Разбираем и вычисляем формулы MS Excel
Одной из самых интересных задач, с которыми нам пришлось столкнуться в процессе работы над компонентом Spreadsheet, стал механизм вычисления формул. Работая над ним, мы основательно углубились в механику функционирования аналогичного механизма в MS Excel.И сегодня я хочу рассказать вам о принципах его работы, хитростях и подводных камнях. А чтобы не сводиться к сухим пересказам документации, разбавленным дополнениями «из жизни» — я заодно вкратце расскажу, как мы реализовывали подобный механизм.
Итак, в этой статье пойдет речь о трех основных частях классического калькулятора формул — разборе выражения, хранении и вычислении.
Внутреннее представление выражения Выражение в Excel хранится в обратной польской записи, RPN. Выражение в RPN форме представляет из себя простой массив, элементы которого называются ParsedThing.Полный набор ParsedThing состоит из следующих элементов:
Операнды — константы, массивы, ссылки; Константы: ParsedThingNumeric ParsedThingInt ParsedThingString ParsedThingBool ParsedThingMissingArg ParsedThingError Массивы: ParsedThingArray Ссылки: ParsedThingName, ParsedThingNameX ParsedThingArea, ParsedThingAreaErr, ParsedThingArea3d, ParsedThingAreaErr3d, ParsedThingAreaN, ParsedThingArea3dRel ParsedThingRef, ParsedThingRefErr, ParsedThingRef3d, ParsedThingErr3d, ParsedThingRefRel, ParsedThingRef3dRel ParsedThingTable, ParsedThingTableExt Операторы — математические, логические, ссылочные, а так же вызовы функций; Вызовы функций: ParsedThingFunc ParsedThingFuncVar Бинарные операторы: ParsedThingAdd ParsedThingSubtract ParsedThingMultiply ParsedThingDivide ParsedThingPower ParsedThingConcat ParsedThingLess ParsedThingLessEqual ParsedThingEqual ParsedThingGreaterEqual ParsedThingGreater ParsedThingNotEqual ParsedThingIntersect ParsedThingUnion ParsedThingRange Унарные операторы: ParsedThingUnaryPlus ParsedThingUnaryMinus ParsedThingPercent Вспомогательные элементы и атрибуты (для оптимизации скорости вычислений, сохранения пробелов и переводов строк в выражении, т.е. не влияющие на результат вычисления выражения). Вспомогательные: ParsedThingMemArea ParsedThingMemNoMem ParsedThingMemErr ParsedThingMemFunc ParsedThingParentheses Атрибуты: ParsedThingAttrSemi ParsedThingAttrIf ParsedThingAttrChoose ParsedThingAttrGoto ParsedThingAttrSum ParsedThingAttrSpace Приведу пару примеров.»=A1*(1+true)». Во внутреннем представлении будет выглядеть так: {ParsedThingRef (A1), ParsedThingInt (1), ParsedThingBool (true), ParsedThingAdd, ParsedThingMultiply} »=SUM (A1,1,»2»,)». Во внутреннем представлении будет выглядеть так: {ParsedThingRef (A1), ParsedThingInt (1), ParsedThingString (»2»), ParsedThingMissing, ParsedThingFuncVar («SUM», 4 аргумента)} Вычисления Вычисление выражения, записанного в обратной польской записи, выполняется с использованием стековой машины. Хороший пример приведен в википедии.Но в вычислении выражений из Excel не обошлось и без хитростей. Разработчики наделили все операнды свойством «тип значения». Это свойство указывает, как должен быть преобразован операнд перед вычислением оператора или функции. Например, обычные математические операторы не могут выполняться над ссылками, а могут только над простыми значениями (числовыми, логическими и т.д.). Чтобы выражение «A1 + B1: C1» работало корректно, Excel указывает для ссылок A1 и B1: C1, что те должны быть преобразованы к простому значению перед помещением результата вычисления в стек.
Существует три типа операндов:
Reference;
Value;
Array.
