Распознавание паспорта РФ на платформе Эльбрус. Часть 1
В этой статье мы продолжим рассказывать о похождениях нашей программы распознавания паспорта: теперь паспорт отправится на Эльбрус!

Итак, что же мы знаем про архитектуру Эльбрус?
Эльбрус — высокопроизводительная и энергоэффективная архитектура процессоров, отличающаяся высокой безопасностью и надежностью. Современные процессоры архитектуры Эльбрус могут применяться в качестве серверов, настольных компьютеров и даже встраиваемых вычислителей. Они способны удовлетворить повышенным требованиям по информационной безопасности, рабочему диапазону температур и длительности жизненного цикла продукции. Процессоры архитектуры Эльбрус, как говорят нам публикации МЦСТ [1, 2], предназначены для решения задач обработки сигналов, математического моделирования, научных расчетов, а также других задач с повышенными требованиями к вычислительной мощности.
Мы в Smart Engines попробовали убедиться, правда ли производительности Эльбруса достаточно, чтобы реализовать распознавание паспорта без значительных потерь в скорости работы.
Обзорно-описательная часть: особенности архитектуры Эльбрус
Архитектура Эльбрус отностися к категории архитектур, использующих принцип широкого командного слова (Very Long Instruction Word, VLIW). На процессорах с VLIW-архитектурой компилятор формирует последовательности групп команд (широкие командные слова), в которых отсутствуют зависимости между командами внутри группы и сведены к минимуму зависимости между командами в разных группах. Эти группы команд исполняются параллельно, что обеспечивает высокий уровень параллелизма на уровне операций.

Распараллеливание на уровне команд целиком обеспечивается оптимизирующим компилятором, что позволяет значительно упростить аппаратуру для исполнения команд, поскольку теперь она не решает задач распараллеливания, как в случае, например, с архитектурой x86. Энергопотребление системы снижается: от процессора больше не требуется анализировать зависимости между операндами или переставлять операции, поскольку все эти задачи возложены на компилятор. Компилятор располагает значительно большими вычислительными и временными ресурсами, чем аппаратные анализораторы бинарного кода, и поэтому может выполнять анализ тщательнее, находить больше независимых операций, и в результате формировать широкие командные слова, исполняющиеся более эффективно.
Наряду с использованием параллелизма операций в архитектуре Эльбрус заложена реализация и других видов параллелизма, свойственных вычислительному процессу: векторного параллелизма, параллелизма потоков управления на общей памяти, параллелизма задач в многомашинном комплексе.
Кроме того, архитектура Эльбрус обладает бинарной совместимостью с архитектурой Intel x86, реализованной на базе динамической бинарной трансляции.
Еще одной важной особенностью архитектуры Эльбрус является аппаратная поддержка защиты программ и данных при исполнении. Программы исполняются в едином виртуальном пространстве, реализованном на аппаратном уровне, что минимизирует возможность исполнения вредоносного кода и позволяет выявлять труднообнаруживаемые на других архитектурах ошибки.
Таким образом, основные особенности архитектуры процессоров Эльбрус [3, 4]:
- параллельная энергетически эффективная архитектура ядра;
- автоматическое распараллеливание потока команд с помощью компилятора;
- повышение надежности и безопасности создаваемого программного обеспечения за счет наличия защищенного режима;
- совместимость с распространенными микропроцессорными архитектурами.
