Потоковая обработка данных с помощью Kafka Streams: архитектура и ключевые концепции
При реализации потоковой обработки и анализа данных может возникнуть необходимость агрегирования записей для объединения нескольких независимых поток данных или обогащения какой-либо модели данных. Для этой цели может использоваться Kafka Streams, которая позволяет выполнять обработку данных в режиме реального времени.
В этой статье мы рассмотрим основные компоненты Kafka Streams и теоретические аспекты их использования. Мы будем использовать последние версии технологий, доступных на сегодня: Kafka 3.4.0 и Java 17 в качестве языка программированию. Для снижения входного порога мы будем использовать только нативные возможности Kafka и Kafka Streams, и не будем рассматривать решения с использованием различных фрейморков вроде Spring.
Для кого предназначена эта статья:
Вы профессионально используете язык Java в своей работе или имеете опыт с другими JVM-подобными языками программирования.
Вы имеете базовые представления и опыт работы с Apache Kafka.
Вы хотите разобраться в реализации потокой обработки данных с помощью Kafka Streams.
Эта статья направленна на профессиональных инженеров-программистов, имеющих обширный опыт промышленной разработки корпоративных приложений. Однако начинающие свой путь в разработке также смогут найти для себя много полезного в этом материале при условии предварительного знакомства с Java и Kafka.
Основные концепции Kafka Streams
Давайте начнем рассмотрение основных концепций и возможностей Kafka Streams. Мы предполагаем, что читатель имеет предварительный опыт работы с Apache Kafka, поэтому мы будем использовать сравнения и аналогии между этими двумя системами, так как они используют крайне схожие концепции.
Также важно упомянуть, что в экосистеме Kafka есть два решения для потоковой обработки данных — Kafka Streams и KSQL. Это два разных способа анализа данных в Kafka, у каждого из которых есть свои преимущества и разные сценарии использования.
Kafka Streams — это клиентская библиотека для создания приложений, где входные и выходные данные хранятся в кластерах Kafka. Она сочетает в себе простоту написания и развертывания стандартных приложений на стороне клиента с преимуществами технологий кластера Kafka на стороне сервера:
Нативный API для Java/Scala и других языков: Kafka Streams реализована как обычная библиотека для Java/Scala. Таким образом, любой разработчик на Java/Scala может использовать его в своих приложениях.
Гибкость кода: Поскольку Kafka Streams позволяет работать непосредственно с программным кодом, это может обеспечить более тонкий уровень контроля. Вы можете выполнять сложные преобразования или объединения, которые может быть сложно выразить в SQL.
Обработка с сохранением и без сохранения состояния: Kafka Streams поддерживает множество операций преобразования, как без сохранения состояния (например,
mapиfilter), так и с сохранением состояния (например,join,aggregate,window).
KSQL — это потоковый SQL движок обработки данных в реальном времени для Apache Kafka. Он предоставляет простой в использовании, но мощный и интерактивный SQL интерфейс для потоковой обработки, без необходимости писать код на языках программирования.
Главные преимущества KSQL:
SQL-подобный синтаксис: Многие люди уже знакомы с SQL, что делает KSQL более доступным для них, чем написание кода на Java/Scala или других языках.
Интерактивные запросы: KSQL поддерживает множество возможностей, начиная от простых запросов к данным Kafka топика, до объединения потоков/таблиц, агрегаций и оконной обработки в реальном времени.
Непрерывная обработка в реальном времени: Как и Kafka Streams, KSQL позволяет выполнять непрерывные запросы, которые генерируют результаты по мере поступления данных в Kafka топик.
В этой статье мы сконцентрируемся на рассмотрении концепций Kafka Streams.
Архитектура Kafka Streams
Kafka Streams представляет собой клиентскую библиотеку, которая работает параллельно уже существующим API: для потребителя (Consumer), производителя (Producer) и интеграций с внешними системами (Connect).
Consumer API — интерфейс для потребителя событий, предназначенный для чтения записей из Kafka топика.
Producer API — интерфейс для производителями событий, предназначенный для записи данных в Kafka топик.
Connect API — интерфейс который обеспечивает подключение к внешним системам хранения данных, таким как базы данных, позволяя переносить данные в Kafka топики или из них.
Kafka Streams предоставляет высокоуровневый API, который является надстройкой над более низкоуровневыми интерфейсами Apache Kafka. Он позволяет разработчикам писать код в декларативном стиле, вместо императивного программирования с использованием Consumer и Producer APIs.
Как следствие, Kafka Streams позволяет уменьшить количество boilerplate-кода, сосредоточившись на декларативном определении операций потоковой обработки, таких как фильтрация, преобразование, агрегация и объединение данных, используя простые и понятные методы высокоуровневого API Kafka Streams.
