REST в реальном мире и практика гипермедиа
Как правильно построить архитектуру приложения, с учетом специфики REST? Было ли с вами такое, что словом «REST» называют любое HTTP API без разбору — и как донести истинное значение этого термина? Как показать, что преимущества REST проявляются в больших долгосрочных проектах, но для небольшой утилиты лучше взять что-то попроще? Эти и другие животрепещущие вопросы освещает Дилан Битти (Dylan Beattie) в докладе «Real world REST and Hands-On Hypermedia».
Дилан — системный архитектор и разработчик, за жизнь успевший поучаствовать во множестве проектов, от небольших вебсайтов до огромных распределенных систем; от легаси с двадцатилетней историей до самых новейших разработок. Сейчас он работает архитектором в Spotlight и занимается решением сложных задач в современных распределенных системах. Создание правильных, красивых и эффективных HTTP API является частью его работы, и он действительно знает в них толк.
Вы сможете встретиться с Диланом вживую на конференции DotNext Moscow 2017, куда он приедет с новым докладом «Life, liberty and the pursuit of APIness: the secret to happy code». Напоминаем, что вы можете купить билеты по вкусной цене вплоть до 31 октября включительно.
Эту статью можно либо прочитать в текстовой расшифровке (жмите кнопку «читать дальше» ⇩), либо посмотреть полную видеозапись доклада. Все необходимые для понимания изображения, слайды и диаграммы присутствуют как на видео, так и в текстовой расшифровке, так что вы ничего не потеряете.
Комментарии к статье приветствуются и действительно важны — мы постараемся задать ваши лучшие вопросы напрямую Дилану на DotNext 2017 Moscow.
Сегодня мы поговорим об идеологии REST в реальном мире и практическом воплощении гипермедиа.
Но сначала немного обо мне.
Меня зовут Дилан Битти (Dylan Beattie). Лучший способ задать любые вопросы по докладу — найти меня в twitter (@dylanbeattie). У меня есть страница ВКонтакте, но я не говорю по-русски, поэтому в этой социальной сети у меня нет друзей.
На протяжении долгого времени я занимаюсь созданием веб-сайтов. Свою первую веб-страницу я создал еще в 1992 году, когда World Wide Web исполнился один год. Кроме того, я разрабатываю веб-приложения.
На текущий момент я системный архитектор в компании Spotlight в Лондоне, которая работает над различными проектами в сфере киноиндустрии — очень интересное направление.
Мой сайт: dylanbeattie.net. Там я публикую свои заметки об архитектуре программного обеспечения, REST и других подобных вещах. Также хочу упомянуть, что код со всех слайдов есть на GitHub: github.com/dylanbeattie/dotnext/. Вы можете загрузить его оттуда и протестировать самостоятельно.
Но давайте поговорим про REST.
REST — довольно известная концепция. Многие о ней слышали, многие с ней работают. Однако до сих пор много неразберихи в том, что такое REST, почему эта концепция важна и как вы можете использовать ее для решения своих проблем. Сегодня мы рассмотрим ответы на некоторые из этих вопросов. Но прежде всего я попробую сформировать четкое представление о том, какие системы соответствуют REST. Поэтому начнем с начала — обратимся к источнику.

Это Рой Филдинг. Рой изобрел REST и определил, что это такое. Существует много материалов, посвященных ПО и вычислительной технике, где объясняется, как все работает. Используемые слова имеют различный смысл для разных людей. Но REST имеет очень четкое определение, которое мы и обсудим вначале.
Сейчас Рой старший научный сотрудник Adobe. А ранее он работал над Apache. Фактически он является одним из основателей проекта веб-сервера Apache и он же был одним из авторов HTTP — базового протокола, который связывает World Wide Web воедино. В 2000 году Рой опубликовал диссертацию «Архитектурные стили и дизайн сетевых программных архитектур». В этой работе он описывает стили архитектуры масштабируемого программного обеспечения в Сети.
Это самый первый момент, который нужно понять. REST — не фреймворк и не библиотека; его нельзя просто скачать или установить. REST — это набор правил, ограничений и рекомендаций относительно того, как вы должны решать проблемы, с которыми сталкиваетесь в своих приложениях.
Тезисы Роя весьма популярны. Их стоит посмотреть, если вы заинтересованы в том, чтобы обратиться к истокам. В его работе я хочу выделить несколько сентенций.
Первая — связанный набор архитектурных ограничений, получив имя, становится архитектурным стилем. На его взгляд, на этот вопрос повлияла архитектура (в контексте строительства), он много думал, в том числе, и об архитектурных стилях. Здания друг от друга отличает не проект, не дизайн —, а стиль: набор индивидуальных особенностей и ограничений. И REST подобен ему. Это набор шаблонов, которые вы можете применить к своим системам.
Еще я считаю очень важным, что »REST в разработке программного обеспечения существует в масштабе десятилетий. Каждая деталь обеспечивает долговечность и независимую эволюцию программного обеспечения». REST предназначен для создания систем, которые будут работать годами, а может быть, десятилетиями. Если в следующем месяце у вас ожидается окончание финансирования, вероятно, вы не должны создавать систему, соответствующую постулатам REST, потому что многие из представленных в рамках этой концепции ограничений прямо противоположны краткосрочной эффективности.
Часто бывает так, что в проекте, над которым вы работаете, есть два или больше способов решения проблемы. И путь, который ведет к REST, зачастую занимает больше времени. На этом пути вы должны думать о множестве вещей, которые могут не являться проблемой для вас и вашей компании. Так что будьте очень внимательны. Подумайте о том, чего именно вы пытаетесь достичь. Если вам повезло работать над системой, которой предстоит функционировать много лет, в рамках этой статьи вы найдете много идей, которые, надеюсь, будут вам полезны.
Если же вы строите прототип, проводите много экспериментов, чтобы увидеть, будет ли что-то работать, — ситуация неоднозначна. REST не навредит —, но некоторые требования могут вас замедлить.
Определение REST
Рой Филдинг предложил определение REST — это скоординированный набор архитектурных ограничений.
