Поиск в пространстве стратегий. AI водитель
Выкладываю отчёт о своём эксперименте в области машинного обучения. В этот раз темой эксперимента было создание AI для управления моделькой автомобиля.
Как написано на умных сайтах, существует два основных способа сделать, чтобы объект управления максимизировал некую функцию оценки:
1) Запрограммировать обучение с подкреплением (привет собакам Павлова)
2) Провести прямой поиск в пространстве стратегий
Я решил выбрать второй вариант.
AI-водитель
В качестве модельной задачи я выбрал подзадачу из одного чемпионата по ИИ (когда я её решал впервые, я ещё не умел machine learning).
Есть объект. Он может поворачиваться вправо-влево и ускоряться вперёд-назад (вперёд — побыстрее, назад — помедленнее). Как быстрее всего добраться этим объектом из пункта А в пункт Б? 
function q = evaluateNN(input,nn)
unit.angle=0;
unit.x=0;
unit.y=0;
trg.x=input(1);
trg.y=input(2);
q=0;
rmin=1e100;
for i=1:20 %машина "живёт" 20 тактов
%работа сенсоров
tangle=180*atan2(-unit.y+trg.y,-unit.x+trg.x)/3.141-unit.angle;
if(tangle>180)
tangle=tangle-360;
end;
if(tangle<-180)
tangle=tangle+360;
end;
r=sqrt((unit.y-trg.y)^2+(unit.x-trg.x)^2);
%принятие решений
answArr=fastSim(nn,[tangle;r]);
answArr(1)=(10+(-2))/2+ answArr(1)*(10-(-2))/2;
answArr(2)=(30+(-30))/2+ answArr(2)*(30-(-30))/2;
%механика
vx=answArr(1)*cos(3.141*unit.angle/180);
vy=answArr(1)*sin(3.141*unit.angle/180);
unit.x=unit.x+vx;
unit.y=unit.y+vy;
unit.angle=unit.angle+answArr(2);
%да, машина у нас довольно простенькая.
if(r0)
q=0;
end;
end
Вообще-то задачу можно решить, записав дифференциальное уравнение движения и решив его… Но я в диффурах не силён. Поэтому регулярно сталкивался с такими проблемами:
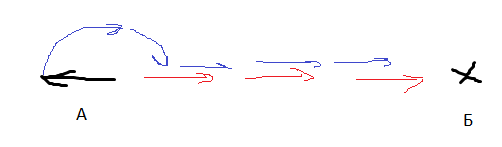
Юнит повёрнут к цели спиной. Ему лучше развернуться и доехать, или доехать задним ходом?

Юнит повёрнут к цели под 70 градусов. Мне лучше ускоряться и одновременно поворачивать, или сначала повернуть, а потом ускоряться? Как выбрать порог, отделяющий одну стратегию от другой?
Теперь, когда у меня есть эффективный оптимизирующий алгоритм и скоростные нейросети, я решил задачу перебором стратегий. То есть я представил нашу задачу как функцию, где входные величины — это веса и сдвиги нейронов, а выходная величина — это численная оценка эффективности данной стратегии (эта численная оценка называется функцией качества или метрикой качества).
Входные данные нейросети:
1) Направление на цель (от -180 до 180 градусов)
2) Расстояние до цели
3) Курсовая скорость объекта управления
4) Боковая скорость объекта управления
Курсовая и боковая скорости — это вот эти штуки: 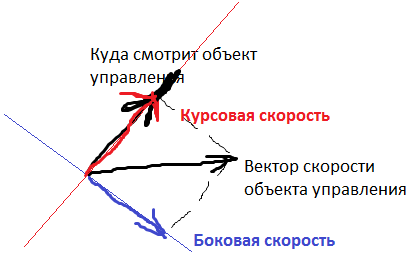
Выходные величины — положение руля (от -30 до +30 градусов за такт) и ускорение от движка (от -2 до +10 клеток/ход за ход).
В качестве функции качества в единичном испытании я выбрал q=(-минимальное расстояние до цели). Q всегда отрицательна, но чем больше Q, тем выше мы оцениваем качество алгоритма. Так как испытаний я провожу несколько, надо вывести из них какую-то единую метрику качества.
