Scapegoat-деревья
 Сегодня мы посмотрим на структуру данных, называемую Scapegoat-деревом. «Scapegoat», кто не в курсе, переводится как «козёл отпущения», что делает дословный перевод названия структуры каким-то странным, поэтому будем использовать оригинальное название. Деревьев поиска, как вы, возможно, знаете есть очень много разных видов, и в основе всех их лежит одна и та же идея: «А хорошо бы при поиске элемента перебирать не весь набор данных подряд, а только какую-то часть, желательно размера порядка log (N)».Для этого каждая вершина хранит ссылки на своих детей и какой-то критерий, по которому при поиске точно понятно, в какую из дочерних вершин надо перейти. За логарифмическое время это всё будет работать тогда, когда дерево является сбалансированным (ну или стремится к этому) — т.е. когда «высота» каждого из поддеревьев каждой вершины примерно одинакова. А вот способы балансировки дерева уже у каждого типа деревьев свои: в красно-чёрных деревьях в вершинах хранятся маркеры «цвета», подсказывающие когда и как нужно перебалансировать дерево, в АВЛ-деревьях в вершинах хранится разница высот детей, Splay-деревья ради балансировки вынуждены изменять дерево во время операций поиска и т.д.
Сегодня мы посмотрим на структуру данных, называемую Scapegoat-деревом. «Scapegoat», кто не в курсе, переводится как «козёл отпущения», что делает дословный перевод названия структуры каким-то странным, поэтому будем использовать оригинальное название. Деревьев поиска, как вы, возможно, знаете есть очень много разных видов, и в основе всех их лежит одна и та же идея: «А хорошо бы при поиске элемента перебирать не весь набор данных подряд, а только какую-то часть, желательно размера порядка log (N)».Для этого каждая вершина хранит ссылки на своих детей и какой-то критерий, по которому при поиске точно понятно, в какую из дочерних вершин надо перейти. За логарифмическое время это всё будет работать тогда, когда дерево является сбалансированным (ну или стремится к этому) — т.е. когда «высота» каждого из поддеревьев каждой вершины примерно одинакова. А вот способы балансировки дерева уже у каждого типа деревьев свои: в красно-чёрных деревьях в вершинах хранятся маркеры «цвета», подсказывающие когда и как нужно перебалансировать дерево, в АВЛ-деревьях в вершинах хранится разница высот детей, Splay-деревья ради балансировки вынуждены изменять дерево во время операций поиска и т.д.
Scapegoat-дерево тоже имеет свой подход к решению проблемы балансировки дерева. Как и для всех остальных случаев он не идеален, но вполне применим в некоторых ситуациях.
К достоинствам Scapegoat-дерева можно отнести:
Отсутствие необходимости хранить какие-либо дополнительные данные в вершинах (а значит мы выигрываем по памяти у красно-черных, АВЛ и декартовых деревьев) Отсутствие необходимости перебалансировать дерево при операции поиска (а значит мы можем гарантировать максимальное время поиска O (log N), в отличии от Splay-деревьев, где гарантируется только амортизированное O (log N)) Амортизированная сложность операций вставки и удаления O (log N) — это в общем-то аналогично остальным типам деревьев При построении дерева мы выбираем некоторый коэффициент «строгости» α, который позволяет «тюнинговать» дерево, делая операции поиска более быстрыми за счет замедления операций модификации или наоборот. Можно реализовать структуру данных, а дальше уже подбирать коэффициент по результатам тестов на реальных данных и специфики использования дерева. К недостаткам можно отнести: В худшем случае операции модификации дерева могут занять O (n) времени (амортизированна сложность у них по-прежнему O (log N), но защиты от «плохих» случаев нет). Можно неправильно оценить частоту разных операций с деревом и ошибиться с выбором коэффициента α — в результате часто используемые операции будут работать долго, а редко используемые — быстро, что как-то не хорошо. Давайте будем разбираться что же такое Scapegoat-дерево и как для него выполнять операции поиска, вставки и удаления.
