Распознавание речи во FreePBX с помощью Яндекс Speechkit
Привет, хабр! Решил поделиться опытом интеграции Asterisk и сервиса Яндекса по распознаванию речи.
Загорелось моему заказчику внедрить в свою АТС фичу Voice2Text.
В качестве АТС использовался FreePBX.
Сразу в голову пришло использование сервисов распознавания речи от Google, но после нескольких часов безуспешных попыток добиться нужного результата решил попробовоть аналогичный сервис Яндекса.
Подробности под катом.
Исходные данные:
FreePBX Distro 12 Stable-6.12.65, CentOS 6.5, Asterisk 11 + неимоверное желание реализовать фичу Voice2Text:)
По умолчанию FreePBX пишет все записи в .wav, нам же нужно передать файлы на распознавание в .mp3. Для это воспользуемся sendmailmp3.
Работу sendmailmp3 можно разбить на некоторые этапы:
«поймать» поток проанализировать содержание электронной почты разделить сообщение на части извлечь аудиофайл конвертировать wav в mp3 восстановить содержимое почты Передать сообщение команде sendmail Воспользуемся скриптом, который установит sendmailmp3 и все необходимые для работы пакеты.
Переходим в /tmp:
cd /tmp Cкачиваем скрипт, который установит sendmailmp3:
wget http://pbxinaflash.com/installmp3stt.sh Делаем файл исполняемым:
chmod +x installmp3stt.sh И запускаем скрипт:
./installmp3stt.sh Далее идем в веб-интерфейс FreePBX, Вкладка Settings, Voicemail Admin, Settings:
И там в поле mailcmd пишем /usr/sbin/sendmailmp3А в поле format: wav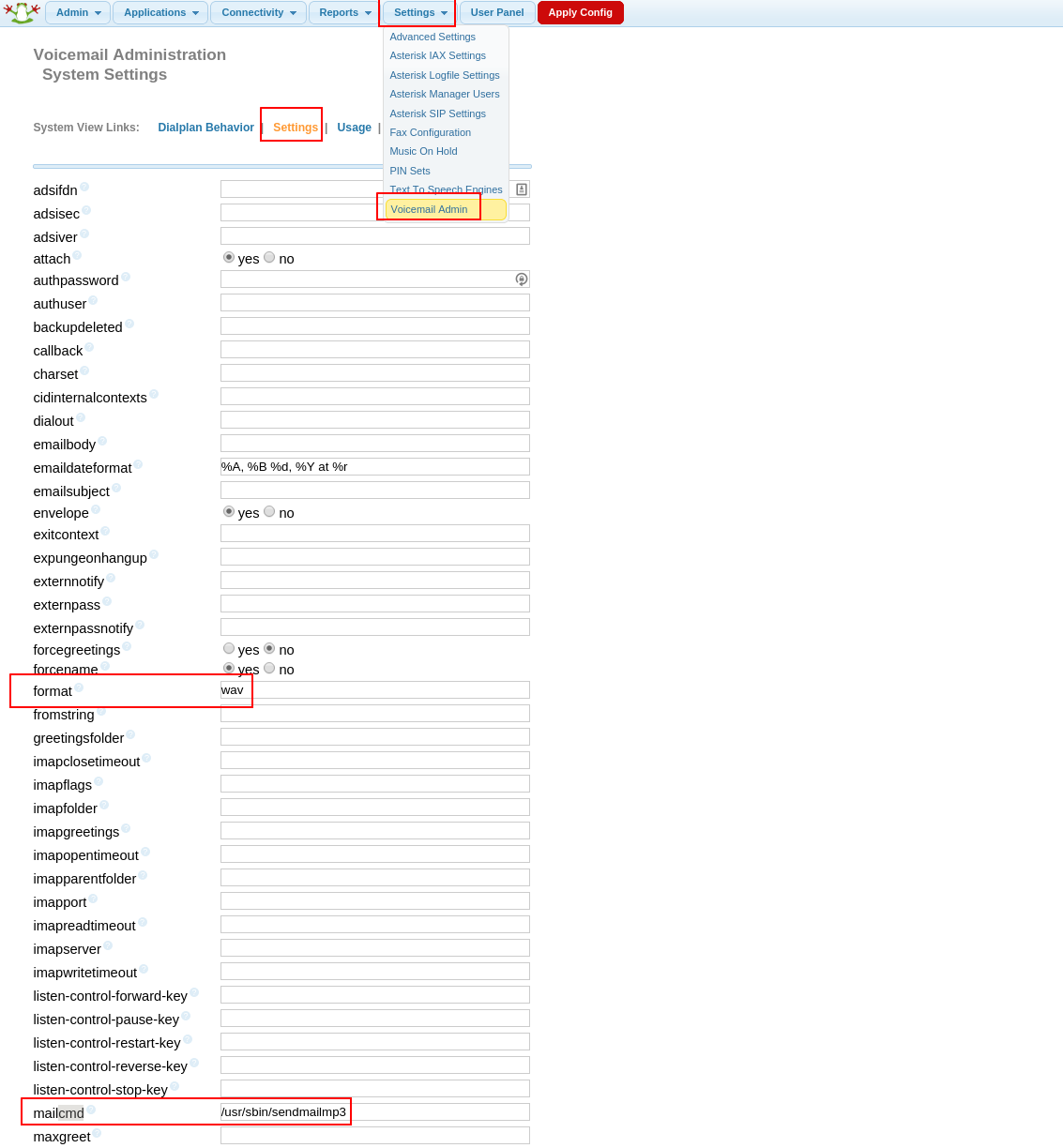
Теперь наши сообщения будут пересылаться на почту в формате mp3, добавим фичу Voice2Text.
