Построение словаря текста на примере NLP библиотеки AIF
Так уж повелось, что каждый релиз лингво-независимой библиотеки обработки естественных текстов AIF сопровождается заметкой о том, что было сделано и как все работает. Подобные тексты о предыдущих двух релизах Alpha1 и Alpha2 можно найти вот тут и тут. Не исключением из этого правила стал и текущей релиз Alpha3, в котором появилась возможность строить словарь токенов для входного текста. О том, как все работает под капотом и как это можно использовать в своём проекте и пойдёт сегодня речь.Немного терминовТермины введены не совсем в соответствии с их каноническим значением, а согласно тому смыслу, который они несут в этом тексте (и на сайте проекта). Полный список терминов можно найти тут
Токен — последовательность символов алфавита, ограниченных с двух сторон разделительными символами. Язык — все множество уникальных токенов. Язык текста — множество всех возможных уникальных токенов присутствующих в тексте. Слово — подмножество языка, в которое входят токены, схожее между собой. Синтаксическое слово — подмножество языка, в которое входят токены, имеющие схожий контекст использования. Словарь текста — множество всех возможных слов, построенных на базе языка текста. Сегодня мы будем говорить о «простом» слове, а не семантическом. Построение семантических связей в тексте и словаря семантических слов текста — это задача следующего релиза.
«Схожесть» токенов
Легко заметить, что некоторые термины являются неполными и требуют некоторых уточнений для их практического использования. Так, например, термин «слово» требует разъяснения того, что такое похожесть токенов. В нашей статье мы будем рассчитывать похожесть двух токенов используя формулу [1]. Эта формула показывает вероятность того, что два токена входят в состав одного слова. Соответственно мы полагаем, что два токена входят в состав одного слова, если выполняется неравенство [2].
[1] 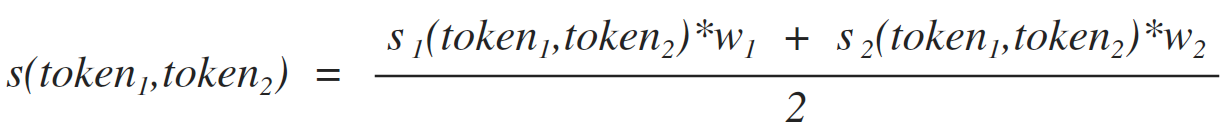
где:
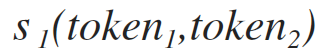 формула схожести токенов на базе подсчета общих символов (смотри формулу 1.1)
формула схожести токенов на базе подсчета общих символов (смотри формулу 1.1)
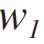 вес формулы схожести токенов на базе подсчета общих символов (может принимать значение от 0. до 1.). Данный параметр вшит в код и имеет значение 0.8. К сожалению, изменение этой ситуации пока не входят в планы релиза Alpha4, но если вам хочется поиграться и совсем не хочется перебирать проект, то вы можете открыть нам таску тут и мы все сделаем.
вес формулы схожести токенов на базе подсчета общих символов (может принимать значение от 0. до 1.). Данный параметр вшит в код и имеет значение 0.8. К сожалению, изменение этой ситуации пока не входят в планы релиза Alpha4, но если вам хочется поиграться и совсем не хочется перебирать проект, то вы можете открыть нам таску тут и мы все сделаем.
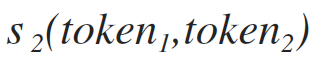 формула схожести токенов на базе рекурсивного подсчета наиболее длинных общих строк (смотри формулу 1.2).
формула схожести токенов на базе рекурсивного подсчета наиболее длинных общих строк (смотри формулу 1.2).
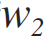 вес формулы схожести токенов на базе рекурсивного подсчета наиболее длинных общих строк. С этим весом та же лажа, что и с прошлым — никакого конфигурирования через конфиг, жёстко вшито значение 1.
Формула схожести токенов на базе подсчета общих символов
вес формулы схожести токенов на базе рекурсивного подсчета наиболее длинных общих строк. С этим весом та же лажа, что и с прошлым — никакого конфигурирования через конфиг, жёстко вшито значение 1.
Формула схожести токенов на базе подсчета общих символов
Эта формула носит гордое имя… простите запамятовал, а кандидатской со всеми ссылками под рукой нет. Но я просто уверен, что доблестный Хабраюзер ткнёт меня носом в правильный ответ, не поленившись написать что-то колкое по поводу этого абзаца в частности и текста в общем)
[1.1]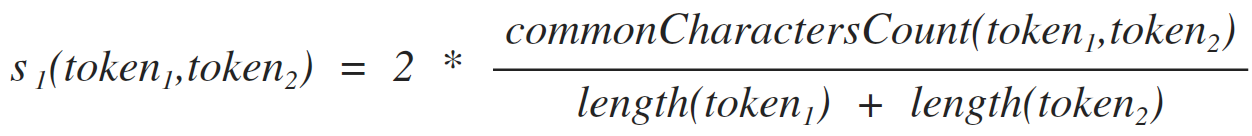
где:
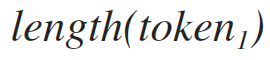 длинна токена,
длинна токена,
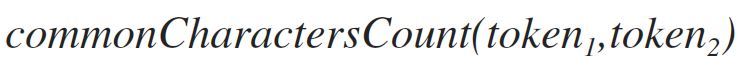 количество символов, которые входят в первый и второй токен одновременно. Например, для входных токенов: «ааббвв», «ааееев», результат будет 3, так как существует 3 символа [a, a, в], которые одновременно входят в оба токена.