Я взял в качестве метрики наихудшее значение качества по всем испытаниям — то есть бот стремиться улучшить не средний, а худший из результатов. Я так сделал, чтобы AI не стремился оптимизировать результаты одних испытаний в ущерб результатам других испытаний.
Моя нейросеть состояла из 2 слоёв по 7 нейронов каждый, функция активации каждого нейрона — арктангенс.
Несколько минут обучения и…
AI стал наводиться на цель вот так. Красная стрелочка — это ориентация машины. То есть бот давал задний ход, одновременно разворачивался, а затем переходил с заднего хода на передний. При этом цели он достигал быстрее, чем стратегия «сначала хотя бы частично развернуться, потом ехать» и чем стратегия «ехать задом».
AI-собиратель
Немного меняем постановку задачи. Всё та же плоскость, всё те же возможности ускоряться/поворачивать (на этот раз ускорение от -3 до 7, а поворот от -30 до 30 градусов за ход). Каждое испытание ограничено 100 ходами.
Но теперь целей несколько. Каждая цель неподвижна. AI видит их таким образом: 
Нейросети доступен угол обзора в 200 градусов, который разбит на 9 равных секторов (22 градуса каждый). Если в один из секторов попадает цель, то на соответствующий сенсор нейросети попадает число, равное расстоянию до цели. Если цели в секторе нет, то на сенсор попадает число 1000 (практически все расстояния в симуляции меньше этого числа).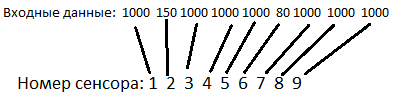
Если управляемый объект подъезжает к цели на расстояние 10 или меньше, цель уничтожается, а AI получает 10 очков (типа съел цель).
Начальные координаты объекта управления нулевые (0,0). Координаты целей в первом испытании такие:
[50,100] [10,30] [100,-120] [60,75]
Это типичные координаты. Всего испытаний 6, и координаты примерно такого порядка. Целей всегда 4.
Ставлю ИИ на обучение. ИИ безуспешно пытается обучиться в течение нескольких часов. Он в среднем захватывает одну цель за испытание (даже чуть меньше). Полагаю, проблема в том, что функция зависимости награды от коэффициентов кусочно-постоянная.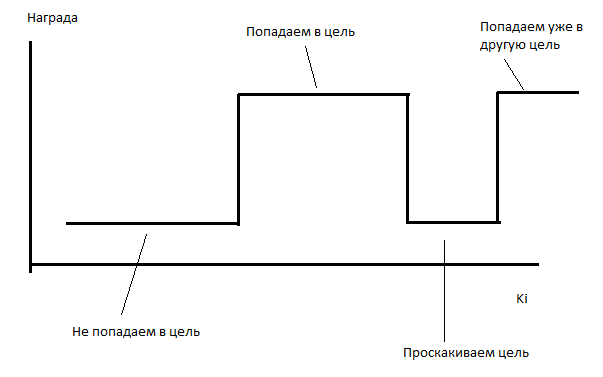
В таких случаях мой оптимизатор работает довольно плохо (да и эволюция в таких случаях не особенно справляется).