Клиент-сервер
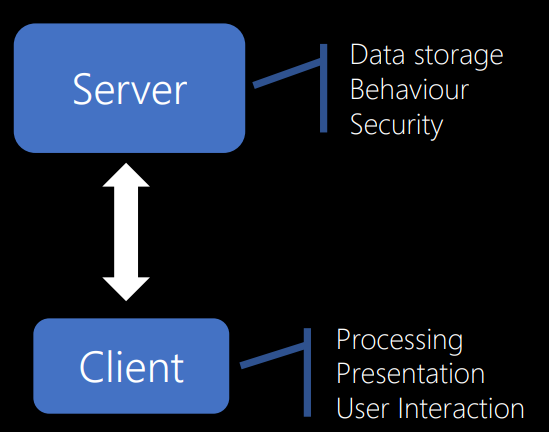
В первую очередь, по его словам, программная система должна быть построена для работы на клиенте и на сервере. Я надеюсь, что это никого не удивляет. Большинство из нас, думаю, уже создавали клиент-серверные приложения — веб-сайты, системы электронной почты, FTP. Сейчас это очень распространено.
Я не буду описывать детали. Ваш сервер как-то делится между клиентами, обеспечивая хранилище данных, основные функции и безопасность, — те вещи, которыми вы хотите управлять централизованно.
Одна из приятных вещей, связанных с клиентами, — каждый из них приходит с компьютера. Поэтому если у вас есть расчеты, которые необходимо выполнить, можно распределить их на большое количество клиентов. Таким образом клиенты обеспечивают обработку данных, представление и взаимодействие с пользователем.
Сервер обслуживает несколько клиентов. И это большое преимущество. Вы можете обслуживать много тысяч пользователей при помощи одного сервера, если, конечно, правильно спроектируете свою систему.
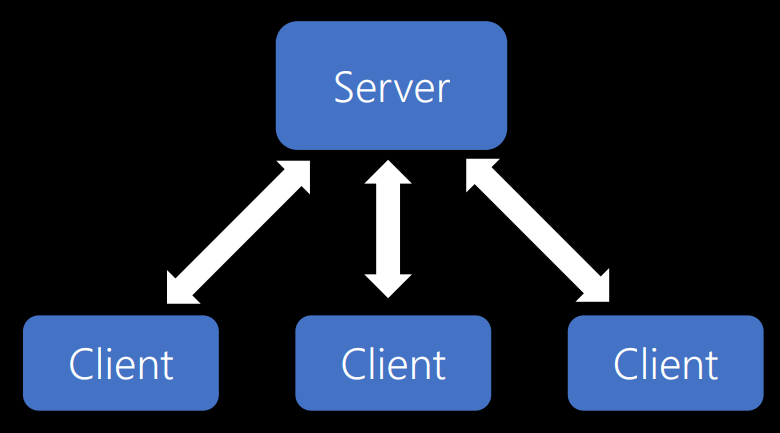
Не храним состояние
Второе ограничение связано с отказом от хранения состояния. В ASP.NET, PHP, ColdFusion или классическом ASP вы сталкиваетесь с идеей сеанса. Таким образом, у вас есть cookie сеанса. Но эта идея больше не работает. Когда у вас было что-то вроде ASP.NET и вы запускали один веб-сервер, он начинал понемногу замедляться. Потом вы устанавливали другой веб-сервер, и в конце концов все переставало работать из-за того, что каждый раз при отправке запроса на сервер выделялось некоторое пространство в хранилище только под этого клиента. Примерно так:
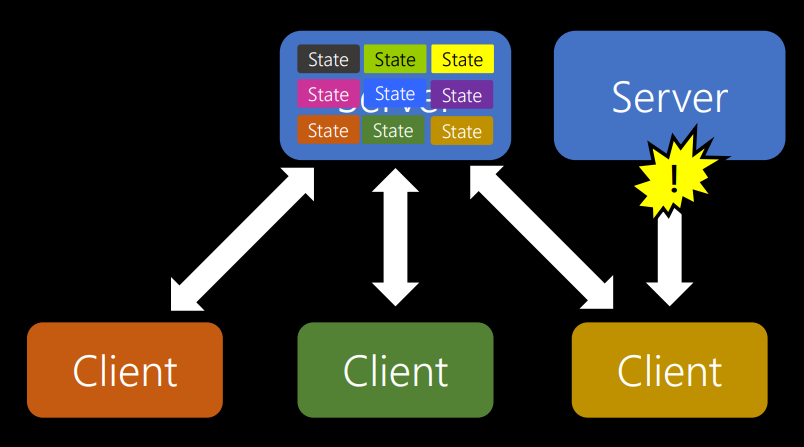
Сервер хранил его состояние. В то же время приходит следующий человек, у которого тоже есть какое-то состояние.
Что происходит, когда сервер заполняется, и тут один из клиентов уходит? Мы не знаем, вернется ли он, поэтому нам приходится хранить состояние в течение какого-то периода времени. Но каков должен быть тайм-аут сеанса? 5 минут, 10 минут, 24 часа? Это очень сложно определить. Но самая большая проблема заключается в том, что если вы запускаете другой сервер, который дает еще больше возможностей, а затем один из клиентов попробует переключиться от одного сервера к другому, соединение прервется, потому что информация о сессии хранится в другом месте.
Поэтому, избегая хранения состояния, вы получаете большую гибкость в отношении того, сколько клиентов вы можете обслуживать и как вы можете масштабировать систему.
Кеширование
Третье ограничение, которое определяет Рой, — это кеширование.
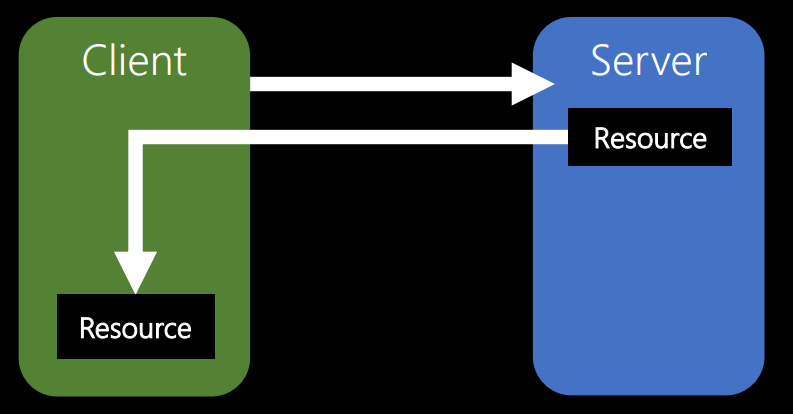
Предположим, на сервере есть некоторый ресурс. Клиент его запрашивает. Если этот же ресурс потребуется клиенту снова, ему не придется заново его запрашивать. Он должен иметь возможность использовать то, что уже есть.
Когда на сервере вы выполняете какую-либо задачу, вы тратите ресурсы. Возможно, вы обрабатываете видео или фотографию. И все, что стоит ресурсов, нужно использовать повторно. Это лучшее, что вы можете сделать. Нужно сохранить результат обработки, чтобы любой, кто когда-либо вернется и вновь попросит те же данные, мог просто получить тот же ресурс.