формула очень проста — мы лишь подсчитываем символы, которые вошли в оба токена без учета позиции этих символов в токены.
количество символов, которые входят в первый и второй токен одновременно. Например, для входных токенов: «ааббвв», «ааееев», результат будет 3, так как существует 3 символа [a, a, в], которые одновременно входят в оба токена.
формула очень проста — мы лишь подсчитываем символы, которые вошли в оба токена без учета позиции этих символов в токены.
формула схожести токенов на базе рекурсивного подсчета наиболее длинных общих строк
Тут уже все веселее, формула рекурсивная и так же названа в честь своего автора)
[1.2]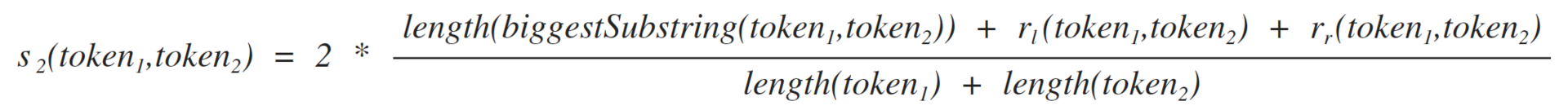
где:
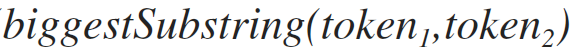 Максимальна строка, которая одновременно входит в оба токена
Максимальна строка, которая одновременно входит в оба токена
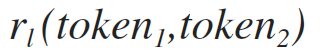 рекурсивный вызов формулы 1.2 для левой подстроки, смотри формулу 1.2.1
рекурсивный вызов формулы 1.2 для левой подстроки, смотри формулу 1.2.1
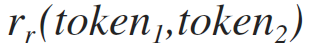 рекурсивный вызов формулы 1.2 для правой подстроки, смотри формулу 1.2.2
[1.2.1]
рекурсивный вызов формулы 1.2 для правой подстроки, смотри формулу 1.2.2
[1.2.1]
где:
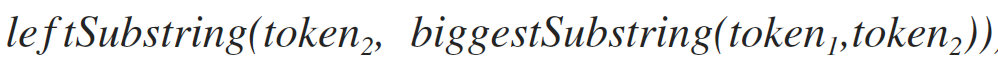 данный метод возвращает подстроку первого параметра в диапазон от первого символа до строки, которая передана вторым параметром. Например, для строк «привет» и «ве» результатом работы будет «при»
[1.2.2]
данный метод возвращает подстроку первого параметра в диапазон от первого символа до строки, которая передана вторым параметром. Например, для строк «привет» и «ве» результатом работы будет «при»
[1.2.2]
где:
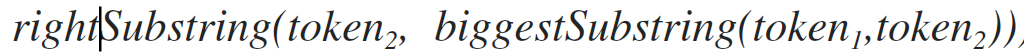 данный метод возвращает подстроку первого параметра в диапазон от окончания строки второго аргумента в первом аргументе, до последнего символа строки. Например, для строк «привет» и «ве» результатом работы будет «т».
[2]
данный метод возвращает подстроку первого параметра в диапазон от окончания строки второго аргумента в первом аргументе, до последнего символа строки. Например, для строк «привет» и «ве» результатом работы будет «т».
[2]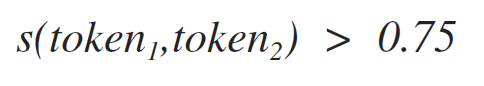
Порог, который используется в данном неравенстве был подобран эмпирически: 0.75. В данном релизе AIF Alpha3 этот параметр нагло «вшит дюбелем» в коде вот тут. Так что, что бы поменять это значение нужно перебирать весь проект (Исправление этой нелепости уже запланировано в Alpha4.
Сравнение слов между собой
По факту, слово — это не более чем множество токенов объединённых между собой по некоему правилу. Правило мы уже обозначили (удовлетворение условию неравенства 2). Так что сравнение двух слов между собой решается достаточно просто ([3]).
