Работа с изображениями на Python в 2017 году
Тема сегодняшнего разговора — чему же научился Python за все годы своего существования в работе с изображениями. И действительно, кроме старичков родом из 1990 года ImageMagick и GraphicsMagick, есть современные эффективные библиотеки. Например, Pillow и более производительная Pillow-SIMD. Их активный разработчик Александр Карпинский (homm) на MoscowPython сравнил разные библиотеки для работы с изображениями на Python, представил бенчмарки и рассказал о неочевидных особенностях, которых всегда хватает. В этой статье расшифровка доклада, который поможет вам выбрать библиотеку под свое приложение, и сделать так, чтобы она работало максимально эффективно.
О спикере: Александр Карпинский работает в компании Uploadcare и занимается сервисом быстрой модификации изображений на лету. Участвует в разработке Pillow — популярной библиотеки для работы с изображениями на Python, развивает собственный форк этой библиотеки — Pillow-SIMD, который использует современные инструкции процессоров для наибольшей производительности.
Бэкграунд
Uploadcare — это сервер, к которому приходит HTTP-запрос с идентификатором изображения и какими-то операциями, которые нужно выполнить клиенту. Сервер должен выполнить операции и как можно быстрее отдать ответ. В качестве клиента чаще всего выступает браузер.
Весь сервис можно описать как обертку вокруг графической библиотеки. Именно от качества, производительности и удобства использования графической библиотеки зависит качество всего проекта. Несложно догадаться, что в качестве графической библиотеки в Uploadcare используется Pillow.
Библиотеки
Кратко рассмотрим, какие вообще есть в Python библиотеки для работы с графикой, чтобы лучше понимать, о чем пойдет речь далее.
Pillow
Pillow — форк PIL (Python Imaging Library). Это очень старый проект, вышедший в 1995 году для Python 1.2. Можно представить, насколько он старый! В какой-то момент Python Imaging Library была заброшена, ее разработка прекратилась. Форк Pillow был сделан для того, чтобы устанавливать и собирать Python Imaging Library на современных системах. Постепенно количество изменений, которые нужны были людям в Python Imaging Library росло, и вышла Pillow 2.0, в которую была добавлена поддержка Python 3. Это можно считать началом отдельной жизни проекта Pillow.
Pillow представляет из себя нативный модуль для Python, половина кода написана на С, половина — на Python. Версии Python поддерживаются самые разнообразные: 2.7, 3.3+, PуPу, PуPуЗ.
Pillow-SIMD
Это мой форк Pillow, который выходит с мая 2016 года. SIMD означает Single Instruction, Multiple Data— подход, при котором процессор может выполнять большее количество действий на такт, используя современные инструкции.
Pillow-SIMD — это не форк в классическом понимании, когда проект начинает жить собственной жизнью. Это замена Pillow, то есть вы устанавливаете одну библиотеку вместо другой, ни строчки не меняете в своем исходном коде, и получаете большую производительность.
Pillow-SIMD можно собирать с инструкциями SSE4 (по умолчанию). Это набор инструкций, который есть практически во всех современных x86 процессорах. Также Pillow-SIMD можно собирать с набором инструкций AVX2. Этот набор инструкций есть, начиная с архитектуры Haswell, то есть примерно с 2013 года.
OpenCV
Другая библиотека для работы с изображениями в Python, о которой вы наверняка слышали — это OpenCV (Open Computer Vision). Работает с 2000 года. Биндинг на Python входит в комплект. Это означает, что биндинг постоянно актуален, не бывает рассинхронности между самой библиотекой и биндингом.
К сожалению, эта библиотека пока не поддерживается в PyPy, потому что OpenCV базируется на numpy, а numpy только недавно стал работать под PyPy, и в OpenCV поддержки PyPy все еще нет.
VIPS
Еще одна библиотека, на которую стоит обратить внимание — VIPS. Основная идея VIPS в том, что для работы с изображением не нужно загружать всё изображение в память. Библиотека может загружать какие-то маленькие кусочки, обрабатывать их и сохранять. Таким образом, для обработки гигапиксельных изображений не нужно тратить гигабайты памяти.
Это довольно старая библиотека — 1993 года, но она обогнала своё время. О ней долгое время было мало, что слышно, но в последнее время для VIPS стали появляться биндинги под разные языки, в том числе для Go, Node.js, Ruby.
