP Option: Router Alert или Record Route.
Мы в этой статье поговорим обо всех. Но преимущественно речь будет о транзитных — ведь именно на них провайдер зарабатывает деньги.
1. Коротко о судьбе и пути пакета
Под пакетом будем понимать PDU любого уровня — IP-пакеты, фреймы, сегменты итд. Для нас важно, что это сформированный пакет информации.
Всю статью мы будем рассматривать некий модульный узел, который пересылает пакеты. Для того, чтобы не запутать читателя, определим, что это маршрутизатор.Все рассуждения данной статьи, с поправками на заголовки, протоколы и конкретные действия с пакетом, применимы к любым сетевым устройствам, будь то маршрутизатор, файрвол или коммутатор — их задача: передать пакет следующему узлу ближе к назначению.
Дабы избежать кривотолков и неуместной критики: автор отдаёт себе отчёт в том, что реальная ситуация зависит от конкретного устройства. Однако задача статьи — дать общее понимание принципов работы сетевого оборудования.
Следующую схему мы выберем в качестве отправной точки.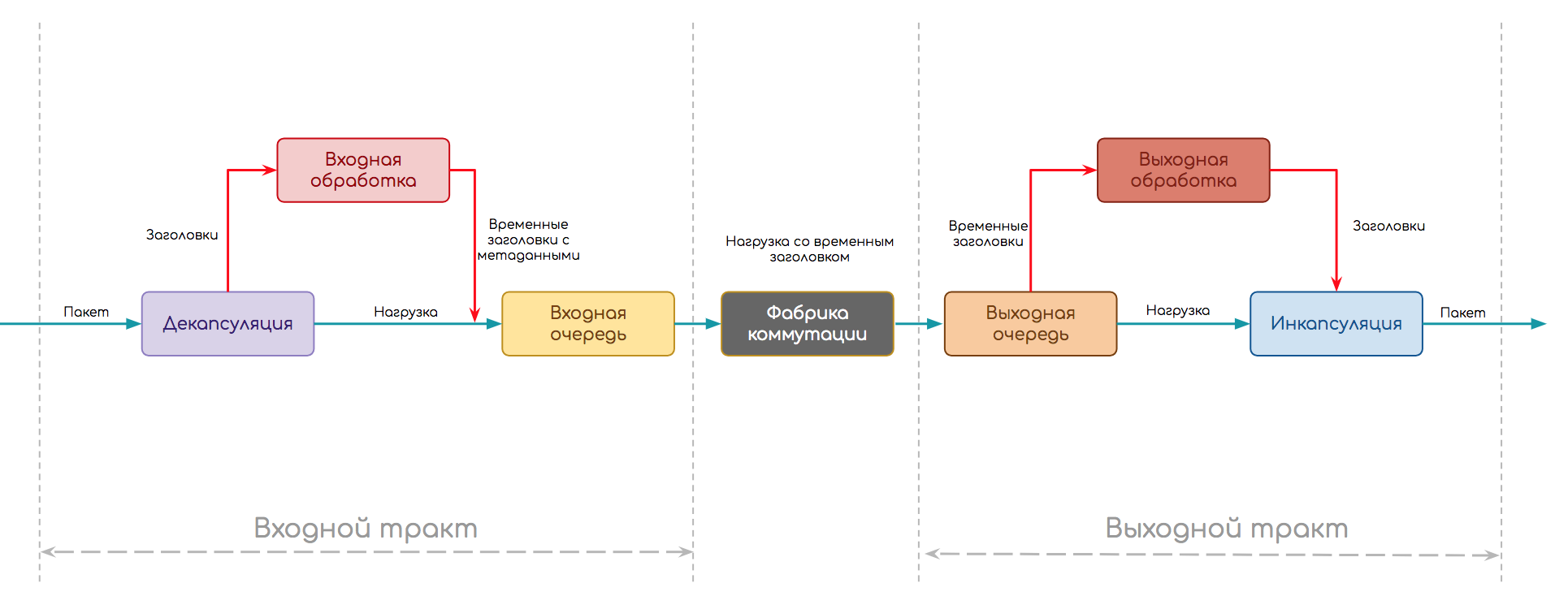
Независимо от того, что за устройство, как реализована обработка трафика, пакету нужно пройти такой путь.
- Путь делится на две части: входной и выходной тракты.
- На входе происходит сначала декапсуляция — отделение заголовка от полезной нагрузки и прочие присущие протоколу вещи (например, вычисление контрольной суммы)
- Далее стадия входной обработки (Ingress Processing) — сам пакет без заголовка (нагрузка) томится в буфере, а заголовок анализируется. Здесь могут к пакетам применяться политики, происходить поиск точки назначения и выходного интерфейса, создаваться копии итд.
- Когда анализ закончен, заголовок превращается в метаданные (временный заголовок), склеивается с пакетом и они передаются на входную очередь. Она позволяет не слать на выходной тракт больше, чем тот может обработать.
- Далее пакет может ждать (или запрашивать) явное разрешение на перемещение в выходную очередь, а может просто туда передаваться, а там, поди, разберутся.
- Выходных трактов может быть несколько, поэтому пакет далее попадает на фабрику коммутации, цель которой, доставить его на правильный.
- На выходном тракте также есть очередь — выходная. В ней пакеты ожидают выходной обработки (Egress Processing): политики, QoS, репликация, шейпинг. Здесь же формируются будущие заголовки пакета. Также выходная очередь может быть полезной для того, чтобы на интерфейсы не передавать больше, чем они могут пропустить.
- И завершающая стадия — инкапсуляция пакета в приготовленные заголовки и передача его дальше.