Наше знакомство с Эльбрусом
Конкретной машиной, с которой мы работали, был Эльбрус 4.4, объединяющий четыре 4-ядерных процессора Эльбрус 4С с 3 контроллерами памяти, 3 каналами межпроцессорного обмена, 1 каналом ввода-вывода и 8 Мбайтным кэшем 2-го уровня (по 2 Мб на ядро). Рабочая тактовая частота Эльбрус 4С составляет 800 МГц, технологическая норма 65 нм, средняя рассеиваемая мощность — 45 Вт. Операционная система — ОС «Эльбрус», созданная на основе Linux. Вот что нам отобразила команда uname -a:

Оптимизирующий компилятор под Эльбрус называется lcс. На нашем сервере был установлен lcc версии 1.20.09 от 27 августа 2015 года, совместимый с gcc 4.4.0. lcc работает со стандартными флагами gcc, а также определяет некоторые дополнительные. Из стандарных флагов мы обратили внимание на -ffast и -ffast-math. Данные опции выключены по умолчанию, поскольку включают преобразования с вещественной арифметикой, которые могут приводить к некорректным результатам работы программ, предполагающих строгое соблюдение стандартов IEEE или ISO для вещественных операций и функций. Кроме того, они включают некоторые потенциально опасные оптимизации, которые в редких случаях могут приводить к некорректному поведению программ, вольно жонглирующих указателями. Оба флага дополнительно включают -fstdlib, -faligned, -fno-math-errno, -fno-signed-zeros, -ffinite-math-only, -fprefetch, -floop-apb-conditional-loads, -fstrict-aliasing. Их использование заметно влияет на производительность программы.
Кроме того, lcc позволяет довольно тонко настраивать оптимизации, например для настройки параметров подстановки функций есть целый набор флагов:
Таблица 1. Флаги lcc, позволяющие управлять параметрами подстановки функций.
| Флаг lcc | Назначение |
|---|---|
| -finline-level= |
Задает коэффициент увеличения интенсивности подстановки [0.1–20.0] |
| -finline-scale= |
Задает коэффициент увеличения основных ресурсных ограничений [0.1–5.0] |
| -finline-growfactor= |
Задает максимальное увеличение размера процедуры после подстановки [1.0–30.0] |
| -finline-prog-growfactor= |
Задает максимальное увеличение размера программы после подстановки [1.0–30.0] |
| -finline-size= |
Задает максимальный размер подставляемой процедуры |
| -finline-to-size= |
Задает максимальный размер процедуры, в которую может быть произведена подстановка |
| -finline-part-size= |
Задает максимальный размер вероятного региона процедуры для частичной подстановки |
| -finline-uncond-size= |
Задает максимальный размер безусловно подставляемой процедуры |
| -flib-inline-uncond-size= |
Задает максимальный размер безусловно подставляемой библиотечной процедуры |
| -finline-probable-calls= |
Запрещает подстановку процедур, счетчик вызова которых меньше, чем (аргумент * max_call_count), где max_call_count — максимальный счетчик операции вызова на всей задаче. |
| -fforce-inline | Включает безусловную подстановку функций со спецификатором inline. |
| -finline-vararg | Включает подстановку функций с переменным числом аргументов. |
| -finline-only-native | Выполняет подстановку только для функций с явным модификатором inline |
Также можно настраивать межпроцедурные оптимизации, анализ указателей, подкачку данных и т. д.
Для профилирования на Эльбрусе доступны привычный многим perf, а также куда менее известный dprof. Кроме того, для dprof доступно расширение, позволяющее перевести профиль в valgrind-совместимый формат.
Итак, нашей целью было запустить консольную версию программы распознавания паспорта. Она целиком написана на С/С++, местами с использованием С++11. Несмотря на то, что поддержки С++11 не заявлено, на самом деле lcc понимает его, хотя и весьма избирательно. Полная поддержка С++11 планируется в новых версиях lcc.
Точно не поддерживаются:
- std: default_random_engine. К сожалению, здесь можно только посоветовать использовать сторонние генераторы псевдослучайных чисел.
- nullptr_t. В тех случаях, когда nullptr действительно нужен, приходится использовать вместо него какое-то специально выделенное значение объекта.
- std: begin и std: end. Для объектов STL можно использовать методы begin () и end (), а вот для С/С++ объектов придется искать адреса вручную.
- std: chrono: steady_clock. Мы использовали std: chrono: high_resolution_clock вместо него, хотя, конечно, отсутствие std: chrono: steady_clock может внести погрешности в измерения времени работы.