Используемые понятия (квадратные скобки в обозначениях выше означают, что мы храним это значение явно, а значит можем взять за время О (1). Круглые скобки означают, что значение будет вычисляться по ходу дела т.е. память не расходуется, но зато нужно время на вычисление)
T — так будем обозначать дерево
root[T] — корень дерева T
left[x] — левый «сын» вершины х
right[x] — левый «сын» вершины х
brother (x) — брат вершины х (вершина, которая имеет с х общего родителя)
depth (x) — глубина вершины х. Это расстояние от неё до корня (количество ребер)
height (T) — глубина дерева T. Это глубина самой глубокой вершины дерева T
size (x) — вес вершины х. Это количество всех её дочерних вершин + 1 (она сама)
size[х] — размер дерева T. Это количество вершин в нём (вес корня)
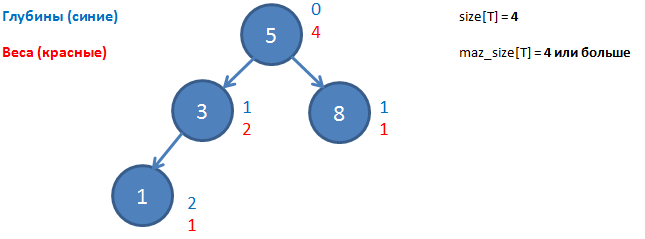
Теперь введем понятия, необходимые нам для Scapegoat-дерева:
Давайте попробуем понять этот критерий. Если α = 0.5 мы требуем чтобы в левом поддереве было ровно столько же вершин, сколько в правом (± 1). Т.е. фактически это требование идеально сбалансированного дерева. При α > 0.5 мы говорим «ок, пусть балансировка будет не идеальной, пусть одному из поддеревьев будет позволено иметь больше вершин, чем другому». При α = 0.6 одно из поддеревьев вершины х может содержать до 60% всех вершин поддерева х чтобы вершина х всё ещё считалась «α-сбалансированной по весу». Легко увидеть, что при α стремящемуся к 1 мы фактически соглашаемся считать «α-сбалансированным по весу» даже обычный связный список.
Теперь давайте посмотрим как в Scapegoat-дереве выполняются обычные операции.В начале работы с деревом мы выбираем параметр α в диапазоне [0.5; 1). Также заводим две переменные для хранения текущих значений size[T] и max_size[T] и обнуляем их.
ПоискИтак, у нас есть некоторое Scapegoat-дерево и мы хотим найти в нём элемент. Поскольку это двоичное дерево поиска, то и поиск будет стандартным: идём от корня, сравниваем вершину с искомым значением, если нашли — возвращаем, если значение в вершине меньше — рекурсивно ищем в левом поддереве, если больше — в правом. Дерево по ходу поиска не модифицируется.
Сложность операции поиска, как вы могли догадаться, зависит от α и выражается формулой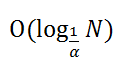 Т.е. сложность, конечно, логарифмическая, вот только основание логарифма интересное. При α близком к 0.5 мы получаем двоичный (или почти двоичный) логарифм, что означает идеальную (или почти идеальную) скорость поиска. При α близком к единице основание логарифма стремится к единице, а значит общая сложность стремится к O (N). Ага, а никто и не обещал идеала.
Т.е. сложность, конечно, логарифмическая, вот только основание логарифма интересное. При α близком к 0.5 мы получаем двоичный (или почти двоичный) логарифм, что означает идеальную (или почти идеальную) скорость поиска. При α близком к единице основание логарифма стремится к единице, а значит общая сложность стремится к O (N). Ага, а никто и не обещал идеала.
ВставкаНачинается вставка нового элемента в Scapegoat-дерево классически: поиском ищем место, куда бы подвесить новую вершину, ну и подвешиваем. Легко понять, что это действие могло нарушить α-балансировку по весу для одной или более вершин дерева. И вот теперь начинается то, что и дало название структуре данных: мы ищем «козла отпущения» (Scapegoat-вершину) — вершину, для которой потерян α-баланс и её поддерево должно быть перестроено. Сама только что вставленная вершина, хотя и виновата в потере баланса, «козлом отпущения» стать не может — у неё ещё нет «детей», а значит её баланс идеален. Соответственно, нужно пройти по дереву от этой вершины к корню, пересчитывая веса для каждой вершины по пути. Если на этом пути встретится вершина, для которой критерий α-сбалансированности по весу нарушился — мы полностью перестраиваем соответствующее ей поддерево так, чтобы восстановить α-сбалансированность по весу.
По ходу дела возникает ряд вопросов: — А как пройти от вершины «вверх» корню? Нам нужно хранить ссылки на родителей? — Нет. Поскольку мы пришли к месту вставки новой вершины из корня дерева — у нас есть стек, в котором находится весь путь от корня к новой вершине. Берём родителей из него.
— А как посчитать «вес» вершины — мы же его не храним в самой вершине? — Нет, не храним. Для новой вершины вес = 1. Для её родителя вес = 1 (вес новой вершины) + 1 (вес самого родителя) + size (brother (x)).
— Ну ок, а как посчитать size (brother (x)) ? — Рекурсивно. Да, это займёт время O (size (brother (x))). Понимая, что в худшем случае нам, возможно, придётся посчитать вес половины дерева — мы видим ту самую сложность O (N) в худшем случае, о которой говорилось в начале. Но поскольку мы обходим поддерево α-сбалансированного по весу дерева можно показать, что амортизированная сложность операции не превысит O (log N).
— А ведь вершин, для которых нарушился α-баланс может быть и несколько — что делать? — Короткий ответ: можно выбирать любую. Длинный ответ: в оригинальном документе с описанием структуры данных есть пара эвристик, как можно выбрать «конкретного козла отпущения» (вот это терминология пошла!), но вообще-то они сводятся к «вот мы попробовали так и так, эксперименты показали, что вроде вот так лучше, но почему — объяснить не можем».
— А как делать перебалансировку найденной Scapegoat-вершины? — Есть два пути: тривиальный и чуть более хитрый.
Тривиальная перебалансировкаОбходим всё поддерево Scapegoat-вершины (включая её саму) с помощью in-order обхода — на выходе получаем отсортированный список (свойство In-order обхода бинарного дерева поиска). Находим медиану на этом отрезке, подвешиваем её в качестве корня поддерева. Для «левого» и «правого» поддерева рекурсивно повторяем ту же операцию. Видно, что всё это дело требует O (size (Scapegoat-вершина)) времени и столько же памяти.
Чуть более хитрая перебалансировка Мы вряд ли улучшим время работы перебалансировки — всё-таки каждую вершину нужно «подвесить» в новое место. Но мы можем попробовать сэкономить память. Давайте посмотрим на «тривиальный» алгоритм внимательнее. Вот мы выбираем медиану, подвешиваем в корень, дерево делится на два поддерева — и делится весьма однозначно. Никак нельзя выбрать «какую-то другую медиану» или подвесить «правое» поддерево вместо левого. Та же самая однозначность преследует нас и на каждом из следующих шагов. Т.е. для некоторого списка вершин, отсортированных в возрастающем порядке, у нас будет ровно одно порождённое данным алгоритмом дерево. А откуда же мы взяли отсортированный список вершин? Из in-order обхода изначального дерева. Т.е. каждой вершине, найденной по ходу in-order обхода перебалансируемого дерева соответствует одна конкретная позиция в новом дереве. И мы можем эту позицию рассчитать в принципе и без создания самого отсортированного списка. А рассчитав — сразу её туда записать. Возникает только одна проблема — мы ведь этим затираем какую-то (возможно ещё не просмотренную) вершину — что же делать? Хранить её. Где? Ну, выделять для списка таких вершин память. Но этой памяти нужно будет уже не O (size (N)), а всего лишь O (log N).В качестве упражнения представьте себе в уме дерево, состоящее из трёх вершин — корня и двух подвешенных как «левые» сыновья вершин. In-order обход вернёт нам эти вершины в порядке от самой «глубокой» до корня, но хранить в отдельной памяти по ходу этого обхода нам придётся всего одну вершину (самую глубокую), поскольку когда мы придём во вторую вершину, мы уже будем знать, что это медиана и она будет корнем, а остальные две вершины — её детьми. Т.е. расход памяти здесь — на хранение одной вершины, что согласуется с верхней оценкой для дерева из трёх вершин — log (3).
Удаление вершиныУдаляем вершину обычным удалением вершины бинарного дерева поиска (поиск, удаление, возможное переподвешивание детей).Далее проверяем выполнение условияsize[T] < α * max_size[T]если оно выполняется — дерево могло потерять α-балансировку по весу, а значит нужно выполнить полную перебалансировку дерева (начиная с корня) и присвоить max_size[T] = size[T]
Насколько это всё производительно? Отсутствие оверхеда по памяти и перебалансировки при поиске — это хорошо, это работает на нас. С другой стороны перебалансировки при модификациях не так чтобы уж очень дешевы. Ну и выбор α существенно влияет на производительность тех или иных операций. Сами изобретатели сравнивали производительность Scapegoat-дерева с красно-черными и Splay-деревьями. У них получилось подобрать α так, что на случайных данных Scapegoat-дерево превзошло по скорости все другие типы деревьев, на любых операциях (что вообще-то весьма неплохо). К сожалению, на монотонно-возрастающем наборе данных Scapegoat-дерево работает хуже в части операций вставки и выиграть у Scapegoat не вышло ни при каком α.