Эта упрощённая схема более или менее универсальна.
Немного усложним её, рассмотрев стек протоколов.
Например, IP-маршрутизатор должен сначала из электрического импульса восстановить поток битов, далее распознать, какой тип канального протокола используется, определить границы кадра, снять заголовок Ethernet, узнать что под ним (пусть IP), передать IP-пакет на дальнейшую обработку.
Тогда схема примет такой вид: 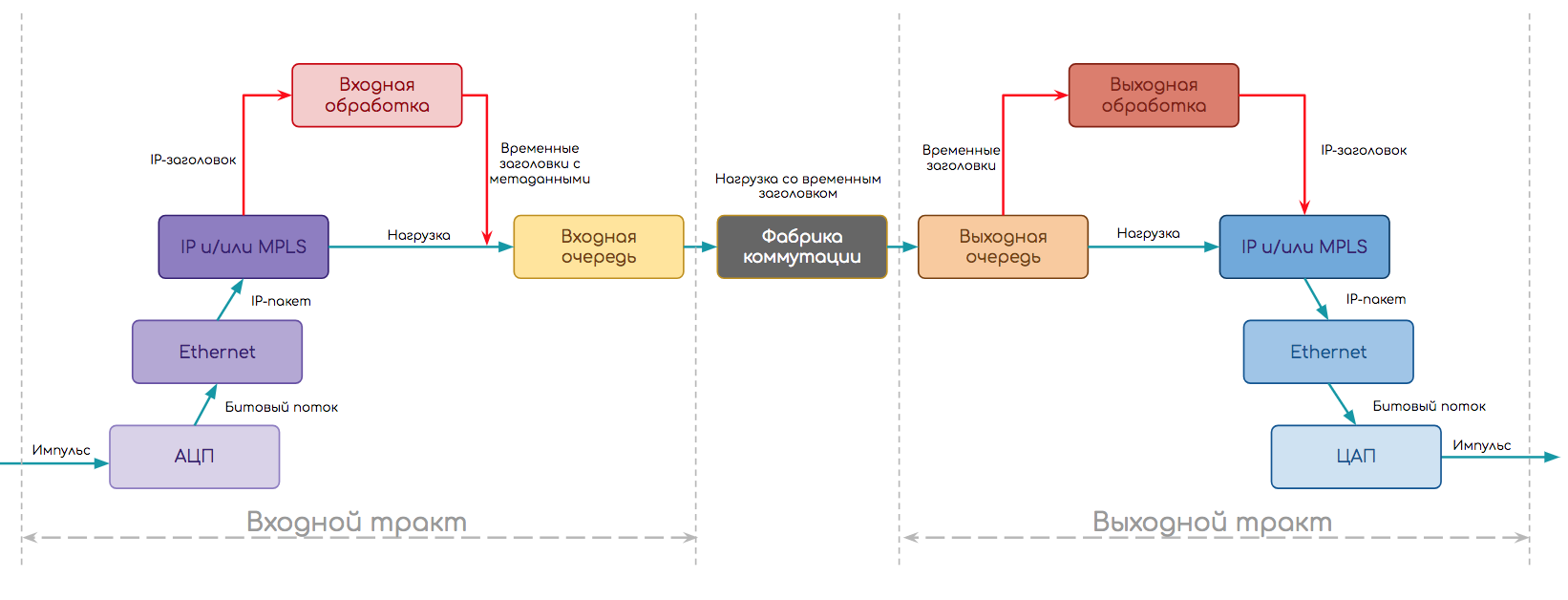
- Сначала отработал модуль физического уровня.
- С помощью АЦП восстановил поток битов — в некоторым смысле декапсуляция физического уровня.
- Работая на определённом типе порта (Ethernet), он понимает, что выходным интерфейсом будет модуль Ethernet.
- Далее происходит декапсуляция и Входная Обработка на Ethernet-модуле:
- Определение границ кадра, преамбулы, IFG, FCS
- Подсчёт контрольной суммы
- Снятие заголовков, разбор на поля
- Применение политик
- Определение адреса назначения — он локальный — и тогда выходной интерфейс — к модулю IP.
- Входная обработка IP:
- Снятие заголовков, разбор на поля
- Применение политик
- Анализ адреса назначения
- Поиск выходного интерфейса в Таблице Пересылки
- Формирование временных внутренних заголовков
- Склейка временных заголовков с данными и отправка пакета на выходной тракт.
- Обработка во входной очереди.
- Пересылка через фабрику коммутации.
- Обработка в выходной очереди.
- На выходном тракте модуль IP совершает Выходную Обработку:
- Применение политик, шейпинг
- Формирование конечного заголовка на основе метаданных (временного заголовка) и передача его модулю Ethernet.
- Далее Выходная Обработка на модуле Ethernet
- Поиск в ARP-таблице MAC-адреса следующего узла
- Формирование заголовка Ethernet
- Подсчёт контрольной суммы
- Применение политик
- Спуск на физический модуль.
- А модуль физического уровня в свою очередь разбивает поток битов на электрические импульсы и передаёт в кабель.
*Порядок выполнения операция приблизительный и может зависеть от реализации.
Все перечисленные выше шаги декомпозируются на сотни более мелких, каждый из которых должен быть реализован в железе или в ПО.
Вот и вопрос — в железе или ПО. Он преследует мир IP-сетей с момента их основания и, как это водится, развитие происходит циклически.
Есть вещи тривиальные, для которых элементная база существует… ммм… с 60-х. Например, АЦП, аппаратные очереди или CPU.
А есть те, которые стали прорывом относительно недавно.
