Сага о том, как Java-разработчики должны тестировать свои приложения. Часть 1
Пост получился просто огромный, так что мы разбили его на две части. Сейчас вы читаете первую часть, а вторая выйдет уже завтра, так же в 10 утра.
Видеозапись доклада:
Коротко о себе
Меня зовут Николай Алименков, я приехал к вам из солнечного Киева. У меня есть Twitter. Если у вас он тоже есть, и вы читаете что-то о Java и процессах разработки — присоединяйтесь.

Я достаточно давно работаю с agile-методологиям и инженерными практиками. Основное направление моей деятельности на протяжении всей достаточно длинной карьеры — это Java и разработка больших распределенных систем разного рода. Большую часть этого времени я работал в качестве Java Technical Lead и Delivery Manager.
По совместительству я являюсь основателем и тренером в тренинговом центре XP Injection, от имени которого мы проводим много интересных мероприятий. У нас есть большие конференции:
- Selenium Camp, целиком и полностью посвященная вопросам автоматизации тестирования. Изначально конференция, существующая с 2011 года, была полностью посвящена Selenium/WebDriver, но сейчас она вышла за его рамки;
- JEE Conf — крупнейшая Java-конференция в Восточной Европе, посвященная современным подходам к разработке распределенных, высоконагруженных, масштабируемых систем, новым направлениям и интересным архитектурным решениям Java, взаимодействию с другими технологиями;
- большая конференция XP days Ukraine, которая посвящена инженерным практикам (continuous delivery, continuous integration, тестированию, автоматизации и всему, что касается инженерной практики), а также инструментарию, позволяющему реализовать обсуждаемые подходы.
На текущий момент я работаю в компании EPAM в должности Senior Delivery Manager, возглавляя большой продуктовый проект. Команда сейчас больше 150 человек, мы растем и планируем, что будем расти и дальше. То, о чём я буду сегодня рассказывать, мы используем в командах не только на этом, но и на других проектах. Все это масштабируется как на маленькие, так и на большие команды без всяких проблем.
Однако всё, что я вам буду рассказывать, базируется на моем персональном опыте и на моем видении, как это должно делаться. Ваш опыт и видение могут не совпадать с изложенным. Если у вас есть другое мнение, буду рад при случае все обсудить.
Тестирование бизнес-логики
Давайте начнем с достаточно простого — с бизнес-логики. Здесь есть 2 основных школы.
Первая школа говорит, что любая существующая логика должна тестироваться в полной изоляции от любой другой логики. Иными словами, вы должны создавать полностью изолированное окружение для каждого кусочка своей бизнес-логики. Если вы тестируете сервис, то любые другие классы, используемые, чтобы дернуть еще какие-то кусочки логики, трансформации и т.п., должны быть изолированы. Т.е. эта школа настаивает на том, что везде следует использовать моки и тестировать в полной изоляции.
У этого подхода есть замечательное преимущество: в тесте вы можете эмулировать любое условие, которые только можно придумать. Надо вам, чтобы какой-то sender сообщения бросил exception любого рода (даже такого, который очень тяжело симулировать в реальной жизни) — без проблем. Например, вы можете узнать, как ответит ваш код на «Out of memory». Он съест «out of memory»? Или залогирует и пойдет дальше? Такие вещи тоже можно протестировать.
Это дает определенную свободу. И плюсы подхода явно видны: тесты выполняются очень быстро, с ними просто. И тут существует огромное количество библиотек.
Вторая школа говорит обратное. Если мы тестируем логику, то мы должны тестировать ее целиком со всем окружением, за исключением достаточно сложных структур, например, внешних систем — их нужно каким-то образом изолировать. У этого подхода также есть определенные плюсы. Один из них — в том, что вы одновременно тестируете не только саму логику, но еще и интеграцию с окружением. Это значит, что тесты будут более показательными, дадут больше информации о ситуации, если что-то пошло не так. Ведь часто бывает, что все юнит-тесты проходят, но приложение даже не поднимается. А причина очень простая: каждый элемент по отдельности имел какой-то свой протокол, но когда они собрались вместе, оказалось, что для эмуляции поведения вы использовали старый протокол, и, вуаля, ничего не работает. Данный подход защищает от такого развития событий.