Многоуровневая система
Следующее ограничение напрямую связано с идеей кэширования. Это идея многоуровневых систем. Мой любимый пример данной идеи — кеширующий прокси-сервер между клиентами и сервером.
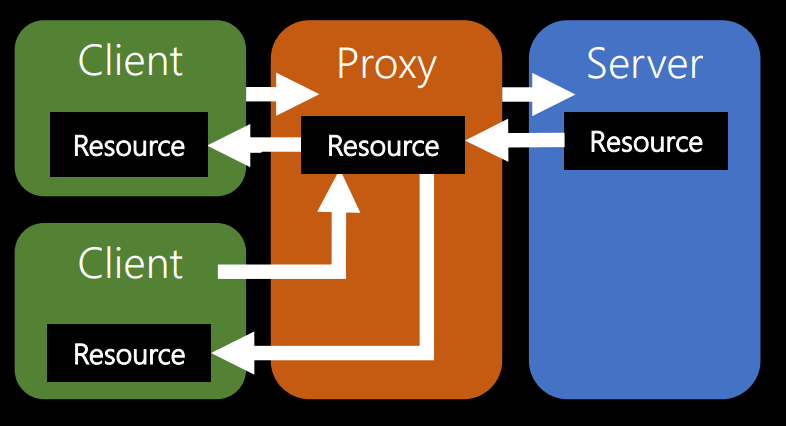
Клиенты на этой схеме слева. Предположим, это различные варианты смартфонов — iPhone, Samsung, Android — все, что угодно. Прокси-сервер — в середине цепочки. Допустим, им управляет некая большая телекоммуникационная компания. Как владелец сервера, вы платите за работу того, что справа от прокси. Ведь когда приходит запрос от клиент, сервер выполняет некоторые расчеты. А это стоит денег — электричества, амортизации оборудования и т.п.
Если телекоммуникационная компания сохранит копию результатов, в следующий раз, когда кто-то запросит информацию, он получит прокси-копию. Вам не нужно будет тратить деньги на исполнение запроса. Таким образом, идея кеширования на прокси невероятно хороша, потому что позволяет другим людям платить за то, чтобы сделать ваше программное обеспечение быстрее без дополнительных вложений.
Еще в рамках идеи многоуровневой системы вы можете добавить больше промежуточных уровней. В многоуровневых системах серверы и клиенты не заботятся о том, через какие уровни проходит запрос.
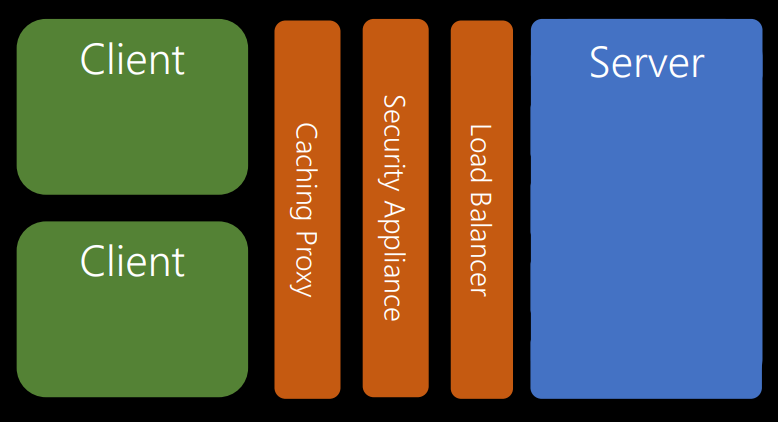
В этом примере клиенты взаимодействуют с прокси-сервером. Прокси считает, что он взаимодействует с сервером, но на самом деле он отправляет запросы на уровень безопасности (например, брандмауэр). Тот, в свою очередь, считает, что общается с сервером, он фактически отправляет запросы на балансировщик нагрузки.
Балансировщик нагрузки считает, что он взаимодействует с сервером, но на самом деле речь идет о пяти серверах. Мы можем разворачивать новые, закрывать старые, и благодаря балансировщику нагрузки другие уровни это не затрагивает.
Концепция многоуровневых систем дает вам огромную гибкость при планировании приложений.
Единый интерфейс
Идентификация ресурсов
До появления HTTP и REST, если вы хотели получить некоторую информацию с сервера, вам предстояло выбрать один из нескольких десятков протоколов — Gopher, FTP, Telnet и т.п. Все это были разные системы, и каждая подразумевала свой способ взаимодействия с удаленной информацией и удаленными службами.
HTTP и REST стандартизировали это. Прежде всего, была стандартизирована идентификация ресурсов — появился URL-адрес (забавно думать, что кто-то придумал URL). Одна часть адреса определяет протокол (HTTP), другая — путь к ресурсу, а третья — порт. Все в интернете, доступное для сетевых запросов, может быть идентифицировано с использованием одного из этих URL-адресов.
Манипуляции с представлениями
Под манипуляциями с представлениями подразумевается то, что вы можете запросить данные в разных форматах. Если вам нужен фрагмент данных, вы можете получить его как таблицу CSV, файл Excel, текстовый документ, jpeg. Это все реальные представления некоторых базовых результатов.
Самоописательные сообщения
Вы должны смочь понять, что происходит в сети. В HTTP есть запросы GET, PUT, POST, DELETE. Они описательны: GET — это английское слово, которое означает, что вы хотите получите что-то. PUT означает положить нечто, DELETE — удалить. Вы можете посмотреть сетевой трафик в некотором инструменте для интеллектуальной отладки и понять, какие запросы отправлялись на самом деле.
Гипермедиа в качестве механизма управления состоянием приложения
Об этомы мы поговорим подробнее.
Кодировка по запросу
Последнее ограничение, которое определил Рой, — это идея создания кода, который будет предоставляться клиентам по требованию. Она подразумевает, что ваш сервер должен иметь возможность отправлять данные, включающие код. Клиент может извлечь этот код, отключиться от сервера и запустить его позже.
Я никогда не видел API, который это делает. Я видел множество веб-приложений: Google Docs Offline, Gmail и множество других одностраничных приложений. Я не поддерживаю идею получения запускаемого кода из чужого API для последующего запуска в моей системе. Но приятно знать, что существует возможность такого запуска операций на клиентах.
Я пришел в отрасль, когда создавались первые веб-браузеры, которые не являлись почтовыми клиентами. Затем кто-то решил, что можно запускать JavaScript, и теперь мы можем создать почтовый клиент в JavaScript и отправить его клиенту так, чтобы он смог запустить его в браузере.