Часть функций всегда была и будет аппаратной, часть — всегда будет программной, а часть — мечется, как та обезьяна.
В этой статье мы будем преимущественно говорить об аппаратных устройствах, лишь делая по ходу ремарки по поводу виртуальных.
2. Уровни и плоскости

Мы столько раз прежде использовали эти понятия, что пора им уже дать определения.
В работе оборудования можно выделить три уровня/плоскости:
- Forwarding/Data Plane
- Control Plane
- Management Plane
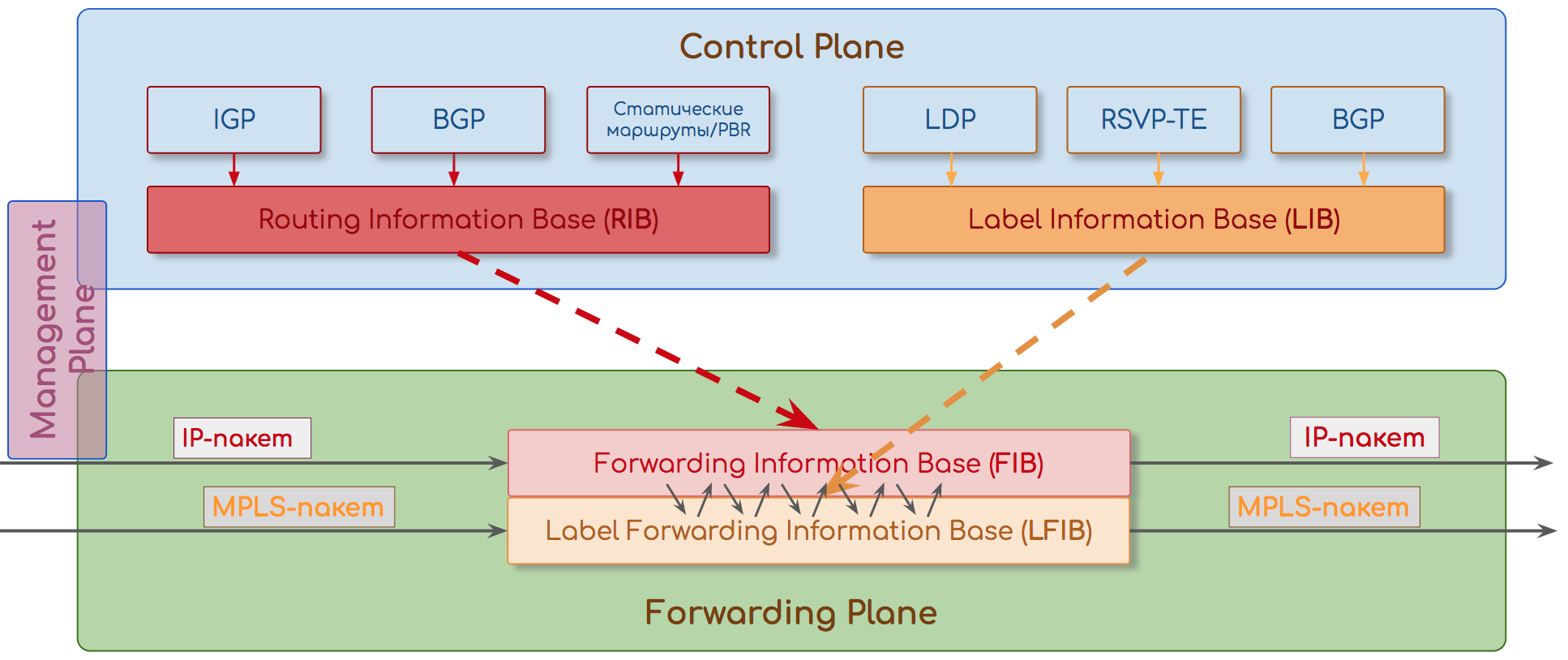
Forwarding/Data Plane
Плоскость пересылки.
Главная задача сети — доставить трафик от одного приложения другому. И сделать это максимально быстро, как в плане пропускной способности, так и задержек.
Соответственно главная задача узла — максимально быстро передать вошедший пакет на правильный выходной интерфейс, успев поменять ему заголовки и применив политики.
Поэтому существуют заранее заполненные таблицы передачи пакетов — таблицы коммутации, таблицы маршрутизации, таблицы меток, таблицы соседств итд.
Реализованы они могут быть на специальных чипах CAM, TCAM, работающих на скорости линии (интерфейса). А могут быть и программными.
Примеры:
- Принять Ethernet-кадр, посчитать контрольную сумму, проверить есть ли SMAC в таблице MAC-адресов. Найти DMAC в таблице MAC-адресов, определить интерфейс, передать кадр.
- Принять MPLS-пакет, определить входной интерфейс и входную метку. Выполнить поиск в таблице меток, определить выходной интерфейс и выходную метку. Свопнуть. Передать.
- Пришёл поток пакетов. Выходным интерфейсом оказался LAG. Решение, в какие из интерфейсов их отправить, тоже принимается на Forwarding Plane.
Однако иногда их разделяют.
Тогда Data Plane означает именно манипуляции с полезной нагрузкой: процесс доставки пакета от входного интерфейса к выходному и обработку его в буферах.
А Forwarding Plane — это обработка заголовков и принятие решения о пересылке.