Но что происходит, если ваша бизнес-логика обладает некоей витиеватостью (есть логические условия, циклы и прочее), причем во вложенных кусочках логики, которая делегирована кому-то, тоже есть циклы и вложенность. В этом случае у вас появляется очень много тестов, т.к. надо пройти все пути. Вы можете прийти к тому, что для тестирования одного сервисного метода придется написать порядка пятидесяти тестов. Понятное дело, никто не будет писать эти 50 тестов. Вы напишите 10 или 15 и на этом остановитесь, удалившись от изначальной цели — обеспечить нормальное покрытие, которые дало бы вам точное понимание, что все идет хорошо. Но не писать же все 50.
Такие тесты запускаются медленнее. Получается, что это тяжело, но зато не возникает распространенной проблемы с моками (когда ты всё «замокал» и все в итоге не очень надёжно).
Я сторонник первого подхода (где надо всё мокать), но с определенными нюансами. И это как раз самое интересное, о чём я хочу рассказать.
Есть много библиотек для моков: EasyMock, Mockito, JMock, Powermock, Spock и другие. У каждой есть свои плюсы и минусы.
Например, один из минусов Mockito — если вы его используете, необходимо сесть и реально в нем разобраться. А наши девелоперы (под «наши» я имею в виду девелоперов с постсоветского пространства) привыкли, что надо колотить деньги. Они увидели Mockito, посмотрели пример в Stack Overflow или в документации Mockito: «Всё понятно. Сделал мок — в конце сделал verify», — и бросились его применять. Но Mockito работает по принципу spy, т.е. записывает все действия, а вы можете часть проверять, а часть не проверять. Не понимая этой логики, вы можете пойти по совершенно неправильному сценарию. Я видел это в реальной жизни: ребята разрабатывали полгода, но ни в одном тесте не делали правильный verify. В итоге у них было много тестов, которые запускались и были всегда зелеными, но не тестировали ничего (они тестировали, что Mockito все записывал, но в конце ничего не проверяли, поскольку все, по их мнению, должно было записаться). Т.е. разобраться в том, как работает фреймворк, необходимо.
EasyMock ведет себя больше как Strict-мок — по умолчанию проверяет все. Strict-мок, когда вы его чему-то не научили (вызвали какой-то метод, о котором не предупреждали, или вдруг два раза вызвали то, что обещали вызывать один раз), говорит: «Я не умею этого делать, поэтому я упал». Но, опять же, им надо уметь пользоваться, потому что есть логика, позволяющая из такого мока сделать stub или более легковесную конструкцию.
Самая большая проблема с моками возникает, когда у вас есть некий сервис, который на самом деле является интегратором и сам никакой логики не содержит, но внутри дергает других (например, сходи в базу данных и вытащи юзера, для чего передаем туда ID юзера и вытаскиваем юзера, после этого зарегистрируй юзера где-то — регистрируем, возвращаем boolean true, пошли сообщение юзеру на e-mail, что он зарегистрирован и верни boolean true или false). В рамках плоской логики (без ветвистости if-ов) мы дергаем A, потом B и т.д. Как будет выглядеть ваш тест, если мы используем моки? Он будет выглядеть точно так же: ожидать, что вызовется А, потом ожидать, что вызовется B, и т.д. И тут возникает интересный вопрос: не являются ли такие тесты слишком хрупкими? Они просто повторяют реализацию. Если теперь я просто поменяю что-то в реализации (причем, не концептуально — я просто переставлю что-то), придется делать то же самое в тесте.
Есть три пути решения этой проблемы.
- Во-первых, такие сервисы-интеграторы мы не тестируем вовсе. Это самый приятный вариант для разработчика: не надо тестировать — нет проблем. Поскольку у нас используется плоская логика, достаточно вызвать этот сервис хотя бы раз в тесте более высокого уровня. У нас есть REST-тесты или функциональные тесты через UI, и они наверняка этот сервис хоть как-то затронут. Если они его затронули и все прошло хорошо, этого достаточно. Способ очень простой. Кстати, вы даже специально можете помечать интеграторы аннотациями, чтобы во всей статистике покрытия они не учитывались.
- Второй способ мне не очень нравится — это жить с данной болью и действительно иметь тесты, в которых полностью дублируется моками все поведение.