Выбор сервисов Яндекса обусловлен тем, что можно отсылать файл прямо в mp3, а не перекодировать во flac или speex (по крайней мере другой информации о поддерживаемых форматах я не нашел), а также тем, что максимальная длина сообщения значительно больше нежели у гугла.
Прежде чем наш скрипт начнет полноценно работать, необходимо пройти по ссылке, далее зайти в кабинет разработчика, авторизироваться в нем с помощью почтового ящика яндекса и запросить API-ключ. После этого вам придет письмо на указанную почту с дальнейшими инструкциями: 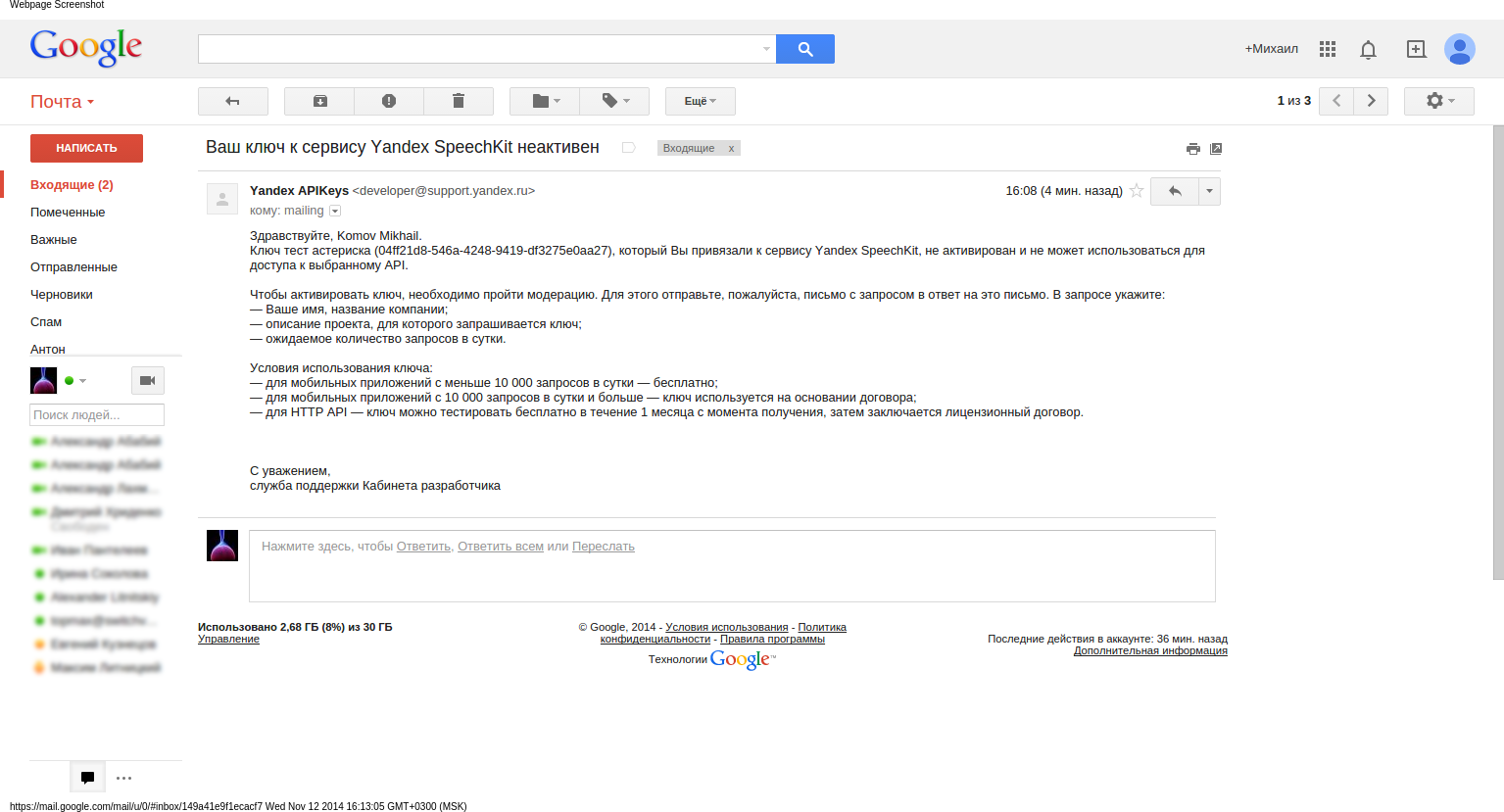
После того, как ваш ключ активирован, необходимо сформировать curl-запрос, который будет отсылать наш файлик на распознавание. Вид должен быть следующий: asr.yandex.net/asr_xml? uuid=<уникальный идентификатор пользователя>& key=
Поддерживаются следующие форматы:
audio/x-speex 1 audio/x-pcm; bit=16; rate=8000 audio/x-pcm; bit=16; rate=16000 2 audio/x-alaw; bit=13; rate=8000 audio/x-wav audio/x-mpeg-3 3 Ответ возвращается в виде XML, содержащего n-best список гипотез распознавания (до 5 значений) с указанием степени достоверности для каждой гипотезы.Пример удачного распознавания: улица басманная
Пример неудачного распознавания: />
В результате чего на указанный вами почтовый ящик падает сообщение с вариантами распознавания и аттачем с mp3-файлом подобное этому:
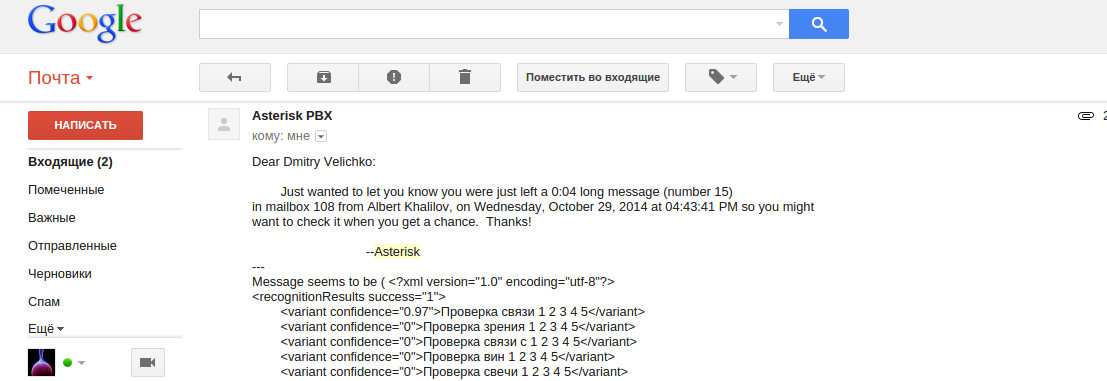
Получившийся в результате скрипт имеет следующий вид:
sendmailmp3 #! /bin/sh # Asterisk voicemail attachment conversion script, including voice recognition using Google API # # Revision history: # 22/11/2010 — V1.0 — Creation by N. Bernaerts # 07/02/2012 — V1.1 — Add handling of mails without attachment (thanks to Paul Thompson) # 01/05/2012 — V1.2 — Use mktemp, pushd & popd # 08/05/2012 — V1.3 — Change mp3 compression to CBR to solve some smartphone compatibility (thanks to Luca Mancino) # 01/08/2012 — V1.4 — Add PATH definition to avoid any problem (thanks to Christopher Wolff) # 31/01/2013 — V2.0 — Add Google Voice Recognition feature (thanks to Daniel Dainty idea and sponsoring:-) # 04/02/2013 — V2.1 — Handle error in case of voicemail too long to be converted