Примерно так: 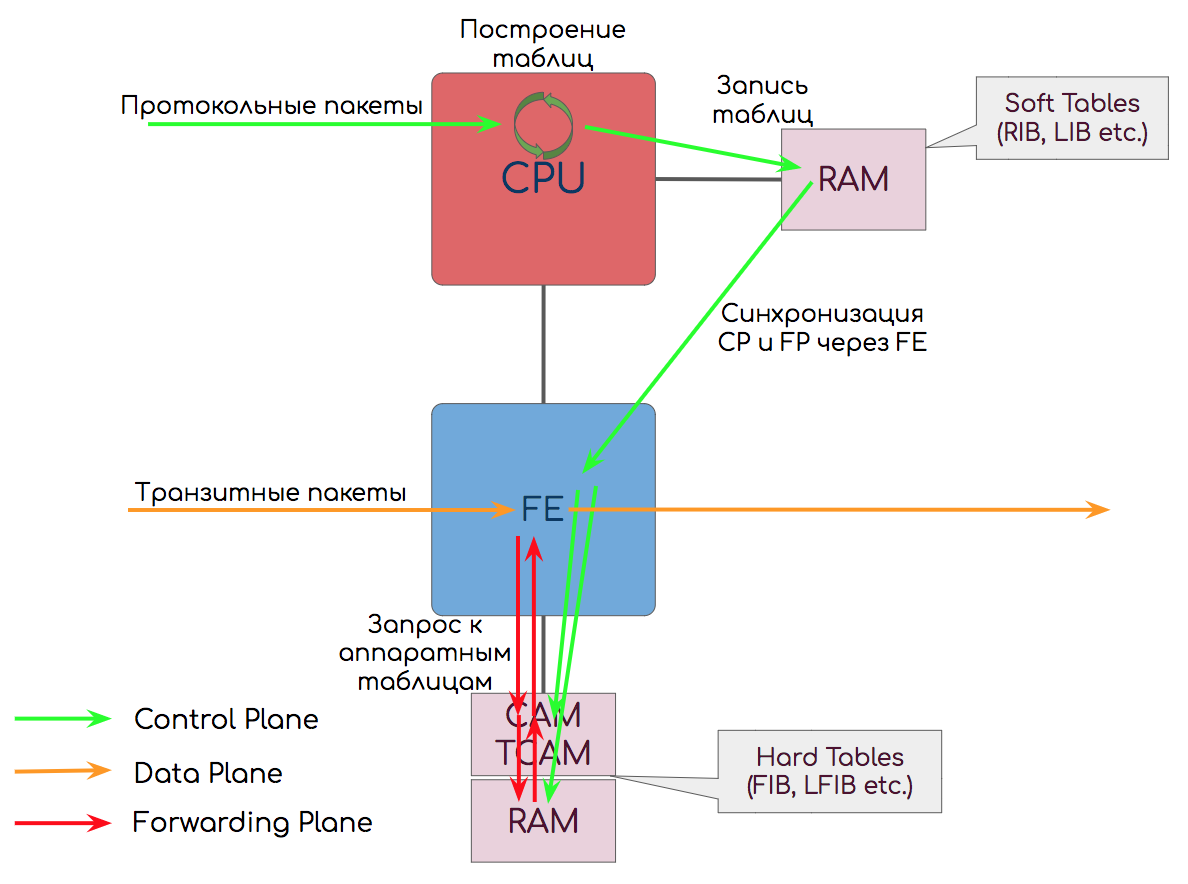
Control Plane
Плоскость управления.
Всему голова. Она заранее заполняет таблицы, по которым затем будет передаваться трафик.
Здесь работают протоколы со сложными алгоритмами, которые дорого или невозможно выполнить аппаратно.
Например, алгоритм Дейкстры реализовать на чипе можно, но сложно. Так же сложно сделать выбор лучшего маршрута BGP или определение FEC и рассылку меток. Кроме того, для всего этого пришлось бы делать отдельный чип или часть чипа, которая практически не может быть переиспользована.
В такой ситуации лучше пожертвовать сабсекундной сходимостью в пользу удобства и цены.
Поэтому ПО запускается на CPU общего назначения.
Получается медленно, но гибко — вся логика программируема. И на самом деле скорость на Control Plane не важна. Однажды вычисленный маршрут инсталлируется в FIB, а дальше всё не скорости линии.
Вопрос скорости Control Plane возникает при обрывах, флуктуациях на сети, но он сравнительно успешно решается механизмами TE HSB, TE FRR, IP FRR, VPN FRR, когда запасные пути готовятся заранее на том же Control Plane.
Примеры:
- Запустили сеть с IGP. Нужно сформировать Hello, согласовать параметры сессий, обменяться базами данных, просчитать кратчайшие маршруты, инсталлировать их в Таблицу Маршрутизации, поддерживать контакт через периодические Keepalive.
- Пришёл BGP Update. Control Plane добавляет новые маршруты в таблицу BGP, выбирает лучший, инсталлирует его в Таблицу Маршрутизации, при необходимости пересылает Update дальше.
- Администратор включил LDP. Для каждого префикса создаётся FEC, назначается метка, помещается в таблицу меток, анонсы уходят всем LDP-соседям.
- Собрали два коммутатора в стек. Выбрать главный, проиндексировать интерфейсы, актуализировать таблицы пересылок — задача Control Plane.
Работа и реализация Control Plane универсальна: ЦПУ + оперативная память: работает одинаково хоть на стоечных маршрутизаторах, хоть на виртуальных сетевых устройствах.
Эта система — не мысленный эксперимент, не различные функции одной программы, это действительно физически разделённые тракты, которые взаимодействуют друг с другом.
Началось всё с разнесения плоскостей на разные платы. Далее появились стекируемые устройства, где одно выполняло интеллектуальные операции, а другое было лишь интерфейсным придатком.