- Третий способ — писать на такие интеграторы интеграционные тесты. Но в этом случае там будет настоящая база, настоящий sender и так далее.
Какой из этих вариантов выбирать — вам виднее.
Примеры из практики
Давайте рассмотрим какие-то практические примеры.
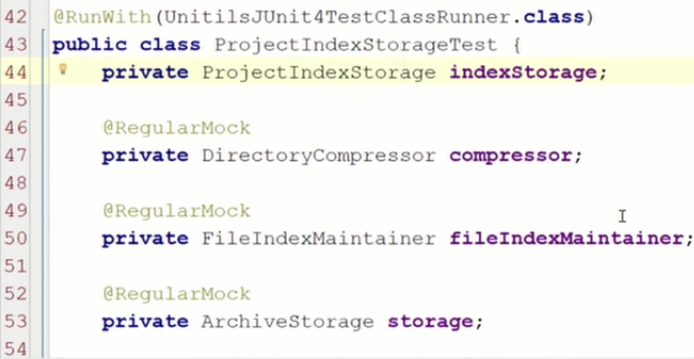
Здесь у меня есть IndexStorage и моки: DirectoryCompressor, FileIndexMaintainer и ArchieveStoreage. Я их всех пометил Regular Mock — это обычный мок.
Как выглядит мой тест:


В конструкторе, когда вызывается init метод теста, я в Before передаю все мои моки в IndexStorage (никакой магии не происходит).
В конце я удаляю файловый dir:

Тест называется «архив создается и сохраняется»:

Здесь есть повторно используемый кусочек:

Тут я как бы говорю: «FileIndexMaintainer, у тебя спросят index по пути, и ты ему верни какую-то такую директорию (это настоящая директория — выше я ее тоже создал)».
После этого: «Storage, тебя должны вызвать. И ты эту настоящую директорию сохрани». Я их всех научил, после чего говорю replay, т.е. они теперь знакомы с этим поведением.
Хочу отметить, что это Strict-мок. Если я теперь поменяю какой-то параметр, например, для storage.store укажу не 11, а 12, он скажет: «Извините, 12 я не ожидал, было только с 11».
После этого я вызываю мой upload и проверяю на файловой системе, что в определенную папку сложился определенный архивчик — assertProjectIdFileExists (11) (хотя это и не относится к мокам):

На что здесь стоит обратить внимание? Когда встречается такая конструкция storage.store ("11", indexActualDir);, — создается некоторое недопонимание. Если вы забыли, что это regular mock, Java-синтаксис создает ощущение, что вы действительно вызываете этот storage. Чтобы такого ощущения не возникало, многие фреймворки, тот же Mockito, имеют свой fluent API. А EasyMock, когда не надо ничего возвращать (как видите, метод store ничего не возвращает, только void), не оборачивают это в expect, а просто вызывают.

Это иногда путает.
Я здесь как раз привел пример, обернув это в expect, чтобы показать: на самом деле это не настоящий вызов. Мне нужно просто объяснить, что это означает. Для этого я выношу метод expectGettingIndexPath:
Это гораздо лучше, чем ставить рядом комментарии. Делайте так, и все будет круто.
Описание через тестирование
Бизнес-логика тестируется по нескольким причинам:
- чтобы убедиться, что она действительно работает так, как вы хотите;
- чтобы добиться безопасности. Если сейчас кто-то пойдет в сам код и по ошибке его поменяет (не так, как вы рассчитывали), ваши тесты должны упасть;
- чтобы где-то было описано, чего умеет ваш класс.
И о последнем пункте я бы хотел поговорить подробнее.
Кто-то делает описания Javadoc-ом. Но насколько часто вы его обновляете?
Обновляем ли мы Javadoc, как только вносим какое-то изменение? Этот подход не очень надежный. Поэтому как дополнительную плюшку от тестов на бизнес-логику хотелось бы иметь описание, что умеет делать тот или иной класс.
Тут все зависит только от вас. Чтобы класс был описан, надо его где-то описать. И есть отличное место для этого — в именах тестовых сценариев.