Я долгое время хотел попробовать эту библиотеку, пощупать, но мне это не удавалось по очень глупой причине. Я не мог разобраться, как установить VIPS, потому что биндинг собирался очень сложно. Но теперь (в 2017 году) вышел биндинг pyvips от автора самого VIPS, с которым уже нет никаких проблем. Теперь установка и использование VIPS очень простая. Поддерживаются: Python 2.7, 3.3+, PуPу, PуPуЗ.
ImageMagick & GraphicsMagick
Если говорить о работе с графикой, то нельзя не упомянуть старичков — библиотеки ImageMagick и GraphicsMagick. Последняя изначально была форком ImageMagick с большей производительностью, но сейчас производительность у них, кажется, сравнялась. Других принципиальных отличий, насколько я знаю, между ними нет. Поэтому можно использовать любую, точнее, ту, которую вам удобнее использовать.
Это самые старые библиотеки из тех, о которых я сегодня упомянул (1990 год). За все это время было несколько биндингов для Python, и почти все из них благополучно умерли к настоящему моменту. Из тех, что можно использовать, остались:
- Биндинг Wand, который построен на ctypes, но уже тоже не обновляется.
- Биндинг pgmagick использует Boost.Python, поэтому компилируется очень долго и не работает в PyPy. Но, тем не менее, использовать его можно, я бы сказал, что он предпочтительнее, чем Wand.
Производительность
Когда мы говорим о работе с изображениями, первое, что нам интересно (по крайней мере мне) — это производительность, потому что иначе мы бы могли и на Python написать что-нибудь руками.
Производительность — это не такая простая штука. Нельзя просто сказать, что одна библиотека работает быстрее другой. В каждой библиотеке есть набор функций, и каждая функция работает с разной скоростью.
Соответственно, корректно говорить только о том, что производительность одной функции выше или ниже в конкретной библиотеке. Либо у вас есть приложение, которому нужен некий набор функциональности, и вы делаете бенчмарк именно под эту функциональность, и говорите, что для вашего приложения такая-то библиотека работает быстрее (медленнее).
Важно проверять результат
Когда вы делаете бенчмарки, очень важно смотреть на результат, который получается. Даже если с первого взгляда вы написали один и тот же код, это не значит, что он одинаковый.
Недавно в статье, где сравнивалась производительность Pillow и OpenCV, мне попался такой код:
from PIL import Image, ImageFilter.BoxBlur
im.filter(ImageFilter.BoxBlur(3))
...
import cv2
cv2.blur(im, ksize=(3, 3))
...
Вроде бы и там, и там, BoxBlur, и там, и там аргумент 3, но на самом деле результат разный. Потому что в Pillow (3) — это радиус размытия, а в OpenCV ksize=(3, 3) — это размер ядра, то есть, грубо говоря, диаметр. В данном случае корректное значение для OpenCV было бы 3×2+1, то есть (7, 7).
В чем проблема?
Почему вообще производительность — это проблема при работе с графикой? Потому что сложность любой операций зависит от нескольких параметров, и чаще всего сложность растет линейно с каждым из них. А если этих факторов, например, три, и сложность линейно зависит от каждого, то получается сложность в кубе.
Пример: Гауссово размытие в OpenCV.

Слева — радиус 3, справа — 30. Как видно, разница в скорости более чем в 10 раз.
Когда передо мной встала задача добавить размытие по Гауссу в мое приложение, меня не устраивало, что гипотетически может тратиться 900 мс на выполнение одной операции. Таких операций в приложении тысячи в минуту, и тратить столько времени на одну — нецелесообразно. Поэтому я изучил вопрос и реализовал в Pillow размытие по Гауссу, которое работает за константное время относительно радиуса. То есть на производительность Гауссова размытия влияет только размер картинки.
Но здесь главное не то, что что-то работает быстрее или медленнее.
Я хочу донести, что, когда вы строите какую-то систему, важно понимать, от каких параметров зависит сложность на выходе. Тогда вы сможете ограничить эти параметры или другими способами бороться с этой сложностью.
Наверное, самая частая операция, которую мы делаем с изображениями после их открытия, — это изменение размера (resize).
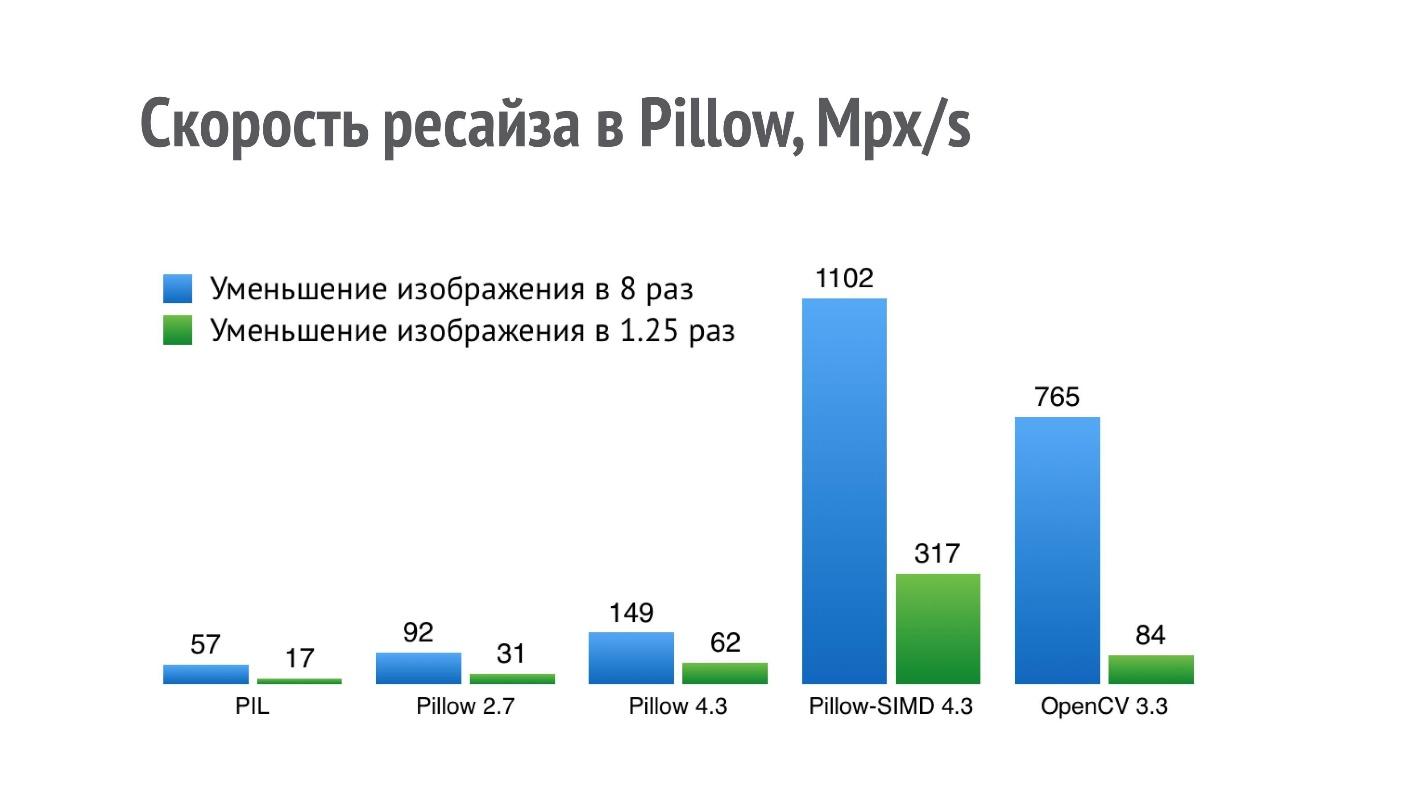
На графике представлена производительность (больше — лучше) разных библиотек для операции уменьшения изображения в 8 и в 1,25 раз.
Для PIL результат 17 Mpx/s означает, что фотографию с айфона (12 Mpx) можно уменьшить в 1,25 раз чуть меньше, чем за секунду. Такой производительности недостаточно для серьезного приложения, которое этих операций выполняет очень много.
Я стал оптимизировать производительность ресайза, и в Pillow 2.7 мне удалось добиться двукратного прироста производительности, а в Pillow 4.3 — трехкратного (на данный момент актуальна версия Pillow 5.3, но производительность ресайза в ней та же).
Но операция ресайза — это такая штука, которая очень хорошо ложится на SIMD. Она подходит к single instruction, multiple data, и поэтому в текущей версии Pillow-SIMD мне удалось в 19 раз увеличить скорость ресайза по сравнению с оригинальной Python Imaging Library при использовании тех же самых ресурсов.
Это существенно выше производительности ресайза в OpenCV. Но сравнение это не совсем корректное, потому что в OpenCV используется чуть менее качественный способ ресайза бокс-фильтром, а в Pillow-SIMD ресайз реализован с помощью сверток.
Это неполный список тех операций, которые ускорены в Pillow-SIMD по сравнению с обычной Pillow.
- Ресайз: от 4 до 7 раз.
- Размытие: 2,8 раз.
- Применение ядра 3×3 или 5×5: 11 раз.
- Умножение и деление на альфа-канал: 4 и 10 раз.
- Альфа-композиция: 5 раз.
Я уже сказал, что нельзя говорить, что какая-то библиотека работает быстрее, чем другая, но можно составить какой-то набор операций, который интересен именно вам. Я выбрал набор операций, которые интересны в моем приложении, сделал бенчмарк и получил такие результаты.

Оказалось, что Pillow-SIMD на этом наборе работает в 2 раза быстрее, чем Pillow. В самом конце находится Wand (напомню, что это ImageMagick).
Но меня заинтересовало другое — почему такие низкие результаты у OpenCV и VIPS, ведь это библиотеки, которые тоже разработаны с прицелом на производительность? Оказалось, что в случае OpenCV, та бинарная сборка OpenCV, которая ставится с помощью pip, собрана с медленным кодеком JPEG (автор сборки был уведомлен, на 2018 год эта проблема уже решена). Она собрана с libjpeg, в то время как в большинстве систем, по крайней мере debian-based, используется libjpeg-turbo, которая работает в несколько раз быстрее. Если собрать OpenCV из исходников самому, то производительность будет больше.
В случае VIPS ситуация другая. Я связался с автором VIPS, показал ему этот бенчмарк, мы с ним довольно долго и плодотворно переписывались. После чего автор VIPS нашел несколько мест в самом VIPS, где исполнение было не по оптимальному маршруту, и исправил их.
Вот что будет с производительностью, если собрать OpenCV из исходников текущей версии, а VIPS — из master, который уже есть сейчас.
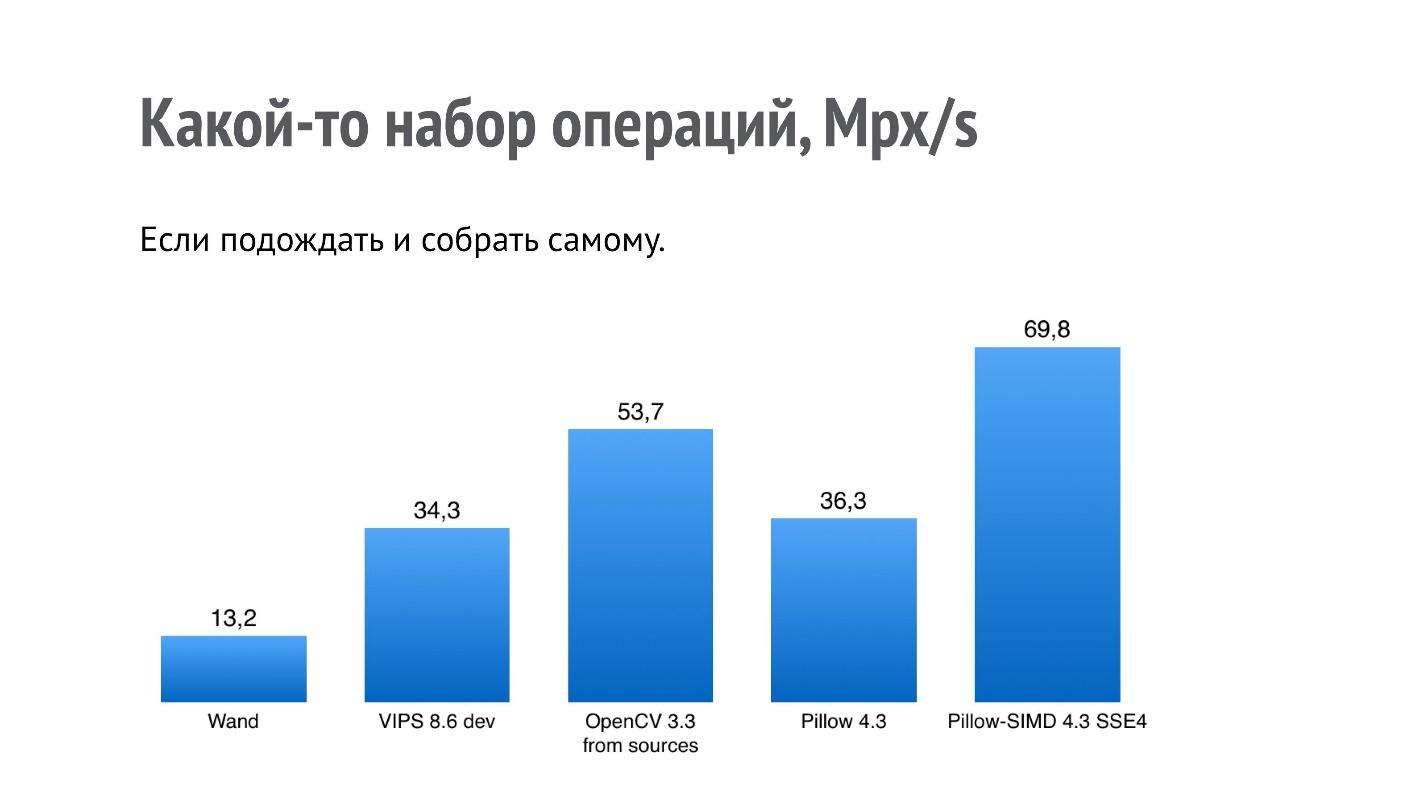
Даже если вы нашли какой-то бенчмарк, еще не факт, что все будет работать именно с такой скоростью именно на вашей машине.
Набор бенчмарков
Все бенчмарки, о которых я рассказал, можно найти на странице с результатами. Это отдельный мини-проект, где я пишу бенчмарки, которые мне самому нужны для разработки Pillow-SIMD, запускаю их и выкладываю результаты.
На GitHub есть проект с фреймворками для тестирования, где каждый может предложить свои бенчмарки или поправить существующие.
Параллельная работа
До сих пор я говорил о производительности в чистом виде, то есть на одно ядро процессора. Но нам всем давно доступны системы с бо́льшим количеством ядер, и хотелось бы их утилизировать. Здесь я должен сказать, что на самом деле Pillow — это единственная из всех рассматриваемых библиотек, которая не использует распараллеливание задач. Я сейчас постараюсь объяснить, почему так происходит. Все остальные библиотеки в том или ином виде его используют.
Метрики производительности
С точки зрения производительности нам интересны 2 параметра:
- Реальное время выполнения одной операции. Есть операция (либо последовательность операций), и вам интересно, за какое реальное время (wall clock) выполнится эта последовательность. Этот параметр важен на десктопе, где есть пользователь, который отдал команду и ждет результат.
- Пропускная способность всей системы (потока операций). Когда у вас есть набор операций, который идет постоянно, либо много независимых операций, и вам важна скорость обработки этих операций на вашем железе. Эта метрика более важна на сервере, где клиентов много, и нужно обслужить их всех. Время обслуживания одного клиента, конечно, важно, но чуть меньше, чем общая пропускная способность.
Исходя из этих двух метрик рассмотрим разные способы параллельной работы.
Способы параллельной работы
1. На уровне приложения, когда вы на уровне приложения решаете, что операции обрабатываются в разных потоках. При этом реальное время выполнения одной операции не меняется, потому что по-прежнему одно ядро занимается одной последовательностью операций. Пропускная способность системы растет пропорционально количеству ядер, то есть очень хорошо.
2. На уровне графических операций — то, что как раз есть в большинстве графических библиотек. Когда графическая библиотека получает какую-то операцию, она внутри себя создает необходимое количество потоков, разбивает одну операцию на несколько более мелких, и выполняет их. При этом реальное время выполнения уменьшается — одна операция выполняется быстрее. Но пропускная способность растет далеко не линейно от количества ядер. Есть операции, которые не параллелятся, и яркий пример — это декодирование PNG-файлов — его никак нельзя распараллелить. Кроме того, есть накладные расходы на создание потоков, разбиение задач, которые тоже не дают пропускной способности расти линейно.
3. На уровне команд процессора и данных. Мы специальным образом подготавливаем данные и используем специальные команды, для того чтобы процессор работал с ними быстрее. Это подход SIMD, который, собственно, и используется в Pillow-SIMD. Реальное время выполнения уменьшается, пропускная способность растет — это беспроигрышный вариант.
Как совместить параллельную работу
Если мы хотим совместить как-то параллельную работу, то SIMD хорошо совмещается с распараллеливанием внутри операции, и SIMD хорошо совмещается с распараллеливанием внутри приложения.

Но распараллеливание внутри приложения и внутри операции друг с другом не совмещаются. Если вы попробуете это сделать, то получите минусы от обоих подходов. Реальное время выполнения операции будет таким же, каким оно и было на одном ядре, а пропускная способность системы вырастет, но не линейно относительно количества ядер.
Многопоточность
Если уж мы заговорили про потоки — мы все пишем на Python и знаем, что в нем есть GIL, который не дает выполняться двум потокам одновременно. Python — это строго однопоточный язык.
Конечно, это не правда, потому что GIL на самом деле не дает выполняться двум потокам на Python, а если код написан на другом языке, и во время своей работы не использует внутренние структуры Python, то этот код может отпускать GIL и таким образом освобождать интерпретатор под другие задачи.
Многие библиотеки для работы с графикой освобождают GIL во время своей работы, в том числе Pillow, OpenCV, pyvips, Wand. Не освобождает только одна — pgmagick. То есть вы можете спокойно создавать потоки под выполнение каких-то операций, и это будет работать параллельно с остальным кодом.
Но возникает вопрос: сколько создавать потоков?
Если мы будем создавать бесконечное количество потоков под каждую задачу, которая у нас есть, то они просто займут всю память и весь процессор, — мы не получим никакой эффективной работы. Я сформулировал специальное правило.
Правило N + 1
Для продуктивной работы нужно создавать не более N + 1 воркеров, где N — количество ядер или потоков процессора на машине, а воркер — это процесс или поток, занятый обработкой.
Лучше всего использовать именно процессы, потому что даже в рамках одного интерпретатора есть узкие места и накладные расходы.
Например, у нас в приложении используется N + 1 instance Tornado, балансировку между которыми осуществляет ngnix. Если упомянуто Tornado, то давайте поговорим об асинхронной работе.
Асинхронная работа
То время, которое графическая библиотека занимается собственно полезной работой — обработкой изображений — можно и нужно использовать для ввода/вывода, если они есть у вас в приложении. Асинхронные фреймворки здесь очень в тему.
Но есть проблема — когда мы вызываем какую-то обработку, она вызывается синхронно. Даже если библиотека отпускает в этот момент GIL, все равно Event Loop блокируется.
@gen.coroutine
def get(self, *args, **kwargs):
im = process_image(...)
...
К счастью, эту проблему очень легко решить созданием ThreadPoolExecutor с одним тредом, на котором запускается обработка изображения. Этот вызов уже происходит асинхронно.
@run_on_executor(executor=ThreadPoolExecutor(1))
def process_image(self,
...
@gen.coroutine
def get(self, *args, **kwargs):
im = yield process_image(...)
...
По сути здесь создается очередь с одним воркером, который выполняет именно графические операции, а Event Loop не блокируется и спокойно работает параллельно в другом потоке.
Ввод/Вывод
Еще одна тема, которую я бы хотел затронуть в рамках разговора о графических операциях — это ввод/вывод. Дело в том, что мы редко создаем какие-то изображения с помощью графической библиотеки. Чаще всего мы открываем изображения, которые пришли к нам от пользователей в виде закодированных файлов (JPEG, PNG, BMP, TIFF и пр.).
Соответственно, графическая библиотека для построения хорошего приложения должна обладать некоторыми плюшками по вводу/выводу именно из файлов.
Ленивая загрузка
Первая такая плюшка — это ленивая загрузка. Если, например, в Pillow вы открываете изображение, то в этот момент не происходит декодирования картинки. Вам возвращается объект, который выглядит, как будто изображение уже загружено и работает. Вы можете посмотреть его свойства и решить на основании свойств этого изображения, готовы ли вы с ним работать дальше, не загрузил ли вам пользователь, например, гигапиксельную картинку для того, чтобы сломать ваш сервис.
>>> from PIL import Image
>>> %time im = Image.open()
Wall time: 1.2 ms
>>> im.mode, im.size
('RGB', (2152, 1345))
Если вы принимаете решение, что дальше работаете, то с помощью явного или неявного вызова load происходит декодирование этого изображения. Уже в этот момент выделяется нужное количество памяти.
>>> from PIL import Image
>>> %time im = Image.open()
Wall time: 1.2 ms
>>> im.mode, im.size
('RGB', (2152, 1345))
>>> %time im.load()
Wall time: 73.6 ms
Режим битых картинок
Вторая плюшка, которая нужна при работе с пользовательским контентом — это режим битых картинок. Файлы, которые мы получаем от пользователей, очень часто содержат какие-то несоответствия с форматом, в котором они закодированы.
Эти несоответствия бывают по разным причинам. Иногда это ошибки передачи по сети, иногда — просто какие-то кривые кодеки, которыми кодировалось изображение. По умолчанию Pillow, когда видит изображения, которые не соответствуют формату до конца, просто кидает исключение.
from PIL import Image
Image.open('trucated.jpg').save('trucated.out.jpg')
IOError: image file is truncated (143 bytes not processed)
Но пользователь же не виноват в том, что у него картинка битая, он все равно хочет получить результат. К счастью, у Pillow есть режим битых картинок. Мы меняем одну настройку, и Pillow старается по максимуму игнорировать все ошибки декодирования, которые есть в изображении. Соответственно, пользователь видит хотя бы что-то.
from PIL import Image, ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
Image.open('trucated.jpg').save('trucated.out.jpg')

Даже обрезанная картинка — это все равно лучше, чем ничего — просто страница с ошибкой.
Сводная таблица
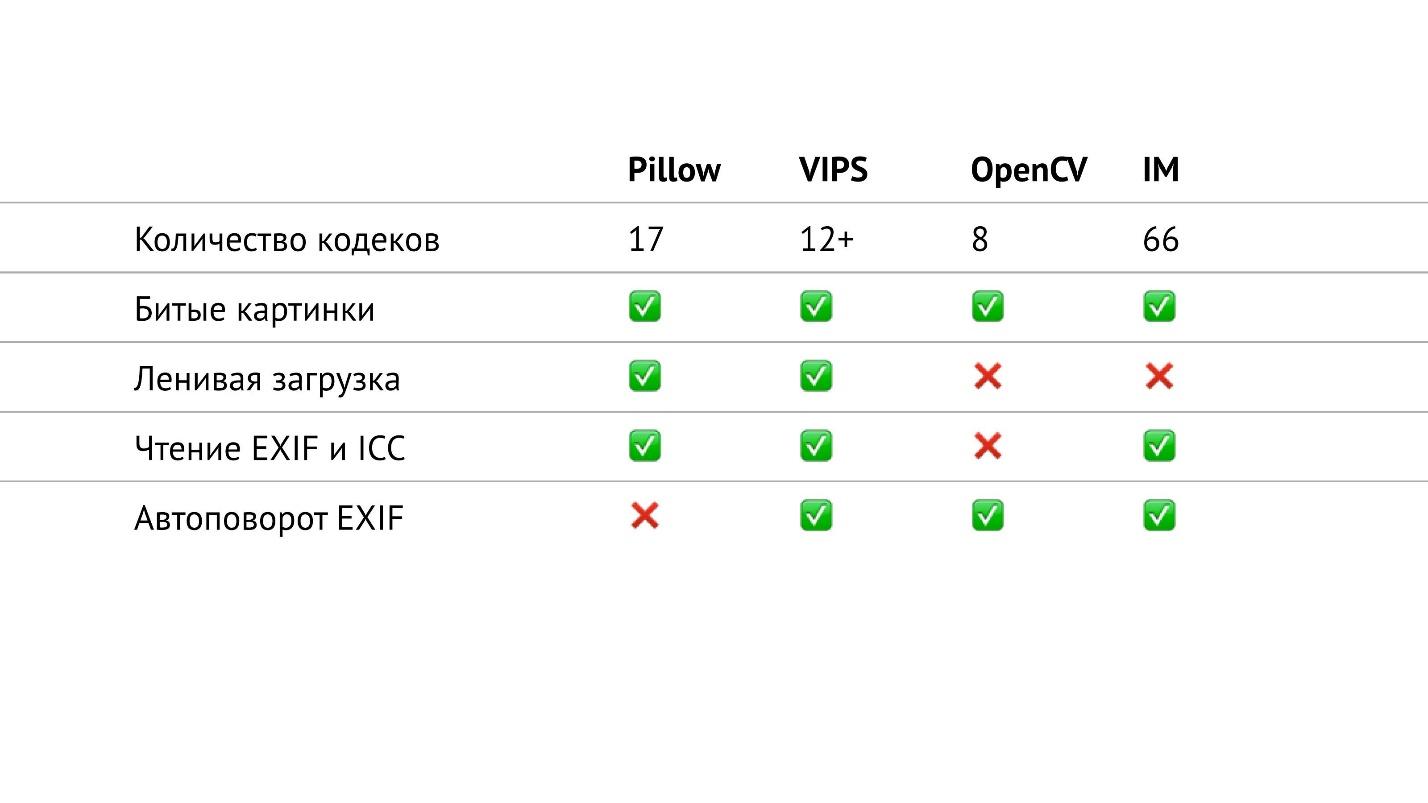
В таблице выше я собрал все, что касается ввода/вывода в тех библиотеках, о которых я рассказываю. В частности, я посчитал количество кодеков различных форматов, которые есть в библиотеках. Получилось, что в OpenCV их меньше всех, в ImageMagick — больше всех. Похоже, что в ImageMagick можно открыть вообще любое изображение, которое вам встретится. У VIPS 12 собственных кодеков, но VIPS может использовать ImageMagick в качестве промежуточного звена. Я не проверял, как это работает, надеюсь, что бесшовно.