Поэтому я совершаю небольшое читерство. Я делаю, чтобы каждый ход AI получал число очков, обратно пропорциональное расстоянию до каждой из неподобранных целей. Он получает по 0.1/r очков за каждую цель. То есть на расстоянии в 10 он будет получать 0.001 очко за цель, а «съедание» этой цели будет давать 10 очков. Число очков, получаемое AI, меняется очень слабо, но функция становится кусочно-переменной, то есть у неё появляется ненулевая производная.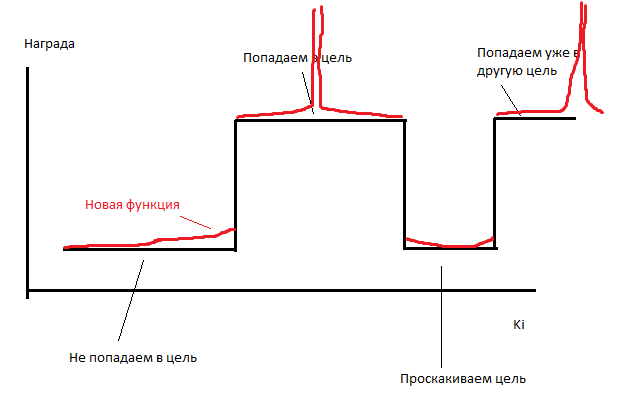
function q = evaluateNN(input,nn)
unit.angle=0;
unit.x=0;
unit.y=0;
unit.vx=0;
unit.vy=0;
trg=[];
trg(1).x=input(1);
trg(1).y=input(2);
trg(1).pickable=1;
trg(2).x=input(3);
trg(2).y=input(4);
trg(2).pickable=1;
trg(3).x=input(5);
trg(3).y=input(6);
trg(3).pickable=1;
trg(4).x=input(7);
trg(4).y=input(8);
trg(4).pickable=1;
tsz=size(trg);
tangle=[];
r=[];
sensor=[];
sensorMax=5;
sensorBound=70;
sectorSize=2*sensorBound/sensorMax;
q=-100;
rmin=1e100;
for i=1:200
%работа сенсоров
for j=1:sensorMax
sensor(j)=1e4;
end;
for j=1:tsz(2)
tangle(j)=180*atan2(-unit.y+trg(j).y,-unit.x+trg(j).x)/3.141-unit.angle;
if(tangle>180)
tangle=tangle-360;
end;
if(tangle<-180)
tangle=tangle+360;
end;
r(j)=sqrt((unit.y-trg(j).y)^2+(unit.x-trg(j).x)^2);
if(tangle(j)>-sensorBound && tangle(j)r(j))
sensor(index)=r(j);
end;
end;
%даём подкрепление за подбор награды
if(r(j)<10 && trg(j).pickable==1)
%picked up
q=q+10;
trg(j).pickable=0;
end;
%даём подкрепление за близость к награде
if(r(j)<50 && trg(j).pickable==1)
q=q+1/r(j);
end;
end;
%сенсоры скорости: боковой и курсовой
vangle=180*atan2(unit.vy,unit.vx)/3.141;
vr=unit.vy*sin(3.141*unit.angle/180)+unit.vx*cos(3.141*unit.angle/180);%v-radial. Scalar multing
vb=-unit.vx*sin(3.141*unit.angle/180)+unit.vy*cos(3.141*unit.angle/180);%v-back. vx*(-y)+vy*x
%принятие решений
answArr=fastSim(nn,[sensor';vr;vb]);
answArr(1)=(4+(-1))/2+ answArr(1)*(4-(-1))/2;
answArr(2)=(30+(-30))/2+ answArr(2)*(30-(-30))/2;
%механическая модель
ax=answArr(1)*cos(3.141*unit.angle/180);
ay=answArr(1)*sin(3.141*unit.angle/180);
unit.vx=unit.vx+ax;
unit.vy=unit.vy+ay;
unit.x=unit.x+unit.vx;
unit.y=unit.y+unit.vy;
unit.angle=unit.angle+answArr(2);
end;
if(q>0)
q=0;
end;
end
При этом результаты нескольких испытаний я объединял следующим образом: я брал средний результат и наихудший, и брал от них среднее.