Вы наверняка видели, как некоторые называют свои тестовые сценарии, допустим, test_success_1, test_success_2 и т.д. Если я потом посмотрю, чего умеет мой класс, то увижу, что он очень «success». Возможно, где-то будет fail. И, к сожалению, это все, что останется мне в наследие от того человека, который в этом классе разобрался, когда писал на него тесты (и, возможно, был автором этого класса).
Если я поступаю по-другому и пытаюсь каждый реализованный тестовый сценарий на бизнес-логику называть в соответствии с тем, что именно я хочу протестировать, получится некая живая спецификация.
Я увижу: archiveIsCreatedAndStored()
Наверное, это success-path — ничего не падает, все хорошо.
Вот другой пример:

Здесь failIndexDownloadIfTempDirectoryRenameHasFailed(), т.е. если падает rename temp directory, то у меня падает вся операция. Это бизнес-rule, которое мы хотим протестировать. И у вас есть прямая связь с этим бизнес-rule, поскольку в спецификации (или задании, в чем бы вы не хранили вашу изначальную задачу реализации бизнес-логики) написано: «Если упал rename temp directory, брось exception».
Есть замечательный plugin для IDEA (и Eclipse тоже) под названием TestDok, который сделает за вас доброе дело — он все тестовые методы, которые мы называем в CamelCase, разбивает на слова, предоставляя для каждого теста коротенькое описание в виде конкретных названий операций, которые могут осуществляться.
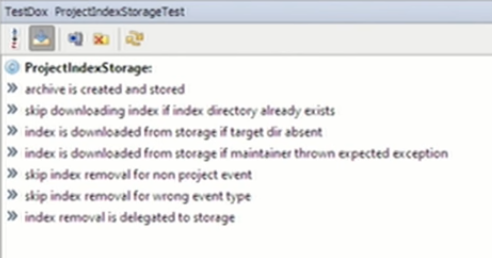
TestDok позволяет вам удобно перемещаться между этими тестами. Представьте, что я никогда не видел этот ProjectIndexStorage. Здесь я могу не просто почитать, что он может (возможно, в Javadoc вы бы тоже это написали). Самый большой бонус в том, что я могу выбрать поведение, которое мне интересно, пойти к нему двойным кликом, увидеть, чего ожидается от тех моков, с которыми я взаимодействую, и запустить это поведение. Могу остановиться в debugging и посмотреть, как оно работает.
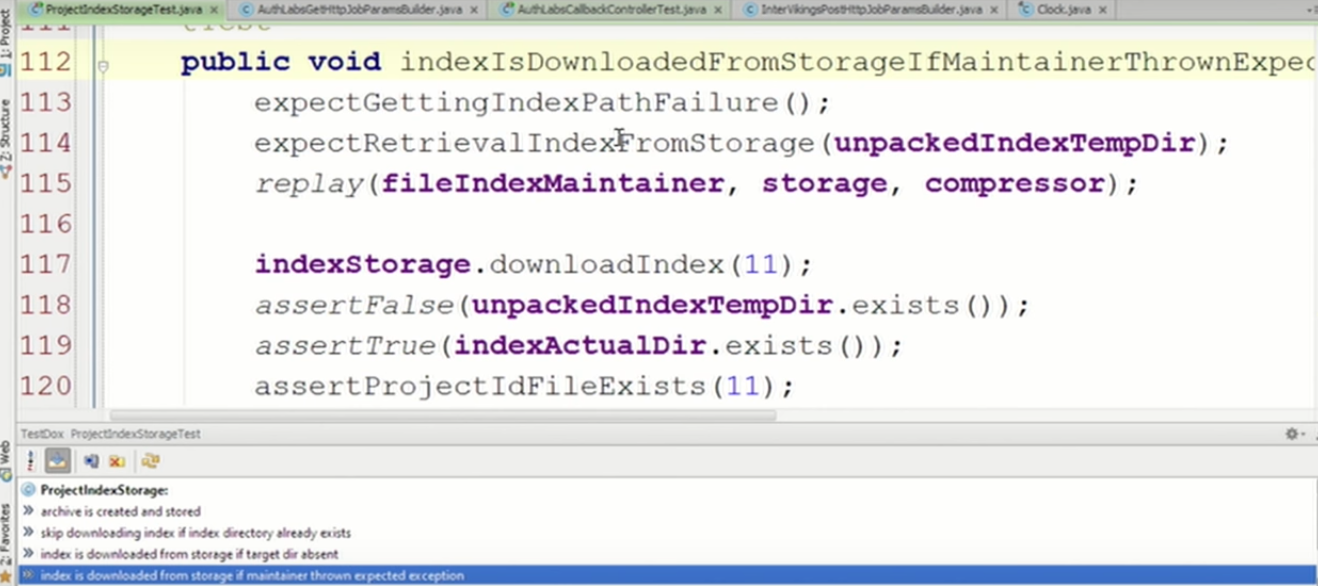
Здесь не надо поднимать всю систему — можно разобраться с одним классом, находясь прямо в тесте. Заметьте, мы сейчас разделяем несколько целей.