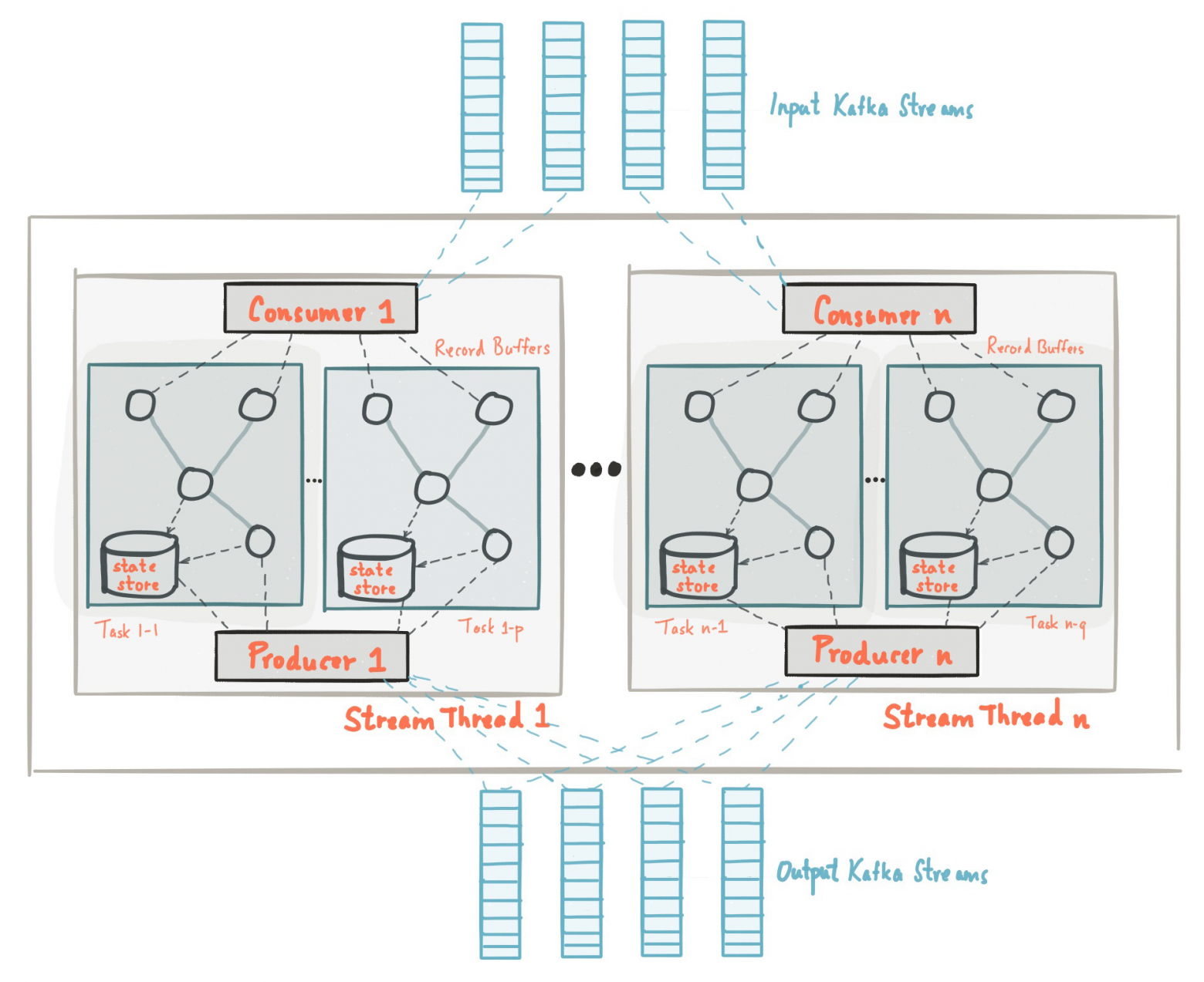
Kafka Streams состоит из следующих ключевых компонентов:
Топология: Топология представляет собой ориентированный ациклический граф обработки потока, который состоит из источников, процессоров и хранилищ состояния. Топология определяет, как данные будут обрабатываться и перемещаться по системе.
KStream: KStream представляет собой поток записей, где каждая запись представляет собой пару ключ-значение. KStream в общем случае используется для представления данных в режиме реального времени.
KTable: KTable представляет собой поток записей, которые представляют собой снимок состояния в определенный момент времени. Каждый ключ в KTable связан с наиболее актуальным значением. Когда новая запись с существующим ключом добавляется в KTable, старая запись заменяется новой.
GlobalKTable: GlobalKTable аналогичен KTable, но данные в GlobalKTable реплицируются во все экземпляры приложения, в отличие от KTable, где данные распределяются по различным экземплярам приложения.
State Stores: Состояние приложения, такое как KTable и окна, помещается в хранилища состояний. Эти хранилища могут быть персистентными или не персистентными, и они могут быть отключены для операций, которые не требуют сохранения состояния.
Stream Processors: Процессоры используются для выполнения пользовательской логики обработки. Вы можете определить свои собственные процессоры и связать их с KStream или KTable.
Serdes: Serde является аббревиатурой для сериализации (serialization) и десериализации (deserialization). В Kafka Streams вы используете Serdes для указания того, как данные должны быть преобразованы в байты для хранения в Kafka, и как эти байты должны быть преобразованы обратно в данные при чтении из Kafka.
Топология
Топология в Kafka Streams — это набор из источников (source), процессоров (processor), синхронизаторов (sink) и хранилищ состояния (state store). Эти компоненты вместе образуют ориентированный ациклический граф обработки данных, который определяет поток данных от источников к процессорам и дальше, к хранилищам состояний и/или к другим процессорам.
Ориентированный ациклический граф (направленный ациклический граф, DAG от англ. directed acyclic graph) — орграф, в котором отсутствуют направленные циклы, но могут быть «параллельные» пути, выходящие из одного узла и разными путями приходящие в конечный узел. Направленный ациклический граф является обобщением дерева (точнее, их объединения — леса).
Источник: Directed acyclic graph

Топология может состоять из следующих компонентов:
Топология может состоять из следующих компонентов:
Источник (Source Processor): Источник — это точка входа в топологию, из которой считываются данные, чем обычно являются Kafka топики.
Потоковый процессор (Stream Processor): Потоковые процессоры — это узлы в топологии, которые обрабатывают данные. Они могут выполнять различные операции, такие как фильтрация, преобразование и агрегации данных.
Хранилища состояния (State Store): Хранилища состояния позволяют процессорам сохранять и извлекать данные. Это полезно для операций, которые требуют знания о предыдущем состоянии, например, для агрегации или join операций.
Синхронизатор (Sink Processor): Синхронизатор отправляет полученные записи от его верхнеуровневого процесса в указанный Kafka топик.
Источник (Source Processor)
Источник (Source Processor) в Kafka Streams — это особый тип узла в топологии, который служит в качестве начальной точки потока данных. Он отвечает за чтение данных из определенных Kafka топиков и отправку этих данных на обработку в другие узлы топологии — потоковые процессоры (Stream Processors).
Когда вы создаете поток (KStream или KTable) из топика в Kafka с помощью метода stream или table класса StreamsBuilder, под капотом Kafka Streams API создает источник.
Пример создания источника с помощью Kafka Streams DSL:
// Creating a topology
StreamsBuilder builder = new StreamsBuilder();
// Reading data from the "input-topic" Kafka topic to a KStream (source)
KStream sourceStream = builder.stream("input-topic", Consumed.with(Serdes.String(), Serdes.String())); В этом коде builder.stream("input-topic") создает источник, который считывает данные из Kafka топика с именем «input-topic». Результатом является KStream — объект, который представляет собой поток данных в Kafka Streams. В этом потоке каждый элемент данных представляет собой пару «ключ-значение», прочитанную из топика «input-topic».
Стоит отметить, что типы ключа и значения в KStream должны соответствовать типам ключа и значения в теме Kafka. В этом примере предполагается, что и ключ, и значение в теме «input-topic» являются строками, поэтому мы использует подходящие String SerDes (Serializer/Deserializer) при создании источника.
Источник — это неизменяемая и начальная точка в топологии потоковой обработки. Он не имеет предыдущих обработчиков и ассоциируется с одним или несколькими Kafka топиками для чтения данных.
Потоковый процессор (Stream Processor)
Потоковый процессор (Stream Processor) — это ключевой компонент в обработке данных, представляющий собой узел в топологии, который берет данные, проходящие через него, и выполняет над ними различные операции. В зависимости от требований приложения, эти операции могут быть очень разнообразными, начиная от простых преобразований до сложных агрегаций.
Рассмотрим некоторые примеры того, что могут делать потоковые процессоры:
Фильтрация:
Потоковые процессоры могут быть использованы для фильтрации данных. Например, они могут отфильтровывать только те записи, которые удовлетворяют определенному условию.
Пример фильтрации потока транзакций, чтобы получить только те из них, которые превышают определенную сумму.