[3]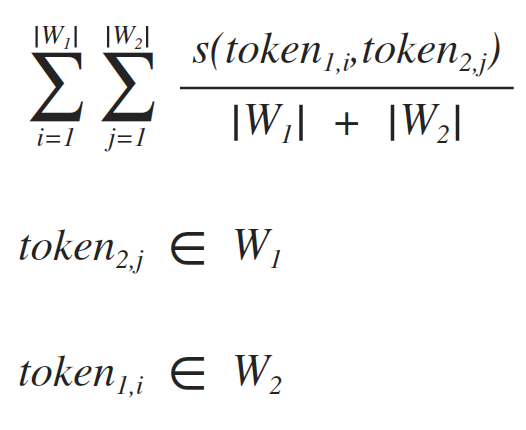
Немного о практическом применении
Практика построения словаря описана на страничке вот тут. Процесс очень простой и занимает не более нескольких строк кода:
final List
final IDictBuilder dictBuilder = new DictBuilder (); final IDict dict = dictBuilder.build (tokens); Интерфейс IDict:
public interface IDict {
public Set
} Ну и сам интерфейс IWord:
public interface IWord {
public String getRootToken ();
public Set
public Long getCount ();
public static interface IWordPlaceholder {
public IWord getWord ();
public String getToken ();
}
} к слову сказать, вся документация релиза Alpha3 лежит вот тут
там можно найти описание API по работе с токенами
и с предложениями
но вернемся к задачи построения словаря. Пример использования данной функции можно посмотреть в коде консольной утилиты-клиента данной библиотеки.
public Void apply (String… args) {
final String text;
try {
text = FileHelper.readAllTextFromFile (args[0]);
} catch (IOException e) {
e.printStackTrace ();
return null;
}
final TokenSplitter tokenSplitter = new TokenSplitter ();
final IDictBuilder
Все достаточно просто, необходимо подключить наш репозиторий в свой проект вот так:
Реальную работу алгоритма рассмотрим на примере консольной утилиты которая использует движок AIF Alpha3. Почитать об использовании утилиты можно вот на этой страничке. Если будете пробовать построить словарь на целой книге то запаситесь терпением. К сожалению текущая реализация достаточно медленная, по этому поводу у нас есть issue, но совершенно не понятно когда дойдут руки его починить.
А вот пример работы программы которую натравили на текст данной статьи (показана лишь часть вывода программы):
java -jar aif-cli-1.2-jar-with-dependencies.jar -dbuild ~/tmp/text1.txt
Basic token: разъяснения tokens: [ [разъяснения] ]Basic token: из tokens: [ [из] ]Basic token: дюбелем» tokens: [ [дюбелем»] ]Basic token: public tokens: [ [public] ]Basic token: слов, tokens: [ [слов, слова, слове,] ]Basic token: том, tokens: [ [том,] ]Basic token: совершенно tokens: [ [совершенно] ]Basic token: code: tokens: [ [code:] ]Basic token: [2]. tokens: [ [[2]., [1]., [1.1]] ]Basic token: Интерфейс tokens: [ [Интерфейс] ]Basic token: developer. tokens: [ [developer., developer, developer,] ]Basic token: сожалению, изменение tokens: [ [сожалению, изменение] ]Basic token: одновременно tokens: [ [одновременно, одновременно.] ]Basic token: testing), tokens: [ [testing),] ]Basic token: (integration tokens: [ [(integration] ]Basic token: символа tokens: [ [символа] ]Basic token: language: tokens: [ [language:] ]Basic token: результат tokens: [ [результат, результатом] ]Basic token: что tokens: [ [что, что-то] ]Basic token: термин tokens: [ [термин, терминов] ]Basic token: сделано tokens: [ [сделано] ]Basic token: Соответственно tokens: [ [Соответственно] ]Basic token: Термины tokens: [ [Термины] ]Basic token: длинна tokens: [ [ длинна] ]Basic token: токены, tokens: [ [токены, токены.] ]Basic token: книге tokens: [ [книге] ]Basic token: существует tokens: [ [существует] ]Press 'Enter' to continue or 'q' command to quit. There are -51 entities to show
Немного о том, что ожидать в следующем релизе
Если все пойдет как задумано, то в конце Января мы выпустим 4й релиз AIF, в котором представим следующие возможности:
построение словаря семантических слов поиск синонимов в тексте построение графа связей семантических слов в тексте Возможно еще и другие функции, если успеем;)
И вновь, хотите помочь проекту — пишите нам. Есть интересные задачи в области НЛП — пишите нам. Не хотите помочь и нет задачи, но есть о чем сказать — пишите. Будем рады)
Наша команда
Kovalevskyi Viacheslav — algorithm developer, architecture design, team lead (viacheslav@b0noi.com / b0noi)Ifthikhan Nazeem — algorithm designer, architecture design, developerSviatoslav Glushchenko — REST design and implementation, developerOleg Kozlovskyi QA (integration and qaulity testing), developer.Balenko Aleksey (podorozhnick@gmail.com) — added stammer support to CLI, junior developerEvgeniy Dolgikh — QA assistance, junior developer
Ссылки на проект и подробности
project language: Java 8 license: MIT license issue tracker: github.com/b0noI/AIF2/issues wiki: github.com/b0noI/AIF2/wiki source code: github.com/b0noI/AIF2 developers mail list: aif2-dev@yahoogroups.com (subscribe: aif2-dev-subscribe@yahoogroups.com)