- Во-первых — тесты существуют и запускаются. И даже если мы будем писать test_success_1 и т.д., они все равно будут запускаться и решать одну задачу.
- Но, во-вторых, есть еще дополнительная задача — это живая документация. Для этого нужны дополнительные усилия с вашей стороны — правильные наименования. Больше ничего делать не надо.
А как же логирование?
Многие делают супер-логирование юнит-тестов. Зачем? В отчете unit-теста есть все, что надо: если вы его назвали правильно и понимаете, какой кусочек функциональности не работает. Второе, что у вас есть, — это StackTrace. Надеюсь, делать операции со StackTrace умеют все: скопировал StackTrace, зашел в IDEA, сказал Analize StackTrace и увидел, что шло не так. Этого для юнит-теста предостаточно. Дополнительное логирование физически бесполезно. Отладчик по-хорошему тоже не нужен.
Но здесь я отталкиваюсь от идеи, что мы тестируем только бизнес-логику. В этом случае мы имеем одну единственную цель — проверить, что бизнес-логика работает правильно. Не надо в общем случае добавлять туда какую-то вторую цель. Разово (для неожиданных ситуаций) — без проблем. Но я говорю о том, что логирования там не должно быть в обычном режиме.
Конечно, бывают разные ситуации, например, у вас могут быть тесты, которые моргают — и это вполне нормальная штука, поскольку запуск тестов из IDE и консоли (или локальные настройки инфраструктуры) отличаются. В этом случаем вам приходится разбираться. Но я не уверен, что вам поможет именно отладчик. Скорее поможет запуск командной строки, которая запускается на вашем Continuous Integration Server. А лог ничего не даст. Те же тайминги будут автоматически — их даст используемый unit testing framework.
Если тест падает в разном окружении, здесь явно проблема с внешними зависимостями. Всем известно, что юнит-тесты должны быть независимыми. Но некоторые разработчики неявно делают эти зависимости. У них на локальной машине тесты могут проходить, потому что они писали их в определенном порядке, тест за тестом. И локально они их запускают в том порядке, в котором они написаны. А если включить флажок «Запускать в случайном порядке», какой-то тест может то падать, то не падать. Вероятнее всего это означает, что он от чего-то зависит — от какого-то другого теста. Возможно, вы не очистили директорию или переменную. Такое случается, и вы должны это обнаружить тем, что выставляете упомянутый флажок.
Иногда вы сталкиваетесь с тем, что у вас есть Memory Leak в юнит-тестах. Garbage Collector начинает работать все агрессивнее и агрессивнее, и у него иногда случаются паузы. Т.к. мы использовали реактивную модель, то мы ждем на промисах пока вернется результат (допустим, мы поставили таймаут три секунды — для юнит-теста этого более чем достаточно), а он не выполняется. Смотрим Garbage Collector Profile, и оказывается, что там паузы. В итоге локально тесты запускаются, потому что мы, допустим, дали больше памяти, а где-то еще — нет. Такое тоже бывает. С этим нужно разбираться в частном порядке. Но по умолчанию здесь должны быть только правильные хорошие наименования тестов и все, ничего другого вам здесь не нужно.
Надо отметить, что мы тут не тестируем хэш код. Hashcode и equals определяют тогда, когда хотят использовать в коллекциях, которые основываются на Hashcode и equals — hashmap, hashset и прочее. Но если вы не используете нигде Hash-что-то, то может быть вам не нужен хэшкод. Поэтому если мы знаем, что там какое-то решение — мы где-то хотим сэкономить или решили сделать кэширование поля, чтобы оно предвычислялось — тогда мы это тестируем. Но кода подобного рода мы стараемся писать как можно меньше.