// Creating a topology
StreamsBuilder builder = new StreamsBuilder();
// Reading data from the "transactions-topic" Kafka topic to a KStream (source)
KStream transactions = builder.stream("transactions-topic", Consumed.with(Serdes.String(), Serdes.Double()));
// Filtering transactions
KStream largeTransactions = transactions.filter((id, transaction) -> transaction.getAmount() > 1000.00); В этом примере мы отбираем только те транзакции, сумма которых превышает 1000.00.
Преобразование:
Потоковые процессоры могут преобразовывать данные и Kafka Streams предоставляет два метода для этой операции — map и mapValues . Они позволяют применять функцию преобразования к каждому элементу в потоке данных, но есть разница в том, как они применяются и какие данные они обрабатывают.
В подавляющем числе случаев стоит использовать mapValues — этот метод применяет функцию преобразования только к значению каждой записи в потоке данных и возвращает новую запись с измененным значением.
Например, вы можете преобразовать поток чисел представляющих сумму транзакции в поток строк, содержащих описание транзакции.
// Creating a topology
StreamsBuilder builder = new StreamsBuilder();
// Reading data from the "transactions-topic" Kafka topic to a KStream (source)
KStream transactions = builder.stream("transactions-topic", Consumed.with(Serdes.String(), Serdes.Double()));
// Mapping transactions
KStream transactionEventDescriptions = transactions.mapValues((userId, transactionValue) -> {
return String.format("User %s has made a transaction of $%s", userId, transactionValue);
}); В этом примере мы преобразовали каждую транзакцию в строку, описывающую транзакцию. Результатом этого вызова будет поток, где каждая запись содержит значение в виде строки с описанием транзакции пользователя.
Ключи записей в потоке данных при этом остаются неизменными, благодаря чему mapValues не оказывает влияния на перераспределение данных (repartitioning) — это позволяет избежать нежелательных побочных эффектов, влияющих на производительность нашего приложения.
Repartitioning (перераспределение данных) может возникнуть в Kafka Streams в следующих случаях:
Изменение ключа: Если операция преобразования изменяет ключ записи, то Kafka Streams должен перераспределить данные, чтобы гарантировать, что записи с одинаковыми ключами попадают в одну и ту же партицию. Например, при использовании операции
mapдля изменения ключа записи.Изменение топологии: Если вы меняете топологию вашего Kafka Streams приложения, добавляете новые операции или меняете конфигурацию группы потоков, то возможно потребуется перераспределение данных для соответствия новой конфигурации.
Изменение числа партиций топика: Если число партиций во входном или выходном топике изменяется, Kafka Streams может автоматически перераспределить данные, чтобы отражать новое количество партиций.
Перераспределение данных может повлиять на производительность приложения, поскольку требуется перемещение данных между брокерами. Поэтому, при проектировании приложения с использованием Kafka Streams, рекомендуется учитывать возможность перераспределения данных и стремиться к минимизации его частоты, особенно в критических по производительности сценариях.
В отличие от mapValues, метод map может изменять и ключ, и значение записи. Этот метод применяет функцию к каждому элементу записи в потоке данных и возвращает новую запись с измененным ключом и/или значением. Кроме этого, применение метода map может изменить размер ключа, что также может повлиять на перераспределение данных (repartitioning).
Пример использования метода map для прошлого кейса:
// Creating a topology
StreamsBuilder builder = new StreamsBuilder();
// Reading data from the "transactions-topic" Kafka topic to a KStream (source)
// where the key is the user ID, and the value is the transaction amount
KStream transactions = builder.stream("transactions-topic", Consumed.with(Serdes.String(), Serdes.Double()));
// Mapping transactions
KStream transactionEventDescriptions = transactions.map((userId, transactionValue) -> {
String message = String.format("User %s has made a transaction of $%s", userId, transactionValue);
return KeyValue.pair(userId, message);
}); Оба этих примера демонстрируют использование операций map и mapValues для преобразования данных. Однако стоит еще раз упомянуть, что метод map может значительно влиять на производительность приложения и его стоит использовать только в случае, когда есть обоснованная причина для изменения ключа записей в потоке данных.
Агрегация:
Потоковые процессоры могут агрегировать данные. Например, вы можете агрегировать поток транзакций для получения количества транзакций для каждого пользователя:
// Creating a topology
StreamsBuilder builder = new StreamsBuilder();
// Reading data from the "transactions-topic" Kafka topic to a KStream (source)
// where the key is the user ID, and the value is the transaction amount
KStream transactions = builder.stream("transactions-topic", Consumed.with(Serdes.String(), Serdes.Double()));
// Count the records grouped by key
KTable transactionCounts = transactions.groupByKey().count(); В этом примере, мы используем groupByKey() для группировки транзакций по userId, а затем count() для подсчета количества транзакций для каждого пользователя. Результатом является KTable , про которую мы поговорим в следующих разделах, где каждому userId соответствует количество его транзакций.
Это примеры базовых операций над потоками в Kafka Streams, которые можно комбинировать и строить более сложные логики потоковой обработки.
Синхронизатор (Sink Processor)
Синхронизатор (Sink Processor) — это узел в топологии обработки данных, который отвечает за отправку обработанных данных в Kafka топик. Он представляет собой конечную точку в потоке обработки данных и не имеет нижестоящих процессоров.
Пример создания Sink Processor в Kafka Streams DSL:
// Creating a topology
StreamsBuilder builder = new StreamsBuilder();
// Creating a Source Processor
KStream transactions = builder.stream("transactions-topic", Consumed.with(Serdes.String(), Serdes.Double()));
// Filtering transactions
KStream largeTransactions = transactions.filter((id, transaction) -> transaction.getAmount() > 1000.00);
// Creating a Sink Processor, which sends data to the output Kafka topic
largeTransactions.to("large-transactions-topic"); В этом примере мы создали Sink Processor, отправляющий данные в Kafka топик «large-transactions-topic». Этот топик будет содержать только транзакции, сумма которых превышает 1000.
Хранилища состояний (State Stores)
Хранилища состояний (State Stores) в Kafka Streams представляют собой механизмы, позволяющие потоковым процессорам (Stream Processors) хранить и извлекать состояние в процессе обработки данных. Это необходимо в сценариях, где операции обработки требуют знания о предыдущем состоянии, например, для операций агрегации или join. При использовании Kafka Streams DSL, такие хранилища состояний создаются автоматически, когда вы вызываете операторы, требующие хранения состояния, такие как count () или aggregate (), или когда вы выполняете оконное разбиение потока.

Каждая потоковая задача в приложении Kafka Streams может включать одно или несколько локальных хранилищ состояний. Эти хранилища состояний могут быть базой данных RocksDB, хеш-таблицей в памяти или другой удобной структурой данных.
По-умолчанию, Kafka Streams использует RocksDB как хранилище состояния. Это встроенное хранилище состояния, поэтому процесс записи не связан с сетевыми вызовами, что устраняет риск потенциального сбоя, который создал бы препятствия в потоковой обработке. RocksDB хранит данные в формате ключ/значение, сохраняя записи как байтовые представления, что гарантирует высокую скорость чтения и записи. Персистентность при этом обеспечивается асинхронной записью данных на диск.
Таблицы (KTable)
KTable в Kafka Streams –—это фактически представление потока данных в форме таблицы, которое обновляется при поступлении каждой новой записи. Все обновления в KTable могут быть рассмотрены как упорядоченные записи в журнале изменений, где ключ становится идентификатором, а связанное с ним значение представляет собой новое состояние этого ключа.
Основной принцип работы KTable заключается в том, что она отслеживает последнее известное состояние каждого ключа. Если поступает новая запись с ключом, который уже присутствует в KTable, старое значение обновляется новым. Если ключ отсутствует, он просто добавляется в таблицу вместе со своим значением. Это реализация так называемого upsert — insert + update.
Такая структура особенно важна при работе с агрегированными данными. Например, если вы хотите подсчитать общее количество событий для каждого ключа, KTable будет хранить текущий общий счет для каждого ключа и обновлять его по мере поступления новых данных. Аналогично, результаты операций объединения (join) между различными потоками данных также могут быть представлены в виде KTable.
KTable, таким образом, является материализованным представлением потока, обеспечивающим структурированное представление входящих данных. Однако стоит помнить, что KTable не равна таблице в реляционной базе данных по своему функционалу и является всего лишь абстракцией над потоком в Kafka Streams. Несмотря на свой мощный функционал, KTable — это, в первую очередь, инструмент потоковой обработки и не полностью подходит для хранения данных в его классическом понимании.
В Kafka Streams существует несколько способов создания KTable. Ранее мы уже рассмотрели создание KTable из KStream через операцию агрегации. Это самый распространенный способ, так как он позволяет преобразовывать и агрегировать данные «на лету».
Давайте рассмотрим и другие способы создания KTable:
1. Использование метода stream и toTable
Данный метод практически аналогичен нашему примеру с аггрегацией. Здесь мы также создаем KTable из KStream, но с более явным синтаксисом. Все записи в топике Kafka будут обрабатываться как упорядоченные записи в KTable.
// Creating a topology
StreamsBuilder builder = new StreamsBuilder();
// Creating a KTable from KStream
KTable table = builder.stream("transactions-topic", Consumed.with(Serdes.String(), Serdes.String())).toTable(); 2. Использование метода table
Данный метод позволяет создать KTable напрямую из Kafka топика.
// Creating a topology
StreamsBuilder builder = new StreamsBuilder();
// Creating a KTable directly from the Kafka topic
KTable table = builder.table("transactions-topic", Consumed.with(Serdes.String(), Serdes.String())); Основное отличие между stream().toTable() и table() заключается в том, как они обрабатывают записи в начале потока при старте приложения. stream().toTable() преобразует каждую запись в потоке в упорядоченную запись в таблице, в то время как table() игнорирует все записи, которые были записаны до последнего обновления каждого ключа.
3. Использование глобальных таблиц
Глобальные таблицы в Kafka Streams — это вариация KTable, которые хранят данные из всех партиций, в отличие от обычных KTable, которые хранят данные только из соответствующих партиций. Глобальные таблицы полезны для данных справочного типа, которые должны быть доступны на всех узлах обработки.
// Creating a topology
StreamsBuilder builder = new StreamsBuilder();
// Creating a GlobalKTable directly from the Kafka topic
GlobalKTable globalTable = builder.globalTable("topic", Consumed.with(Serdes.String(), Serdes.String())); При выборе способа создания KTable стоит учесть различные факторы, такие как формат исходных данных, требуемая производительность и требуемые семантики обработки.
Кроме этого, KTables могут быть объединены вместе, подобно тому, как таблицы объединяются в SQL. Рассмотрим, к примеру, две таблицы: одну с информацией о пользователях и другую с информацией о транзакциях пользователя. Мы могли бы объединить эти две KTables вместе, чтобы получить полную информацию о каждой покупке следующим образом:
// Creating a topology
StreamsBuilder builder = new StreamsBuilder();
// Creating a KTable directly from the "transactions-topic" Kafka topic
KTable transactions = builder.table("transactions-topic", Consumed.with(Serdes.String(), Serdes.String()));
// Creating another KTable from the "users-topic" Kafka topic
KTable users = builder.table("users-topic", Consumed.with(Serdes.String(), Serdes.String()));
// Joining the two KTables together
// We now have a KTable where each key is a user ID, and each value is the combined user info and transaction
KTable joined = users.join(transactions, (userInfo, transaction) -> userInfo + ": " + transaction); Здесь KTable — это новая таблицы, которая объединяет информацию о пользователе и его транзакциях вместе.
Особенности KTable и State Stores
KTable и хранилища состояний в Kafka Streams являются мощными, но при этом достаточно сложными инструментами. Для их эффективного использования важно понимать особенности, которые могут значительно влиять на производительность вашего приложения. Рассмотрим основные из них:
Кэширование
Kafka Streams использует механизм кэширования для сглаживания нагрузки на бэкенд, то есть уменьшения количества операций записи. Он объединяет обновления для одного и того же ключа в KTable вместе и записывает только самое последнее обновление в кэш. Затем записи из кэша записываются в KTable периодически или когда кэш заполняется.
Это может существенно уменьшить количество операций записи и улучшить производительность обработки потока, особенно когда у вас есть частые обновления одного и того же ключа. Однако это также означает, что есть некоторая задержка между тем, как обновление происходит в исходном потоке, и когда оно видимо в KTable.
Томбстоуны
Томбстоны в Kafka являются специальным типом записей, которые используются для указания на то, что ключ был удален. В контексте KTable, запись с null значением считается томбстоуном и при ее обработке ключ удаляется из KTable.
Это удобно для отслеживания удалений в исходных данных и автоматического обновления состояния KTable соответствующим образом. Однако стоит помнить, что томбстоуны также передаются в нижестоящие потоки, и при обработке томбстоунов в этих потоках ключ также будет удален.
Хранение состояния
KTable использует хранилище состояния для материализации своих данных. Это хранилище обычно размещается локально на том же узле, что и поток Kafka Streams, и может быть реализовано с использованием различных механизмов, таких как RocksDB или In-Memory Store. Как мы обсуждали ранее, это хранилище состояния обновляется каждый раз, когда поступает новая запись в KTable, и может быть использовано для выполнения интерактивных запросов к текущему состоянию KTable.
Обратите внимание, что хотя KTable в некотором роде похож на таблицу в реляционной базе данных, он имеет свои собственные особенности и ограничения. В частности, он не предназначен для выполнения произвольных запросов на чтение или запись, как это может быть с таблицами в реляционной базе данных. Вместо этого, он оптимизирован для потоковой обработки данных, где состояние обновляется в реальном времени по мере поступления новых данных.
Интерактивные запросы к KTable
Кроме вышеописанных операций, Kafka Streams поддерживает интерактивные запросы, которые позволяют извлекать данные из KTable непосредственно. Интерактивные запросы в Kafka Streams позволяют приложениям напрямую запросить текущее состояние локально хранимых KTables или глобальных GlobalKTables.
Когда вы создаете KTable или используете операции, такие как groupByKey() или windowedBy(), Kafka Streams материализует (сохраняет) промежуточное состояние в локальном хранилище состояния, которое является инстанцией RocksDB по-умолчанию. Это хранилище состояния обновляется каждый раз, когда поступает новая запись в соответствующую KTable. Таким образом, вы можете считать это хранилище состояния как кэш последнего известного состояния KTable.
Когда вы делаете интерактивный запрос к KTable, вы на самом деле запрашиваете это локальное хранилище состояния. Вместо того чтобы вычитывать все данные из топика Kafka и фильтровать их для получения конкретного значения по ключу, интерактивный запрос просто получает значение из локального хранилища состояния по ключу, что намного более эффективно.
Если KTable распределена между несколькими узлами в кластере Kafka Streams, каждый узел будет хранить только часть состояния KTable. В таком случае, вам потребуется найти узел, который хранит значение для интересующего вас ключа. В Kafka Streams есть встроенные механизмы для обнаружения узлов и маршрутизации запросов, чтобы облегчить вам эту задачу.
Однако, стоит отметить, что, несмотря на то что операция чтения из локального хранилища состояния является быстрой, запись в него может вносить некоторую задержку в обработку потока, так как Kafka Streams должен обновлять состояние каждый раз, когда поступает новая запись.
В этом разделе мы сосредоточимся на рассмотрении интерактивных запросов. Все решения по конфигурации Kafka и поднятию соответствующей инфраструктуры будут оставлены за рамками этой статьи для упрощения.
Пример использования интерактивных запросов:
package com.example;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StoreQueryParameters;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.kstream.Consumed;
import org.apache.kafka.streams.kstream.Materialized;
import org.apache.kafka.streams.state.QueryableStoreTypes;
import org.apache.kafka.streams.state.ReadOnlyKeyValueStore;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
public class KTableInteractiveQueriesExample {
public static void main(String[] args) {
// Kafka Streams Configuration
Properties config = new Properties();
config.put("application.id", "ktable-interactive-queries-example");
config.put("bootstrap.servers", "localhost:9092");
config.put("default.key.serde", Serdes.String().getClass());
config.put("default.value.serde", Serdes.String().getClass());
// Define the processing topology
StreamsBuilder builder = new StreamsBuilder();
// Create a KTable from the 'transactions-topic'
// Record key is a user id and the record value is a transaction amount
builder.table("transactions-topic", Consumed.with(Serdes.String(), Serdes.String()), Materialized.as("transaction-store"));
// Build the Kafka Streams application
KafkaStreams streams = new KafkaStreams(builder.build(), config);
// Latch to wait for streams to be in RUNNING state
final CountDownLatch latch = new CountDownLatch(1);
// State listener to listen for a transition to RUNNING state
streams.setStateListener((newState, oldState) -> {
if (newState == KafkaStreams.State.RUNNING && oldState != KafkaStreams.State.RUNNING) {
latch.countDown();
}
});
// Start the Kafka Streams application
streams.start();
// Wait for the streams to be in the RUNNING state
try {
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
Thread.currentThread().interrupt();
}
// Define the store query parameters
StoreQueryParameters> storeQueryParameters = StoreQueryParameters.fromNameAndType(
"transaction-store", QueryableStoreTypes.keyValueStore());
// Fetch our store
ReadOnlyKeyValueStore keyValueStore = streams.store(storeQueryParameters);
// We can now query the store directly for a user's transaction
String userId = "1";
// Get the transaction amount for the user with id '1'
String transaction = keyValueStore.get(userId);
// Print the result
System.out.println("Transaction amount for user with id " + userId + " is: " + transaction);
// Always close the Kafka Streams instance when you are done
streams.close();
}
}
Настройка зависимостей для данного примера с помощью Maven в pom.xml:
4.0.0
com.example
kafka-streams-basic-example
1.0-SNAPSHOT
17
17
UTF-8
3.4.0
org.apache.kafka
kafka-streams
${kafka.version}
org.apache.maven.plugins
maven-surefire-plugin
2.22.0
Давайте пошагово разберем наш пример:
В методе
mainмы начинаем с созданияPropertiesобъекта для конфигурации нашего Kafka Streams приложения. Это включает в себя идентификатор приложения, адрес Kafka брокеров, а также классы для сериализации и десериализации ключей и значений. Вам необходимо поменять адрес Kafka брокера в переменной «bootstrap.servers», если в вашем случае он отличается от «localhost:9092».Затем мы создаем
StreamsBuilder, который является основой для определения нашего топологии обработки.С помощью
StreamsBuilder, мы создаемKTableиз топика Kafkatransactions-topic.Consumed.with(Serdes.String(), Serdes.String())определяет, что ключи и значения в этой теме сериализуются и десериализуются как строки.Materialized.as("transaction-store")задает имя для хранилища состояния, связанного с этим KTable. Создания Kafka топикаtransactions-topicи добавление в него значений также необходимо выполнить на вашей стороне.KafkaStreamsобъект создается с помощью топологии, которую мы определили сStreamsBuilder, и нашей конфигурации.CountDownLatchиспользуется для блокировки основного потока до тех пор, пока приложение Kafka Streams не будет готово обрабатывать запросы к состоянию.StateListenerиспользуется для слежения за изменениями состояния приложения Kafka Streams. Когда состояние переходит вRUNNING, отсчет возвращается, освобождая основной поток.Мы начинаем наше приложение Kafka Streams, затем ждем, пока оно не перейдет в состояние
RUNNING.StoreQueryParametersобъект создается для нашего запроса к хранилищу состояния.Мы получаем наше хранилище состояния с помощью
streams.store(storeQueryParameters)и сохраняем его в переменнуюkeyValueStore.Далее мы можем запросить наше хранилище состояния напрямую, чтобы получить транзакцию пользователя с идентификатором
1.Результат выводится на экран и мы закрываем наше приложение Kafka Streams.
Это полный цикл обработки потока с использованием Kafka Streams, от чтения данных из темы Kafka до выполнения интерактивных запросов к сохраненному состоянию. Пожалуйста учитывайте, что это учебный пример и реальное промышленное решения для потоковой обработки данных будет выглядеть гораздо сложнее.
Для запуска приложения необходимо выполнить следующую команду:
mvn clean install && mvn exec:java -Dexec.mainClass="com.example.KTableInteractiveQueriesExample"Kafka топик в нашем случае будет содержать следующие значения:

Kafka топик «transactions-topic», где ключом является идентификатор пользователя, а значение — сумма его транзакций
Результатом работы нашей программы будет следующая запись в логе:
17:22:58.345 [ktable-interactive-queries-example-4b56a7e5-a5f1-4f6b-a270-b671e44d7b87-StreamThread-1] INFO o.a.k.clients.consumer.KafkaConsumer - [Consumer clientId=ktable-interactive-queries-example-4b56a7e5-a5f1-4f6b-a270-b671e44d7b87-StreamThread-1-consumer, groupId=ktable-interactive-queries-example] Requesting the log end offset for transactions-topic-0 in order to compute lag
Transaction amount for user with id 1 is: 150.00В нашем Kafka топике было две записи с id пользователя равным 1 со значениями 100.00 и 150.00. Как мы помним при использовании KTable в хранилище состояние записывается самое последнее значение, соответствующее определенному ключу. Поэтому нам вернулось значение 150.00, так как оно является более поздним.
В заключение, стоит отметить, что интерактивные запросы работают только в рамках одного Kafka Streams приложения и не могут быть использованы для извлечения данных между различными приложениями.
Заключение
В этой статье мы рассмотрели основные концепции и архитектуру Kafka Streams. Мы разобрались с различными примерами потоковой обработки с данных с помощью KStreams и KTables, рассмотрели операциями фильтрации, преобразования и агрегирования данных. Рассмотрели создания разных типов процессоров, разобрались с устройством KTable и хранилищ состояний. В заключение мы рассмотрели пример реализации Kafka Streams приложения и использования интерактивных запросов для выгрузки данных из хранилища состояния.
Стоит отметить, что Kafka Streams предлагает ряд продвинутых функций, которые могут быть необходимы в более сложных сценариях промышленной разработки. Это включает в себя гарантированную единичную обработку (exactly-once processing), обратный вызов (backpressure), расширенные возможности тестирования, а также встроенную поддержку для обработки таблиц.
С помощью Kafka Streams можно организовать обработку данных на нескольких уровнях параллелизма, что позволяет масштабировать приложения горизонтально для обработки больших объемов данных. Интеграция с Kafka Connect позволяет легко подключать различные источники данных и