В Pillow 17 кодеков. Это сейчас единственная библиотека, в которой нет автоповорота EXIF. Но сейчас это небольшая проблема, потому что можно прочитать EXIF самому и повернуть изображение в соответствии с ним. Это вопрос небольшого сниппета, который легко гуглится и занимает максимум в 20 строчек.
Особенности OpenCV
Если посмотреть на эту таблицу внимательно, то видно, что в OpenCV на самом деле не все так хорошо с вводом/выводом. В нем меньше всего кодеков, нет ленивой загрузки и нельзя прочитать EXIF и цветовой профиль.
Но это не все. На самом деле у OpenCV есть еще особенности. Когда мы просто открываем какую-то картинку, то вызов cv2.imread(filename) поворачивает JPEG-файлы в соответствии с EXIF (см. таблицу), но при этом игнорирует альфа-канал у PNG-файлов — довольно странное поведение!
К счастью, в OpenCV есть флаг: cv2.imread(filename, flags=cv2.IMREAD_UNCHANGED).
Если указать флаг IMREAD_UNCHANGED, то OpenCV оставляет альфа-канал у PNG-файлов, но перестает поворачивать JPEG-файлы в соответствии с EXIF. То есть один и тот же флаг влияет на два совершенно разных свойства. Как видно из таблицы, у OpenCV нет возможности прочитать EXIF, и получается, что в случае с этим флагом невозможно повернуть JPEG вообще.
Что делать, если вы заранее не знаете, какого формата у вас изображение, и вам нужны и альфа-канал у PNG, и автоповорот у JPEG? Ничего не сделать — OpenCV так не работает.
Причина, почему в OpenCV такие проблемы, кроется в названии этой библиотеки. В ней очень много функциональности для компьютерного зрения и анализа изображений. По сути, OpenCV рассчитана на работу с верифицированными источниками. Это, например, камера наружного наблюдения, которая раз в секунду скидывает изображения, и делает это в течение 5 лет в одном и том же формате и одном и том же разрешении. Здесь не нужна вариативность в вопросе ввода/вывода.
Людям, которым нужна функциональность OpenCV, не сильно нужна функциональность работы с пользовательским контентом.
Но что делать, если в вашем приложении все-таки нужна функциональность работы с пользовательским контентом, и в то же время нужна вся мощь OpenCV по обработке и статистике?

Решение в том, что нужно совмещать библиотеки. Дело в том, что OpenCV построен на базе numpy, и в Pillow есть все средства для того, чтобы экспортировать изображения из Pillow в массив numpy. То есть мы экспортируем массив numpy, и OpenCV может дальше работать с этим изображением, как со своим собственным. Это делается очень легко:
import numpy
from PIL import Image
...
pillow_image = Image.open(filename)
cv_image = numpy.array(pillow_image)
Дальше, когда мы делаем магию с помощью OpenCV (обработку), мы вызываем еще один метод Pillow и обратно импортируем из OpenCV картинку в формат Pillow. Соответственно, можно снова пользоваться вводом/выводом.
import numpy
from PIL import Image
...
pillow_image = Image.fromarray(cv_image, "RGB")
pillow_image.save(filename)
Таким образом получается, что мы пользуемся вводом/выводом от Pillow, и процессингом от OpenCV, то есть берем лучшее из двух миров.
Надеюсь, это поможет вам построить нагруженное приложение для работы с графикой.
Узнать некоторые другие секреты разработки на Python, перенять бесценный и местами неожиданный опыт, а главное обсудить свои задачи можно будет уже совсем скоро на Moscow Python Conf++. Например, обратите внимание на такие имена и темы в расписании.
- Donald Whyte с историей о том, как с помощью популярных библиотек, хитрости и коварства делать математику в 10 раз быстрее, а код — понятным и поддерживаемым.
- Андрей Попов про сбор огромного количества данных и их анализ на наличие угроз.
- Ефрем Матосян в своем докладе «Make Python fast again» расскажет, как увеличить производительность демона, обрабатывающего сообщения из шины.
Полной список того, что предстоит обсудить за 22 и 23 октября тут, успевайте присоединиться.