- Отсутствует метод std: string: pop_back (). Но вместо него спокойно можно использовать std: string: erase (size ()-1, 1).
- std: to_string не определен для аргумента типа double. Эта проблема решается преобразованием, например, к long double, который поддерживается.
- В стандартных контейнерах STL не предусмотрены спецификации для std: unique_ptr в качестве хранимого объекта с операцией перемещения вместо копирования, то есть, к примеру, создать std: map
При этом сами по себе std: unique_ptr, std: shared_ptr поддерживаются.
Кроме того, lcc расстраивает gcc-расширение __uint128_t, а также файлы исходного кода в кодировке UTF-8 с BOM.
После переписывания неподдерживаемых кусков кода мы смогли успешно скомпилировать наш проект. Однако просто взять и запустить программу распознавания паспорта нам не удалось: при попытке запуска мы получили ошибку Bus error. После консультации со специалистами МЦСТ было выяснено, что проблема заключается в невыровненном доступе в память, который возникает внутри библиотеки Eigen, которой мы пользуемся.
Eigen — оптимизированная header-only библиотека линейной алгебры, написанная на С++ [5]. Она может использоваться для различных операций над матрицами и векторами, а также включает оптимизации под x86 SSE, ARM NEON, PowerPC AltiVec и даже IBM S390x.
Поскольку разработчики Eigen вряд ли предполагали, что их библиотеку когда-либо будут использовать на Эльбрусе, они не предусмотрели его в списке поддерживаемых архитектур, и режим выровненного доступа в память был попросту отключен. Наши коллеги из МЦСТ оперативно помогли нам исправить эту проблему, показав, как следует модифицировать :

В результате этого дополнения необходимая нам функциональность Eigen заработала. Надо заметить, это была единственная несовместимость Eigen с Эльбрусом, причем проявляющаяся только при включенных оптимизациях.
Однако на этом наши злоключения не закочились. Ошибка Bus error никуда не делась, однако теперь она возникала при исполнении кода уже наших библиотек. После небольшого исследования мы выяснили, что невыровненный доступ в память периодически возникал при инициализации дополнительных контейнеров изображений в процессе распознавания.
При заполнении строчки 8-битной картинки фиксированным значением в целях ускорения находилась часть строчки, кратная 4 байтам, и заполнялась 32-битными значениями (созданными копированием исходного 8-битного), а остаток строчки заполнялся уже по одному байту. Однако при аллокации 8-битной картинки выравнивание в памяти гарантируется только до одного байта, и при попытке записать по такому адресу 32-битное значение возникала ошибка.
Для решения проблемы мы добавили в начале обработки строчки вычисление ближайшего адреса, кратного нужному количеству байт (в описанном случае — четырём) и заполнение до этого адреса по одному байту, а заполнение по 4 байта сделали уже с этого адреса.
После исправления этой ошибки наша программа не просто запустилась, но и продемонстрировала правильную работу!


Это уже была маленькая победа, но мы двинулись дальше. Следующим шагом мы перешли непосредственно к оптимизации нашей системы. Наша программа может работать в двух режимах: распознавание произвольно расположенного разворота паспорта на фотографии или отсканированном изображении (anywhere-режим), а также распознавание паспорта на видеоролике (mobile-режим). Во втором случае предполагается, что паспорт занимает большую часть кадра, от кадра к кадру его положение меняется слабо, и обработка одного кадра включает значительно упрощенные алгоритмы поиска документа.
Распознавание одного тестового изображения в anywhere-режиме, идущее в 1 поток, «из коробки» работало на Эльбрусе около 100 (!) секунд.