# set language for voice recognition (en-US, en-GB, fr-FR, …) LANGUAGE=«ru_RU»
# set PATH PATH=»/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin»
# save the current directory pushd . # create a temporary directory and cd to it TMPDIR=$(mktemp -d) cd $TMPDIR # dump the stream to a temporary file cat >> stream.org # get the boundary BOUNDARY=`grep «boundary=» stream.org | cut -d'»' -f 2` # cut the file into parts # stream.part — header before the boundary # stream.part1 — header after the bounday # stream.part2 — body of the message # stream.part3 — attachment in base64 (WAV file) # stream.part4 — footer of the message awk '/'$BOUNDARY'/{i++}{print > «stream.part«i}' stream.org # if mail is having no audio attachment (plain text) PLAINTEXT=`cat stream.part1 | grep 'plain'` if [ »$PLAINTEXT» != » ] then # prepare to send the original stream cat stream.org > stream.new # else, if mail is having audio attachment else # cut the attachment into parts # stream.part3.head — header of attachment # stream.part3.wav.base64 — wav file of attachment (encoded base64) sed '7,$d' stream.part3 > stream.part3.wav.head sed '1,6d' stream.part3 > stream.part3.wav.base64 # convert the base64 file to a wav file dos2unix -o stream.part3.wav.base64 base64 -di stream.part3.wav.base64 > stream.part3.wav # convert wav file to mp3 file # -b 24 is using CBR, giving better compatibility on smartphones (you can use -b 32 to increase quality) # -V 2 is using VBR, a good compromise between quality and size for voice audio files lame -m m -b 24 stream.part3.wav stream.part3.mp3 # convert back mp3 to base64 file base64 stream.part3.mp3 > stream.part3.mp3.base64 # generate the new mp3 attachment header # change Type: audio/x-wav to Type: audio/mpeg # change name=«msg----.wav» to name=«msg----.mp3» sed 's/x-wav/mpeg/g' stream.part3.wav.head | sed 's/.wav/.mp3/g' > stream.part3.mp3.head # convert wav file to flac compatible for Google speech recognition # sox stream.part3.wav -r 16000 -b 16 -c 1 audio.flac vad reverse vad reverse lowpass -2 2500
# call Google Voice Recognition sending flac file as POST curl -v -4 «asr.yandex.net/asr_xml? key=23988820–8719–4a2e-82ba-9ddd5a9bfe67&uuid=12345678123456781234567812345678&topic=queries&lang=ru-RU» -H «Content-Type: audio/x-mpeg-3» --data-binary »@stream.part3.mp3» 1>audio.txt # curl --data-binary @audio.flac --header 'Content-type: audio/x-flac; rate=16000' 'https://www.google.com/speech-api/v2/recognize? key=AIzaSyB5lwncPRYpNrHXtN-Sy-LNDMLLU5vM1n8&xjerr=1&client=chromium&pfilter=0&lang='ru_RU'&maxresults=1' 1>audio.txt # extract the transcript and confidence results FILETOOBIG=`cat audio.txt | grep »»` TRANSCRIPT=`cat audio.txt | cut -d»,» -f3 | sed 's/^.*utterance\»:\»\(.*\)\»$/\1/g'` CONFIDENCE=`cat audio.txt | cut -d»,» -f4 | sed 's/^.*confidence\»:0.\([0–9][0–9]\).*$/\1/g'`
# generate first part of mail body, converting it to LF only mv stream.part stream.new cat stream.part1 >> stream.new sed '$d' < stream.part2 >> stream.new
# beginning of transcription section echo »---» >> stream.new
# if audio attachment is too big if [ »$FILETOOBIG» != » ] then # error message echo «Voice message is too long to be transcripted.» >> stream.new else # append result of transcription echo «Message seems to be ($CONFIDENCE% confidence) :» >> stream.new echo »$TRANSCRIPT» >> stream.new fi
# end of message body tail -1 stream.part2 >> stream.new
# append mp3 header cat stream.part3.mp3.head >> stream.new dos2unix -o stream.new
# append base64 mp3 to mail body, keeping CRLF unix2dos -o stream.part3.mp3.base64 cat stream.part3.mp3.base64 >> stream.new # append end of mail body, converting it to LF only echo » >> stream.tmp echo » >> stream.tmp cat stream.part4 >> stream.tmp dos2unix -o stream.tmp cat stream.tmp >> stream.new fi # send the mail thru sendmail cat stream.new | sendmail -t # go back to original directory popd # remove all temporary files and temporary directory sleep 50 rm -Rf $TMPDIR
На мой взгляд этот вариант несколько проще, нежели было описано тут, т.к. все сводится к запуску и изменению одного скрипта и пары кликов в веб-интерфейсе, а также присылает записи в mp3, а не в .wav. Безусловно, кто-то скажет, что это не unix-way:), но может кому-то будет полезно, хотя бы в целях ознакомления.
