Разработка веб-скрапера для извлечения данных с портала открытых данных России data.gov.ru
Инструменты веб-скрапинга (web scraping) разрабатываются для извлечения данных с веб-сайтов. Эти инструменты бывают полезны тем, кто пытается получить данные из Интернета. Веб-скрапинг — это технология, позволяющая получать данные без необходимости открывать множество страниц и заниматься копипастом. Эти инструменты позволяют вручную или автоматически извлекать новые или обновленные данные и сохранять их для последующего использования. Например, с помощью инструментов веб-скрапинга можно извлекать информацию о товарах и ценах из интернет-магазинов.
Возможные сценарии использования инструментов веб-скрапинга:
- Сбор данных для маркетинговых исследований
- Извлечение контактной информации (адреса электронной почты, телефоны и т.д.) с разных сайтов для создания собственных списков поставщиков, производителей или любых других лиц, представляющих интерес.
- Загрузка решений со StackOverflow (или других подобных сайтов с вопросами-ответами) для возможности оффлайн чтения или хранения данных с различных сайтов — тем самым снижается зависимость от доступа в Интернет.
- Поиск работы или вакансий.
- Отслеживание цен на товары в различных магазинах.
Существует большое количество инструментов, позволяющих извлекать данные из веб-сайтов, не написав ни одной строчки кода »10 Web Scraping Tools to Extract Online Data». Инструменты могут быть самостоятельными приложениями, веб-сайтами или плагинами для браузеров. Перед тем, как писать собственный веб-скрапер, стоит изучить существующие инструменты. Как минимум, это полезно с той точки зрения, что многие из них имеют очень даже неплохие видео руководства, в которых объясняется, как все это работает.
Веб скрапер можно написать на Python (Web Scraping с помощью python) или R (Еще примеры использования R для решения практических бизнес-задач).
Я буду писать на C# (хотя, полагаю, что применяемый подход не будет зависеть от языка разработки). Особое внимание я постараюсь уделить тем досадным ошибкам, которые я допустил, поверив, что все будет работать легко и просто.
Зачем я это сделал и как я это использовал, можно прочитать здесь:
- Загрузка данных с сайта открытых данных data.gov.ru
- Анализ наборов данных с портала открытых данных data.gov.ru
- Использование наборов данных с портала открытых данных России data.gov.ru
Итак, я хочу извлечь информацию о наборах данных с портала открытых данных России data.gov.ru и сохранить для последующей обработки в виде простого текстового файла формата csv. Наборы данных выводятся постранично в виде списка, каждый элемент которого содержит краткую информацию о наборе данных.

Чтоб получить более подробную информацию, необходимо перейти по ссылке.
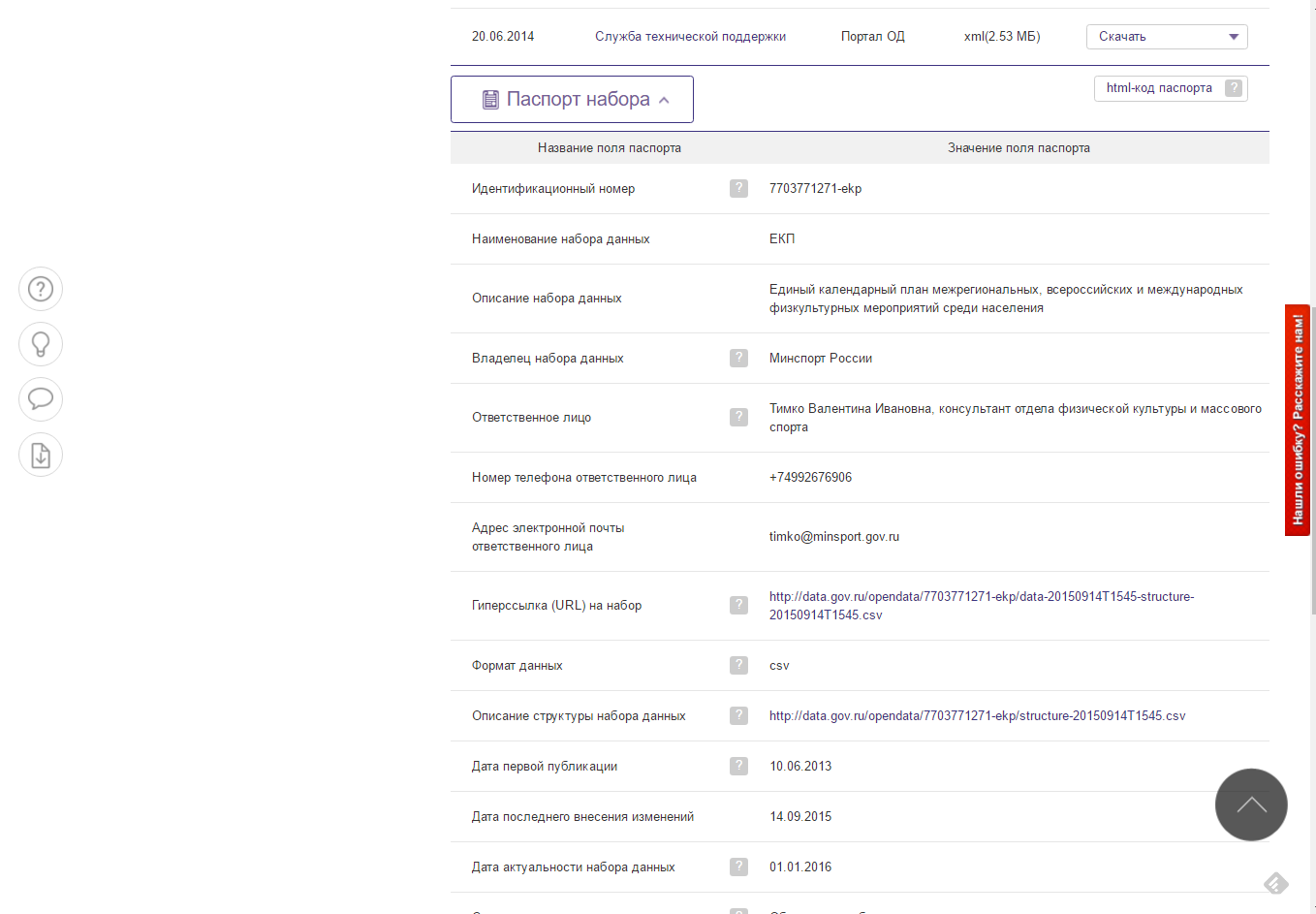
Таким образом, для того, чтобы получить информацию о наборах данных, мне необходимо:
- Пройти по всем страницам, содержащим наборы данных.
- Извлечь краткую информацию о наборе данных и ссылку на страницу с полной информацией.
- Открыть каждую страницу с полной информацией.
- Извлечь из страницы полную информацию.
Чего я делать не буду, так это самостоятельно загружать страницу с помощью HttpClient или WebRequest, самостоятельно парсить страницу.
Я воспользуюсь фреймворком ScrapySharp. ScrapySharp имеет встроенный веб-клиент, который может эмулировать реальный веб-браузер. Также, ScrapySharp позволяет легко парсить Html с помощью CSS селекторов и Linq. Фреймворк является надстройкой над HtmlAgilityPack. В качестве альтернативы можно рассмотреть, например, AngleSharp .
Чтобы начать использовать ScrapySharp, достаточно подключить соответствующий nuget пакет.
Теперь можно воспользоваться встроенным веб-браузером для загрузки страницы
//Создать веб-браузер
ScrapingBrowser browser = new ScrapingBrowser();
//Загрузить веб-страницу
WebPage page = browser.NavigateToPage(new Uri("http://data.gov.ru/opendata/"));Страница вернулась в виде объекта типа WebPage. Страница представляется в виде набора узлов типа HtmlNode. С помощью свойства InnerHtml можно посмотреть Html код элемента, а с помощью InnerText — получить текст внутри элемента.
Собственно, чтобы извлечь необходимую информацию, мне необходимо найти нужный элемент страницы и извлечь из него текст.
Вопрос: как посмотреть код страницы и найти нужный элемент?
Можно просто посмотреть код страницы в браузере. Можно, как рекомендуют в некоторых статьях, использовать такой инструмент, как Fiddler.

Но мне показалось более удобным использовать Инструменты разработчика в Google Chrome.

Для удобства анализа кода страницы я поставил расширение XPath Helper для Chrome. Практически сразу видно, что все элементы списка содержат один и тот же класс CSS .node-dataset. Чтобы в этом убедиться, можно воспользоваться одной из функций консоли для поиска по стилю CSS.

Заданный стиль встречается на странице 30 раз и точно соответствует элементу списка, содержащего краткую информацию о наборе данных.
Получаю с помощью ScrapySharp все элементы списка, содержащие .node-dataset.
var Table1 = page.Html.CssSelect(".node-dataset")и извлекаю все элементы div, в которых лежит текст.
var divs = item.SelectNodes("div")На самом деле, есть множество вариантов извлечения нужных данных. И я действовал по принципу «если что-то работает, то не надо это трогать».
Например, ссылку на расширенную информацию можно получить из атрибута about
Комментарии (4)
4 марта 2017 в 16:14
–2
↑
↓
VisualWebRipper наше все.
 Arepo
Arepo
4 марта 2017 в 18:00
+1
↑
↓
Но ведь на главной странице со списком справа вверху есть «Экспорт реестра», где, в т.ч. можно скачать уже готовый CSV со списком и всей доступной информацией по набору
4 марта 2017 в 18:11
0
↑
↓
Можно. Но ещё вчера там были данные за ноябрь 2016, а xls вообще был пустой
 parserme
parserme
4 марта 2017 в 18:38
+1
↑
↓
Прошло десять лет, и придумали ещё несколько умных слов, чтобы обозвать то, чем я занимался))



