Проактивная оптимизация производительности БД Oracle
Если вы работаете с боевыми серверами, то хорошо представляете, что значат инциденты производительности. Нужно всё бросить и быстро решать проблему. ООО РНКО «Платежный центр» работает с многими агентами, и для них очень важно, чтобы таких проблем было как можно меньше. Александр Макаров на HighLoad++ Siberia рассказал, что было сделано, чтобы значительно уменьшить количество инцидентов производительности. На помощь пришла проактивная оптимизация. А почему и как ее производят на боевом сервере, читайте ниже.

О спикере: Александр Макаров (AL_IG_Makarov) ведущий администратор БД Oracle ООО РНКО «Платежный центр». Несмотря на должность, администрированием, как таковым, занимается крайне мало, основные задачи связаны с поддержанием комплекса и его развитием, в частности с решением проблем производительности.
Сначала разберемся с терминами, что в данном докладе понимается под словами «проактивная оптимизация производительности». Иногда можно встретить точку зрения, что проактивная оптимизация — это, когда анализ проблемных мест проводится еще до запуска приложения. Например, выясняем, что какие-то запросы работают неоптимально, так как не хватает индекса или в запросе использован неэффективный алгоритм, при этом такая работа делается на тестовых серверах.
Тем не менее, мы в РНКО этот проект делали на боевых серверах. Много раз мне приходилось слышать: «Как так? Вы же это делаете на боевом сервере — значит, это не проактивная оптимизация производительности!» Тут надо вспомнить про подход, который культивируется в ITIL. С точки зрения ITIL у нас есть:
- инциденты производительности — это то, что уже произошло;
- меры, которые мы принимаем, чтобы инциденты производительности не происходили.
В этом смысле наши действия являются проактивными. Несмотря на то что мы решаем проблему на боевом сервере, сама проблема у нас еще не возникла: инцидент не произошел, мы не бегали и не пытались решить эту проблему в какие-то сжатые сроки.
Итак, в данном докладе под проактивностью понимается именно проактивность в смысле ITIL, мы решаем проблему до возникновения инцидента производительности.
РНКО «Платежный центр» обслуживает 2 крупных системы:
- РБС-Ритейл Банк;
- ЦФТ-Банк.
Характер нагрузки на этих системах смешанный (DSS + OLTP): есть что-то, что работает очень быстро, есть отчеты, есть средние нагрузки.
Мы столкнулись с тем, что не очень часто, но с определенной периодичностью, возникали инциденты производительности. Те, кто работает с боевыми серверами, представляют себе, что это такое. Это означает, что нужно все бросить и быстро решать проблему, потому что в это время клиент не может получить услугу, что-то либо не работает вообще, либо работает очень медленно.
Поскольку на нашу организацию завязано достаточно много агентов, клиентов, для нас это очень важно. Если мы не сможем быстро устранять инциденты производительности, значит, наши клиенты будут в той или иной мере страдать. Например, не смогут пополнить карточку или сделать перевод. Поэтому мы задумались, что можно сделать, для того чтобы избавиться даже от этих нечастых инцидентов производительности. Работать в режиме, когда необходимо бросать все и решать проблему, — это не совсем правильно. Мы используем спринты и составляем план работ на спринт. Наличие инцидентов производительности — это еще и отклонение от плана работ.
Надо что-то делать с этим!
Мы подумали и пришли к пониманию технологии проактивной оптимизации. Но прежде, чем я расскажу про проактивную оптимизацию, надо сказать несколько слов про классическую реактивную оптимизацию.
Реактивная оптимизация
Сценарий простой, есть боевой сервер, на котором что-то произошло: запустили отчет, клиенты получают выписки, в это время идет текущая активность на базе данных, и вдруг кто-то решил обновить какой-то объемный справочник. Система начинает тормозить. В этот момент приходит клиент и говорит: «Я не могу выполнить то-то и то-то» — надо найти причину, почему он не может это сделать.
Классический алгоритм действий:
- Воспроизвести проблему.
- Локализовать проблемное место.
- Оптимизировать проблемное место.
В рамках реактивного подхода главная задача не столько найти саму первопричину и устранить ее, сколько сделать так, чтобы система работала нормально. Устранением первопричины можно заняться и позже. Главное, быстро восстановить работоспособность сервера, чтобы клиент смог получить услугу.
Основные цели реактивной оптимизации
У реактивной оптимизации можно выделить две главные цели:
1. Уменьшение времени отклика.
Действие, например, получение отчета, выписки, транзакция, должно выполняться за какое-то регламентное время. Нужно сделать так, чтобы время получения услуги вернулось в приемлемые для клиента границы. Может быть, услуга работает чуть медленнее, чем обычно, но для клиента это допустимо. Тогда считаем, что инцидент производительности устранен, и начинаем работать над первопричиной.
2. Увеличение количества обработанных объектов за единицу времени при пакетной обработке.