О покрытии бизнес-логики и времени на тесты
Обычно в проектах покрытие бизнес-логики в большинстве случаев близко к 100%, т.к. большинство разработчиков пишет по TDD (люди не пишут код, если не могут сформулировать, что он должен делать). Речь идет обо всем коде, за исключением синтетического, геттеров, сеттеров, фреймворков или упомянутых выше интеграторов, т.е. вещей, которые мы не хотим покрывать.
В том проекте, который я сейчас веду, мы стремимся к тому, чтобы покрытие повышать, и на текущий момент оно порядка 60%.
Теперь поговорим про mutation tests. Они используются для того, чтобы проверять, насколько ваши тесты покрывают логику. В двух словах они работают следующим образом: приходят в какой-то if и инвертируют его. И смотрят — тесты продолжают работать или нет. Если тесты все еще «зеленые», значит этот if вы не очень хорошо проверяете. Точно так же они делают с перестановкой других вещей. Например, присвоением какой-то локальной переменной другого значения. Самый популярный инструмент, который используется в Java, — это pit.
В прошлом проекте (код которого я показывал) мы экспериментировали и нашли порядка 3 — 5 тестов, которые были «так себе» (и то, спорно), поэтому мы не включили мутационное тестирование на постоянной основе, т.к. мы к тому моменту разрабатывали уже 5 лет. Если за 5 лет у нас было только 3 таких теста, делать проверку постоянно — слишком большой overhead. Но на некоторых проектах, я вас уверяю, вы найдете много всего интересного. Некоторые тесты вообще ничего не проверяют.
Но покрытие не должно являться целью. Если цель — покрытие, пишите любую белиберду, лишь бы она вызывала методы. Можно не написать ни одного assert, сделать миллион тестов, которые просто вызывают методы с разными параметрами — и у вас будет супер-покрытие. Но в этом нет смысла. Бороться следует не за покрытие, а за тесты, которые дают понимание, что функциональность работает правильно, и периодически ломаются (поскольку когда тест ломается, он показывает свою пользу — за исключением ситуации, когда они ломаются из-за неправильного написания).
Сколько времени это занимает? Здесь я скажу такую вещь, с которой, может быть, не все согласятся: я не хочу считать, сколько это занимает. И причина очень простая: у всех есть какой-то подход к написанию кода. Нельзя подойти к разработчику и сказать: «Ты генеришь качественные решения, но как меняется твоя продуктивность от того, одной или двумя руками ты программируешь? Может мы тебе ползарплаты будем платить, но ты одной рукой тоже неплохо справишься?». Манипулирование временем написания тестов — это попытка вычленить какой-то кусочек из стандартного процесса, по которому вы получаете качественное решение. И она намекает на то, что вы бы хотели от него избавиться («заоптимизировать»).

Тот же самый вопрос можно задать про code review. Сколько занимает code review? Это хороший вопрос в плане оптимизации самого code review (чтобы иметь это как метрику и отслеживать, чтобы code review занимал поменьше), но с иной целью этот вопрос задавать опасно.
Могу сказать сугубо личное ощущение: я пишу тесты гораздо дольше, чем сам код (и здесь мы плавно перетекаем в следующую тему — TDD). Большую часть кода я не пишу, а генерю. Я никогда не пишу public class и еще что-то, конструктор, геттеры, сеттеры и т.п. Уже на протяжении лет 8-ми я никогда с нуля сам руками не создаю метод. Я просто пишу в тесте, как он должен выглядеть, и после этого IDE для меня все генерирует автоматически. Получается, что большую часть времени я пишу тест. Но это не означает, что при отсутствии теста я бы сразу сильно ускорился. Наоборот, я бы замедлился, и low level дизайн бы ухудшился.