Вчерашний день — это системы вроде Cisco Nexus 5000 Switch + Nexus 2000 Fabric Extender, где 2000 выступает в роли выносной интерфейсной платы для 5000.
Где-то в параллельной Вселенной тихо живёт SDN разлива 1.0 — с Openflow-like механизмами, где Control Plane вынесли на внешние контроллеры, а таблицы пересылок заливаются в совершенно глупые коммутаторы.
Наша реальность и ближайшее будущее — это наложенные сети (Overlay), настраиваемые SDN-контроллерами, где сервисы абстрагированы от физической топологии на более высоком уровне иерархии.
И несмотря на то, что с каждой статьёй мы всё глубже погружаемся в детали, мы учимся мыслить свободно и глобально.
Разделение на Control и Forwarding Plane позволило отвязать передачу данных от работы протоколов и построения сети, а это повлекло значительное повышение масштабируемости и отказоустойчивости.
Так один модуль плоскости управления может поддерживать несколько интерфейсных модулей.
В случае сбоя на плоскости управления механизмы GR, NSR, GRES и ISSU помогают плоскости пересылки продолжать работать будто ничего и не было.
Management Plane
Плоскость или демон наблюдения. Не всегда его выделяют в самостоятельную плоскость, относя его задачи к Control Plane, а иногда, выделяя, называют Monitoring.
Этот модуль отвечает за конфигурацию и жизнедеятельность узла. Он следит за такими параметрами, как:
- Температура
- Утилизация ресурсов
- Электропитание
- Скорость вращения вентиляторов
- Работоспособность плат и модулей.
Примеры:
- Упал интерфейс — генерируется авария, лог и трап на систему мониторинга
- Поднялась температура чипа — увеличивает скорость вращения вентиляторов
- Обнаружил, что одна плата перестала отвечать на периодические запросы — выполняет рестарт плат — вдруг поднимется.
- Оператор подключился по SSH для снятия диагнонстической информации — CLI также обеспечивается Control Plane’ом.
- Приехала конфигурация по Netconf — Management Plane проверяет и применяет её. При необходимости инструктирует Control Plane о произошедших изменениях и необходимых действиях.
Итак:
Forwarding Plane — передача трафика на основе таблиц пересылок — собственно то, из чего оператор извлекает прибыль.
Control Plane — служебный уровень, необходимый для формирования условий для работы Forwarding Plane.
Management Plane — модуль, следящий за общим состоянием устройства.
Вместе они составляют самодостаточный узел в сети пакетной коммутации.
Разделение на Control и Forwarding/Data Plane — не абстрактное — их функции действительно выполняют разные чипы на плате.
Так Control Plane обычно реализован на связке CPU+RAM+карта памяти, а Forwarding Plane на ASIC, FPGA, CAM, TCAM.
Но в мире виртуализации сетевых функций всё смешалось — эту ремарку я буду делать до конца статьи.
3. История способов обработки трафика
Сейчас с Forwarding Plane всё отлично: 10 Гб/с, 100 Гб/с — не составляют труда — плати и пользуйся. Любые политики без влияния на производительность. Но так было не всегда.
В чём сложности?
В первую очередь это вопрос организации вышеописанных трактов: что делать с электрическим импульсом из одного кабеля и как его передать в другой — правильный.
Для этого на сетевых устройствах есть букет разнообразных чипов.

Это пример интерфейсной платы Cisco
Так, например, микросхемы (ASIC, FPGA) выполняют простые операции, вроде АЦП/ЦАП, подсчёта контрольных сум, буферизации пакетов.
Ещё нужен модуль, который умеет парсить, анализировать и формировать заголовки пакетов.
И модуль, который будет определять, куда, в какой интерфейс, пакет надо передать. Делать это нужно для каждого божьего пакета.
Кто-то должен также следить и за тем, можно ли этот пакет пропускать вообще. То есть проверить его на предмет подпадания под ACL, контролировать скорость потока и отбросить, если она превышена.
Сюда же можно вписать и более комплексные функции трансляции адресов, файрвола, балансировки итд.
Исторически все сложные действия выполнялись на CPU. Поиск подходящего маршрута в таблице маршрутизации был реализован как программный код, проверка на удовлетворение политикам — тоже. Процессор с этим справлялся, но только он с этим и справлялся.
Чем это грозит понятно: производительность будет падать тем сильнее, чем больше трафика устройство должно перемалывать и чем больше функций мы будем вешать на него. Поэтому одна за другой большинство функций были делегированы на отдельные чипы.
И из обычного x86-сервера маршрутизаторы превратились в специализированные сетевые коробки, набитые непонятными деталями и интерфейсами. А Ethernet-хабы переродились в интеллектуальные коммутаторы.
Функции по парсингу заголовков и их анализу, а также поиску выходного интерфейса взяли на себя ASIC, FPGA, Network Processor.
Обработка в очередях, обеспечение QoS, управление перегрузками — тоже специализированные ASIC.
Такие вещи, как стейтфул файрвол, остались на ЦПУ, потому что количество сессий несъедобное.
Другой вопрос: мы где-то должны хранить таблицы коммутации. В чём-то быстром.
Первое, что приходит в голову — это классическая оперативная память.
Проблема с ней в том, что обращение к ней идёт по адресу ячейки, а возвращает она уже её содержимое (или контент, не по-русски если).
Однако входящий пакет несёт в себе никак не адрес ячейки памяти, а только MAC, IP, MPLS.
Тогда бы нам пришлось иметь некий хэш алгоритм, который, задействуя CPU, высчитывал бы адрес ячейки и извлекал оттуда нужные данные.