Обязательность ограничений
Важная вещь заключается в том, что Рой Филдинг прямо говорит: существует 6 ограничений, и только одно из них опционально.

Если вы строите систему и решаете возникающие проблемы описанным образом, то система будет RESTful. Если же вы решаете их по-другому — система будет не RESTful. Это не значит, что она хорошая или плохая. Определение выше ничего не говорит о качестве системы. Однако очень важно, чтобы мы договорились о том, что представляет собой RESTful API по определению (в соответствии с первоисточником).
Посмотрим, как указанные ограничения будут выглядеть в реальной жизни, а точнее, в жизни героев из комиксов. Попробуем написать код социальной сети для супергероев в соответствии с REST. Это будет весело.
REST на практике

Здесь изображены действительно интересные персонажи из комиксов (и фильмов по комиксам). Попробуем создать для них социальную сеть. Но мы не хотим увязнуть в разработке пользовательского интерфейса, так же как не хотим тестировать JavaScript. Поэтому давайте просто создадим API.
Вот наша точка входа:
GET / HTTP/1.1в ответ мы получаем:
200 OK
Content-Type: application/json
{
"message": "Welcome to Herobook!"
}Давайте создадим конечную точку, называемую здесь »/ profiles», которая будет иметь два метода:
GET /profiles HTTP/1.1 Метод возвращает массив JavaScript — JSON из профайлов всех супергероев, которые присоединились к социальной сети:
200 OK
Content
-Type: application/json
[
{
"username": "ironman",
"name": "Tony Stark",
}
]
В данный момент мы не беспокоимся о безопасности, этот вопрос за рамками нашей беседы.
Второй метод — POST. Отправляя POST в /profiles, вы даете полезную нагрузку в виде JSON.
POST /profiles HTTP/1.1
{
"username" : "blackwidow"
"name": "Наташа Романова",
}
Ответ — сообщение об успешном создании профиля и его адрес:
201 Created
Location: http://api.herobook.local/profiles/blackwidow
{
"username": "blackwidow",
"name": "Наташа Романова"
}
Разместим описание сервиса и его API где-либо в интернете, чтобы каждый знал, как пользоваться нашей системой:

… и отправляемся на выходные.
Вернувшись в понедельник, мы обнаруживаем, что информация о нашем сервисе разошлась по сети: кто-то положил его на Reddit, перепостил в Твиттере, и у нас набралось два миллиона пользователей. Ничего себе!
GET /profiles HTTP/1.1
200 OK
{
"_links" : { … },
"items" : {
{ "username":"ironman", "name":"Tony Stark" }
{ "username":"blackwidow", "name":"Наташа Романова" },
{ "username":"spidey", "name":"Peter Parker" },
{ /* +2 million users! Wow! */ },
{ "username":"ducky", "name":"Howard the Duck" }
}
]И вдруг звонит телефон. Мы берем трубку, а на другом конце провода кто-то говорит: «Ваш API забил весь наш канал!». А затем еще звонок: «Ваш идиотский API перегружает нашу базу данных».
В чем здесь проблема? Что произошло? Почему все нами недовольны?
Потому что в ответе на запрос мы шлем два миллиона записей. У нас есть только одна конечная точка — /profiles. Единственное, что вы можете сделать с API, — это получить или опубликовать данные. И если вы попробуете это сделать, каждый раз будете получать 2 миллиона записей. Таким образом, каждый раз, когда кто-то пытается использовать наш API, он получает мегабайты данных. Сеть падает, база данных — тоже. Вся система не масштабируется.
Что мы можем с этим сделать? Давайте возьмем конечную точку и разобьем ее:
GET /profiles?page=1 HTTP/1.1
200 OK
{
"_links" : { … },
"items" : [
{ "username":"ironman", "name":"Tony Stark" }
{ "username":"spidey", "name":"Peter Parker" },
{ "username":"blackwidow", "name": "Наташа Романова" },
{ "username":"cap", "name":"Steve Rogers" },
{ "username":"storm", "name":"Ororo Munroe" }
]
}
Далее мы можем запросить страницу 2:
GET /profiles?page=2 HTTP/1.1
200 OK
затем страницу 3:
GET /profiles?page=3 HTTP/1.1
200 OK
и так далее:
GET /profiles?page=4 HTTP/1.1
200 OK
GET /profiles?page=5 HTTP/1.1
204 No Content
Это очень просто, и это работает. Я уверен, что большинство из нас может создать систему, которая делает это. А когда мы получаем «No Content», это значит, что у вас есть все профили системы.
Однако это не REST. И причина в том, что API не использует гипермедиа в качестве двигателя состояния приложения. Когда мы получаем первую страницу, теоретически мы можем перейти оттуда на страницы 2, 3. Но в ответе сервера нет ничего, что говорит нам о такой возможности.
Что мы будем с этим делать?
Прежде чем дать ответ, напомню вам об одной серии книг из детства.

Это книги серии «Выберите свое приключение». Они существовали раньше, чем мы узнали, что такое даже 8-битный компьютер. На первой странице представлена часть истории, а в конце — выбор того, что вы хотите сделать дальше.
В качестве примера я создал специальный текст для нашей ситуации:

Это «Выбери себе приключение» специально для DOTNEXT в Санкт-Петербурге.
«У вас был УДИВИТЕЛЬНЫЙ первый день на DotNext в Санкт-Петербурге. Теперь вы на конференции после вечеринки. Это был напряженный день; может, вам стоит пойти в свою комнату и поспать? Но некоторые люди собираются заказать суши. Или вы можете остаться на вечеринке и посмотреть, как Евгений поет караоке?»
Этот контент — начало истории. А затем у нас есть операции гипермедиа, встроенные в представление результатов:
«Чтобы пойти в свою комнату и поспать, перейдите на стр. 23,
Чтобы съесть суши, перейдите на страницу 41,
Чтобы остаться на вечеринке и посмотреть караоке, перейдите на страницу 52.»
Это гипермедиа. Наш результат содержит аннотацию гипермедиа, описывающую, как мы можем взаимодействовать с системой.
Давайте посмотрим, как это на самом деле выглядит в коде. Мы будем использовать для этого формат hal+json. Это json с дополнительными битами для языка репликации гипермедиа. Причина, по которой я его использую, заключается в том, что этот формат довольно короткий, поэтому его легко разместить на слайдах PowerPoint.
Итак, вместо того, чтобы просто возвращать массив, мы собираемся создать коллекцию элементов. Мы будем возвращать полезную нагрузку (наш контент) внутри коллекции, а также дополнять результаты ссылками на другие места, куда мы можем перейти (доступные переходы состояний, реализованные через гипермедиа).