Каждый операнд имеет тип «по умолчанию»: Все виды ссылок
Reference
Константы кроме массивов
Value
Массивы
Array
Вызовы функций
Value, Reference, Array
Результат вычисления функции может быть любого типа. Большинство функций возвращают Value, некоторые (например, INDIRECT) -Reference, остальные — Array (MMULT).Конечным пользователям не нужно забивать голову типами данных: Excel сам подбирает нужный тип операнда уже на этапе разбора выражения. А на этапе вычисления не обойтись без «неявного приведения типов». Оно происходит в соответствии со следующей схемой: 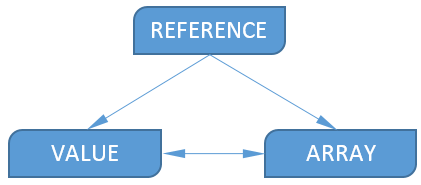 Значение типа Value можно преобразовать к Array, в этом случае создастся массив из одного значения. В обратном направлении (Array→Value) преобразование тоже достаточно простое — из массива берется первый элемент.
Значение типа Value можно преобразовать к Array, в этом случае создастся массив из одного значения. В обратном направлении (Array→Value) преобразование тоже достаточно простое — из массива берется первый элемент.
Как видно из схемы, значение типа Reference невозможно получить из Value или Array. Это вполне логично, из числа, строки и т.п. получить ссылку не получится.
При преобразовании Reference к Array все значения из ячеек, входящих в диапазон, переписываются в массив. В случае когда диапазон комплексный (состоящий из двух или более других диапазонов) — результат преобразования равен ошибке #VALUE!
Интересным образом происходит преобразование Reference к Value. Между собой это правило мы прозвали «Кроссинг». Проще всего объяснить его суть на примере: 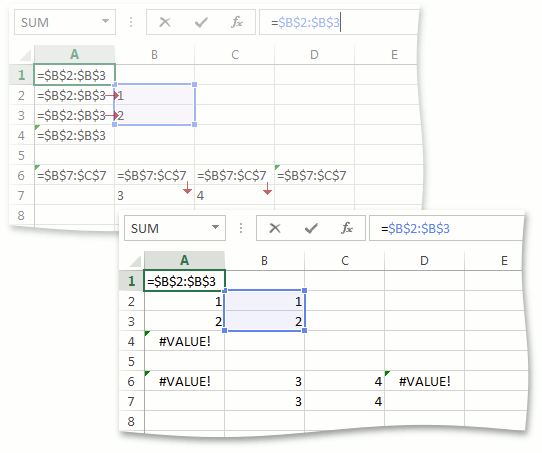
Пусть мы хотим привести к Value значения ячеек с A1 по A4, в которых находится одинаковая формула »=B2: B3», имеющая тип Reference. Диапазон B2: B3 состоит из одной колонки. Если бы это было не так и колонок было бы больше, преобразование Reference к Value для всех ячеек с A1 по A4 вернуло бы #VALUE! и на этом бы завершилось. Ячейки A2 и A3 находятся в строках, пересекающихся с диапазоном B2: B3. Преобразование Reference→Value для этих ячеек вернет соответствующее значение из диапазона B2: B3, т.е. преобразование для A2 вернет 1, а для A3 вернет 2. Для остальных ячеек, таких как A1 и A4, преобразование вернет #VALUE!
Точно таким же поведение будет и для диапазона B7: C7, состоящего из одной строки. Для ячеек B6 и C6 преобразование вернет значения 3 и 4 соответственно, а для A6 и — D6 #VALUE! Аналогично, если бы строк в диапазоне было больше, преобразование вернуло бы #VALUE! для всех ячеек с A6 по D6
Существует несколько правил преобразования типов.
Значения всех формул, находящихся внутри ячеек, всегда приводятся к типу Value.
Например:
»=123» В этой формуле задана константа, она уже типа Value. Ничего преобразовывать не надо. »={1,2,3}» Тут задан массив. Преобразование к Value по правилу дает нам первый элемент массива — 1. Он и будет результатом вычисления выражения. Формула »=A1: B1» находящаяся в ячейке B2. Операнд-ссылка на диапазон по умолчанию имеет тип Reference. При вычислении он будет приведен к Value по правилу «кроссинг». Результатом в данном случае будет значение из ячейки B1. Математические, логические и текстовые операторы не могут работать со ссылками. Поэтому аргументы для них подготавливаются и приводятся либо к Value либо к Array. Второй вариант при этом возможен только внутри Array формул. Например, при вычислении выражения »=B1: B2+A3: B3», записанного в ячейку A1, оба аргумента математического оператора сложения сначала будут приведены к типу Value по правилу «Кроссинг», а затем результаты будут сложены. Т.е. значение будет равно сумме значений ячеек B1 и A3.Операторы ссылки не могут работать ни с каким другим типом, кроме Reference. К примеру, формула »=A1: «test» будет неправильной, ввод такой формулы приведет к ошибке — Excel просто не даст такую формулу записать в ячейку.