Вот только пропускная способность порта в 10 Гб/с означает, что CPU должен передавать 1 бит каждые 10 нс. И у него есть порядка 80 мкс, чтобы передать пакет размером в один килобайт.
Впрочем, вычисление хэша — алгоритм очень простой, и любой мало-мальски уважающий себя ASIC с этим справится. Инженерам был адресован вопрос —, а что дальше делать с хэшем?
Так появилась память CAM — Content Addressable Memory. Её адреса — это хэши значений. В своей ячейке CAM содержит или ответное значение (номер порта, например) или чаще адрес ячейки в обычной RAM.
То есть пришёл Ethernet-кадр, ASIC’и его разорвали на заголовки, вытащили DMAC — прогнали его через CAM и получили вожделенный исходящий интерфейс.
Подробнее о CAM дальше.
Что с тобой не так, IP?!
Я не зря взял в пример Ethernet-кадр. С IP совсем другая история.
MAC-коммутация — это просто: ни тебе агрегации маршрутов, ни тебе Longest Prefix Match — только 48 уникальных бит.
А вот в IP это всё есть. У нас может быть несколько маршрутов в Таблице Маршрутизации с разными длинами масок и выбрать нужно наидлиннейшую. Это базовый принцип IP-маршрутизации, с которым не поспоришь и не обойдёшь.
Кроме того есть сложные ACL с их Wildcard-масками.
Долгое время решения этой проблемы не существовало. На заре сетей с пакетной коммутацией IP-пакеты обрабатывались на CPU. И главная проблема этого — даже не коммутация на скорости линии (хотя и она тоже), а влияние дополнительных настроек на производительность. Вы и сейчас можете это увидеть на каком-нибудь домашнем микротике, если настроить на нём с десяток ACL — сразу заметите, как просядет пропускная способность.
Интернет разрастался, политик становилось всё больше, а требования к пропускной способности подпрыгивали скачкообразно, и CPU становился камнем преткновения. Тем более учитывая, что поиск маршрута подчас приходилось делать не один раз, а рекурсивно погружаться всё глубже.
Так в лихие 90-е зародился MPLS. Какая блестящая идея — построить заранее путь на Control Plane. Адресацией в MPLS будет метка фиксированной длины, и соответственно нужна единственная запись в таблице меток, что с пакетом дальше делать. При этом мы не теряем гибкости IP, поскольку он лежит в основе, и можем использовать CAM. Плюс заголовок MPLS — короток (4 байта против 20 в IP) и предельно прост.
Однако по иронии судьбы в то же время инженеры совершили прорыв, разработав TCAM — Ternary CAM. И с тех пор ограничений уже почти не было (хотя не без оговорок).
Подробнее от TCAM дальше.
Что же до MPLS, который ввиду данного события должен был скоропостижно скончаться, едва родившись, то он прорубил себе дверь в другой дом. Но об этом мы уже наговорились.
О дивный новый мир
В последнее десятилетие вокруг SDN и NFV поднялся небезосновательный хайп. Развитие виртуализации и облачных сервисов, как её квинтэссенция, предъявляет к сети такие требования, которые не могут удовлетворить традиционные устройства и подходы.
- Нужна маршрутизация и коммутация в пределах одного сервера между различными виртуалками.
- Горизонтальная масштабируемость требует возможности запускать новые виртуалки в любой части сети, а соответственно и адаптировать её конфигурацию.
- Цепочка услуг (Service Chain), такая как Anti-DDoS, IDS/IPS, FW предполагает маршрутизацию, управляемую программно и автоматическую настройку сетевых узлов.
Поэтому большая часть сетевой инфраструктуры ЦОДов сейчас виртуализируется. А это предполагает переход от аппаратной архитектуры к гибридной. CAM, TCAM, NP, ASIC сейчас заменяются на связку DPDK с более умными сетевыми картами, которые тоже поддерживают виртуалиацию — SR-IOV — и забирают на свои чипы некоторую часть рутинной работы.
Кроме того, с развитием алгоритмических методов поиска, сегодня сокращается необходимость в CAM/TCAM на традиционных коммутаторах и маршрутизаторах.
Таким образом мы снова становимся свидетелями сдвига парадигмы в вопросе реализации Forwarding Plane.Но мы пока остаёмся в сфере аппаратной пересылки и теперь давайте подробнее обо всех чипах.
4. Типов-чипов
Я не ставлю целью данной статьи описать все существующие чипы — только те, что используются в сетевом оборудовании.
CPU — Central Processing Unit
Самый медленный, но самый гибкий элемент устройства — центральный процессор.
Он занимается обработкой протокольных пакетов и сложного поведения.

Его прелесть в том, что он управляется запущенными приложениями и «многозадачен». Логику легко изменить, просто поправив программный код.
Такие вещи, как SPF, установка соседства по всем протоколам, генерация логов, аварий, подключение к пользовательским интерфейсам управления — все действия со сложной логикой — происходят на нём.
Собственно, поэтому, например, вы можете наблюдать, что при высокой загрузке CPU становится некомфортно работать в консоли. Хотя трафик при этом ходит уверенно.
CPU берёт на себя функции Control Plane.
На устройствах с программной пересылкой, участвует также и в Forwarding Plane.
CPU может быть один на весь узел, а может быть отдельно на каждой плате в шасси при распределённой архитектуре.
Результаты своей работы CPU записывает в оперативную память ↓.
RAM — Random Access Memory
Классическая оперативная память — куда без неё?

Мы ей адрес ячейки — она нам содержимое.
В ней хранятся, так называемые Soft Tables (программные таблицы) — таблицы маршрутизации, меток, MAC-адресов.