Введем переменную index — это страница, на которой вы находитесь. Total — общее количество записей в коллекции.
GET /profiles HTTP/1.1
200 OK
Content
-Type: application/hal+json
{
"_links" : {
"self" : { "href" : "http://herobook/profiles?index=0" },
"next" : { "href" : "http://herobook/profiles?index=5" },
"last" : { "href" : "http://herobook/profiles?index=220" }
},
"count" :5,
"index" :0,
"total" : 223,
"items:"
[
{ "username":"ironman", "name":"Tony Stark" }
{ "username":"spidey", "name":"Peter Parker" },
{ "username":"blackwidow", "name":"Ната́ша Романов" },
{ "username":"pepper", "name":"Pepper Potts" },
{ "username":"storm", "name":"Ororo Munroe" }
]
}Давайте посмотрим на код.
Но прежде всего хочу предупредить: вы можете заметить здесь некоторые странные символы. Это C#. Я использую FiraCode (https://github.com/tonsky/FiraCode), который обозначает следующее:

Не волнуйтесь, когда их встретите. Это не забавные маленькие руны, это математические символы. Мне они нравятся. FiraCode — проект с открытым исходным кодом. Вы можете скачать его здесь.
Для демонстрации я буду использовать инструмент, который создал для работы с такими вещами. Его можно найти в моем репозитории GitHub (ссылка в начале статьи).

Это просто инструмент API Explorer, запущенный внутри браузера.
С одной стороны, у вас есть веб-браузеры, которые отлично справляются с просмотром страниц, покупкой вещей на Amazon и Ebay. Все они очень хорошо работают с API. С другой стороны, у нас есть инструменты, такие как Callcommandline, или специальные, вроде Postman. Они хорошо подходят для выполнения одного запроса. Но когда вы хотите перемещаться по системе гипермедиа, их использовать не стоит. Мой инструмент находится где-то между этими двумя крайностями: работает в браузере (все это работает на JavaScript) и понимает гипермедиа.
Мы собираемся использовать наш API. Вводим /profiles и нажимаем go.

В ответ получаем сообщение об успешном выполнении — 200 OK — и два миллиона записей (большое спасибо тому в интернете, кто взял каждого супергероя комиксов и поместил в большую электронную таблицу; мне было достаточно только скопировать и выложить все это для демонстрации).
Давайте посмотрим код, который обеспечил такой ответ.
Web API
Первое демо — это asp.net Web API. Я думаю, что на DotNext большинство людей знакомы с .NET и ASP.NET. И это просто Web API, ничего страшного.
Код выглядит следующим образом:
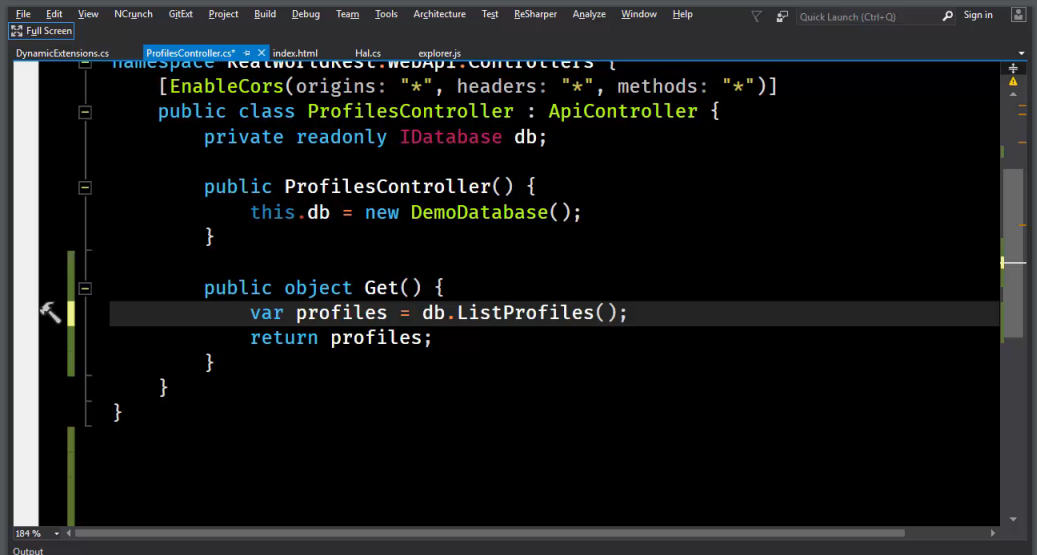
У нас есть ProfilesController (который наследует ApiController). Есть база данных DemoDatabase (), а также публичный объект Get (), который возвращает db.ListProfiles ().
Как мы можем адаптировать этот код, чтобы соответствовать требованию о гипермедиа? Разбить результат на страницы и дать ссылку с одной страницы на другую.
Первое, что нам нужно сделать, — обернуть наш массив во что-то. Мы не можем вернуть просто данные. Одна из вещей в .NET, которая хорошо подойдет для этого, — это возможность создавать анонимные типы. Впоследствии вы можете сериализовать их, чтобы получить практически то же самое, что в них положили. Я думаю, что это действительно мощный инструмент. Анонимные типы решают много задач, если вы попробуете передать их между модулями кода .NET. Но если вы просто делаете веб-сайт, превратите его прямо в Json, сериализируйте его, а затем отбрасьте ненужное.
public object Get() {
var profiles = db.ListProfiles();
var result = new {
items = profiles
};
return result;
}
Вот что у нас получается: 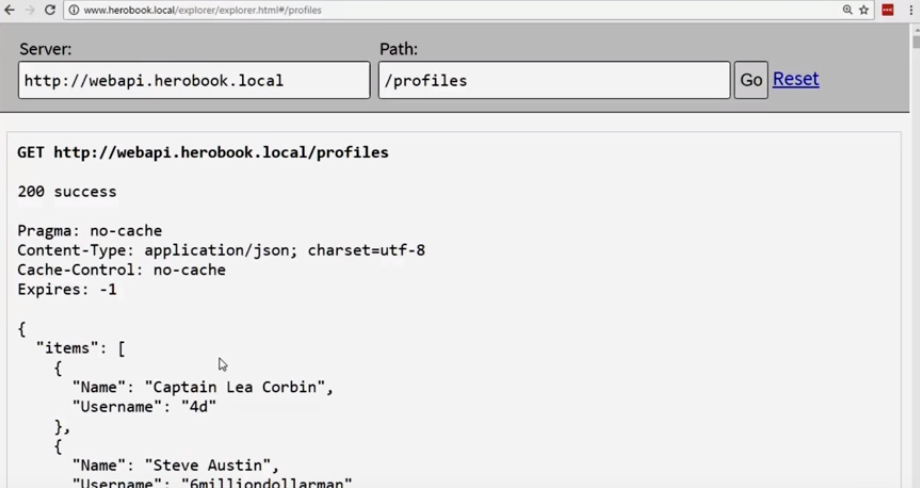
У нас все еще выводятся два миллиона записей, но теперь массив находится внутри JSON-объектов JavaScript. Это означает, что у нас есть место, куда мы можем интегрировать больше функций.