Когда идет пакетная обработка транзакций нужно уменьшить время обработки одного объекта из пакета.
Плюсы реактивного подхода:
● Разнообразие инструментов и методик — самый главный плюс реактивного подхода.
Мы можем с помощью инструментов мониторинга понять, в чем непосредственно проблема: не хватает ЦПУ, потоков, памяти, или просела дисковая система, или логи медленно обрабатываются. Инструментов и методик по исследованию текущей проблемы производительности в БД Oracle достаточно много.
● Желаемое время отклика — еще один из плюсов.
В процессе такой работы мы доводим ситуацию до допустимого времени отклика, то есть не пытаемся его уменьшить до минимального значения, а доходим до некоторой величины и после этого действия заканчиваем, поскольку считаем, что дошли до приемлемых границ.
Минусы реактивного подхода:
- Инциденты производительности остаются — это самый большой минус у реактивного подхода, потому что мы не всегда можем дойти до первопричины. Она могла остаться где-то в стороне и лежать где-то глубже, несмотря на то, что мы достигли приемлемой производительности.
А как работать с инцидентами производительности, если они еще не случились? Попробуем сформулировать, каким образом можно провести проактивную оптимизацию, чтобы предотвратить такие ситуации.
Проактивная оптимизация
Первое, с чем мы сталкиваемся, — не известно, что нужно оптимизировать. «Сделай то, не знаю, что».
- Нет классического алгоритма.
- Проблема еще не возникла (неизвестна), и можно только предположить, где она может быть.
- Нужно найти какие-то потенциально слабые места в системе.
- Попытаться оптимизировать работу запросов в этих местах.
Основные цели проактивной оптимизации
Основные задачи проактивной оптимизации отличаются от задач реактивной оптимизации и состоят в следующем:
- избавление от узких мест в БД;
- уменьшение потребления ресурсов БД.
Последний момент является самым принципиальным. В случае реактивной оптимизации у нас нет задачи уменьшения потребления ресурсов в целом, а только задача привести время отклика работы функциональности в допустимые границы.
Как найти узкие места в БД?
Когда мы начинаем думать над этой проблемой, сразу возникает множество подзадач. Нужно провести:
- нагрузочное тестирование по ЦПУ;
- нагрузочное тестирование по чтениям/записям;
- нагрузочное тестирование по количеству активных сессий;
- нагрузочное тестирование по… и т.д.
Если мы попытаемся смоделировать эти проблемы на тестовом комплексе, то можем столкнуться с тем, что проблема, возникшая на тестовом сервере, не имеет никакого отношения к боевому. Причин для этого множество, начиная с того что тестовые серверы, как правило, слабее. Хорошо, если есть возможность сделать тестовый сервер точной копией боевого, но и это не гарантирует того, что нагрузка будет воспроизведена таким же образом, потому что нужно точно воспроизвести пользовательскую активность и еще множество разных факторов, которые влияют на итоговую нагрузку. Если попытаться смоделировать эту ситуацию, то, по большому счету, никто не гарантирует, что будет воспроизведено именно то же самое, что случится на боевом сервере.
Если в одном случае проблема возникла потому, что пришел новый реестр, то в другом она может возникнуть из-за того, что пользователь запустил огромный отчет, делающий большую сортировку, из-за которой временное табличное пространство (temporary tablespace) заполнилось, и, как следствие, система начала тормозить. То есть причины могут быть разные, и не всегда можно их предугадать. Поэтому от попыток искать узкие места на тестовых серверах мы отказались практически с самого начала. Мы отталкивались только от боевого сервера и от того, что на нем происходит.
Что же делать в таком случае? Давайте попробуем понять, каких ресурсов в первую очередь, скорее всего, будет не хватать.
Уменьшение потребления ресурсов БД
Исходя из промышленных комплексов, которые есть у нас в распоряжении, наиболее частая нехватка ресурсов наблюдается в дисковых чтениях и ЦПУ. Поэтому в первую очередь будем искать слабые места именно в этих областях.
Второй важный вопрос: как искать-то?
Вопрос очень нетривиальный. Мы используем Oracle Enterprise Edition с опцией Diagnostic Pack и для себя нашли такой инструмент — AWR-отчеты (в других редакциях Oracle можно использовать STATSPACK-отчеты). В PostgreSQL есть аналог — pgstatspack, есть pg_profile Андрея Зубкова. Последний продукт, как я понял, появился и начал развиваться только в прошлом году. Для MySQL мне не удалось найти похожих инструментов, но я не специалист по MySQL.
Сам подход не привязан к какой-то конкретной разновидности базы данных. Если есть возможность получить информацию по нагрузке системы из какого-то отчета, то, применяя методику, о которой я сейчас расскажу, можно выполнять работы по проактивной оптимизации на любой базе.
Оптимизация топ-5 операций
Технология проактивной оптимизации, которую мы выработали и применяем в РНКО «Платежный центр» состоит из четырех этапов.
Этап 1. Получаем отчет AWR за максимально большой период.
Максимально большой промежуток времени нужен, чтобы усреднить нагрузку в разные дни недели, так как иногда она сильно отличается. Например, в РБС-Ритейл Банке во вторник приходят реестры за прошлую неделю, они начинают обрабатываться, и целый день мы имеем нагрузку выше средней примерно в 2–3 раза. В остальные дни нагрузка меньше.
Если известно, что у системы есть какая-то специфика — в какие-то дни нагрузка больше, в какие-то дни — меньше, значит, отчеты нужно за эти периоды получать отдельно и работать с ними отдельно, если мы хотим оптимизировать конкретные интервалы времени. Если необходимо оптимизировать общую ситуацию на сервере, то можно получить большой отчет за месяц, и посмотреть, что же реально потребляет ресурсы сервера.
Иногда попадаются очень неожиданные ситуации. Например, в случае ЦФТ-Банка запрос, который проверяет очередь сервера отчетов, может попадать в топ-10. Причем этот запрос служебный и не выполняет никакой бизнес-логики, а только проверяет, есть отчет на выполнение или нет.
Этап 2. Смотрим секции:
- SQL ordered by Elapsed Time — SQL-запросы отсортированные по времени выполнения;
- SQL ordered by CPU Time — по употреблению ЦПУ;
- SQL ordered by Gets — по логическим чтениям;
- SQL ordered by Reads — по физическим чтениям.
Остальные секции SQL ordered by изучаются по мере необходимости.
Этап 3. Определяем родительские операции и зависимые от них запросы.
В отчете AWR есть отдельные секции, где, в зависимости от версии Oracle, показываются 15 и больше топовых запросов в каждой из этих секций. Но эти запросы Oracle в отчете AWR показывает вперемешку.
Например, есть родительская операция, внутри нее могут быть 3 топовых запроса. Oracle в отчете AWR покажет и родительскую операцию, и все эти 3 запроса. Поэтому надо сделать анализ этого списка и посмотреть, к какой операции относятся конкретные запросы, сгруппировать их.
Этап 4. Оптимизируем топ-5 операций.
После такой группировки на выходе получается список операций, из которых можно выбрать самые тяжелые. Мы ограничиваемся 5 операциями (не запросами, а именно операциями). Если система более сложная, то можно брать больше.
Типичные ошибки проектирования запросов
За время применения этой методики мы собрали небольшой список типичных ошибок проектирования. Некоторые ошибки настолько простые, что кажется, что их быть не может.
● Отсутствие индекса → Полное сканирование
Бывают очень казусные случаи, например, с отсутствием индекса на боевой схеме. У нас был конкретный пример, когда запрос долгое время работал быстро без индекса. Но там было полное сканирование, и поскольку размер таблицы постепенно рос, то запрос начал работать медленнее, и из квартала в квартал требовал чуть больше времени. В конечном итоге мы обратили на него внимание и оказалось, что индекса там нет.
● Большая выборка → Полное сканирование
Вторая типичная ошибка — это большая выборка данных — классический случай полного сканирования. Все знают, что полное сканирование надо использовать только тогда, когда это действительно оправдано. Иногда бывают случаи, когда попадается полное сканирование там, где можно было бы обойтись без него, например, если перенести условия фильтрации из pl/sql-кода в запрос.
● Неэффективный индекс → Длинный INDEX RANGE SCAN
Может быть, это даже самая распространенная ошибка, про которую почему-то очень мало говорят, — так называемый неэффективный индекс (длинное индексное сканирование, длинный INDEX RANGE SCAN). Например, у нас есть таблица по реестрам. В запросе мы пытаемся найти все реестры данного агента, и в конечном итоге добавляем какое-нибудь условие фильтрации, например, за некий период, или с определенным номером, или конкретного клиента. В таких ситуациях индекс обычно строят только по полю «агент» из соображений универсальности использования. В итоге получается такая картина: в первый год работы, скажем, у агента было 100 записей в этой таблице, в следующем году уже 1 000, еще через год может быть 10 000 записей. Проходит некоторое время, этих записей становится 100 000. Очевидно, что запрос начинает медленно работать, потому что в запрос нужно добавлять не только сам идентификатор агента, но еще и какой-то дополнительный фильтр, в данном случае по дате. Иначе будет получаться, что объем выборки из года в год будет увеличиваться, поскольку число реестров для данного агента растет. Эту проблему надо решать на уровне индекса. Если данных становится слишком много, тогда надо уже думать в сторону секционирования.
● Ненужные ветки дистрибутивного кода
Это тоже курьезный случай, но, тем не менее, и так бывает. Мы смотрим в топ запросов, и видим там какие-то странные запросы. Приходим к разработчикам и говорим: «Мы нашли некоторые запросы, давайте разберемся и посмотрим, что с этим можно сделать». Разработчик задумывается, потом приходит через некоторое время и говорит: «В вашей системе этой ветки кода быть не должно. У вас эта функциональность не используется». Потом разработчик рекомендует включить какую-то специальную настройку, чтобы работать в обход этого участка кода.
Примеры из практики
Теперь я бы хотел рассмотреть два примера из нашей реальной практики. Когда мы имеем дело с топом запросов, мы конечно в первую очередь думаем о том, что там должно быть что-то мегатяжелое, нетривиальное, со сложными операциями. На самом деле это не всегда так. Иногда бывают случаи, когда в топ операций попадают очень даже простые запросы.
Пример 1
select *
from (select o.*
from rnko_dep_reestr_in_oper o
where o.type_oper = 'proc'
and o.ean_rnko in
(select l.ean_rnko
from rnko_dep_link l
where l.s_rnko = :1)
order by o.date_oper_bnk desc,
o.date_reg desc)
where ROWNUM = 1
В этом примере запрос всего из двух таблиц, причем это не тяжелые таблицы — всего лишь несколько миллионов записей. Казалось бы, чего проще? Тем не менее, запрос попал в топ.
Давайте попробуем разобраться, что же с ним не так.
Ниже приведена картинка из Enterprise Manager Cloud Control — данные по статистике работы этого запроса (у Oracle есть такой инструмент). Видно, что есть регулярная нагрузка по данному запросу (верхний график). Цифра 1 сбоку говорит о том, что в среднем работает не больше одной сессии. Зеленая диаграмма показывает, что запрос использует только ЦПУ, что вдвойне интересно.

Попробуем разобраться, что же тут происходит?

Выше таблица со статистикой по запросу. Почти 700 тысяч запусков — этим никого не удивишь. Но интервал времени от First Load Time 15 декабря до Last Load Time 22 декабря (см. предыдущую картинку) — это одна неделя. Если посчитать количество запусков в секунду, получается, что запрос в среднем выполняется каждую секунду.
Смотрим дальше. Время выполнения запроса 0,93 сек, т.е. меньше секунды, это же замечательно. Можно порадоваться — запрос не тяжелый. Тем не менее он попал в топ, значит потребляет много ресурсов. В каком месте он потребляет много ресурсов?
В таблице есть строчка по логическим чтениям. Мы видим, что на один запуск ему требуется почти 8 тысяч блоков (обычно 1 блок — это 8 Кбайт). Получается, что запрос, работая один раз в секунду, загружает примерно 64 Мбайта данных из памяти. Что-то здесь уже не так, надо разбираться.
Посмотрим план: есть полное сканирование. Что ж, пойдем дальше.
Plan hash value: 634977963
-------------------------------------------------------------------
| Id | Operation | Name |
-------------------------------------------------------------------
| 0 | SELECT STATEMENT | |
|* 1 | COUNT STOPKEY | |
| 2 | VIEW | |
|* 3 | SORT ORDER BY STOPKEY | |
| 4 | NESTED LOOPS | |
| 5 | TABLE ACCESS BY INDEX ROWID| RNKO_DEP_LINK |
|* 6 | INDEX UNIQUE SCAN | UK_RNKODEPLINK$S_RNKO |
|* 7 | TABLE ACCESS FULL | RNKO_DEP_REESTR_IN_OPER |
-------------------------------------------------------------------
Predicate Information (identified by operation id):
1 - filter(ROWNUM=1)
3 - filter(ROWNUM=1)
6 - access("L"."S_RNKO"=:1)
7 - filter(("O"."TYPE_OPER"='proc' AND "O"."EAN_RNKO"="L"."EAN_RNKO"))
В таблице rnko_dep_reestr_in_oper, всего лишь 5 миллионов строк и их средняя длина строки 150 байт. Но оказалось, что не хватает индекса по тому полю, которое является соединительным — подзапрос соединяется с запросом через поле ean_rnko, по которому индекса нет!
Более того, даже если он появится, на самом деле ситуация будет не очень хорошая. Возникнет то длинное индексное сканирование (длинный INDEX RANGE SCAN). ean_rnko — это внутренний идентификатор агента. Реестры по агенту будут накапливаться, и с каждым годом количество данных, которые будет выбирать этот запрос, будет увеличиваться, и запрос будет подтормаживать.
Решение: создать индекс по полям ean_rnko и date_reg, попросить разработчиков ограничить глубину сканирования по дате в данном запросе. Тогда можно хотя бы в некоторой степени гарантировать, что производительность запроса будет оставаться примерно в одних и тех же границах, так как объем выборки будет ограничиваться фиксированным интервалом времени, и не нужно будет вычитывать всю таблицу. Это очень важный момент, посмотрите, что получилось.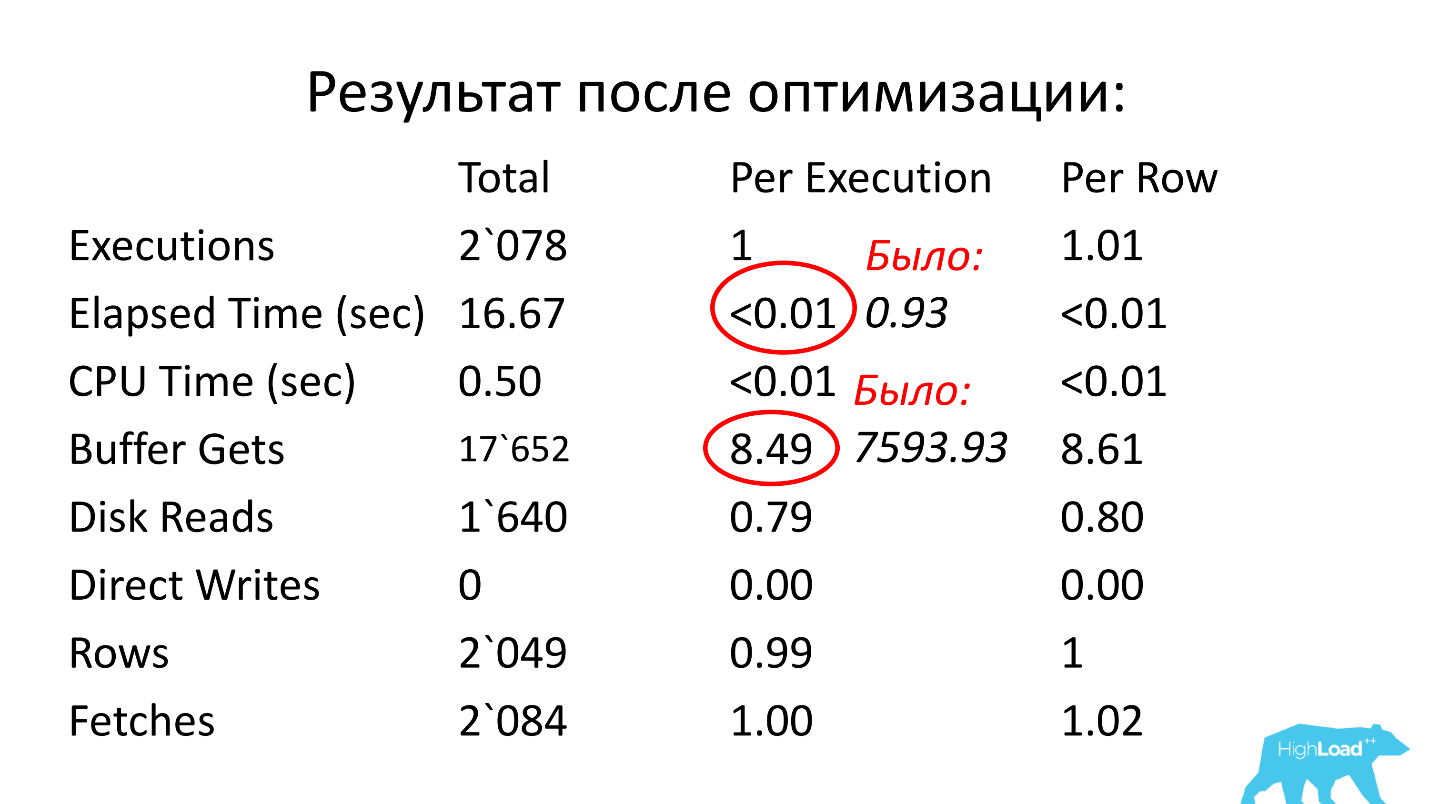
После оптимизации время работы стало меньше сотой секунды (было 0,93), количество блоков стало в среднем 8,5 — меньше в 1000 раз, чем было.
Пример 2
select count(1)
from loy$barcodes t
where t.id_processing = :b1
and t.id_rec_out is null
and not t.barcode is null
and t.status = 'u'
and not t.id_card is null
Я начал рассказ с того, что обычно в топе запросов ожидается что-то сложное. Выше пример «сложного» запроса, который идет к одной таблице (!), и он тоже попал в топ запросов :) Индекс по полю ID_PROCESSING есть!
В данном запросе есть 3 условия IS NULL, а, как мы знаем, такие условия не индексируются (нельзя использовать индекс в этом случае). Плюс есть всего лишь два условия типа равенство (по ID_PROCESSING и STATUS).
Наверное, разработчик, который посмотрел бы на этот запрос, в первую очередь предложил бы сделать индекс по ID_PROCESSING и STATUS. Но учитывая количество данных, которое при этом выберется (их будет очень много), это решение не проходит.
Однако, запрос потребляет много ресурсов, значит, нужно сделать что-то такое, чтобы он стал работать быстрее. Давайте попробуем разобраться в причинах.
Выше статистика за 1 день, из которой видно, что запрос запускается каждые 5 минут. Основное потребление ресурсов — это ЦПУ и чтение с диска. Ниже на графике со статистикой количества запусков запроса видно, что в целом все в порядке — количество запусков почти не меняется с течением времени — достаточно стабильная ситуация.
А если дальше посмотреть, то видно, что время работы запроса иногда меняется достаточно сильно — в несколько раз, что уже существенно.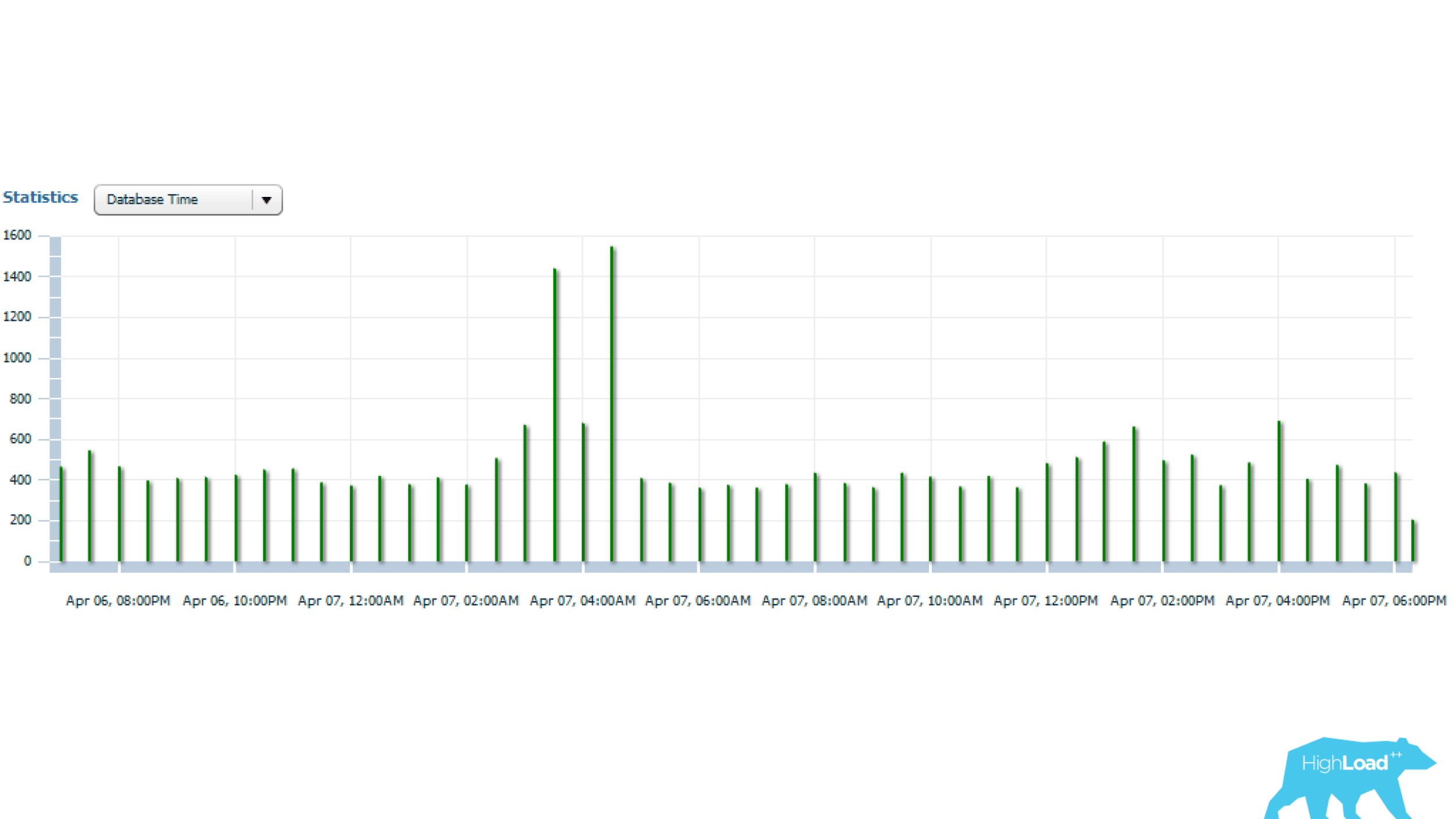
Давайте разбираться дальше.
В Oracle Enterprise Manager есть утилита SQL-Monitoring. Этой утилитой можно посмотреть в режиме реального времени потребление запросом ресурсов.
Выше отчет для проблемного запроса. В первую очередь нас должно заинтересовать, что INDEX RANGE SCAN (нижняя строка) в колонке Actual Rows показывает 17 миллионов строк. Наверное, стоит задуматься.
Если посмотреть дальше на план выполнения, то окажется, что после следующего пункта плана из этих 17 миллионов строк остается всего 1705. Спрашивается — зачем было выбрано 17 миллионов? В итоговой выборке осталось примерно 0,01%, то есть выполнена заведомо неэффективная, ненужная работа. Более того, эта работа выполняется каждые 5 минут. Вот проблема! Поэтому это запрос попал в топ запросов.
Давайте попробуем решить эту нетривиальную проблему. Индекс, который напрашивается в первую очередь, неэффективен, поэтому нужно придумать что-то хитрое и победить условия IS NULL.
Новый индекс
Мы посовещались с разработчиками, подумали, и пришли к такому решению: сделали функциональный индекс, в котором есть колонка ID_PROCESSING, которая была с условием равенства в запросе, а все остальные поля включили в качестве аргументов этой функции:
create index gc.loy$barcod_unload_i
on gc.loy$barcodes (gc.loy_barcodes_ic_unload(id_rec_out,
barcode,
id_card,
status),
id_processing);
Где
function loy_barcodes_ic_unload(
pIdRecOut in loy$barcodes.id_rec_out%type,
pBarcode in loy$barcodes.barcode%type,
pIdCard in loy$barcodes.id_card%type,
pStatus in loy$barcodes.status%type)
return varchar2 deterministic is
vRes varchar2(1) := '';
begin
if pIdRecOut is null and pBarcode is not null and pIdCard is not null and pStatus = 'U' then
vRes := pStatus;
end if;
return vRes;
end loy_barcodes_ic_unload;
Эта функция типа deterministic, то есть на одном и том же наборе параметров всегда выдает один и тот же ответ. Мы сделали так, чтобы эта функция выдавала фактически всегда одно значение — в данном случае «U». Когда все эти условия выполняются, выдается «U», когда не выполняются — NULL. Такой функциональный индекс дает возможность эффективно отфильтровать данные.
Применение этого индекса привело к следующему результату:
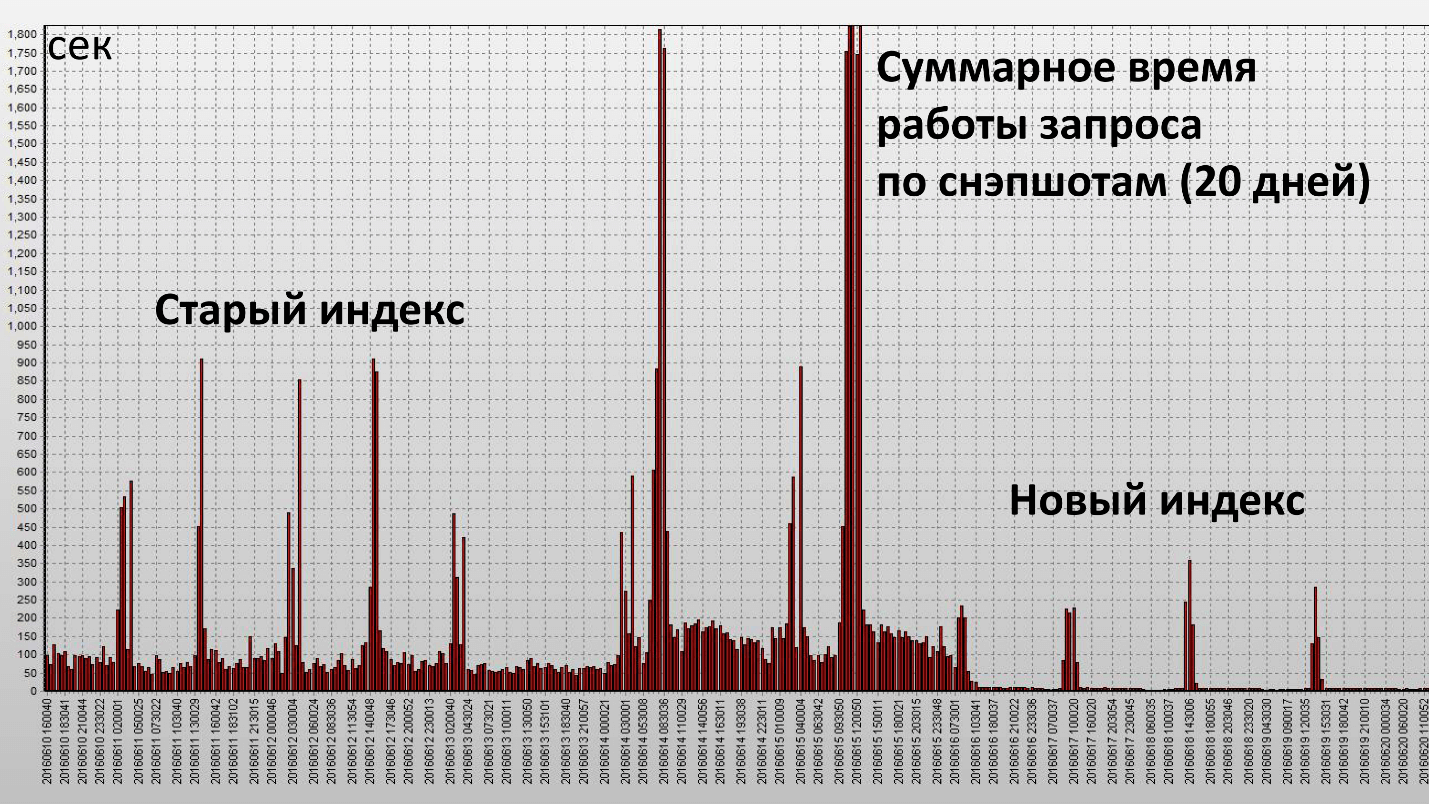
Здесь одна колонка — это один снэпшот, они делаются каждые полчаса работы БД. Мы добились своей цели и этот индекс оказался действительно эффективным. Посмотрим количественные характеристики:
| Средняя статистика работы запроса | ||
| ДО | ПОСЛЕ | |
| Elapsed Time, сек | 143.21 | 60.7 |
| CPU Time, сек | 33.23 | 45.38 |
| Buffer Gets, блок | 6`288`237.67 | 1`589`836 |
| Disk Reads, блок | 266`600.33 | 2`680 |
Время работы уменьшилось в 2,5 раза, а потребление ресурсов (Buffer Gets) — примерно в 4. Количество блоков данных, считываемых с диска, уменьшилось очень значительно.