Сначала мы попробовали задействовать все 16 ядер Эльбрус 4.4. Задействовать эффективно все 16 потоков оказалось возможным только примерно в трети нашей программы. Остальные вычисления удалось распараллелить на 2 потока. В результате время распознавания сократилось до 7.5 секунд. Воодушевленные, мы посмотрели в профайлер. К нашему удивлению, мы увидели там что-то такое:

Оказалось, внутри основного цикла программы было замечательное место:
std::vectorВ результате многократного выполнения этого кода накладные расходы на изменение размера вектора чудовищно растут и достигают 16% времени распознавания. На других архитектурах это место не было заметно, однако на Эльбрусе реаллокация памяти оказалась неожиданно медленной. После исправления этой досадной оплошности время работы сократилось практически на 1 секунду.
Затем мы перешли к увеличению параллелизма внутри каждого потока — основной «фишке» VLIW. Для этого мы использовали самый короткий путь — уже оптимизированную специалистами МЦСТ библиотеку EML.
Высокопроизводительная библиотека EML
Для микропроцессоров архитектуры Эльбрус разработана библиотека EML — библиотека, предоставляющая пользователю набор разнообразных функций для высокопроизводительной обработки сигналов, изображений, видео, а также математические функций и операции [4, 6].
EML включает в себя следующие группы функций:
- Vector — функции для работы с векторами (массивами) данных;
- Algebra — функции линейной алгебры;
- Signal — функции обработки сигналов;
- Image — функции обработки изображений;
- Video — функции обработки видео;
- Volume — функции преобразования трехмерных структур;
- Graphics — функции для рисования фигур.
Библиотека EML предназначена для использования в программах, написанных на языках С/С++.
Низкоуровневые функции обработки изображений или поддерживаются EML напрямую, или представимы через основные ариметические функции EML над векторами (в нашем случае — строками изображения).
Например, поэлементное сложение двух массивов 32-битных вещественных чисел:
for (int i = 0; i < len; ++i)
dst[i] = src1[i] + src2[i];можно выполнить с помощью функции EML:
eml_Status eml_Vector_Add_32F(const eml_32f *pSrc1, const eml_32f *pSrc2, eml_32f *pDst, eml_32s len)где
pSrc1— Указатель на вектор первого операндаpSrc2— Указатель на вектор второго операндаpDst— Указатель на вектор результатаlen— Количество элементов в векторах
Возвращает она
EML_OK, если функция отработала успешноEML_INVALIDPARAMETER, если один из указателей равен NULL или длина векторов меньше или равна 0.
Всего перечисление eml_Status может принимать 4 значения:
EML_OK— Нет ошибокEML_INVALIDPARAMETER— Некорректный аргумент или вне допустимого диапазонаEML_NOMEMORY— Нет свободной памяти для операцииEML_RUNTIMEERROR— Некорректные данные, ошибка в процессе исполнения
Определены основные типы данных:
typedef char eml_8s;
typedef unsigned char eml_8u;
typedef short eml_16s;
typedef unsigned short eml_16u;
typedef int eml_32s;
typedef unsigned int eml_32u;
typedef float eml_32f;
typedef double eml_64f;Аналогично устроена функция для поэлементного умножения 32-битных вещественных чисел:
eml_Status eml_Vector_Mul_32F(const eml_32f *pSrc1, const eml_32f *pSrc2, eml_32f *pDst, eml_32s len)А вот для целых чисел определены только функции поэлементного сложения и умножения со сдвигом, которые выполняют такие операции:
// Addition
for (int i = 0; i < len; ++i)
dst[i] = SATURATE((src1[i] + src2[i]) << shift);
// Multiplication
for (int i = 0; i < len; ++i)
dst[i] = SATURATE((src1[i] * src2[i]) << shift); И собственно функции EML:
// int16_t addition
eml_Status eml_Vector_AddShift_16S(const eml_16s *pSrc1, const eml_16s *pSrc2, eml_16s *pDst, eml_32s len, eml_32s shift)
// int32_t addition
eml_Status eml_Vector_AddShift_32S(const eml_32s *pSrc1, const eml_32s *pSrc2, eml_32s *pDst, eml_32s len, eml_32s shift)
// uint8_t addition
eml_Status eml_Vector_AddShift_8U(const eml_8u *pSrc1, const eml_8u *pSrc2, eml_8u *pDst, eml_32s len, eml_32s shift)
// int16_t multiplication
eml_Status eml_Vector_MulShift_16S(const eml_16s *pSrc1, const eml_16s *pSrc2, eml_16s *pDst, eml_32s len, eml_32s shift)
// int32_t multiplication
eml_Status eml_Vector_MulShift_32S(const eml_32s *pSrc1, const eml_32s *pSrc2, eml_32s *pDst, eml_32s len, eml_32s shift)
// uint8_t multiplication
eml_Status eml_Vector_MulShift_8U(const eml_8u *pSrc1, const eml_8u *pSrc2, eml_8u *pDst, eml_32s len, eml_32s shift)Такие фунции могут пригодиться, например, для целочисленной арифметики.