Когда вы выполняете команду «show ip route», запрос идёт именно в оперативку к Soft Tables.
CPU работает именно с оперативной памятью — когда он посчитал маршрут, или построил LSP — результат записывается в неё. А уже оттуда изменения синхронизируются в Hard Tables в CAM/TCAM↓.
Кроме того, периодически происходит синхронизация всего содержимого всех таблиц на случай, если вдруг по какой-то причине инкрементальные изменения не спустились корректно.
Soft Tables не может быть непосредственно использован для передачи данных, потому что слишком медленно — обращение к оперативке идёт через ЦПУ и требуется алгоритмический поиск, затратный по времени. С оговоркой на NFV.
Кроме того на чипах RAM (DRAM) реализованы очереди: входные, выходные, интерфейсные.
CAM — Content-Addressable Memory
Это особо-хитрый вид памяти.
Вы ей — значение, а она вам — адрес ячейки.
Content-Addressable означает, что адресация базируется на значениях (содержимом).

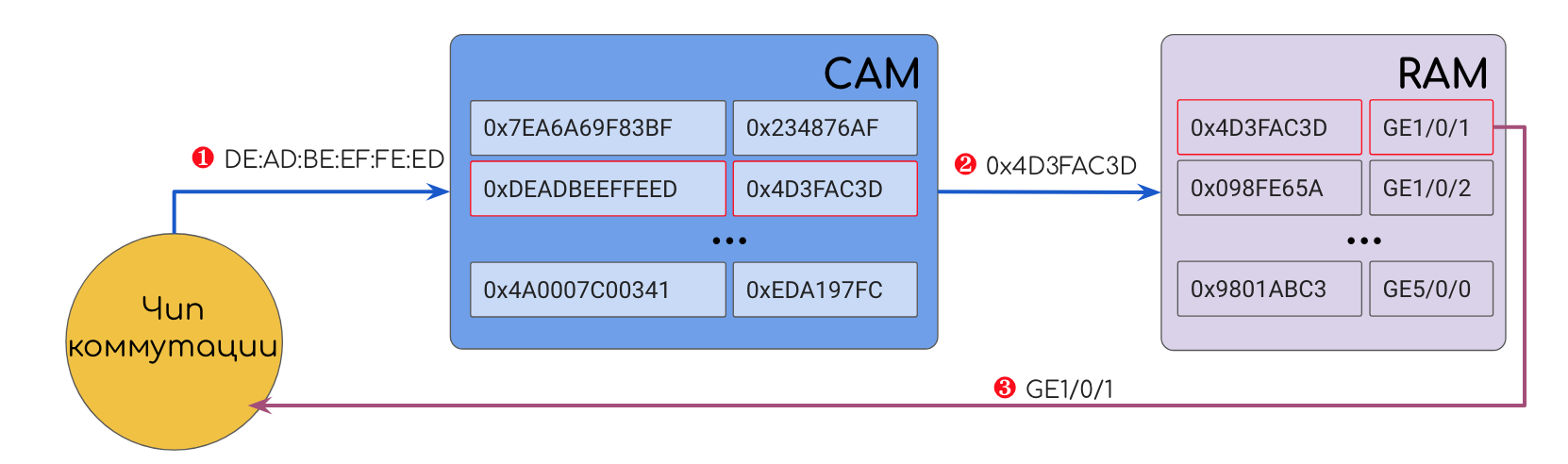
Значением, например, может быть, например DMAC. CAM прогоняет DMAC по всем своим записям и находит совпадение. В результате CAM выдаст адрес ячейки в классической RAM, где хранится номер выходного интерфейса. Дальше устройство обращается к этой ячейке и отправляет кадр, куда положено.
Для достижения максимальной скорости CAM и RAM располагаются очень близко друг к другу.
Не путать данную RAM с RAM, содержащей Soft Tables, описанной выше — это разные компоненты, расположенные в разных местах.
Прелесть CAM в том, что она возвращает результат за фиксированное время, не зависящее от количества и размера записей в таблице — О (1), выражаясь в терминах сложностей алгоритмов.
Достигается это за счёт того, что значение сравнивается одновременно со всеми записями. Одновременно! А не перебором.
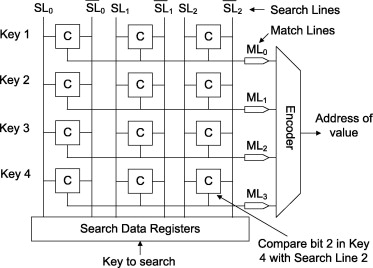
На входе каждой ячейки хранения в CAM стоят сравнивающие элементы (мне очень нравится термин компараторы), которые могут выдавать 0 (разомкнуто) или 1 (замкнуто) в зависимости от того, что на них поступило и что записано.
В сравнивающих элементах записаны как раз искомые значения.
Когда нужно найти запись в таблице, соответствующую определённому значению, это значение прогоняется одновременно через ВСЕ сравнивающие элементы. Буквально, электрический импульс, несущий значения, попадает на все элементы, благодаря тому, что они подключены параллельно. Каждый из них выполняет очень простое действие, выдавая для каждого бита 1, если биты совпали, и 0, если нет, то есть замыкая и размыкая контакт. Таким образом та ячейка, адресом которой является искомое значение, замыкает всю цепь, электрический сигнал проходит и запитывает её.
Вот архитектура такой памяти:
Источник картинки.