Первое, что мы хотим сделать, — сократить вывод. Просто введем константу, обозначающую количество результатов на странице. Это будет 10. А затем мы переходим к базе данных и говорим:
profiles = db.ListProfiles().Take(REULTS_PER_PAGE)Теперь когда мы обратимся к базе данных, она выдаст нам только 10 профайлов. Вот полный код Get ():
public object Get() {
var RESULTS_PER_PAGE = 10;
var profiles = db.ListProfiles().Take(RESULTS_PER_PAGE)
var result = new {
items = profiles
};
return result;
}Возвращаемся в наш инструмент и обновляем страницу. Вместо 2 миллионов получаем 10 записей (это видно по полосе прокрутки).
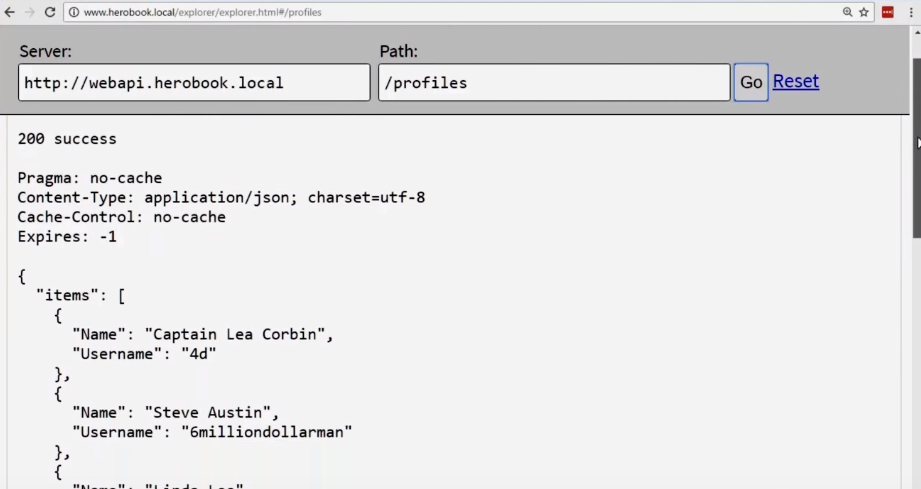
Мы решили проблему. Теперь запрос /profiles больше не приведет к сбою интернет-соединения.
Следующая вещь, которую мы хотим сделать, — ссылки для запроса страницы. Наш API достаточно умен, чтобы выдавать нужную страницу.
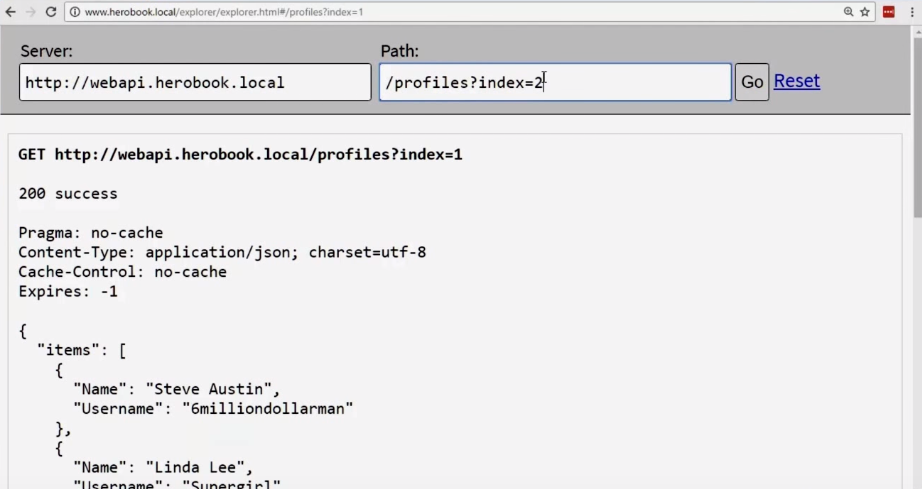
Однако пользователь не знает о такой возможности, поэтому пока эта система не соответствует REST.
Нам необходимо вернуться в код и кое-что поправить.
У нас есть результат, который является анонимным типом. Поэтому мы можем добавить в него все, что нам нравится. В частности, ссылки. Здесь мы будем использовать интерполяцию строк C#:
var result = new {
_links = new {
next = new {
href = $"/profiles?index={index+RESULTS_PER_PAGE}"
}
},
items = profiles
};
return result;Теперь, запрашивая профайлы, мы получаем не только сами данные, но и коллекцию ссылок.
Вернемся к нашему API Explorer. Посмотрим, что произойдет:
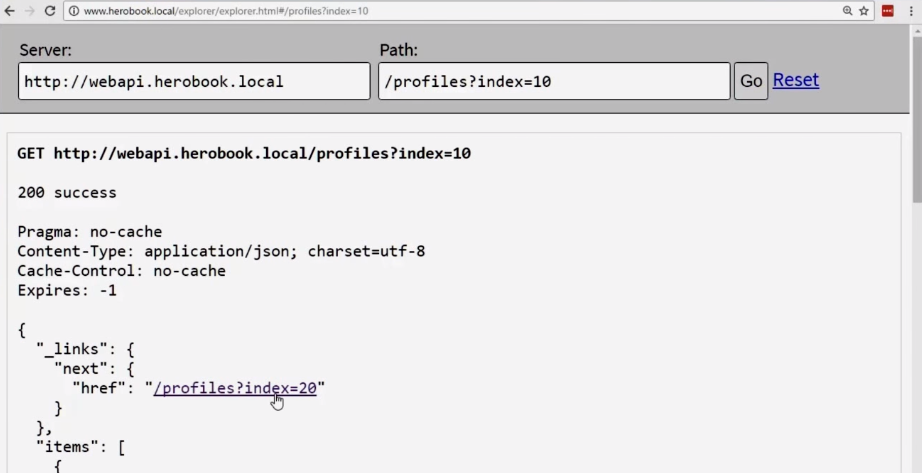
Таким образом мы сделали первые шаги к тому, что называется API с поддержкой гипермедиа.