Эволюция тестов
Тест является более-менее точечным. Лично я придерживаюсь такого подхода: я знаю, что мы в этот тест стараемся не закладывать сверх-усилий. Если у меня появилась какая-то новая функциональность, которая заставляет модифицировать тест (и менять название), зачастую я оставляю старый, генерю новый, убеждаюсь, что новый работает, и после этого убираю старый. Если надо, я действую старым дедовским способом copy-paste, т.е. copy paste driven development в этом плане мне сильно помогает. Когда пишу новый тест, я пытаюсь сформулировать, как теперь он должен выглядеть. После этого я copy paste внутренность теста и, таким образом, от старого я в принципе могу избавиться.
Это решает проблему изменения названий. С Javadoc все наоборот: он вообще вас никак не затрагивает, вы можете поменять его после окончания работы (но «после» обычно вылетает из головы и никакого желания это делать ни у кого нет).
Тесты можно писать как сразу, так и по мере нарастания кода. Обычно сразу я пишу те тестовые сценарии, которые боюсь забыть.
Почему хорошо писать тестовый сценарий перед кодом? При написании ты начинаешь задумываться об использовании API, о возможных исходах (например, возврате false вместо ожидаемого true в определенных ситуациях). И тогда ты либо записываешь себе, что надо протестировать сценарий с false, либо сразу пишешь сценарий с false — это уже зависит от того, какая память у человека. Некоторые сосредоточены на одном и все, что встречают по пути, потом забывают. Но тогда обидно, что мыслительный процесс прошел зря. Поэтому я предпочитаю, встречая что-то неочевидное (чего изначально не было в памяти), сразу же формулировать это в виде теста.
Но все тесты сразу я не пишу. Почему я этого не делаю? Вот пример: я начинаю какой-то тест писать и мне кажется, что сейчас API хорош. Но не факт, что он таким останется. Не факт, что когда я начну его реализовывать, я не увижу в нем какие-то минусы. И обидно будет, если я все тесты сформулирую в рамках такого же API, а потом буду все менять. Поэтому лучше идти по маленькому кусочку.
Если тесты не актуальны, удаляйте их. Не комментируйте, не делайте skip, просто удаляйте. У вас есть система контроля версий, из которой вы можете легко восстановить их при необходимости. Если боитесь потерять, введите правило: когда вы удаляете какие-то тесты, вы отмечаете это каким-нибудь специальным тегом в комменте в вашей системе контроля версий (например, unit test remove — utr). Все — если помечен utr, там удален тест, и его можно будет легко найти. Но, я думаю, это вам никогда не понадобится.
Внутренности теста — разделение ответственности
Есть несколько типичных вопросов о внутренностях теста, касающихся разделения ответственности в разных вариациях.
Во-первых, вопрос о количестве assert-ов в тесте. Я не согласен с правилом: «Делай всегда один assert». Единственное — assert-ы не должны покрывать сразу несколько сценариев.
Когда мы говорим о юнит-тестах на бизнес-логику, хотелось бы покрыть какой-то конкретный сценарий. Иногда тянет сэкономить и по ходу кучу всего проверить, но это получается больше интеграционный тест. Его проблема в том, что он хрупкий — если изменилась только одна функциональность (не вся, а одна из тех, что вы assert-ите), он будет падать. Поэтому я склоняюсь к правилу, что assert должен быть четко из того бизнес-сценария, который вы тестируете. Но сколько их будет физически (один проверит папку, другой проверит моки, третий — изначальные параметры) — не важно. Как в примере, о котором мы говорили выше:

Некоторые говорят, что так делать нельзя и в конце должна быть строка assert только одна. А здесь 3 assert, но они все взаимосвязаны. Можно было бы соединить их вместе, вложив в них смысл и физически превратив в один, но я этим никогда не занимался — не вижу в этом смысла. На мой взгляд, это уже перфекционизм.
Во-вторых, концепция single responsibility помогает принимать решение о тестировании protected, private и т.п. Когда вы хотите сделать protected-метод? Когда понимаете, что его логика достаточно сложна и вы бы хотели протестировать его независимо. Но когда сложность класса превышает определенный уровень, по хорошему надо дробить на несколько классов и делегировать эту логику кому-то другому (возможно, в этом же пакете и package visible без дополнительных церемоний). И дальше строить отдельные тесты для отдельных классов.
Профит в том, что классы становятся проще и вы поддерживаете понятие single responsibility.