В EML определена структура для изображения:
typedef struct {
void * data; /**< Указатель на начало данных */
eml_image_type type; /**< Тип данных изображения */
eml_32s width; /**< Ширина изображения в пикселях, ось x */
eml_32s height; /**< Высота изображения в пикселях, ось y */
eml_32s stride; /**< Расстояние между строками в элементах формата */
eml_32s channels; /**< Число каналов (элементов) в пикселе */
eml_32s flags; /**< Вспомогательные признаки */
void * state; /**< Указатель на внутреннюю структуру */
eml_32s bitoffset;/**< Смещение в битах от начала буфера данных до первого пикселя */
eml_format format; /**< Формат пикселя */
eml_8u addition[32 - 2 * sizeof (void *)]; /**< выравнивание размера структуры до 64 байт */
} eml_image;Поддерживаемые типы данных eml_image_type для изображений:
- EML_BIT — 1-битные беззнаковые целые данные
- EML_UCHAR — 8-битные беззнаковые целые данные
- EML_SHORT — 16-битные знаковые целые данные
- EML_INT — 32-битные знаковые целые данные
- EML_FLOAT — 32-битные данные с плавающей точкой
- EML_DOUBLE — 64-битные данные с плавающей точкой
- EML_USHORT — 16-битные безнаковые целые данные
EML поддерживает и другие функции, нужные для обработки изображений. Например, часто нужная для эффективной реализации сепарабельных фильтров функция транспонирования:
eml_Status eml_Image_FlipMain(const eml_image *pSrc, eml_image *pDst)Эта функция накладывает центр исходного изображения на центр результирующего изображения и выполняет транспонирование. Ее работу можно описать формулой:
dst[width_dst/2 + (y - height_src/2), height_dst/2 + (x - width_src/2)] = src[x, y], где x = [0, width-1], y = [0, height-1]Изображения должны иметь одинаковый тип данных (EML_UCHAR, EML_SHORT, EML_FLOAT или EML_DOUBLE) и иметь одинаковое число каналов (1, 3 или 4).
Эксперименты и результаты
В Таблице 2 показаны времена выполнения сложения и умножения для разных типов данных. В данном эксперименте мы 50 раз замеряли время выполнения 1000 итераций сложения/умножения двух массивов длины 105 и брали медиану из полученных значений. В таблице приведено среднее время выполнения одной итерации. Можно видеть, что использование EML позволяет заметно ускорить вычисления в вещественных 32-битных числах и 8-битных беззнаковых целых числах. Это важно, поскольку эти типы данных очень часто используются в оптимизированном тракте обработки изображений.
Таблица 2. Время выполнения сложения и умножения массивов чисел длины 105 на Эльбрус 4.4.