Работа пошла бодрее. Несколько десятков минут — и вуаля: 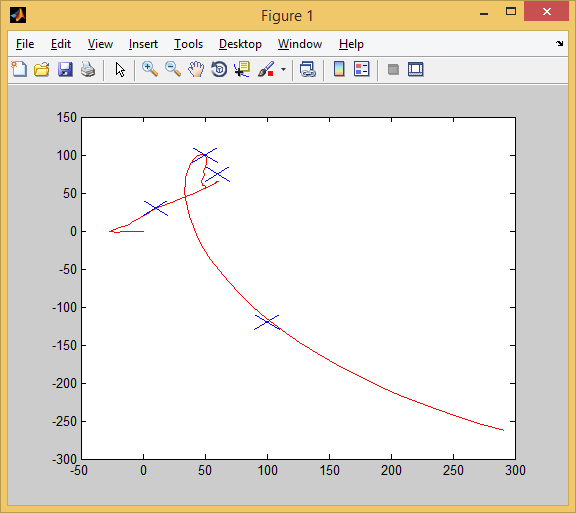
Так мы проходим 1-ое испытание. Все цели (синие крестики) успешно захвачены.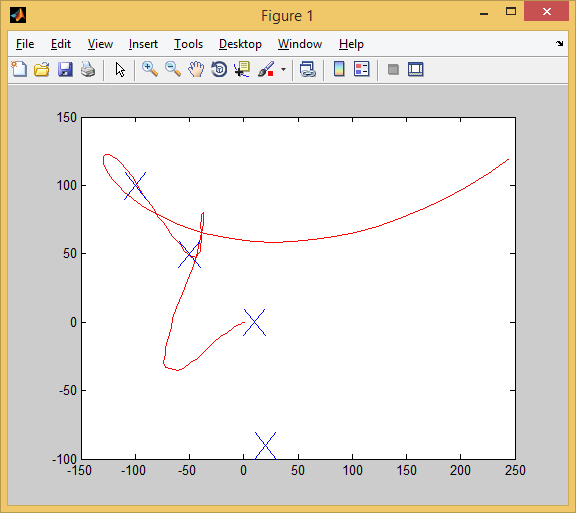
Так мы проходим 2-ое испытание. Захвачено 3 цели (для захвата той первой цели пришлось чуть проехать вперёд, а затем развернуться. Крупным планом это выглядит так: 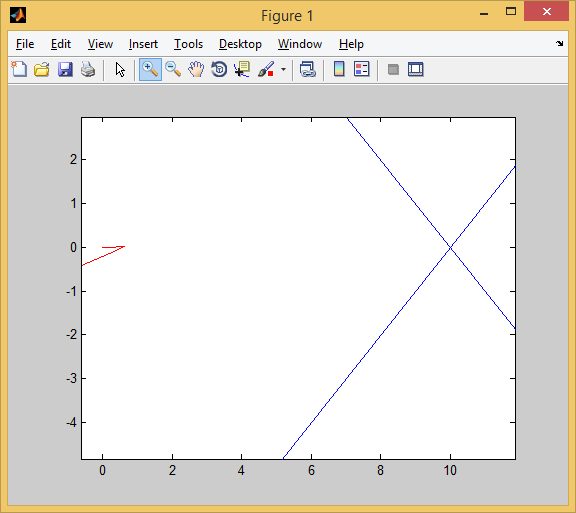
В 3-ем испытании тоже 4 из 4: 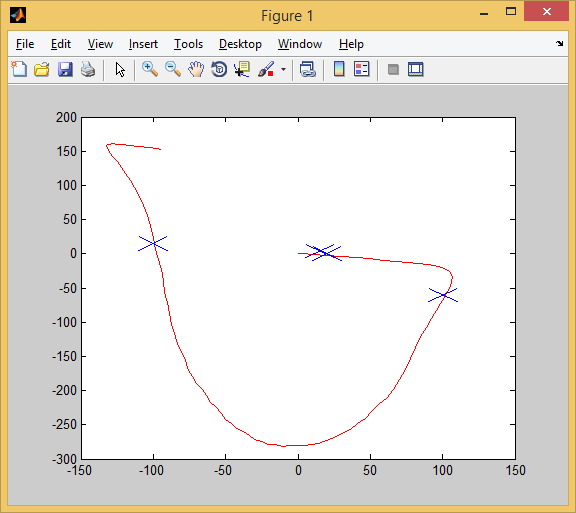
И в 4-ом: 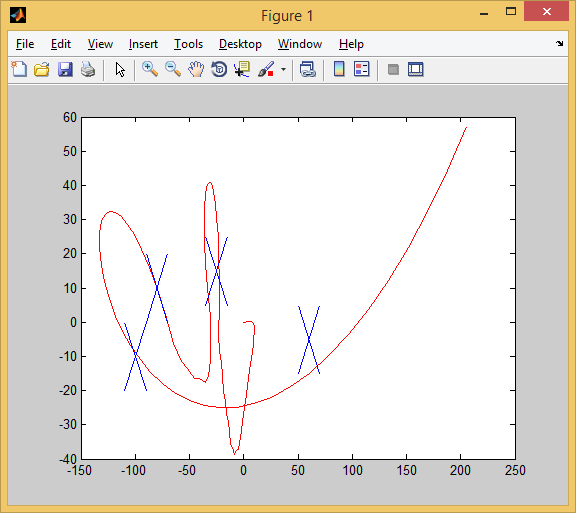
И в 5-ом: 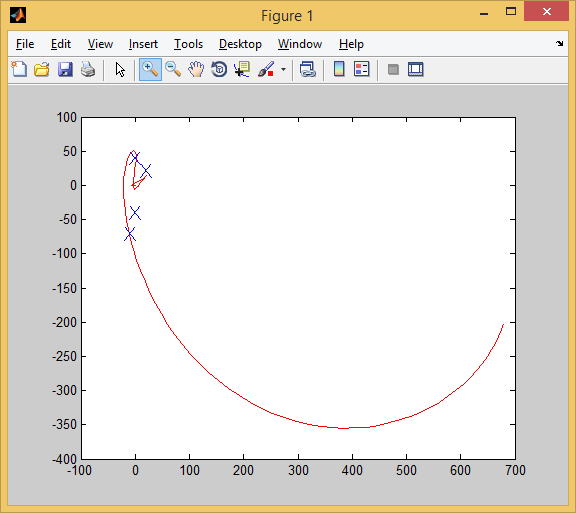
А вот в 6-ом у нас уже 3 из 4.
Зададим теперь новые испытания — такие, которых не было в обучающей выборке (проведём кроссвалидацию).
3 из 4! Признаться, я до последнего сомневался, что AI сможет перенести опыт обучающей выборки на тестовую.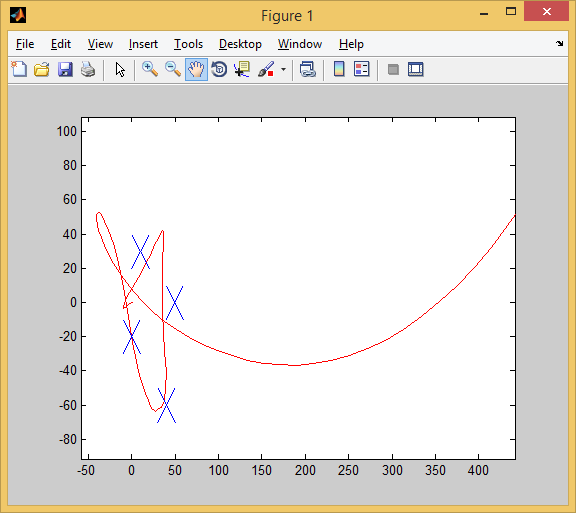
Отработал 3 цели, и мимо одной чуть-чуть промазал.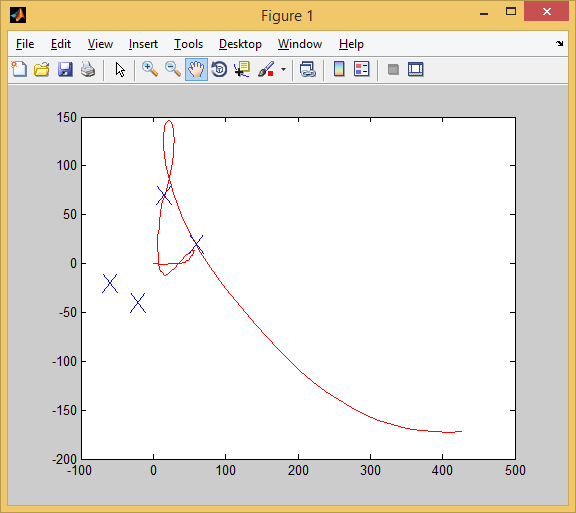
Ну, а тут AI совсем облажался. Отработал 2 цели из 4.
Вывод.
Отчёт об эксперименте должен заканчиваться выводами. Выводы следующие:
1) Обучение методом перебора пространства стратегий — многообещающая методика. Но она требовательна к оптимизатору — я применял довольно замороченный алгоритм для подбора параметров.
2) Кусочно-постоянная функция качества — это зло. Если у функции нет чего-то, хоть отдалённо напоминающего производную, её очень тяжело будет оптимизировать.
3) 2 слоя по 7 нейронов — это достаточно, чтобы сделать простенький автопилот. Обычно 14 нейронов — это пшик, из которого не собрать никакую полезную функцию.
Буду благодарен за комментарии, товарищи!
Если статья понравится, я расскажу, как делал аналогичный AI для игры типа Mortal Kombat.