Выражения внутри «имен» и некоторых других конструкций приводятся к типу «по умолчанию». В отличие от формул внутри ячеек, выражения в которых приводятся к типу Value. Выражение внутри некоторого «имени» name »=A1: B1» в результате вычисления будет равно диапазону A1: B1. Это же выражение в ячейке будет вычисляться и в результате будет либо одно значение, либо ошибка #VALUE! Но выражение в ячейке »=name» уже будет иметь тип Value и будет вычисляться в зависимости от текущей ячейки.
Парсер Написав на коленке первый вариант парсера мы поняли, что монстр слишком велик и слабо поддается модернизации. А она в нашем случае была неизбежна, поскольку большое количество тонкостей мы познавали уже когда парсер худо-бедно работал. Для интереса решил попробовать другие методы и вооружился для этого генератором трансляторов Coco/R. Выбор на него в тот момент пал в основном из-за того, что я был с ним уже неплохо знаком. Coco/R оправдал мои надежды. Сгенеренный им парсер показал весьма неплохие результаты по скорости работы, поэтому решили остановиться на этом варианте.Конечно, в рамках этой статьи я не стану останавливаться на описании возможностей и пересказе документации Coco/R. Благо, что документация написана на мой взгляд весьма понятно. Кроме этого рекомендую почитать статью на хабре.
Собираем Coco/R из исходников В некоторых местах Coco/R генерирует не CLS-compliant код.Проблема в публичных константах, имя которых начинается со знака подчеркивания. Правильный выход из ситуации только один — поправить Coco/R, благо полный исходный код его доступен на сайте разработчиков.
Покопавшись в исходниках нашел три места, где создаются публичные константы. Все они в файле ParserGen.cs. Например:
void GenTokens () { foreach (Symbol sym in tab.terminals) { if (Char.IsLetter (sym.name[0])) gen.WriteLine (»\tpublic const int _{0} = {1};», sym.name, sym.n); } } Далее, получившийся код продолжает быть невалидным, теперь уже по мнению FxCop. В нашей компании сборки постоянно тестируются на соответствие большому числу правил. Конечно, поскольку код сгенерирован, можно было бы сделать для него исключение и подавить проверку сгенерированных классов. Но это не лучший выход. К счастью, проблема только одна — публичные поля не соответствуют правилу Microsoft.Design: CA1051. Чтобы все исправить достаточно внести необходимые правки в файлы Parser.frame и Scanner.frame, которые располагаются рядом с файлом грамматики. То есть, сам Coco/R пересобирать не надо. Вот примеры:
public Scanner scanner; public Errors errors; public Token t; // last recognized token public Token la; // lookahead token Некоторые из этих полей вообще не используются за пределами класса — их просто делаем приватными, остальным — создаем публичные свойства.При разработке грамматики для Coco/R я пользовался плагином для студии.
Его плюшки Подсветка синтаксиса для файла с грамматикой; Автоматический запуск генератора при сохранении файла с грамматикой; Intellisense для ключевых слов; Показывает ошибки компиляции, возникающие в файле парсера в соответствующем месте в файле с грамматикой Последняя фича была бы весьма удобна, но, к сожалению, у меня она работала некорректно — показывала ошибки не там где надо.
Плагин тоже пришлось научить генерировать CLS compliant код. Скачиваем исходный код плагина, и повторяем те же операции, что и с самим Coco/R.