| Сложение | ||
|---|---|---|
| Тип данных | uint8_t | float |
| Без EML, мкс | 16.7 | 148.8 |
| EML, мкс | 8.0 | 83.6 |
| Умножение | ||
|---|---|---|
| Тип данных | uint8_t | float |
| Без EML, мкс | 31.4 | 108.9 |
| EML, мкс | 27.6 | 73.5 |
Затем, мы решили проверить, как EML работает с изображениями и исследовали транспонирование, поскольку это довольно востребованная операция при обработке изображений. Зависимость времени транспонирования от размера для квадратных изображений разных типов:
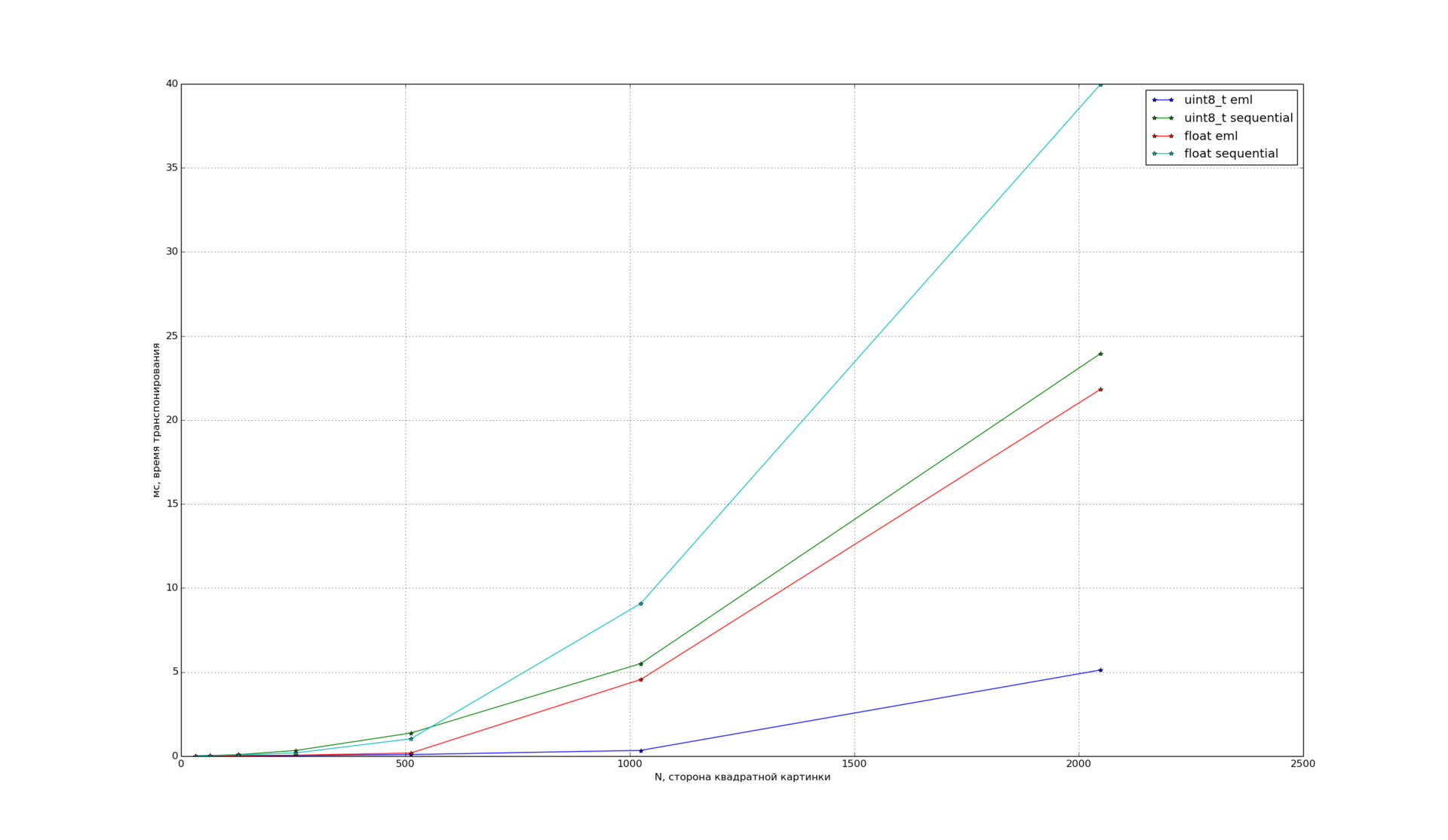
Можно видеть, что EML демонстрирует хорошее ускорение для типов uint8_t и float.
