PRFRL — как устроен интерфейс аналитики
В этом посте хотелось бы рассказать больше про концепцию панели аналитики. Собственно именно она дает разработчикам уникальные возможности для поиска проблемных по производительности мест в коде. PRFLR — это система аналитики, направленная на скорейшее обнаружения проблемных по производительности мест в работе приложений. Realtime и непосредственно на Production серверах.
В первую очередь PRFLR ориентирован на высоконагруженные серверные приложения работающие на больших кластерах, однако применим для небольших проектов, десктоп и мобильных приложений. Конечно если вас действительно волнует вопрос их быстродействия.
Концепция Весь наш опыт работы над hiload проектами говорит что 80% времени пожирают 2–3 слабых места в системе, устранив которые можно добиться существенного прироста скорости работы. Поэтому весь процесс заключается в сравнении скорости работы различных кусков кода и выделения самых медленных.Для того чтобы понять время выполнения куска кода мы используем timers — это сущность которая знает как называется код, знает в каком окружении он выполняется и сколько времени это заняло. К примеру: [ mysite.ru, dellete_user_from_db, 0,03s ] Накапив такие таймеры за достаточное продолжительное время мы можем начать анализировать эти данные.
Чтобы выявить бутылочные горлышки, по сути нам надо просто взять список таймеров и отсортировать его по какому либо интересующему нас параметру, к примеру по максимальному времени выполнения. Такой подход стал основой интерфейса панели управления. Поглядим на интерфейс поближе.
RAW Timers
Первый экран — это просто сырой поток таймеров, где можно увидеть, работает ли код вообще:) На скрине видно все 5ь параметров таймера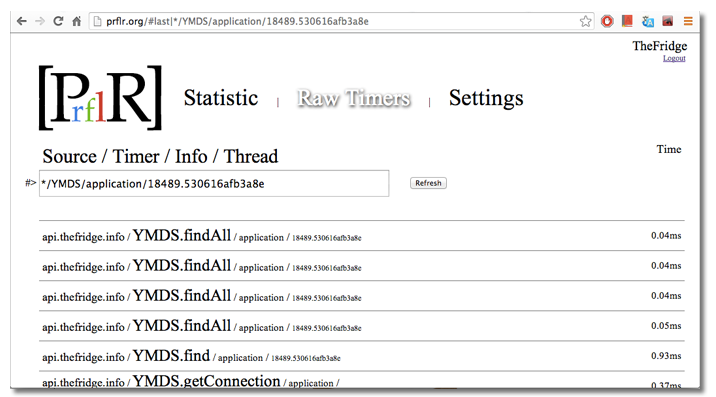
Source — источник таймера. Может быть сайт, ip, имя приложения Timer — название таймера. Понятное вам название куска кода. Обычно задается так чтобы совпадало с функцией / классом.методом Info- дополнительная информация о таймере, к примеру результат выполнения функции, версия API, автор последнего комита :) Thread — тред в котором выполнялся таймер, сильно помогает при анализе единичных затупов в коде. Время — это миллисекунды показывающие еденичное выполнение таймера. Глядя на этот скрин, видно, что последним в системе выполнились 4 запроса к MongoDB. 3 — за 0.04ms, а один за 0.05ms
Вверху списка таймеров находится строка поиска. Думаю ее синтаксис и назначение объяснять не надо, все тривиально. Каждое значение работает как поиск по подстроке в соответствующем параметре таймера.
Statistic
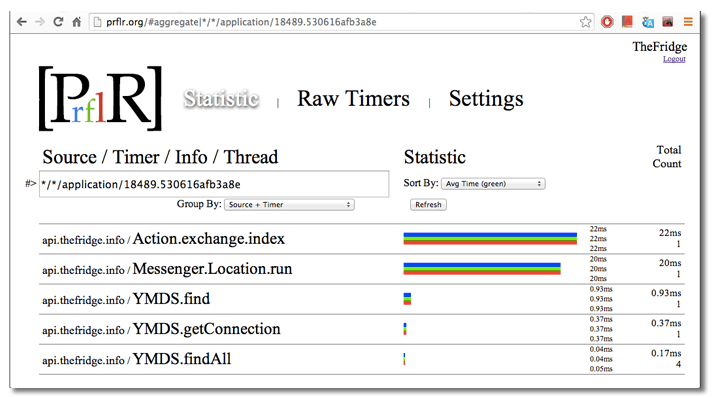
Наконец мы добрались до самого главного раздела обработки статистики. На нем видны те же таймеры, строка поиска. Для каждого таймера выведена накопленная статистика.
Доступны следующие значения:
min, avr, max — соответвтвено минимальное, среднее и максимальное время выполнения таймера count — общее количество таймеров total — суммарное время выполнения всех таймеров этого типа Под строкой поиска есть селектор группировки таймеров. Можно сгруппировать по источник, имени таймера или по тому+другому вместе. Это сильно помогает при анализе.
И как этим пользоваться? Встроив SDK в приложение и убедившись что таймеры начали поступать в PRFLR, можно начать смотреть срезы статистики и сортировать по различным параметрам.
К примеру введя в строку поиска занчение » */mongo/*/* » — мы получим все таймеры относящиеся к работе с mongoDB. Переключая селектор группировки мы может ответить сразу на 3 вопроса:
source — на каком сервере работа с mongoDB идет наиболее медленно timer — какой запрос наиболее проблемный в системе в целом source+timer — поглядеть на каком конкретно сервере какой запрос рабоатет плохо Последний вариант группировки иногда дает слишком много данных, поэтому удобней дофильтровать данные по конкретному серверу, указав имя сервера в строке поиска.
Обычно есть несколько типовых срезов статистики: сравнить сервера между собой, поглядеть работы отдельного модуля внутри, поглядеть как модуль работает на разных серверах, выбрать все и поглядеть что тупит и жрет ресурсы.
А как вы сами этим пользуетесь? PRFLR начал делаться давно, но наиболее серьезно его применили для анализа географичечки распределенного серверного бекенда одного мобильного приложения. Сервера стояли в 5х разных дата-центрах на 3х континентах. И каждый сервер был уникальным по железу. От 8 ядерного ксенона с 32 гб оперативки, до виртуалки с 500 мб памяти. Буквально за несколько дней мы нашли и исправили почти все косяки в производительности. А регулярный анализ работы после каждого релиза не позволяет появиться новым проблемам.
По опыту можем уверять — если вы даже не очень глубоко понимаете архитектуру исследуемого ПО, но на практически доскональный анализ в плане производительности у вас уйдет около 30 минут, даже если система состоит из десятков модулей и работает на 10–20 серверах.
Повторный анализ поле релизов — займет минут 5. А ведь это именно то что нужно — давать нужную аналитику и за максимально короткий период времени.