Модернизируем сканер и парсер Напомню, что для разбора выражения Coco/R создает пару классов — Parser и Scanner. Оба они создаются заново для каждого нового выражения. Поскольку в нашем случае выражений много, то пересоздание сканера может занять дополнительное время на большом количестве вызовов. В целом, нам достаточно одного комплекта парсер-сканер. Первая модернизация коснулась именно этого.Вторая модернизация коснулась вспомогательного класса Buffer, который создается сканером для чтения входящего потока символов. «Из коробки» Coco/R содержит пару реализаций Buffer и UTF8Buffer. Оба они работают с потоком. Нам же поток не нужен: достаточно работы со строкой. Для этого создадим третью реализацию StringBuffer, попутно выделив интерфейс IBuffer:
public interface IBuffer { string GetString (int beg, int end); int Peek (); int Pos { get; set; } int Read (); } Сама реализация StringBuffer простая: public class StringBuffer: IBuffer { int stringLen; int bufPos; string str; public StringBuffer (string str) { stringLen = str.Length; this.str = str; if (stringLen > 0) Pos = 0; else bufPos = 0; } public int Read () { if (bufPos < stringLen) return str[bufPos++]; else return StreamBuffer.EOF; } public int Peek() { int curPos = Pos; int ch = Read(); Pos = curPos; return ch; } public string GetString(int beg, int end) { return str.Substring(beg, end - beg); } public int Pos { get { return bufPos; } set { if (value < 0 || value > stringLen) throw new FatalError («buffer out of bounds access, position:» + value); bufPos = value; } } } Тестируем На всякий случай проверяем, что создали дополнительный класс не зря. Запускаем тестирование трех сценариев для строки длиной N: инициализация из строки; чтение символа (вызов метода IBuffer.Read () N раз) ; получение 10 символов из строки (вызов IBuffer.GetString (i-10, i) (N-10) раз). При N = 100: Init x 100000: Buffer: 171 мсStringBuffer: 2 мсRead xNx10000: Buffer: 14 мсStringBuffer: 8 мсGetString x (N-10) x 10000: Buffer: 250 мсStringBuffer: 20 мс
Разработка грамматики Грамматика для Coco/R описывается в РБНФ (EBNF). Разработка грамматики для Coco/R сводится к построению РБНФ и оформлению ее в соответсвии с грамматикой Coco/R в файле с расширением atg.Парсер строится на основе рекурсивного спуска, грамматика должна удовлетворять LL (k). Сканер основывается на детерминированном конечном автомате.
Итак, приступим. Первым в файле грамматики идет название будущего компилятора:
COMPILER FormulaParserGrammar Далее должна следовать спецификация сканера. Сканер будет case-insensitive, указываем это при помощи ключевого слова IGNORECASE. Теперь надо определиться с символами. Нам надо отделить цифры, буквы, управляющие символы. Получилось следующее: CHARACTERS digit = »0123456789». chars = »~!@#$%^&*()_-+={[]}|\\:;\»',./? <> ». eol = '\r'. blank = ' '. letter = ANY — digit — chars — eol — blank + '_'. Coco/R позволяет не только складывать множества символов, но и вычитать. Так, в описании letter применено ключевое слово ANY, которое подставляет все множество символов, из которого вычитаются определенные выше другие множества.Важной задачей сканера является идентификация токенов во входной последовательности. Во время работы над парсером набор токенов постоянно менялся и в итоге выглядит так:
TOKENS ident = letter {letter | digit | '.'}. wideident = letter {letter | digit} ('?'|'\\') {letter | digit | '?'|'\\'}. positiveinumber = digit {digit}. fnumber = ».» digit {digit} [(«e» | «E») [»+» | »-»] digit {digit}] | digit {digit} ( ».» digit {digit} [(«e» | «E») [»+» | »-»] digit {digit} ] | («e» | «E») [»+» | »-»] digit {digit} ). space = blank. quotedOpenBracket = »'[». quotedSymbol = »''» | »']» | »'@» | »'#». pathPart = »:\\». trueConstant = «TRUE». falseConstant = «FALSE». Обратите внимание, что идентификатор может содержать одну или несколько символов «точка». Таким, например, может быть имя листа в ссылке на диапазон. Так же необходим дополнительный, расширенный, идентификатор. Он отличается от обычного наличием знака вопроса или бекслеша. Отмечу, что в Excel понятие идентификатора достаточно сложное и его трудно описать в грамматике. Вместо этого все строчки, идентифированные сканером как ident и wideident, проверяю уже в коде на соответствие следующим правилам:
Может содержать только буквы, цифры, и символы: _,.,\,?; Не может быть равен TRUE или FALSE; Первый символ может быть только буквой, знаком подчеркивания, или бекслешем; Если первый символ строки — бекслеш, то второго символа может не быть, либо это должен быть один из: _,.,\,?; Не должен быть схож с названием диапазона (например, A10); Не должен начинаться на строку, которая может быть воспринята как ссылка в формате R1C1. Природа этого условия сложнообъяснима, приведу только несколько примеров идентификаторов, которые ему не удовлетворяют: «R1_test», «R1test», «RC1test», «R», «C». При этом «RCtest» — вполне подходит. Выделение quotedOpenBracket, quotedSymbol и pathPart в отельный токен — не более чем хитрость. Она позволила пропустить символы в именах колонок в табличной ссылке, перед которыми должен следовать апостроф. Например, в выражении »=Table1[Column'[1']]» имя колонки начинается после символа »[» и продолжается до символа »]». При этом первый такой символ вместе с предшествующим ему апострофом будет прочитан сканером как терминал quotedSymbol (»]) и, тем самым, чтение имени колонки на нем не остановится.