Представьте, что у вас есть класс, в котором есть 5 разных ответственностей. Высока вероятность того, что в него придут люди из разных задачек и будут одновременно работать над его кодом. А если каждый класс отвечает ровно за одну responsibility, вероятность параллельных модификаций (т.е. того, что нужно интегрироваться, решать проблемы) гораздо ниже.
Если логика не делегирована, вы эту боль будете каждый раз переживать в тесте. Когда класс у вас становится супер-сложным, когда у него супер-много зависимостей и вам тяжело в тестах, это явно проблема с дизайном. Это не значит, что вы не можете сейчас, чтобы ускорится, так сделать (протестировать private). Но мы в своем проекте к таким вещам пишем комментарий, что это будет переделано в рамках какой-то технической работы. Но когда у вас есть текущая потребность, ее надо решить прямо сейчас, иначе вы не закончите вашу задачу, понятное дело, можно пойти на это. Но в общем это плохой дизайн. Вы же хотите инкапсулировать и быть свободным во внутренней реализации. Приватные методы, протектед методы — по сути вы можете делать в них все, что угодно — это никого не должно касаться во внешнем мире. Никто не должен писать какие-то правила на поведение ваших внутренних методов. В этом и есть инкапсуляция поведения — то, что вы спрятали конкретную реализацию за собой.
Стоит отметить, что если protected изначально был задуман как часть бизнес-логики, тестировать его надо. Плохой дизайн проявляется, когда вы сделали его protected, чтобы он был виден для ваших тестов. Когда вы private тестируете, каким-то образом вызывая его через reflection и передавая туда параметры, потому что вы уверены, что protected там сделать нельзя, т.к. он сразу станет видимым (и это плохо), но протестировать очень хочется, — тогда у вас есть проблема.
Кстати, сделать package default — тоже не обходной маневр. Когда вы делаете что-то package default, это значит, что любой другой сделает такой же package, только положит туда свой файлик и сделает его public. И все (я так делал миллион раз на чужой API, который был мне нужен).
Вместо заключения о бизнес-логике
Еще один момент, который мы упустили, когда говорили про бизнес-логику — никогда не пытайтесь мокать примитивные служебные классы того же JDK или какие-то утилитные классы. Если у вас есть утилитный метод, проверь строку на blank (пустая / не пустая), но никогда не мокайте. Это как раз тот случай, когда моки вредят, потому что у вас нет сложной логики.
Вообще любой разработчик, который хочет хорошо писать юнит-тесты, должен хоть немного изучить такое понятие, как тест-дизайн и классические техники тест-дизайна. Вы должны понимать, что такое классы эквивалентности, как разбивать ваши тестовые данные на классы эквивалентности.
Есть банальный вопрос, который задают всем тестировщикам на собеседовании: у вас есть логин, приложение; расскажите, какие именно тесты вы напишите, чтобы протестировать логин. Можно же бесконечное количество логинов и паролей сгенерить. А надо остановиться на каком-то конечном наборе.
Так же и у нас: если blank, но какой именно blank? Брать и пустую, и с пробелами, и с табуляциями или еще чем-то? Или сделать какого-то одного представителя этого типа?
Это выбор баланса. Если в любом месте, где у вас проверка на blank, вы будете проверять все комбинации, то у вас будет очень много тестов, которые почти ничего не тестируют. С другой стороны, недостаточно сделать какую-то одну строку (например, какую-нибудь «пробел, табуляция») и объявить представителем blank для всех тестов.
Вы не можете протестировать все. Добиться покрытия всех кейсов, которые только можно описать, практически невозможно. Поэтому вы разбиваете данные на классы эквивалентности и берете по одному из представителей классов.
На этом мы заканчиваем первую часть поста. Вторая часть выйдет завтра и в ней речь пойдет о TDD, BDD, тестировании UI и работы с БД.
В реальности встретиться с Николаем в Москве можно будет на JPoint 2017 (7–8 апреля 2017 года в Москве). В этот раз он представит доклад «Сделаем Hibernate снова быстрым». Зато в дискуссионной зоне на конференции никто не сможет остановить вас от обсуждения тестирования!
И как всегда, на JPoint есть целая куча крутых докладов практически обо всем из мира Java — обзор планируемых докладов представлен на сайте мероприятия.
А если вы из Украины и вам до JPoint не доехать, берите билеты на JEEConf.
