PostgreSQL Antipatterns: редкая запись долетит до середины JOIN
Если писать SQL-запросы без анализа алгоритма, который они должны реализовать, ни к чему хорошему с точки зрения производительности это обычно не приводит.
Такие запросы любят «кушать» процессорное время и активно почитывать данные практически на ровном месте. Причем, это вовсе не обязательно какие-то сложные запросы, наоборот — чем проще он написан, тем больше шансов получить проблемы. А уж если в дело вступает оператор JOIN…

Само по себе соединение таблиц не вредно и не полезно — это просто инструмент, но и пользоваться им надо уметь.
Группировка по недосмотру
Сначала возьмем совсем простой пример.
Есть «словарик» на 100 записей (например, это регионы РФ):
CREATE TABLE tbl_dict AS
SELECT
generate_series(0, 100) k;
ALTER TABLE tbl_dict ADD PRIMARY KEY(k);
… и к нему прилагается таблица связанных «фактов» на 100K записей:
CREATE TABLE tbl_fact AS
SELECT
(random() * 100)::integer k
, (random() * 1000)::integer v
FROM
generate_series(1, 100000);
CREATE INDEX ON tbl_fact(k);
Теперь попытаемся подсчитать сумму значений по каждому «региону».
Как слышится, так и пишется
SELECT
d.k
, sum(f.v)
FROM
tbl_fact f
NATURAL JOIN
tbl_dict d
GROUP BY
1;
Само чтение данных заняло только 18% времени, остальное — обработка:
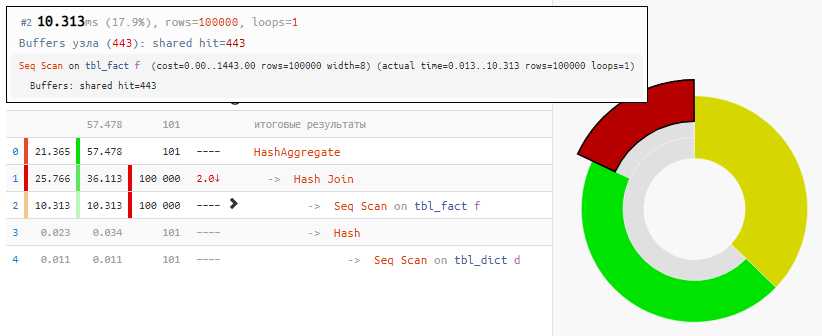
[посмотреть на explain.tensor.ru]
А все потому, что Hash Join и Hash Aggregate пришлось обрабатывать по 100K записей из-за нашего желания группировать по полю связанной таблицы.
Применяем смекалку
Но ведь значение этого поля равно значению поля в агрегируемой таблице! То есть нам никто не мешает сначала сгруппировать «факты», а уже потом делать соединение:
SELECT
d.k
, f.sum
FROM
(
SELECT
k
, sum(v)
FROM
tbl_fact
GROUP BY
1
) f
NATURAL JOIN
tbl_dict d;
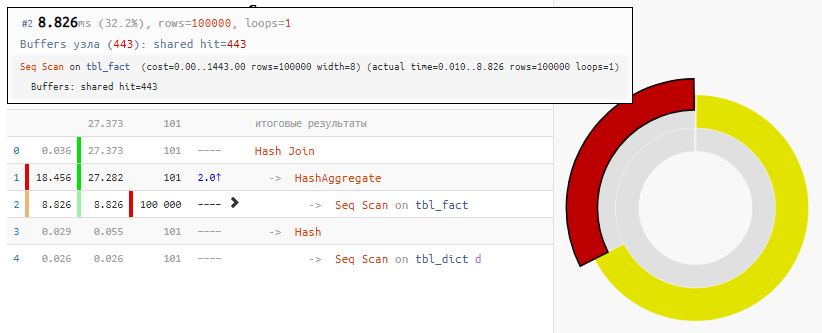
[посмотреть на explain.tensor.ru]
Безусловно, метод не универсален, но для нашего случая «обычного JOIN» выигрыш по времени в 2 раза с минимальной модификацией запроса — просто за счет «обнулившегося» Hash Join, которому на вход вместо 100K записей пришло только 100.