Наконец, укажем сканеру, чтобы он пропускал переводы строк и табуляции.IGNORE eol + '\n' + '\t'. Сами выражения могут быть написаны в несколько строк, но на грамматику это не влияет.
Мы подошли к основному разделу PRODUCTIONS. В нем необходимо описать все нетерминалы. В примерах дальше я буду приводить упрощенный код, большинство семантических вставок вырезаю, т.к. они внесут сложности в понимание грамматики. Оставлю лишь места построения самого выражения, без оптимизаций.
По всем нетерминалам (из которых Coco/R сделает методы) будет передаваться ссылка на выражение в RPN форме, а так же тип данных, к которому надо его привести. При вызове парсера для формулы внутри ячейки начальный тип данных — Value. Далее во время разбора он будет меняться, и в ветви дерева разбора будет передаваться подготовленный тип. К примеру, при разборе выражения »=OFFSET (A1: B1, A1, A2)» элемент польской записи — функция OFFSET — получит тип Value, при разборе же аргументов первый будет приводиться к Reference, другие два к Value. Для всех функциий мы храним информацию, какие аргументы и каких типов должны в нее передаваться.
Задачей парсера также является проверка формулы на правильность. Формулу будем считать некорректной, если Excel не дает записать ее в ячейку. Кроме синтаксических ошибок формулу некорректной могут сделать и неправильное количество аргументов, переданное в функцию или же несовпадение типа данных запрошенному. Например, функция ROW либо вообще не нуждается в параметрах либо только в одном, и он должен быть исключительно Reference. Мы уже говорили, что к Reference невозможно привести ни один другой тип, а это значит, что выражения »=ROW (1)»,»=ROW («A1»)» будут невалидными.
Т.к. наша грамматика является усложненной грамматикой для обычных математических выражений, строится она так же в зависимости от старшинства операций. Первым следуют логические выражения, последним — операторы работы с диапазонами. Т.е. в порядке увеличения приоритета.
Для визуализации РБНФ использую небольшую программку EBNF Visualizer. Вот так будет выглядеть первый нетерминал в нашей грамматике — логическое выражение:
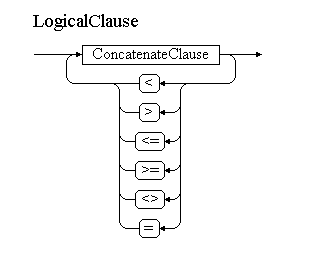
Далее грамматика для Coco/R. В семантических вставках, оформленных между »(.» и ».)» я добавлю нужный ParsedThing к выражению.