Результаты по ускорению программы распознавания паспорта (тестовое изображение, anywhere-режим) приведены в Таблице 3. Они были получены за первые 3 месяца работы с Эльбрусом и, разумеется, мы планируем работать над оптимизацией системы дальше.
Таблица 3. Процесс оптимизации программы распознавания паспорта на Эльбрус 4.4.
| Версия | Время работы, с |
|---|---|
| 1 поток | ~100 |
| 16 потоков, О3 | 6.2 |
| 16 потоков, O4 | 5.4 |
| 16 потоков, O4, транспонирование (EML) | 5.0 |
| 16 потоков, O4, транспонирование, матричные операции (EML) | 4.5 |
| 16 потоков, O4, транспонирование, матричные операции, арифметические операции (EML) | 3.4 |
Для оценки времени работы оптимизированной версии мы проанализировали время работы на 1000 входных изображений для каждого из режимов. В Таблице 4 приведены минимальное, максимальное и среднее времена распознавания одного кадра для anywhere- и mobile-режимов.
Таблица 4. Время работы распознавания паспорта на Эльбрус 4.4.
| Режим | Минимальное время, c | Максимальное время, с | Среднее время, с |
|---|---|---|---|
| anywhere | 0.9 | 8.5 | 2.2 |
| mobile | 0.2 | 1.5 | 0.6 |
Мы не стали сравнивать производительность с Intel или ARM: оптимизация наших библиотек для этих процессоров заняла у нас несколько лет и было бы некорректно проводить сравнение сейчас, всего лишь после 3 месяцев работы.
Заключение
В этой статье мы постарались поделиться своим опытом портирования программы на такую необычную архитектуру, как Эльбрус. «Этого точно не может случиться с нами!» — думали мы, рассуждая о некоторых видах программных ошибок, однако от глупых ляпов не застрахован никто. Стоит признать, что работа с платформой Эльбрус действительно помогла нам найти как минимум два проблемных места в нашем коде, поэтому обещания производителя можно считать выполненными.
Всего за несколько месяцев нам удалось не только добиться правильной работы распознавания, но и значительного ускорения нашей системы на Эльбрусе. Сейчас производительность нашей программы распознавания паспорта на Эльбрус 4.4 и на x86 отличается уже не на порядок, что является очень неплохим результатом. И мы не намерены останавливаться на достигнутом. Мы верим, что его все еще можно значительно улучшить.
Что ж, все это означает, что наши первые шаги в путешествии на Эльбрус можно считать вполне успешными!
Большое спасибо компании МЦСТ и ее сотрудникам за предоставление аппаратной платформы и консультаций по архитектуре и оптимизации.
Использованные источники
[1] А.К. Ким, И.Н. Бычков и др. Архитектурная линия «Эльбрус» сегодня: микропроцессоры, вычислительные комплексы, программное обеспечение // Современные информационные технологии и ИТ-образование. Сборник докладов, с. 21–29.
[2] A.К. Ким. Российские универсальные микропроцессоры и вычислительные комплексы высокой производительности: результаты и взгляд в будущее. Вопросы радиоэлектроники серия ЭВТ, Т. 3, c. 5–13, 2012.
[3] А.К. Ким и И.Н. Бычков. Российские технологии «Эльбрус» для персональных компьютеров, серверов и суперкомпьютеров.
[4] В.С. Волин и др. Микропроцессоры и вычислительные комплексы семейства «Эльбрус». Учебное пособие. Питер, 2013.
[5] Eigen, C++ template library for linear algebra: matrices, vectors, numerical solvers, and related algorithms, http://eigen.tuxfamily.org.
[6] П.А. Ишин, В.Е. Логинов, and П.П. Васильев. Ускорение вычислений с использованием высокопроизводительных математических и мультимедийных библиотек для архитектуры Эльбрус.