У нас есть страница 0, и вы можете перемещаться по страницам.
Но с API все еще остались некоторые проблемы. Нам нужна навигация: мы должны иметь возможность двигаться вперед и назад по страницам, а также перемещаться к началу или к концу списка. Пока API этого не поддерживает. Кроме того, когда мы дойдем до конца коллекции, система начнет возвращать нам пустые массивы.
Чтобы API полностью соответствовал концепции REST, нам нужно добавить немного логики для расчета, куда мы можем отправиться с текущей страницы.
Для этого я использую маленький вспомогательный класс.
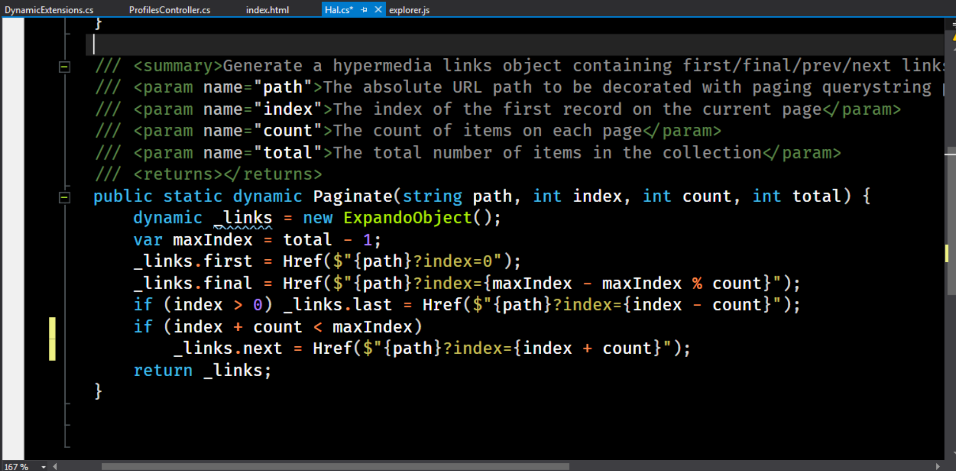
Здесь статический метод возвращает динамический объект. Что он делает? Мы даем ему индекс текущей страницы, количество элементов на каждой странице, а также общее количество элементов, и выполняем некоторые вычисления — получаем номера первой и последней страницы. Первый всегда будет равен нулю, последний — всегда будет содержать профайл с максимальным индексом в коллекции. Далее для индекса больше нуля мы можем вернуться назад. Однако мы не можем вернуться назад, и если index — count меньше минимального индекса; также мы можем идти вперед, но не сможем пройти мимо конца.
Метод возвращает ссылки.
Теперь вернемся в наш код, переписав его следующим образом:
public object Get(index = 0) {
var RESULTS_PER_PAGE = 10;
var profiles = db.ListProfiles()
.Skip(index)
.Take(RESULTS_PER_PAGE);
var total = db.CountProfiles();
var result = new {
_links = Hal.Paginate("/profiles", index, RESULTS_PER_PAGE, total),
items = profiles
};
return result;
}Запустим его:
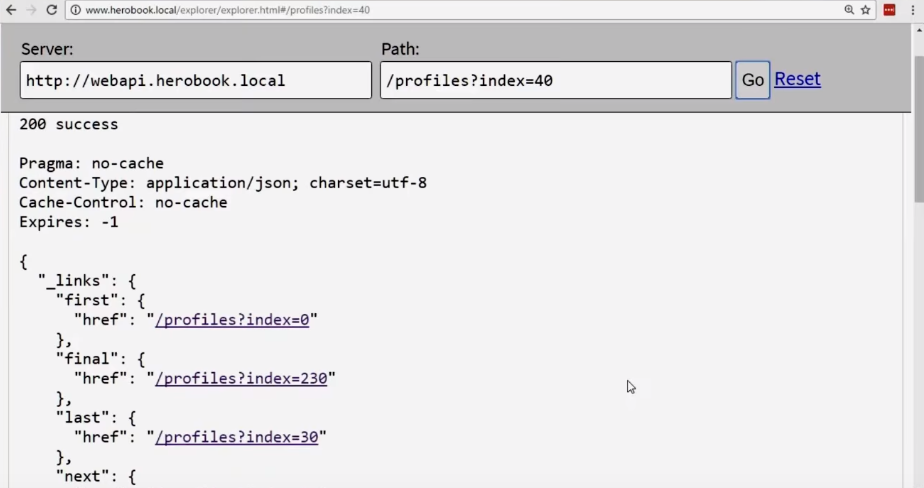
Теперь у нас есть ссылки на первую, последнюю, следующую и предыдущую страницы. Мы можем пойти вперед или назад; доступные для перехода ссылки учитывают, дошли ли вы до первой или последней страницы (с первой страницы нельзя пойти назад, с последней — вперед).
Таким образом, у нас было 2 миллиона записей в социальной сети. Мы разбили данные на отдельные страницы и затем использовали гипермедиа, чтобы любой, кто получает доступ к ресурсу, знал, как он может перемещаться по коллекции.
Развертывание ресурсов
В социальных сетях люди делятся информацией со своими друзьями. Они устанавливают дружеские взаимоотношения, а затем публикуют обновления: «эй посмотрите, что я сделал сегодня утром; посмотрите, где я».
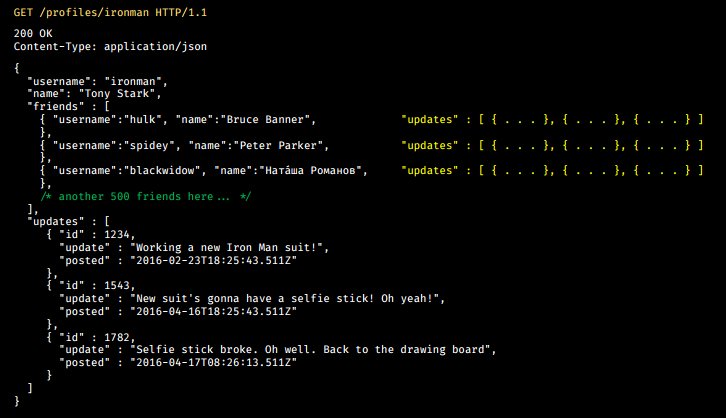
Предположим, у нас в сети есть Железный Человек — Тони Старк. И у него в друзьях Ironman, Spider-Man, Наташа Романова.
Тони обновляет статус.