LogicalClause
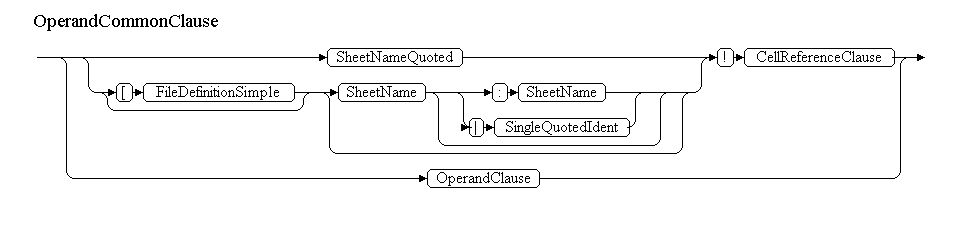
Однако, в приведенной грамматике есть неоднозначность. Она заключается в том, что SheetName и OperandClause могут начинаться с одного и того же терминала — с идентификатора. Например, может следовать выражение »=Sheet! A1», а может »=name». Тут «Sheet» и «name» — идентификаторы. К счастью, Coco/R позволяет разрешать конфликты, просматривая входящий поток сканером на несколько терминалов вперед. Т.е. мы можем просмотреть в поисках символа »!», если таковой будет найден — то мы разбираем SheetName, иначе — OperandClause. Вот так будет выглядеть грамматика:
OperandCommonClause
Нетерминал SheetName может начинаться с цифры или состоять только из цифр. В этом случае, имя листа должно быть заключено в апострофы. В противном случае, Excel добавляет недостающие апрострофы.
SheetName
SheetName
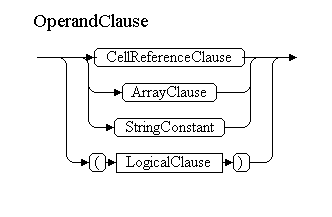
OperandClause
CellReferenceClause
Парсинг неполных выражений и «предсказания»
Рассмотрим задачу подсветки диапазонов, участвующих в формуле.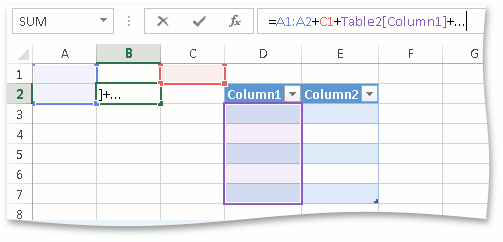
Проблемой здесь является то, что выражение может быть невалидное, а подсвечивать диапазоны надо все равно. На тот момент парсер, не осилив выражение, возврашал всегда null. Конечно, можно было бы попробовать разобраться в частично прочитанном выражении и собрать ссылки с него, но как узнать на каких местах в выражении стоит конкретная ссылка? Поэтому решили научить парсер сразу по ходу чтения складывать все интересное по местам. Так, все ссылки по типам оказались в специально предназначенных коллекциях. Парсер при обнаружении, например, ссылки на диапазон вызывает соответствующий метод
void RegisterCellRange (CellRange range, int sheetDefinitionIndex, int position, int length) После чтения, вне зависимости удачно оно завершилось или нет, у нас есть набор ссылок.
На этом же стал основываться еще один механизм — предсказания. В выражении »=1*(1+2» нарушен баланс скобок, но, с большой вероятностью, пользователь забыл поставить скобку именно в конце выражения. То есть можно попробовать исправить эту формулу, дописав к ней недостающую скобку. Конечно, парсер сам этим заниматься не будет, он только скажет где и чего по его мнению не хватает. Так, например, в уже знаком нам OperandClause появилась следующие строки:
'('
CommonCellReference
Оптимизация производительности вычислений Excel, еще на этапе разбора выражения, старается облегчить себе дальнейшую жизнь. Для этого он, по возможности, наполняет выражения всяческими вспомогательными элементами. Давайте рассмотрим их.Атрибут AttrSemi. Этот атрибут добавляется первым элементом в те выражения, которые содержат volatile-функции.
Класс атрибутов Mem. Сюда входят сразу несколько атрибутов. Их объединяет то, что они созданы для оптимизации вычисления ссылок. По сути, они являются оберткой над некоторым выражением. Во время вычисления внутреннее выражение может и не вычисляться, за него результат выдаст Mem. Отличительной особенностью этих элементов является то, что они вставляются в обратной польской записи до выражения, которое оптимизируют.
ParsedThingMemFunc — указывает на то, что выражение внутри должно вычисляться каждый раз и не результат не может быть закеширован. Например, все выражение =INDIRECT («A1»): B1 будет обернуто в MemFunc, т.к. функция INDIRECT является volatile функцией и при следующем расчете может вернуть уже другое значение. ParsedThingMemArea. Заключает в себе выражение, значение которого уже посчитано и не будет меняться. Это значение сохранится внутри атрибута и при следующем расчете в стек будет добавлено именно оно, а внутреннее выражение вычисляться вообще не будет. ParsedThingMemErr. Заключает в себе выражение, значение которого посчитано, не будет меняться и равно ошибке. ParsedThingMemNoMem. При вычислении выражения внутри Excel столкнулся с нехваткой памяти. На практике я такое ни разу не встречал. Атрибут AttrSum применяется в качестве упрощенной формы записи функции SUM в том случае, когда в функцию передан только один аргумент.
Атрибут AttrIf применяется совместно с одним или двумя операторами Goto для оптимизации вычисления функции IF. Напомню синтаксис функции IF: IF (условие, значение_истина, [значение_ложь]). Из двух значений можно вычислить только одно и сэкономить время на вычислении другого, если сразу после вычисления условия перейти к нужному значению. Тем самым, простое выражение =IF (condition, «v_true», «v_false») Excel густо разбавляет атрибутами. Получается примерно следующее:

Вычисление идет так. Значение condition помещается в стек. Следующим на очереди идет атрибут IF. Он смотрит на значение на вершине стека. Если оно истинно — ничего не делает. Если ложно, прибавляет текущий счетчик элементов в выражении на записанное внутри смещение, тем самым счетчик начинает указывать на «v_false». Следующим рассчитывается либо «v_true», либо «v_false» и результат помещается в стек. Далее идет Goto, первый или второй. Но оба они ссылаются на конец выражения (либо на следующие операторы в выражении, если таковые имеются).
AttrChoose работает очень похожим образом. Напомню, функция CHOOSE выбирает из аргументов один, порядковый номер которого указан в первом аргументе.Тем самым на дальнейший результат расчета влияет только один аргумент, все остальные можно пропустить. В AttrChoose хранится набор смешений, каждое из которых указывает на начало каждого следующего аргумента. После аргумента следует уже знакомый AttrGoto, который указывает на конец выражения или следующий за функцией CHOOSE элемент.
Атрибут Space используется для сохранения формата введенного пользователем выражения, а именно переводов строк и пробелов. Каждый такой атрибут кроме количества имеет тип. Типов всего шесть:
SpaceBeforeBaseExpression, CarriageReturnBeforeBaseExpression, SpaceBeforeOpenParentheses, CarriageReturnBeforeOpenParentheses, SpaceBeforeCloseParentheses, CarriageReturnBeforeCloseParentheses, SpaceBeforeExpression; Взглянув на эти типы можно догадаться, что Excel не умеет сохранять пробелы в конце строки и перед знаком '='. Кроме этого пробелы внутри структурированных ссылок и массивов так же сохранены не будут.
Тестирование Когда наш контрол только-только научился читать и писать файлы в формате OpenXML, мы поспешили проверить его в деле. И самый лучший для этого способ — найти много- много файлов и попробовать погонять чтение и запись этих файлов. Так мы накачали около 10к случайных OpenXML файлов и написали несложную программку. Создали для нее задачу на тестовой ферме. Каждую ночь задача автоматически запускается и читает-пишет файлы. При возникновении каких либо ошибок вся необходимая информация записывается в лог. Так мы смогли отладить огромное количество ошибок.По мере развития контрола добавлялись как поддерживаемые форматы, так и фичи. Так сейчас постоянно тестируются 20к xls файлов и 15к csv файлов. И тестируются не только на чтение-запись, но и проверяются сторонними утилитами, которые также нам очень помогают.
Огромное количество знаний о работе формул в Excel мы получили, когда запустили задачу на тестирование вычислений формул из тех же 10к OpenXML и 20к xls файлов. Файл открывается, записывается в модель данных. Затем поочередно мы начинаем помечать ячейки на листе как не посчитанные, вычисляем и сравниваем новое значение с тем значением, которое было прочитано из файла. Тем самым мы убили двух зайцев — отладили парсер формул и привели результаты вычислений максимально близко к тем, что получаются при использовании Excel.
Конечно, мы не избавились ото всех проблем, связанных с формулами — уж слишком обширная тема. Но уже очень много всего изучили и реализовали, и не останавливаемся на достигнутом. Лично мне было интересно работать над ним, надеюсь, что и Вам было интересно читать эту статью.
Спасибо за внимание!