Результаты применения проактивной оптимизации
Мы получили:
- снижение нагрузки на БД;
- повышение стабильности работы БД;
- значительное уменьшение количества инцидентов производительности ПО.
Инциденты производительности уменьшились в 10 раз. Это субъективная величина, раньше инциденты происходили на комплексе РБС-Ритейл Банк стабильно 1–2 раза в месяц, а сейчас мы практически про них забыли.
Тут возникает вопрос —, а причем тут инциденты производительности ПО? Мы же не занимались ими напрямую?
Вернемся к последнему графику. Если вы помните, там было полное сканирование, требовалось хранить в памяти большое количество блоков. Поскольку запрос выполнялся регулярно, все эти блоки хранились в кэше Oracle. При этом получается, что, если в это время в базе возникнет высокая нагрузка, например, кто-то начнет активно пользоваться памятью, нужен будет кэш для хранения блоков данных. Таким образом, часть данных для нашего запроса будет вытесняться, а значит, придется делать физические чтения. Если делать физические чтения, время работы запроса сразу колоссально увеличится.
Логическое чтение — это работа с памятью, оно происходит быстро, а любое обращение к диску — это медленно (если смотреть по времени, миллисекунды). Если повезет, и в кэше операционной системы или в кэше массива есть эти данные, то все равно это будут десятки микросекунд. Чтение из кэша самого Oracle намного быстрее.
Когда мы избавились от полного сканирования, исчезла необходимость хранить такое большое количество блоков в кэше (Buffer Cache). Когда происходит нехватка этих ресурсов, запрос работает более-менее стабильно. Больше не наблюдается таких больших всплесков, какие были со старым индексом.
Итоги по проактивной оптимизации:
- Первичную оптимизацию запросов нужно проводить на серверах тестирования, смотреть, как работают запросы и их бизнес-логику, чтобы не делать ничего лишнего. Эти работы остаются.
- Но периодически, раз в несколько месяцев имеет смысл снимать отчеты по полной нагрузке с сервера, делать поиск топовых запросов и операций в БД и оптимизировать их.
Инструментов для получения статистических данных в БД Oracle много:
- AWR Report (DBMS_WORKLOAD_REPOSITORY.awr_report_html);
- Enterprise Manager Cloud Control 12c (SQL Details);
- SQL Details Active Report (DBMS_PERF.report_sql);
- SQL Monitoring (вкладка в EMCC);
- SQL Monitoring Report (DBMS_SQLTUNE.report_sql_monitor*).
Часть этих инструментов работает в консоли, то есть не привязаны к Enterprise Manager.
Примеры работы инструментов Oracle по сбору статистических данных
Бонус: специалисты РНКО «Платежный центр» и ЦФТ отлично подготовились к конференции в Новосибирске, сделали несколько полезных докладов, а еще организовали настоящее выездное радио. За два дня в эфире радио ЦФТ успели побывать эксперты, докладчики, организаторы. Перенестись с сибирское лето можно, включив записи, вот ссылки на блоки: Kubernetes: за и против; Data Science & Machine Learning; DevOps.
На HighLoad++ в Москве, которая уже 8 и 9 ноября, будет еще больше интересного. В программе доклады обо всех аспектах работы над высоконагруженными проектами, мастер-классы, митапы и мероприятия от партнеров, которые поделятся экспертными советами и найдут, чем удивить. О самом интересном обязательно напишем и оповестим в рассылке, подключайтесь!
