Рекомендации на основе изображений товаров

В данной статье я хотел бы рассмотреть на практике вариант построения простейшей рекомендательной системы основанной на схожести изображений товаров. Этот материал предназначен для тех, кто хотел бы попробовать применить Deep Learning, а именно свёрточные нейронные сети, в простом, интересном и практически применимом проекте, но не знает с чего начать.
Предыстория
К написанию данного прототипа меня подтолкнул процесс выбора футболок в интернет-магазине. Пролистав 1000 из 11 000 товаров я немного притомился. Очень хотелось получить возможность поискать товары похожие на те, что я уже отобрал. Встроенная рекомендательная система не могла помочь ничем. Было решено запилить свой вариант и посмотреть как он работает на реальных данных.
Парсинг картинок
Для начала был реализован простой парсер картинок из этой категории. Превьюшки разрешением 250×250 были сложены в одну папку с именами вида ItemID.jpg. Получилось около 11 000 картинок.
Извлечение признаков
Для определения схожести изображений нам нужно получить их векторные представления. Для этого возьмём свёрточную нейронную сеть используемую для классификации изображений (VGG-16), уже натренированную на большом датасете (ImageNet), и отрежем от нее последний слой, дающий на выходе вероятности каждого из 1000 классов ImageNet. В итоге у нас получится 4096-мерный вектор для каждого из изображений.
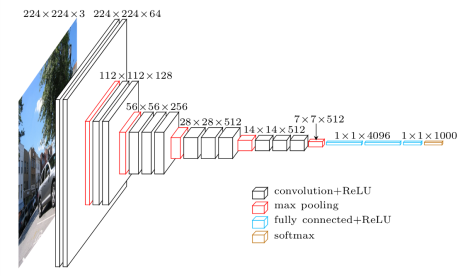
Прототип удобнее всего реализовывать в ipython notebook, очень советую тем, кто ещё не пробовал.
За основу был взят этот код: gist.github.com/baraldilorenzo/07d7802847aaad0a35d3
Подгружаем библиотеки:
%matplotlib inline
from keras.models import Sequential
from keras.layers.core import Flatten, Dense, Dropout
from keras.layers.convolutional import Convolution2D, MaxPooling2D, ZeroPadding2D
from keras.optimizers import SGD
import cv2, numpy as np
import os
import h5py
from matplotlib import pyplot as plt
import theano
theano.config.openmp = True
Загружаем предобученную на ImageNet VGG-16 и удаляем у нее последний слой:
def VGG_16(weights_path=None):
model = Sequential()
model.add(ZeroPadding2D((1,1),input_shape=(3,224,224)))
model.add(Convolution2D(64, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(64, 3, 3, activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(128, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(128, 3, 3, activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(256, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(256, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(256, 3, 3, activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(Flatten())
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096, activation='relu'))
# model.add(Dropout(0.5))
# model.add(Dense(1000, activation='softmax'))
assert os.path.exists(weights_path), 'Model weights not found (see "weights_path" variable in script).'
f = h5py.File(weights_path)
for k in range(f.attrs['nb_layers']):
if k >= len(model.layers):
# we don't look at the last (fully-connected) layers in the savefile
break
g = f['layer_{}'.format(k)]
weights = [g['param_{}'.format(p)] for p in range(g.attrs['nb_params'])]
model.layers[k].set_weights(weights)
f.close()
print('Model loaded.')
return model
model = VGG_16('../../keras/vgg16_weights.h5')
sgd = SGD(lr=0.1, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(optimizer=sgd, loss='categorical_crossentropy')
Загружаем и преобразуем изображения в формат пригодный для нашей нейросети:
path = "../../keras/tshirts/out/"
ims = []
files = []
for f in os.listdir(path):
if (f.endswith(".jpg")) and (os.stat(path+f) > 10000):
try:
files.append(f)
im = cv2.resize(cv2.imread(path+f), (224, 224)).astype(np.float32)
# plt.imshow(im)
# plt.show()
im[:,:,0] -= 103.939
im[:,:,1] -= 116.779
im[:,:,2] -= 123.68
im = im.transpose((2,0,1))
im = np.expand_dims(im, axis=0)
ims.append(im)
except:
print f
images = np.vstack(ims)
Создаем словари для преобразования внешних IDшников к нашим и наоборот:
r1 =[]
r2= []
for i,x in enumerate(files):
r1.append((int(x[:-4]),i))
r2.append((i,int(x[:-4])))
extid_to_intid_dict = dict(r1)
intid_to_extid_dict = dict(r2)
Извлекаем векторные представления из картинок:
out = model.predict(images)
print out
print out.shape
Получается по 4096-мерному вектору для каждой из 11 556 картинок:
[[ 0.00000000e+00 5.96046448e-08 4.35693979e+00 ..., 2.01165676e-07
-2.30967999e-07 5.48017263e+00]
[ -2.98023224e-08 -1.78813934e-07 5.60834265e+00 ..., 2.01165676e-07
7.45058060e-09 9.42541122e+00]
[ 8.94069672e-08 0.00000000e+00 8.79157162e+00 ..., 2.01165676e-07
-2.30967999e-07 8.50830841e+00]
...,
[ 5.17337513e+00 -5.96046448e-08 6.89156103e+00 ..., 2.01165676e-07
7.45058060e-09 1.49011612e-08]
[ 3.18071890e+00 -1.78813934e-07 -5.96046448e-08 ..., 2.01165676e-07
-2.30967999e-07 1.49011612e-08]
[ 8.19161701e+00 5.96046448e-08 9.62305927e+00 ..., -3.72529030e-08
-2.30967999e-07 7.47453260e+00]]
(11556, 4096)
Поиск похожих изображений
Найдем насколько самых близких по косинусному расстоянию изображений:
from sklearn.metrics.pairwise import pairwise_distances
extid = 875317
i = extid_to_intid_dict[extid]
print i
plt.imshow(cv2.imread(path+files[i]))
plt.show()
dist = pairwise_distances(out[i],out, metric='cosine', n_jobs=1)
top = np.argsort(dist[0])[0:7]
for t in top:
print t,dist[0][t]
plt.imshow(cv2.imread(path+files[t]))
plt.show()

Веб-интерфейс для тестов
Тестировать это всё в ipython не очень удобно, поэтому было решено сделать веб-интерфейс на Django.
Сохраняем необходимые данные для использования в веб-интерфейсе:
import joblib
joblib.dump((extid_to_intid_dict,intid_to_extid_dict,out),"../../keras/tshirts/models/wo_1_layer.pkl")
Далее при запуске поднимаем данные в память и при каждом запросе находим по 5 ближайших соседей
Вот результат — imgrec.ddns.net
При запросе без параметра выбирает рандомное изображение. Выдаёт по 5 ближайших изображений для разных метрик расстояния — «cosine», «euclidean», «manhattan»
По-моему, получилось достаточно не плохо.
Интересно то, что нейросеть, обученная классифицировать изображения на ImageNet, умеет «понимать» что изображено на футболке и подбирать схожие по смыслу изображения.
Вот например:
Кошки — imgrec.ddns.net/? itemid=966730
Медведи — imgrec.ddns.net/? itemid=650443
Люди — imgrec.ddns.net/? itemid=847003
Фрукты — imgrec.ddns.net/? itemid=1020961
Похожий стиль — imgrec.ddns.net/? itemid=932401
Схожая текстура — imgrec.ddns.net/? itemid=862294