Неравные условия
Теперь усложним задачу: у нас есть 3 таблицы, связанные одним идентификатором — основная и две вспомогательные с некими прикладными данными, по которым мы будем фильтровать.
Маленькое, но очень важное замечание: пусть на основе «прикладных» знаний целевой задачи нам уже заведомо известно, что условия будут выполняться на первой таблице — почти всегда (для определенности — 3:4), а на второй — очень редко (1:8).
Мы хотим отобрать из основной и первой вспомогательной таблицы 100 первых по id записей с четными значениями идентификатора, для которых выполняются условия на всех таблицах. Всего записей в таблицах у нас пусть будет снова по 100K.
CREATE TABLE base(
id
integer
PRIMARY KEY
, val
integer
);
INSERT INTO base
SELECT
id
, (random() * 1000)::integer
FROM
generate_series(1, 100000) id;
CREATE TABLE ext1(
id
integer
PRIMARY KEY
, conda
boolean
);
INSERT INTO ext1
SELECT
id
, (random() * 4)::integer <> 0 -- 3:4
FROM
generate_series(1, 100000) id;
CREATE TABLE ext2(
id
integer
PRIMARY KEY
, condb
boolean
);
INSERT INTO ext2
SELECT
id
, (random() * 8)::integer = 0 -- 1:8
FROM
generate_series(1, 100000) id;
Как слышится, так и пишется
SELECT
base.*
, ext1.*
FROM
base
NATURAL JOIN
ext1
NATURAL JOIN
ext2
WHERE
id % 2 = 0 AND
conda AND
condb
ORDER BY
base.id
LIMIT 100;
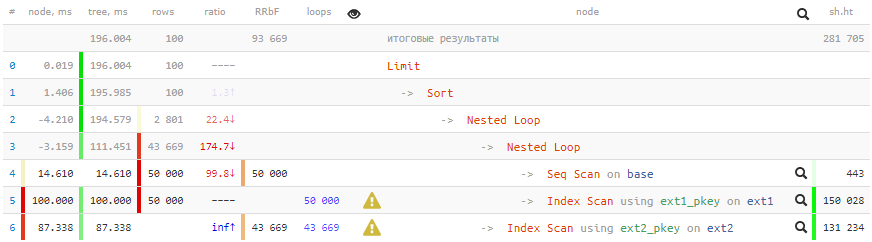
[посмотреть на explain.tensor.ru]
200 мс и больше 2GB данных прокачано — не очень хорошо для 100 записей!
Применяем смекалку
Используем следующие подходы, чтобы добиться ускорения:
- Для начала поймем, что все условия по связанным таблицам нам вообще имеет смысл проверять только при выполнении условия по основной таблице (для четных id).
- Данные на выходе должны быть отсортированы по base.id, и для этого нам отлично подойдет первичный ключ этой таблицы!
- Данные из ext2 нам вообще не нужны, и используются только для проверки условия. Значит, всю работу с этой таблицей можно смело вынести из JOIN в WHERE-часть. И использовать для проверки EXISTS, а то вдруг такой записи там вообще нет?
- Извлекать хоть какие-то данные из ext1 нам надо только в случае успешного прохождения остальных проверок по base и ext2. То есть соединение с ext1 должно идти после всех действий с base/ext2, чего можно добиться с помощью LATERAL.
- Чтобы планировщик запроса не пытался вложенную проверку по ext2 превратить в JOIN, подзапрос «спрячем под CASE».
SELECT
base.*
, ext1.*
FROM
base
, LATERAL( -- подзапрос делается заведомо после отбора по base
SELECT
*
FROM
ext1
WHERE
id = base.id AND
conda -- частое условие
LIMIT 1
) ext1
WHERE
CASE
WHEN base.id % 2 = 0 THEN
EXISTS( -- подзапрос делается только при прохождении первичного условия
SELECT
NULL
FROM
ext2
WHERE
id = base.id AND
condb -- редкое условие
LIMIT 1
)
END
ORDER BY
base.id -- сортировка пойдет строго по PK, потому что больше не по чему
LIMIT 100;

[посмотреть на explain.tensor.ru]
Запрос, конечно, стал посложнее, но выигрыш в 13 раз по времени и в 350 по «прожорливости» стоит того!
Снова напомню, что использовать стоит не все способы и не всегда, но знать — лишним не будет.