Вот пример работы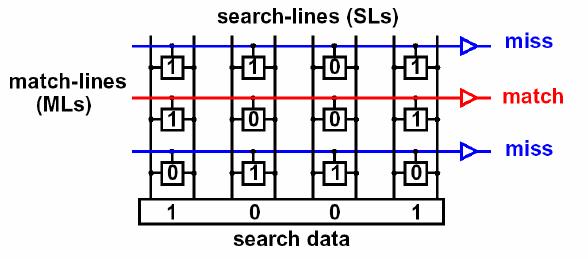
Картинка из прелюбопытнейшего документа.
А это схема реализации: 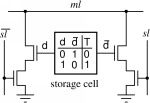
Источник картинки.
Это чем-то похоже на пару ключ-замок. Только ключ с правильной геометрией может поставить штифты замка в правильные положения и провернуть цилиндр.
Вот только у нас много копий одного ключа и много разных конфигураций замков. И мы вставляем их все одновременно и пытаемся провернуть, а нужное значение лежит за той дверью, замок которой ключ откроет.
Для гибкого использования CAM мы берём не непосредственно значения из полей заголовков, а вычисляем их хэш.
Хэш-функция используется для следующих целей:
- Длина результата значительно меньше, чем у входных значений. Так пространство MAC-адресов длиной 48 бит можно отобразить в 16-ибитовое значение, тем самым в 2^32 раза уменьшив длину значений, которые нужно сравнивать, и соответственно, размер CAM.
Основная идея хэш-функции в том, что результат её выполнения для одинаковых входных данных всегда будет одинаков (например, как остаток от деления одного числа на другое — это пример элементарной хэш функции). - Результат её выполнения на всём пространстве входных значений — это ± плоскость — все значения равновероятны. Это важно для снижения вероятности конфликта хэшей, когда два значения дают одинаковый результат.
Конфликт хэшей, кстати, весьма любопытная проблема, которая описана в парадоксе дней рождения. Рекомендую почитать Hardware Defined Networking Брайна Петерсена, где помимо всего прочего он описывает механизмы избежания конфликта хэшей. - Независимо от длины исходных аргументов, результат будет всегда одной длины. То есть на вход можно подать сложное сочетание аргументов, например, DMAC+EtherType, и для хранения не потребуется выделять более сложную структуру памяти.
Именно хэш закодирован в сравнивающие элементы. Именно хэш искомого значения будет сравниваться с ними.
По принципу CAM схож с хэш-таблицами в программировании, только реализованными на чипах.
В этот принцип отлично укладывается также MPLS-коммутация, почему MPLS и сватали в своё время на IP.
Например:
- Пришёл самый первый Ethernet-кадр на порт коммутатора.
- Коммутатор извлёк SMAC, вычислил его хэш.
- Данный хэш он записал в сравнивающие элементы CAM, номер интерфейса откуда пришёл кадр в RAM, а в саму ячейку CAM адрес ячейки в RAM.
- Выполнил рассылку изначального кадра во все порты.
- Повторил пп. 1–5 …
- Заполнена вся таблица MAC-адресов.
- Приходит Ethernet-кадр. Коммутатор сначала проверяет, известен ли ему данный SMAC (сравнивает хэш адреса с записанными хэшами в CAM) и, если нет, сохраняет.
- Извлекает DMAC, считает его хэш.
- Данный хэш он прогоняет через все сравнивающие элементы CAM и находит единственное совпадение.
- Узнаёт номер порта, отправляет туда изначальный кадр.
Резюме:
- Ячейки CAM адресуются хэшами.
- Ячейки CAM содержат (обычно) адрес ячейки в обычной памяти (RAM), потому что хранить конечную информацию — дорого.
- Каждая ячейка CAM имеет на входе сравнивающий элемент, который сравнивает искомое значение с хэш-адресом. От этого размер и стоимость CAM значительно больше, чем RAM.
- Проверка совпадения происходит одновременно во всех записях, отчего CAM дюже греется, зато выдаёт результат за константное время.
- CAM+RAM хранят Hard Tables (аппаратные таблицы), к которым обращается чип коммутации.
TCAM — Ternary Content-Addressable Memory
Возвращаемся к вопросу, что не так с IP.
Если мы возьмём описанный выше CAM, то на любой DIP он очень редко сможет вернуть 1 во всех битах.
Дело в том, что DIP — это всегда один единственный адрес, а маршруты в таблице маршрутизации — это подсеть или даже агрегация более мелких маршрутов. Поэтому полного совпадения быть почти не может — кроме случая, когда есть маршрут /32.
Перед разработчиками чипов стояло два вопроса:
- Как это в принципе реализовать?
- Как из нескольких подходящих маршрутов выбрать лучший (с длиннейшей маской)?

Ответом стал TCAM, в котором «T» означает «троичный». Помимо 0 и 1 вводится ещё одно значение Х — «не важно» (CAM иногда называют BCAM — Binary, поскольку там значения два — 0 и 1).
Тогда результатом поиска нужной записи в таблице коммутации будет содержимое той ячейки, где самая длинная цепочка 1 и самая короткая «не важно».
Например, пакет адресован на DIP 10.10.10.10.
В Таблице Маршрутизации у нас следующие маршруты: 0.0.0.0/0
10.10.10.8/29
10.10.0.0/16
10.8.0.0/13
Другие.
В сравнивающие элементы TCAM записываются биты маршрута, если в маске стоит 1, и «не важно», если 0.
При поиске нужной записи TCAM, как и CAM, прогоняет искомое значение одновременно по всем ячейкам. Результатом будет последовательность 0, 1 и «не важно».
Только те записи, которые вернули последовательность единиц, за которыми следуют «не важно» участвуют в следующем этапе селекции.
Далее из всех результатов выбирается тот, где самая длинная последовательность единиц — так реализуется правило Longest p