GET /profiles/ironman HTTP/1.1
200 OK
Content-Type: application/json
{
"username": "ironman",
"name": "Tony Stark",
"friends" : [
{ "username":"ironman", "name":"Tony Stark" },
{ "username":"spidey", "name":"Peter Parker" },
{ "username":"blackwidow", "name":"Ната́ша Романов" },
/* another 500 friends here//. //
]
"updates" : [
{ "id" : 1234,
"update" : "Working a new Iron Man suit!",
"posted" : "2016-02-23T18:25:43.511Z"},
{ "id" : 1543,
"update" : "New suit's gonna have a selfie stick! Oh yeah!",
"posted" : "2016-04-16T18:25:43.511Z"},
{ "id" : 1782,
"update" : "Selfie stick broke. Oh well. Back to the drawing board",
"posted" : "2016-04-17T08:26:13.511Z"}
]
}
Его первое обновление: «Эй, я строю новый костюм Железного Человека», следующее — «Я собираюсь поставить на него палку для селфи, потому что эгоисты потрясающие, о да». И затем он публикует еще одно обновление: «Палка для селфи сломалась. Возвращаюсь к чертежной доске, обратно в мою лабораторию».
Конечно, его друзья тоже имеют профили. Поэтому в каждом из этих обновлений есть перечень друзей, и у каждого из этих друзей есть свои собственные обновления.
Но у друзей есть свои друзья, а у тех — свои обновления и т.п.
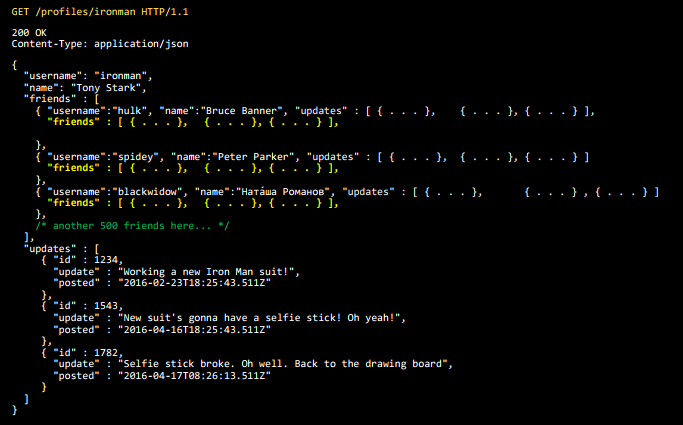
Так мы приходим к тому, что называется Big Data.

Потому что Big Data — это нечто, слишком большое для размещения JSON этих данных на слайде PowerPoint. Пусть это будет моим определением.
Мы реализовали поддержку статусов и их обновлений. И тут звонит телефон: «Ваш API забил весь наш канал… опять!», «Ваш API перегружает базу данных. Опять!… Я говорил, нам нужно было использовать PHP… (ранее в PHP вы никогда не слышали о таких проблемах, правда?)»
Как мы это исправим? Что мы будем делать, чтобы решить эту проблему?
Мы опять разделим наши данные. Вместо того, чтобы возвращать весь связанный с отдельной записью граф, мы предложим ссылки. Мы уже обсуждали, как использовать ссылки для движения вперед / назад. Теперь расширим эту идею.
GET /profiles/ironman HTTP/1.1
200 OK
Content-Type: application/hal+json
{
"_links": {
"self": { "href" "/profiles/ironman" },
"friends": { "href" : "/profiles/ironman/friends" },
"photos": { "href" : "/profiles/ironman/photos" },
"updates": { "href" : "/profiles/ironman/updates" }
},
"username" : "ironman",
"name" : "Tony Stark"
}self — указывает на профайл, который вы смотрите, потому что вы можете уходить от него по разным маршрутам и хотели бы иметь возможность быстро вернуться обратно (это обычная практика для подобных систем). Также вы можете быстро получить доступ к friends, photos и updates — друзьям, фотографиям и обновлениям.
GET /profiles/ironman HTTP/1.1
200 OKили
GET /profiles/ironman/friends HTTP/1.1
200 OK
GET /profiles/ironman/updates HTTP/1.1
200 OK
GET /profiles/ironman/photos HTTP/1.1
200 OK Давайте также попробуем запросить фото:
GET /profiles/ironman/photos/1234 HTTP/1.1
200 OK Кто-то оставил к этой фотографии комментарии:
GET /profiles/ironman/photos/1234/comments HTTP/1.1
200 OK Давайте запросим фото 1345:
GET /profiles/ironman/photos/1345 HTTP/1.1
200 OK
И здесь тоже есть чьи-то комментарии:
GET /profiles/ironman/photos/1345/comments HTTP/1.1
200 OK
GET /profiles/ironman/photos/1456 HTTP/1.1
200 OK
GET /profiles/ironman/photos/1456/comments HTTP/1.1
200 OKИ снова звонит телефон: «Я должен сделать 50 вызовов API, чтобы просто выдать 1 страницу?!!!». «Наш веб-сервер упал из-за того, что IIS-логи заполнили диск C: (у нас никогда не было таких проблем с PHP)» — действительно, это одна из самых распространенных причин падения сервисов.
Что мы будем делать?
Мы взяли большой объем данных, который вызывал проблемы, и мы его разделили. И теперь небольшие данные вызывают уже другие проблемы.
Поможет нам в решении этих проблем так называемое развертывание ресурсов. Если вы знакомы с чем-то вроде ORM, то знаете, что там в процессе загрузки вы можете запросить определенный объект и включить туда еще один объект.
Развертывание ресурсов — аналогичная идея для гипермедиа API. Таким образом мы можем запросить профиль Железного человека и развернуть его обновления.
GET /profiles/ironman?expand=updates HTTP/1.1
200 OK
Content-Type: application/json
{
"_links": {
"self" : { "href": "/profiles/ironman" },
"friends" : { "href": "/profiles/ironman/friends" },
"photos" : { "href": "/profiles/ironman/photos" },
"updates" : { "href": "/profiles/ironman/updates" }
},
"username" : "ironman",
"name" : "Tony Stark"
"_embedded" : {
"updates" : [
{
"update" : "Working a new Iron Man suit – with a built-in selfie stick!",
"posted" : "2016-02-23T18:25:43.511Z"
},
{
"update" : "Selfie stick broke. Oh well. Back to the drawing board",
"posted" : "2016-04-17T08:26:13.511Z"
}
]
}
}Я снова хочу сделать демо-версию кода, показывающую, как реализовать это. Для второго демо мы фактически будем использовать другой сервер — Nancy.

Код, который это делает, — модуль Nancy:
